






索引操作:
- 为了更好的理解这些基本操作,我们将读取一个真实的股票数据。关于文件操作,后面介绍,这里只先用一下API
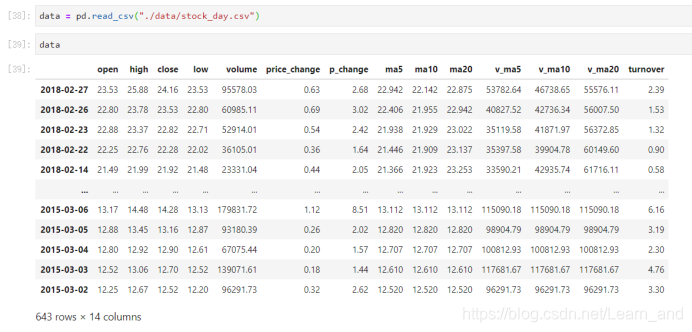
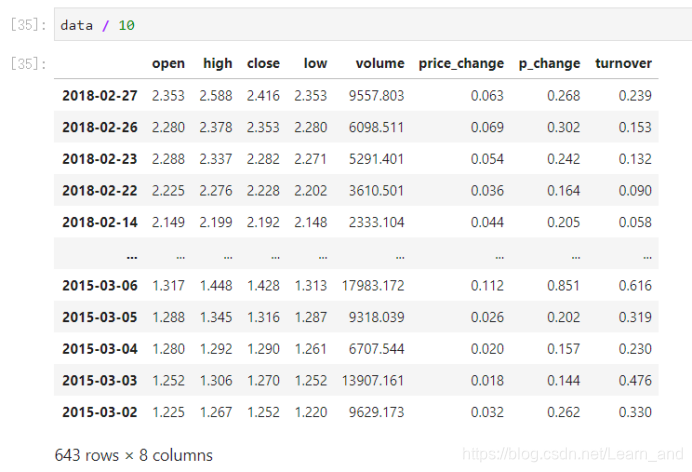
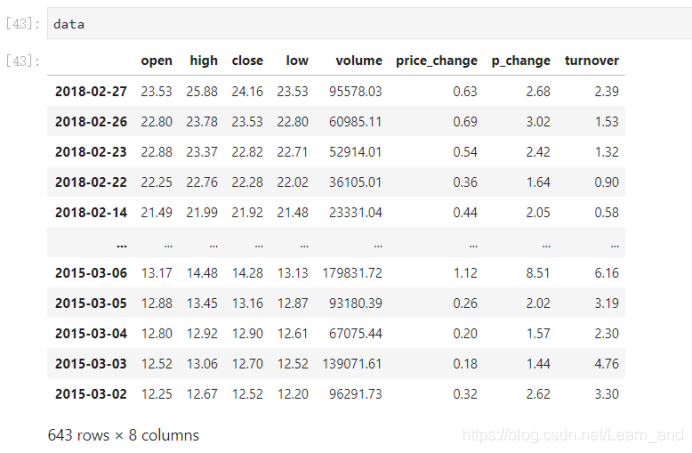
读取文件
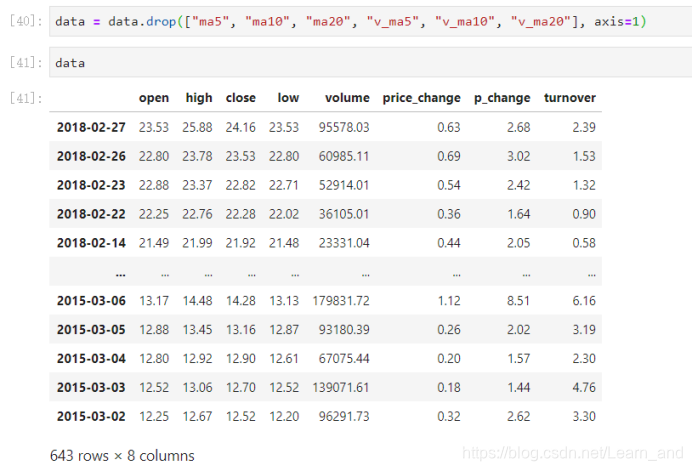
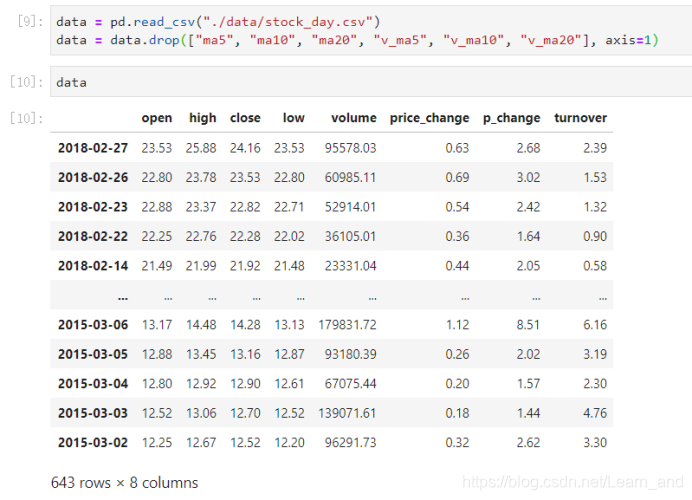
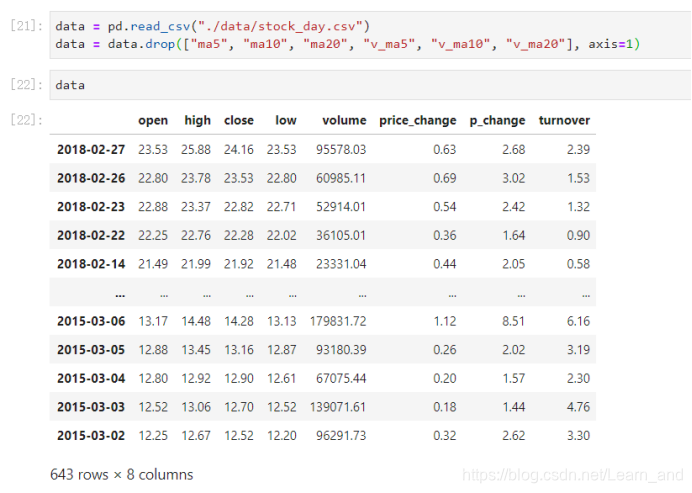
- 删除一些列,让数据更简单些,再去做后面的操作:
- data = data.drop([“ma5”, “ma10”, “ma20”, “v_ma5”, “v_ma10”, “v_ma20”], axis=1)
- 注意:不能直接进行数字索引。


- Numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似的操作,也可以直接使用列名、行名称,甚至组合使用。
直接使用行列索引(先列后行):
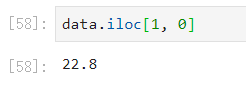
- 获取“2018-02-27”这天的’close’的结果。
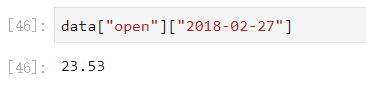
- 注意:必须先列后行。

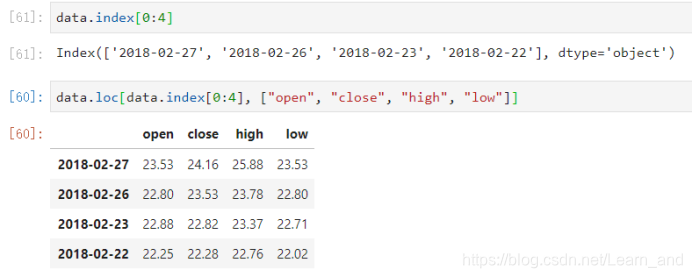
结合loc或者iloc使用索引:
- 获取从“2018-02-27”到“2018-02-22”的open列的结果。
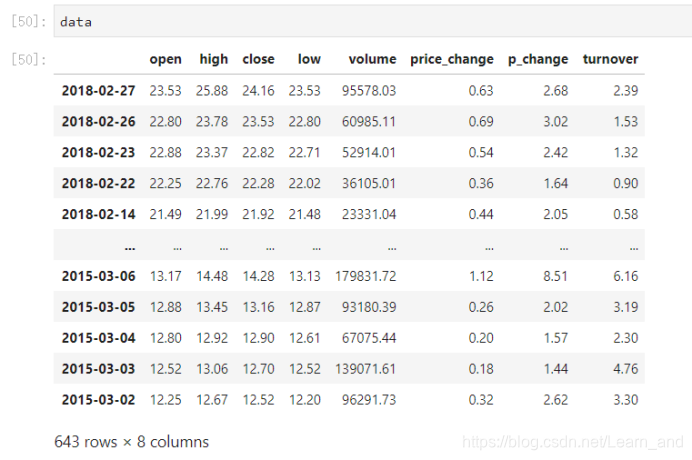
使用loc只能指定行列索引的名字。

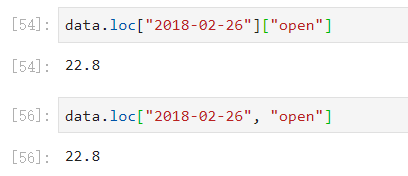
- 总结:如果不使用loc关键字的话,需要先列后行,如果使用loc关键字的话,那就可以先行后列了。
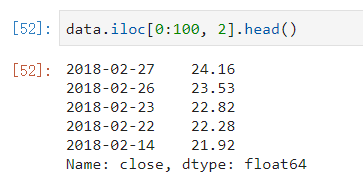
获取前100天的数据的“open”列的结果:
使用iloc可以通过索引的下标去获取:
- 也可以使用切片:

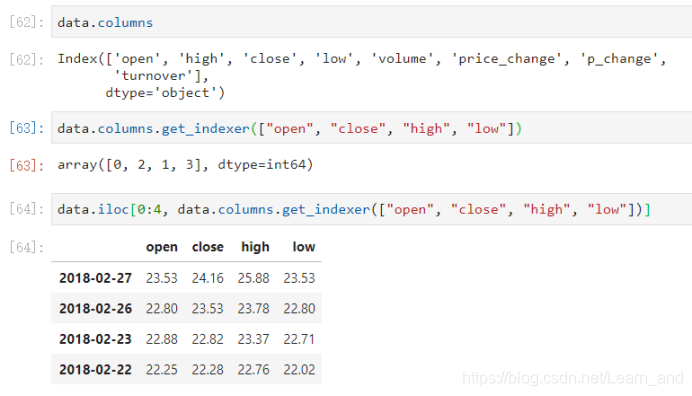
获取行第1天到第4天的[“open”, “close”, “high”, “low”]这4个指标的结果:
总结:
- 基本数据操作
- 索引操作
- 直接索引
- 先列后行
- 按名字索引
- loc
- 按数字索引
- iloc
- 组合索引
- 数字、名字
- 直接索引
- 索引操作
赋值:

