






需求
需要网页中的基因(Gene Symbol),一共371个。
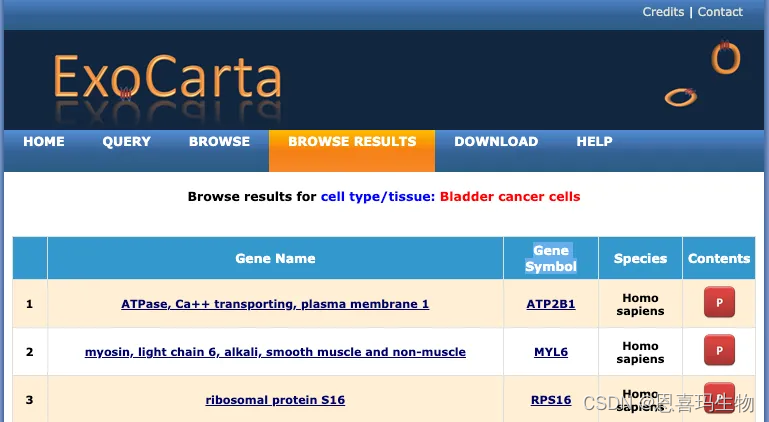
使用pandas读取网页表格
read_html 返回的是列表(a list of DataFrame)
import pandas as pd
import bioquest as bq
url = "http://exocarta.org/browse_results?org_name=&cont_type=&tissue=Bladder%20cancer%20cells&gene_symbol="
df = pd.read_html(url, encoding='utf-8',header=0,index_col=0)[0]
bq.tl.select(df,columns=["Gene Name","Gene Symbol","Species"]).to_csv("gene.csv",index=False)
没有学过爬虫,好奇是read_html怎么做到的,怎么解析网页的。
This function searches for <table> elements and only for <tr> and <th> rows and <td> elements within each <tr> or <th> element in the table. <td> stands for “table data”. This function attempts to properly handle colspan and rowspan attributes. If the function has a <thead> argument, it is used to construct the header, otherwise the function attempts to find the header within the body (by putting rows with only <th> elements into the header).
网页中的表格html语法大概如下
tr: 定义表格的行
th: 定义表格的表头
td: 定义表格单元
<table class="..." id="...">
<thead>
<tr>
<th>...</th>
</tr>
</thead>
<tbody>
<tr>
<td>...</td>
</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
...
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
</tbody>
</table>
所以read_html是依靠lxml等库根据HTML语法找到表格位置,并转换为DataFrame
Reference
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_html.html
https://zhuanlan.zhihu.com/p/51968879
https://blog.csdn.net/qq_40478273/article/details/103980288














 552
552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