对DataFrame当中的close列进行重新赋值为1:
- 或是:
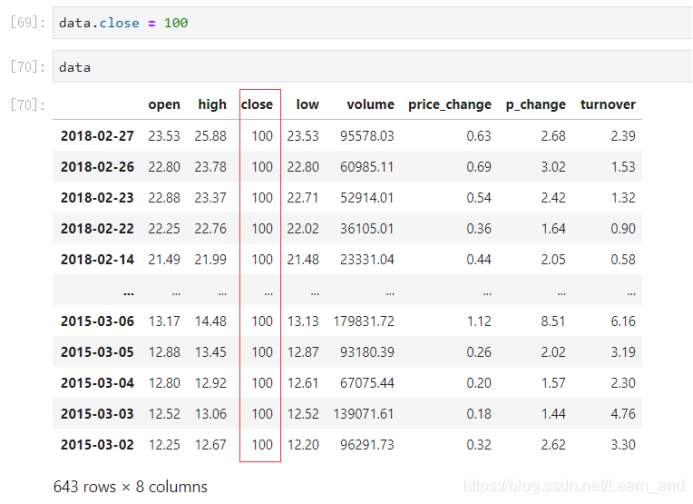
注意:都是修改原数据的
排序
排序有两种形式:
- 一种对内容进行排序;
- 一种对索引进行排序
对DataFrame类型的数据使用df.sort_values()对内容进行排序:
使用df.sort_values(key=,ascending=)对内容进行排序
- 单个键或者多个键进行排序,默认升序
- ascending=False:降序
- ascending=True:升序
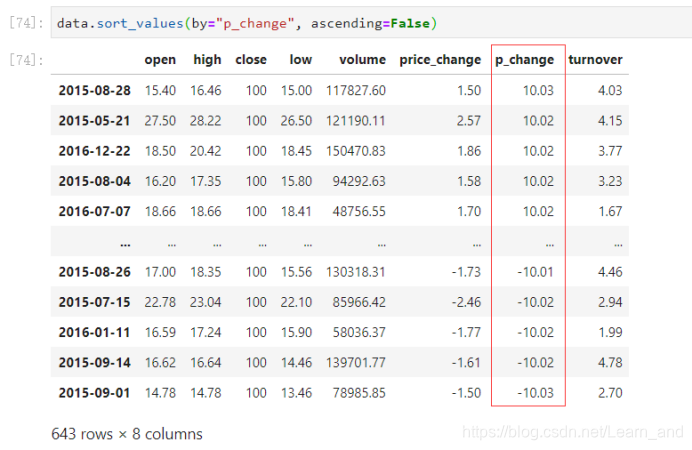
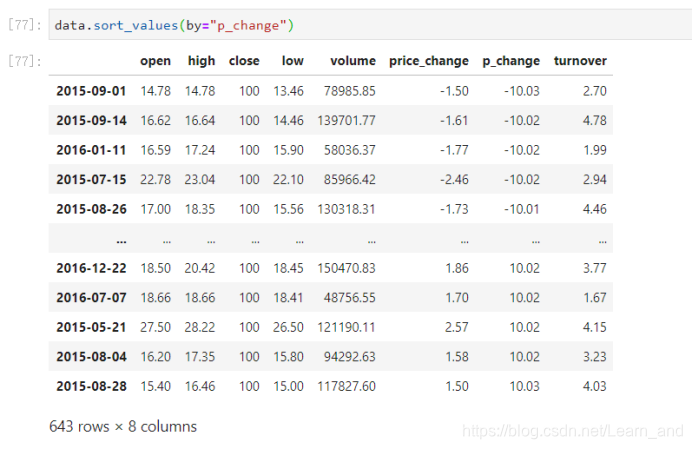
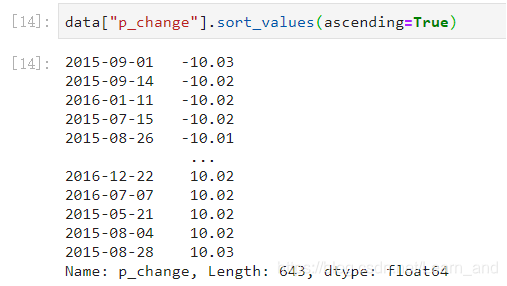
按照涨跌幅大小进行降序排序:
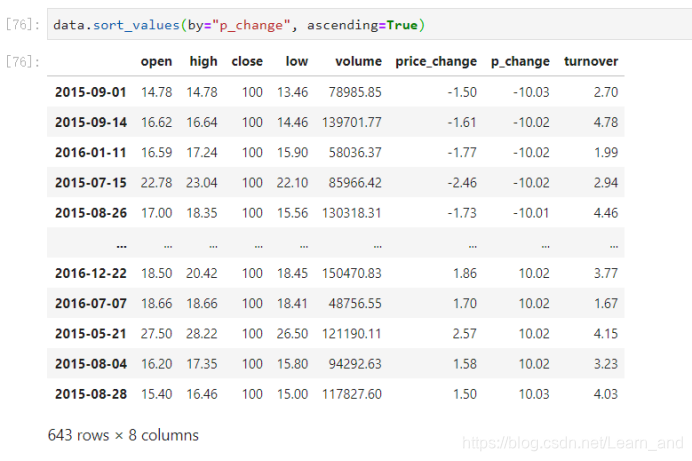
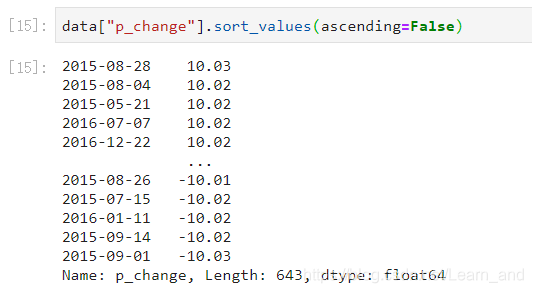
按照涨跌幅大小进行升序排序:
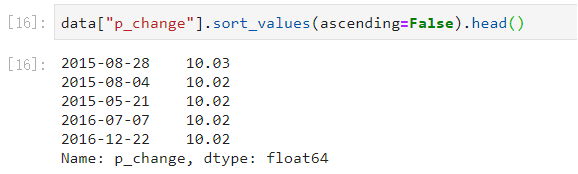
默认是升序:
按照多个键进行排序:

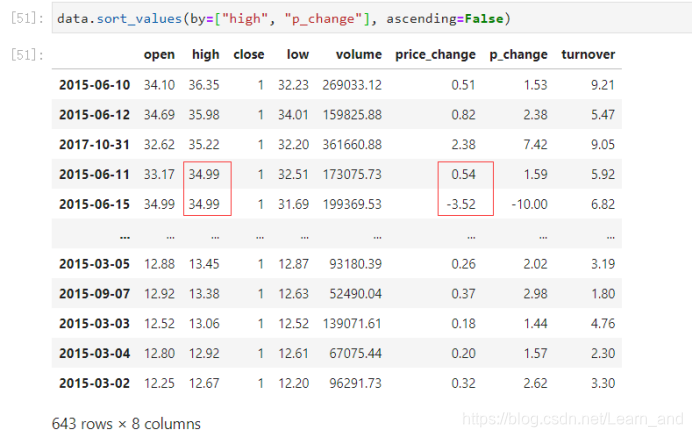
- 先按着high排序,high值一样的,再按着p_change列进行排序,也就是第一个排序规则一样的内容,再按着第二个规则进行排序。
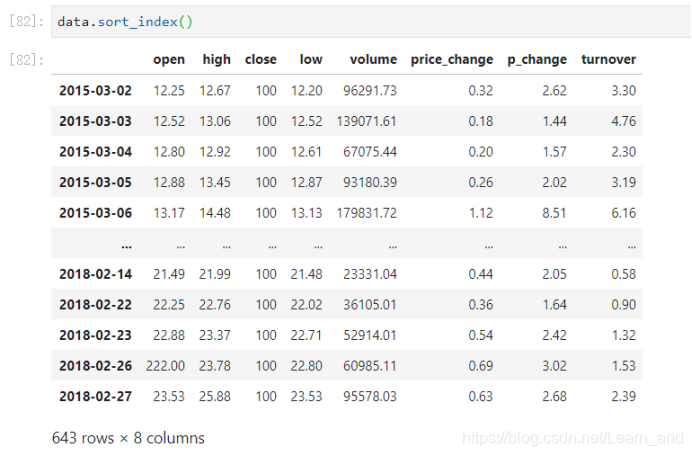
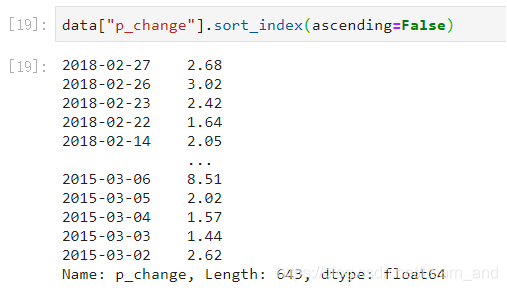
对DataFrame类型的数据使用df.sort_index对索引进行排序:
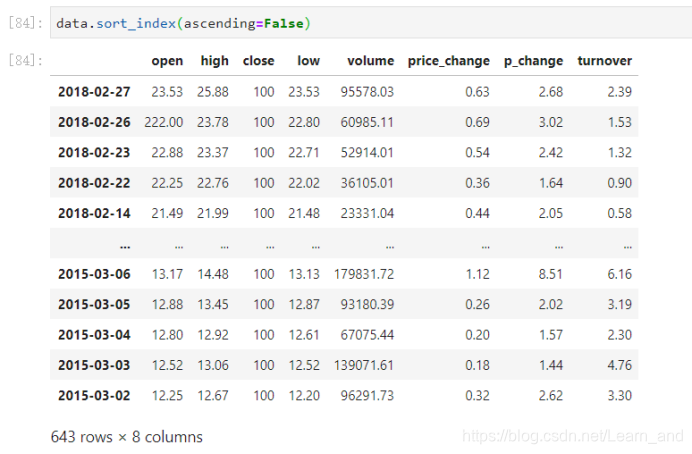
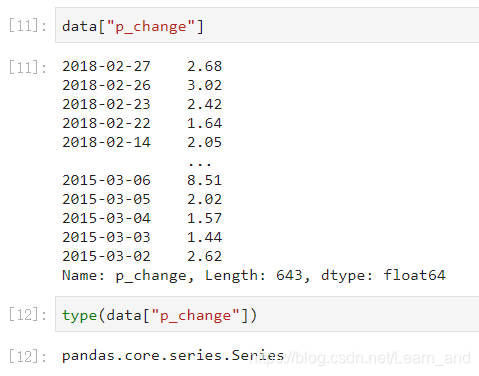
对Series类型的数据使用series.sort_values()对内容进行排序:
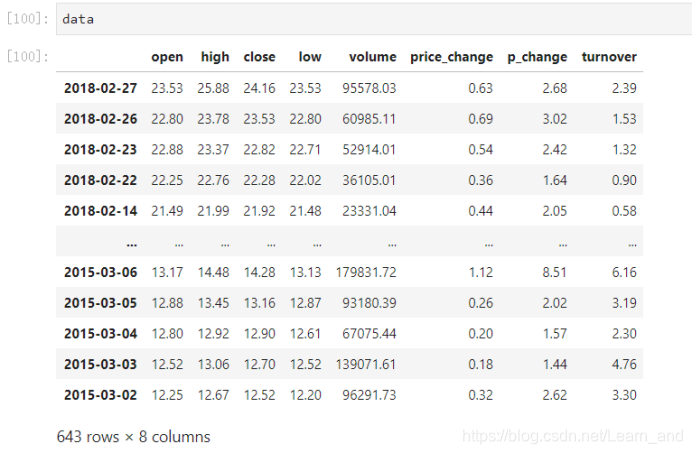
- data = pd.read_csv("./data/stock_day.csv")
- data = data.drop([“ma5”, “ma10”, “ma20”, “v_ma5”, “v_ma10”, “v_ma20”], axis=1)
提示:由于series排序时,只有一列,不需要排序字段参数。
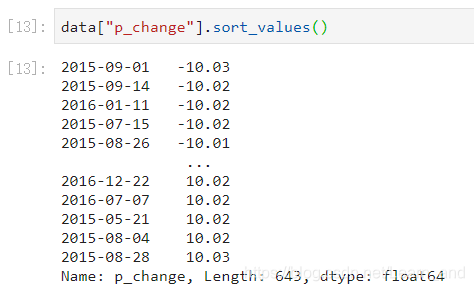
- 默认是True:
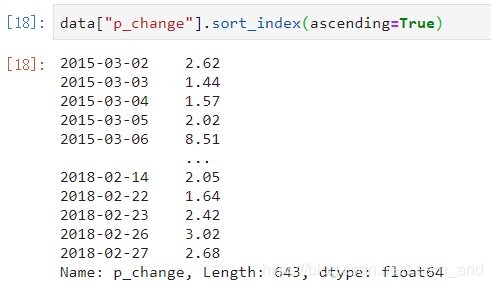
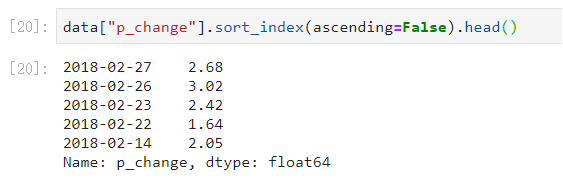
对Series类型的数据使用series.sort_index()对索引进行排序:

- 默认是True:
总结:
- sort_values对内容进行排序
- sort_index对索引进行排序
算术运算:
准备数据:
- data = pd.read_csv("./data/stock_day.csv")
- data = data.drop([“ma5”, “ma10”, “ma20”, “v_ma5”, “v_ma10”, “v_ma20”], axis=1)
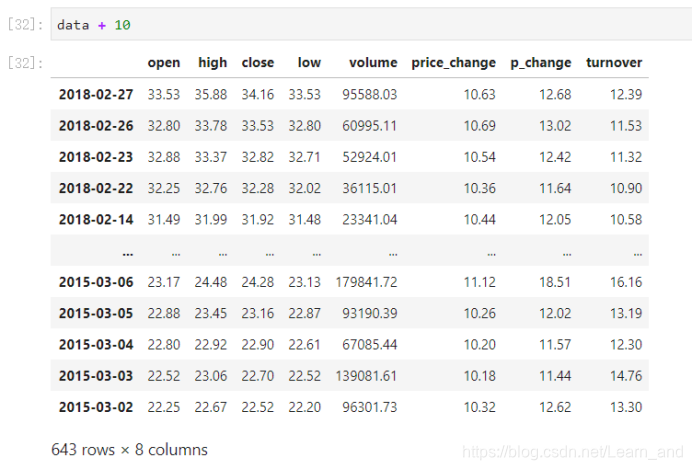
add(other):比如进行数学运算加上具体的一个数字。

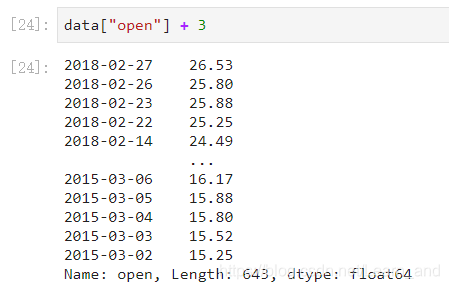
- 也可以:
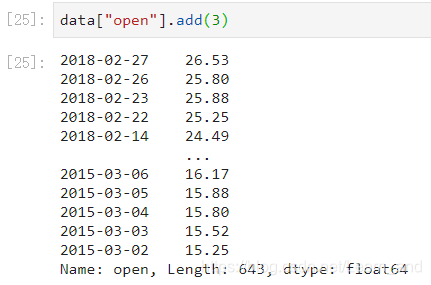
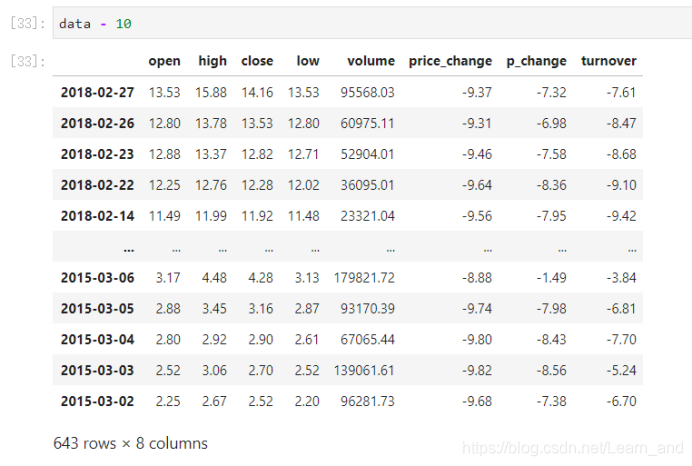
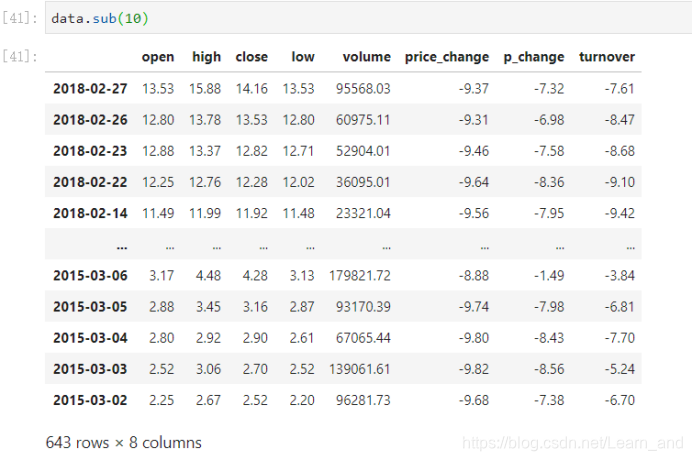
sub(other):比如进行数学运算减上具体的一个数字。
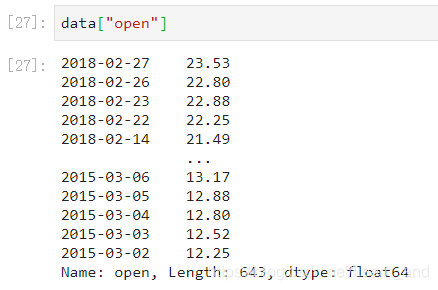
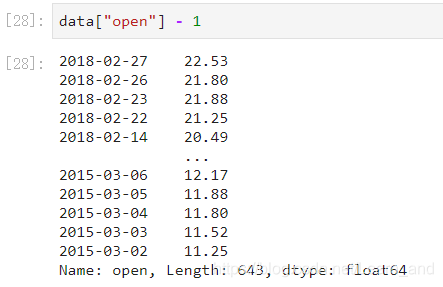
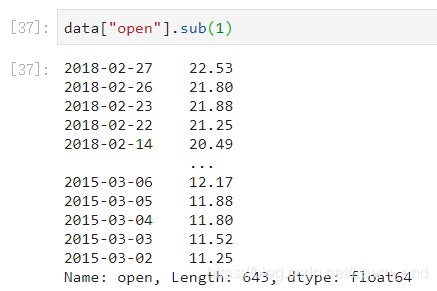
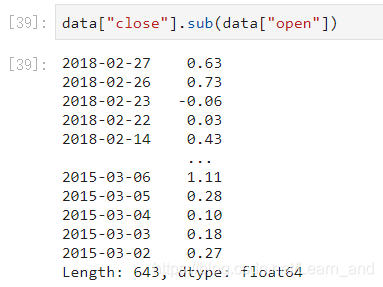
如果想要得到每天的涨跌大小?求出每天close-open价格差。
- 收盘价减去开盘价:
其它四则运算:
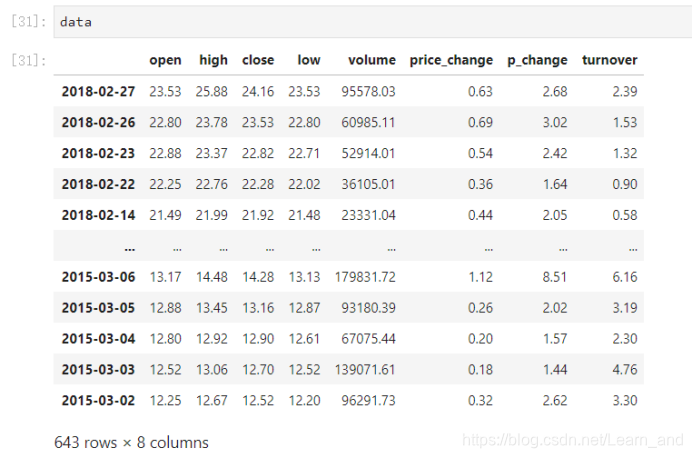
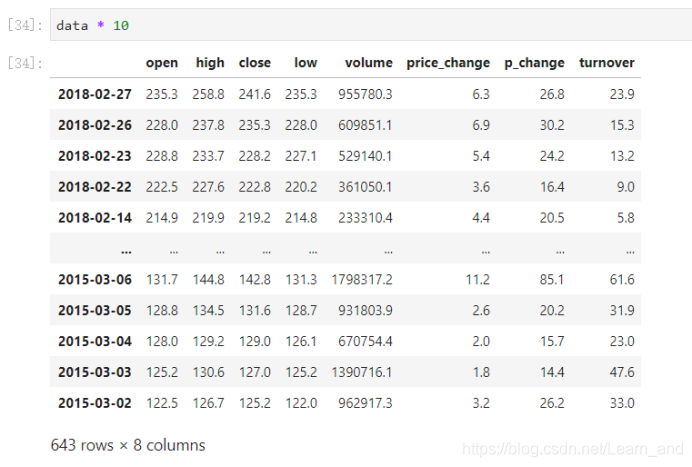
也可以对整个DataFrame进行运算:
逻辑运算:
逻辑运算符号:< > | &
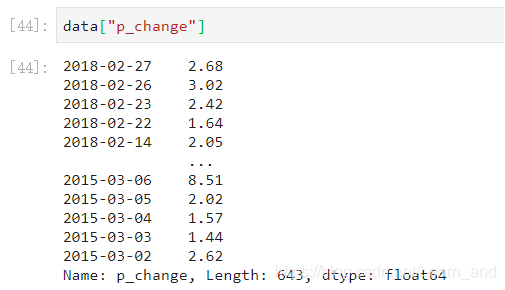
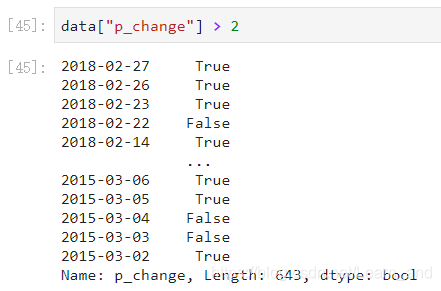
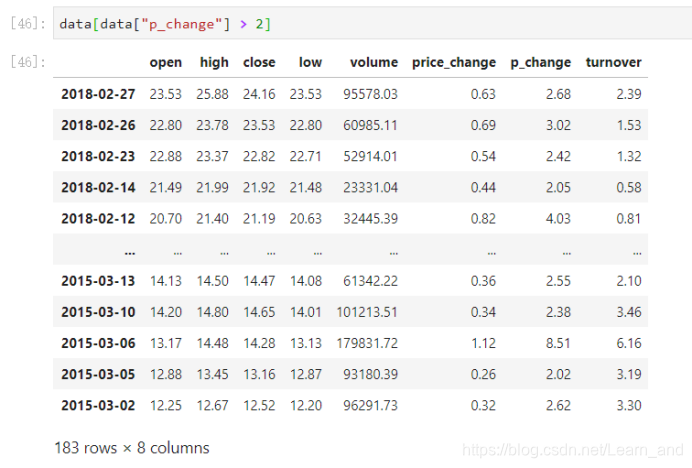
筛选出p_change > 2的日期数据,返回逻辑结果:
- 将逻辑判断的结果作为筛选的依据:
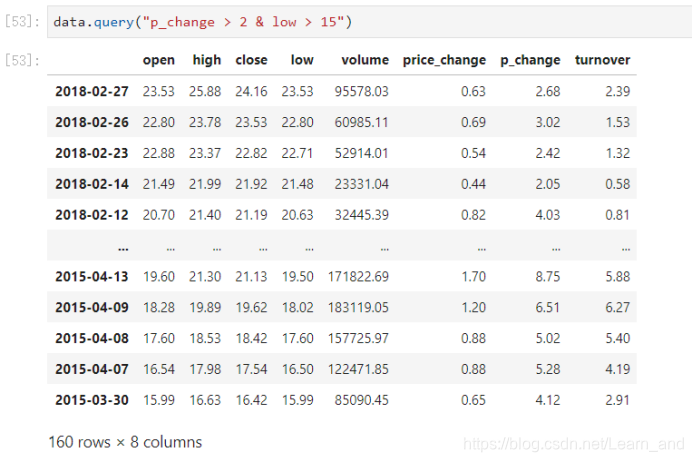
- 完成多个逻辑判断:筛选出p_change > 2 并且 low > 15
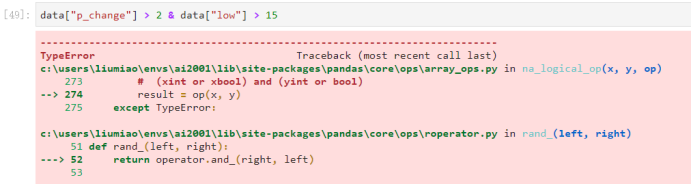

- 需要带上括号:
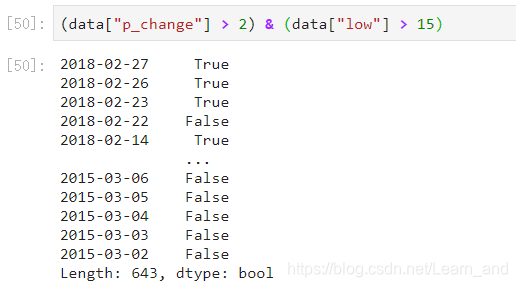
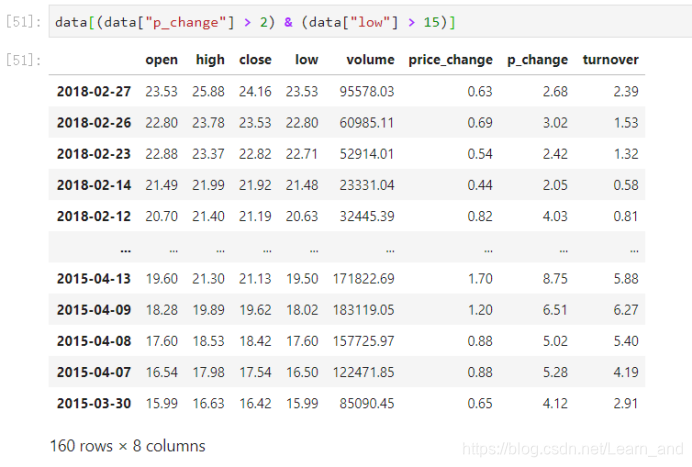
- 将逻辑判断的结果作为筛选的依据:
逻辑运算函数:
query(查询字符串):通过query使得刚才的过程更加方便简单。
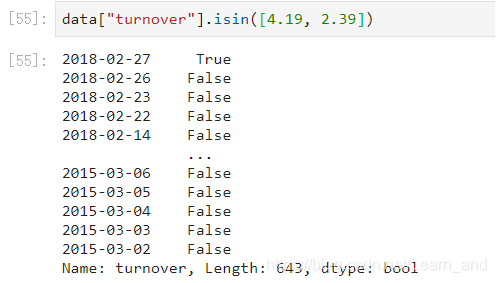
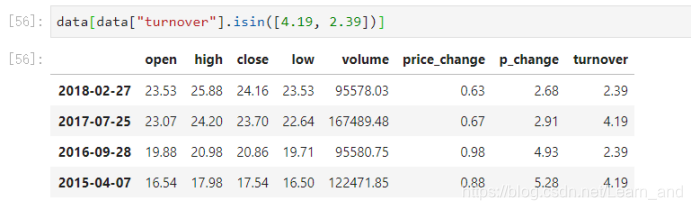
isin(values):比如判断‘turnover’是否为4.19, 2.39
- 可以指定值进行一个判断,从而进行筛选操作。
统计运算:
- describe():综合分析能够直接得出很多统计结果,count, mean(平均值), std(标准差), min(最小值), max(最大值)等。
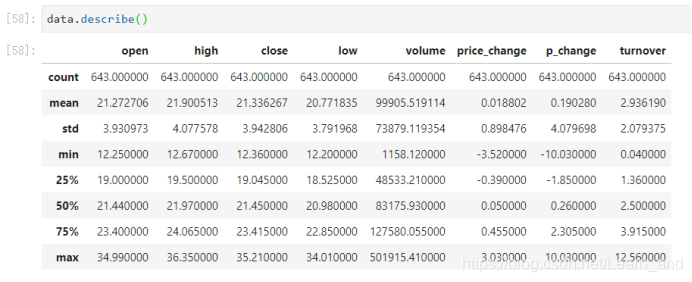
min最小值,max最大值,mean平均值,median中位数,var方差,std标准差结果。

- 对于单个函数去进行统计的时候,坐标轴还是按照这些默认为"columns"(axis=0,default),如果要对行"index"需要指定(axis=1)
注意:使用统计函数时0代表对列求结果,1代表对行求统计结果。
最大值:
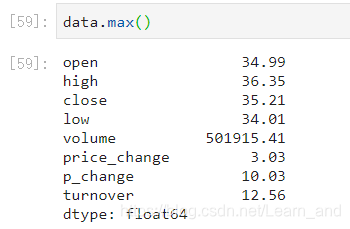
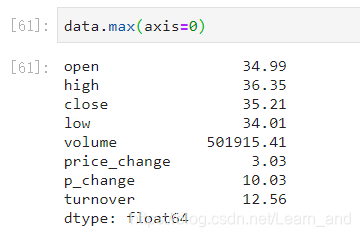
- 或是:
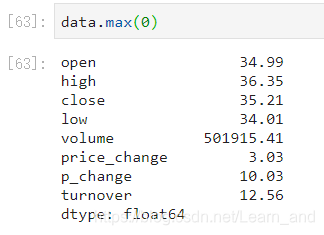
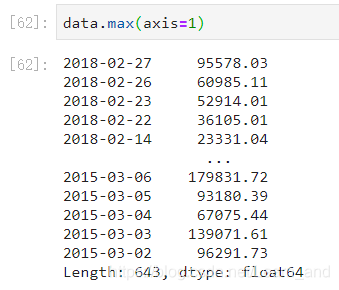
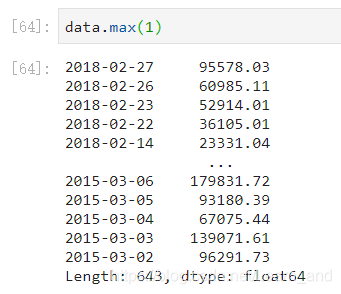
最小值:
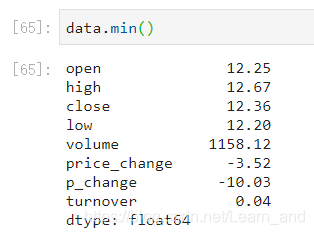
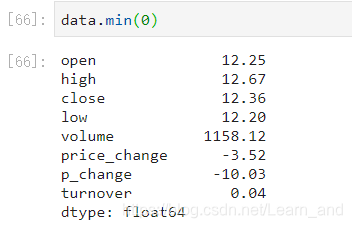
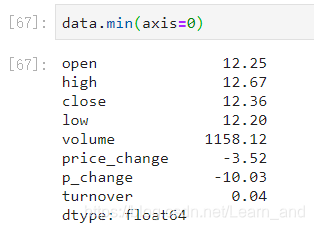
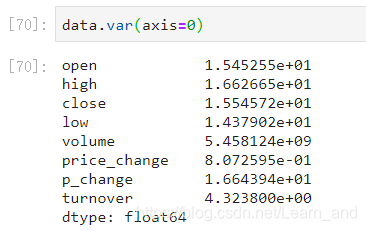
方差:
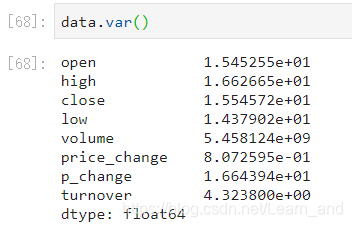
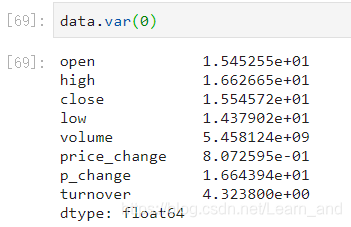
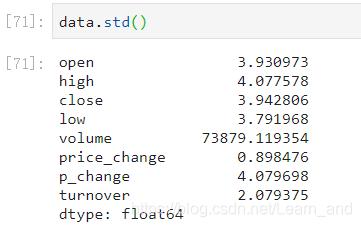
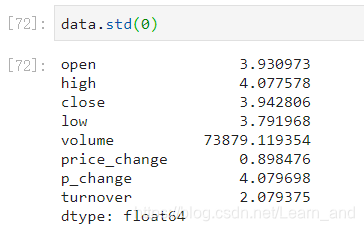
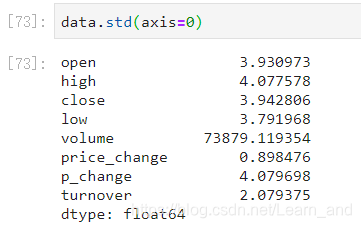
标准差:
平均值:
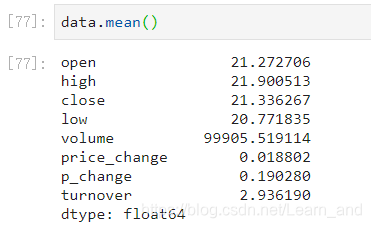
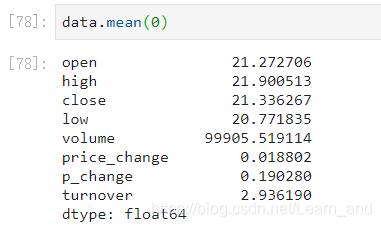
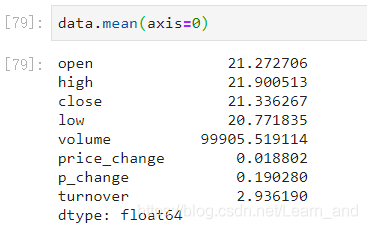
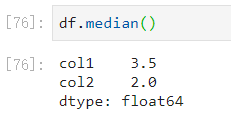
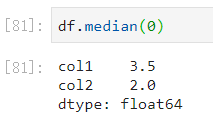
中位数:
- 中位数是将数据从小到大排列,在最中间的那个数为中位数。如果没有中间数,取中间两个数的平均值。
- df = pd.DataFrame({“col1”: [2, 3, 4, 5, 4, 2], “col2”: [0, 1, 2, 3, 4, 2]})
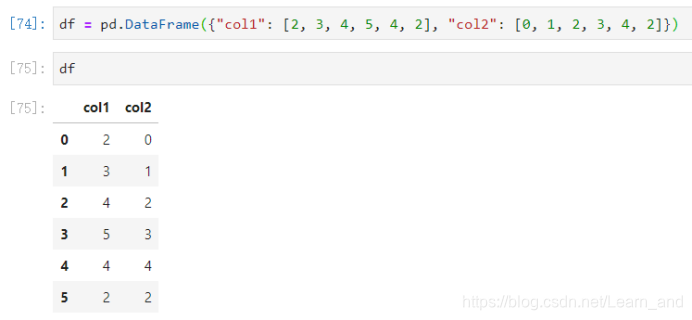

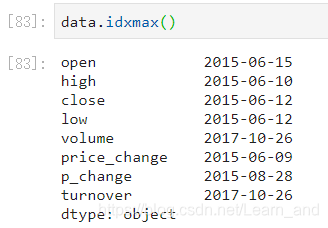
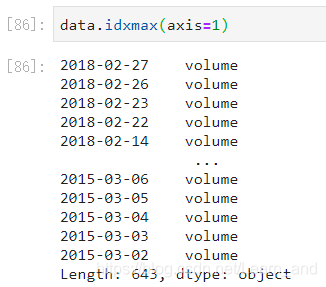
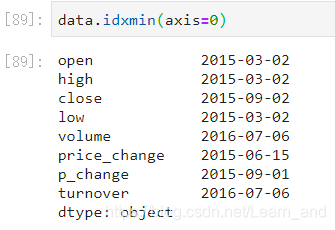
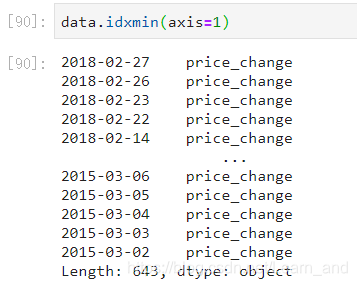
最大值的索引:
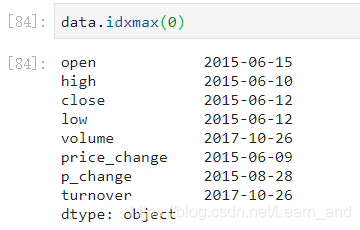
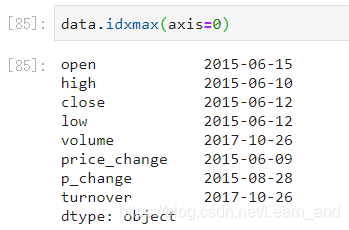
- 注意:等于1一般是没有意义的。
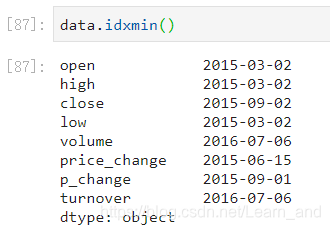
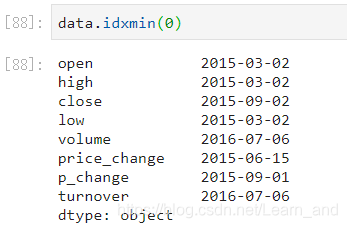
最小值的索引:
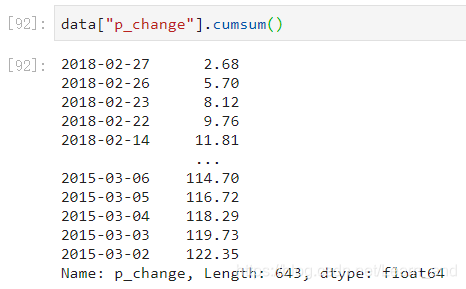
累计统计函数:

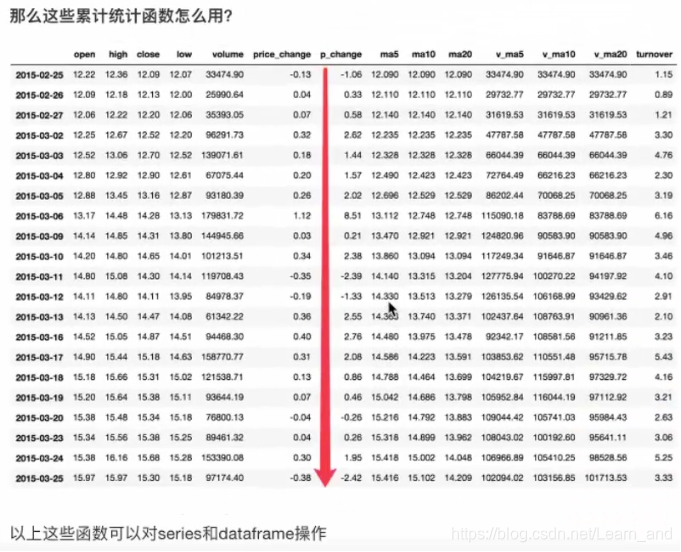
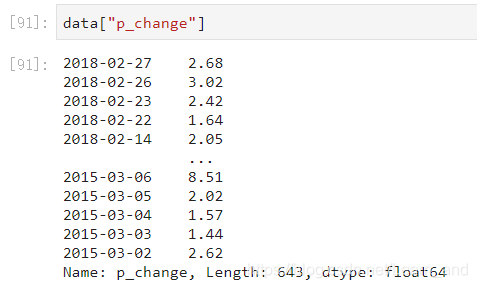
- 下面的5.70是上面的2.68+3.02得到的,下面的8.12是5.70+2.42得到的,依此类推。
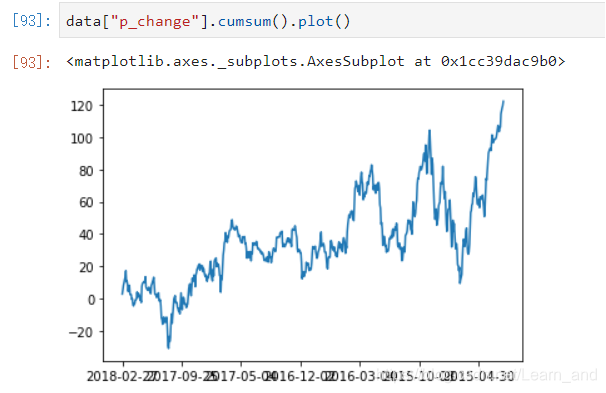
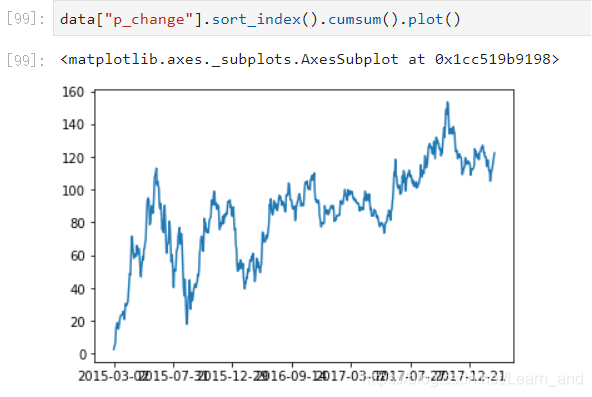
- 也可以下面这样:



自定义运算:

定义一个函数用于求出对每列进行最大值减去最小值:
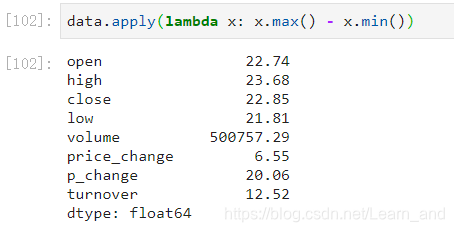
- 上面就对每一列进行了一个按最大值减去最小值的一个操作。

- 或者:

总结:


















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









