







🔗Github地址:https://github.com/Mengqi-Lei/SoftHGNN
🔗arXiv论文:https://arxiv.org/abs/2505.15325
文章目录
1. 摘要
视觉识别依赖于理解图像标记(image tokens)的语义内容以及它们之间复杂的交互关系。主流的自注意力(self-attention)方法虽然能够有效建模全局的成对关系,但难以捕捉真实世界场景中固有的高阶关联,同时也常常存在冗余计算的问题。超图(hypergraph)通过建模高阶交互关系扩展了传统图结构,为解决这些局限性提供了一种有前景的框架。然而,现有的超图神经网络(Hypergraph Neural Networks, HGNN)通常依赖于静态或人工构造的超边,这会导致超边数量过多且冗余,同时采用刚性的二元节点归属方式,忽略了视觉语义的连续性。
为了突破这些瓶颈,提出了软超图神经网络(Soft Hypergraph Neural Networks, SoftHGNN),扩展了超图计算理论,使其在视觉识别任务中真正高效且通用。SoftHGNN框架引入了软超边(soft hyperedges)的概念,其中,每个节点与超边的关联不再是硬性的二元分配,而是通过连续的归属权重来表达。 这种动态且可微的关联机制是通过可学习的语义原型向量实现的。通过计算token特征与这些原型之间的相似度,模型能够生成稀疏但语义丰富的超边。 这种设计允许节点以灵活的权重参与多个超边,更好地捕捉视觉语义的不确定性和渐变性。为了提高超边数量扩展时的计算效率,本文引入了一种仅激活 top-k 超边的稀疏超边选择机制,并结合负载均衡正则项(load-balancing regularizer),确保超边的合理利用和均衡分配。
在包含了3个典型视觉识别任务的5个公开数据集上的实验结果表明,SoftHGNN 能够高效建模高阶视觉关系,显著提升模型的性能表现。
2. 引言
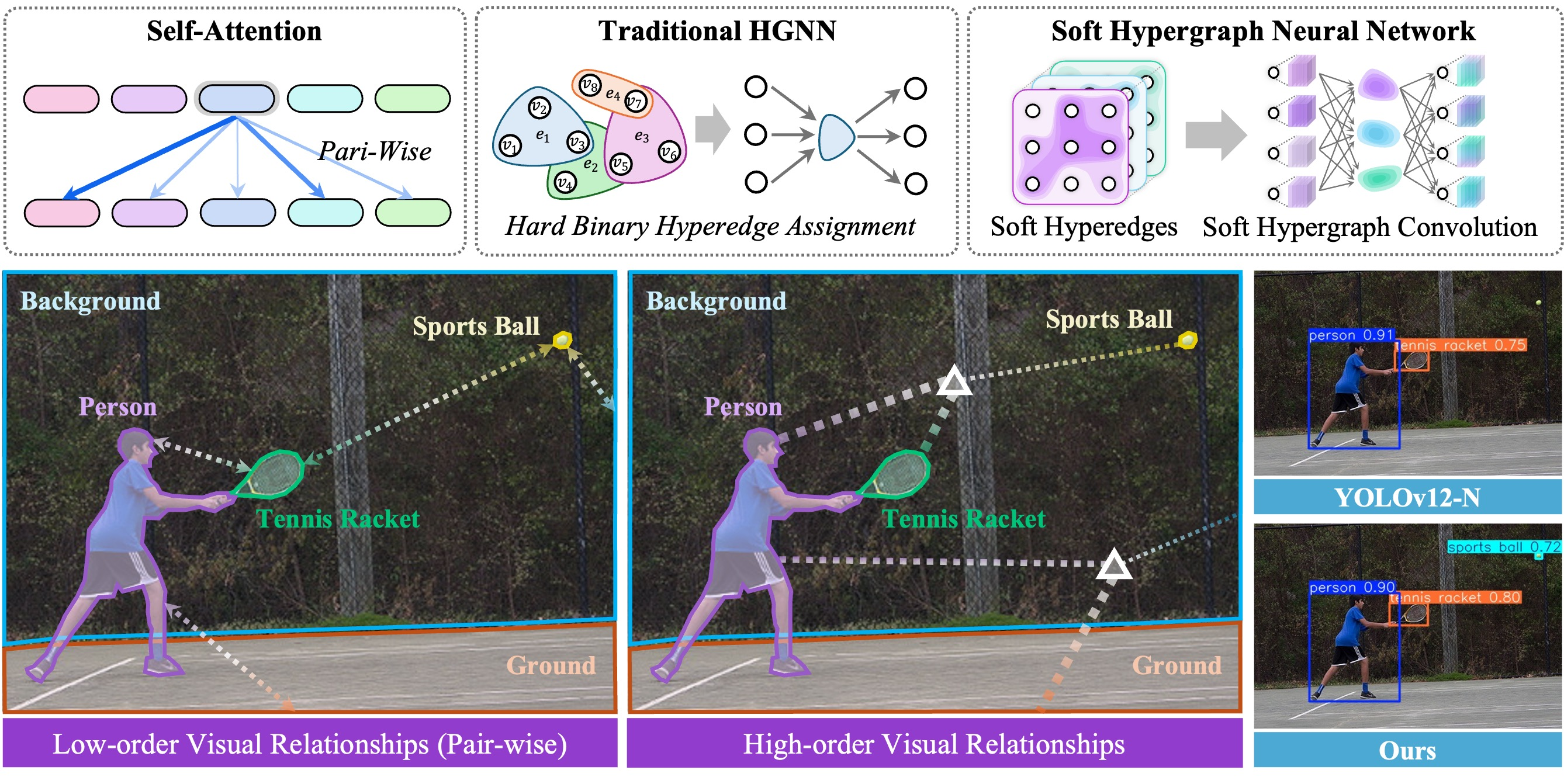
近年来,视觉识别领域取得了显著进展,这主要得益于以深度神经网络为基础的模型,尤其是卷积神经网络(CNN)和 Transformer 模型。CNN 擅长捕捉局部空间结构信息,而基于自注意力机制的 Transformer 模型则能有效地建模图像 Token 之间的全局关系。当前主流的范式,如 Vision Transformer 及其变体,通常将图像划分为一系列视觉 Token,并重点关注这些 Token 之间的两两关系。
尽管取得了令人瞩目的成果,但基于自注意力机制的视觉模型仍面临两大挑战。其一,自注意力天然构建了一个完全连接的语义图,主要关注 Token 之间的两两关系,难以有效地表达真实视觉场景中普遍存在的高阶关联。例如,“一个人持拍击球”的简单场景,涉及人、球拍和球三者的多方交互——这种高阶关联仅通过两两建模难以捕捉。其二,Transformer 常采用稠密的全局注意力,导致大量冗余计算、高昂的开销以及模型收敛困难。
为缓解上述问题,超图作为传统图结构的扩展,因其显式建模高阶关联的能力而受到广泛关注。超图神经网络通过超边将多个顶点的关系编码在一起,有望更好地捕捉视觉数据中的复杂语义交互。例如,已有研究已初步验证了 HGNN 在视觉任务中的有效性。然而,将现有主要面向网络型数据设计的 HGNN 直接应用于视觉场景,会遇到两个关键瓶颈:
- 冗余超边。传统超图构建常基于 k 近邻或 ε‑球准则,为每个顶点生成一个超边。由于视觉任务中的顶点数(通常为 B×H×W,其中 B 是批量大小)极大,这种方法会产生大量远超实际有意义关联的超边,导致严重的计算冗余和效率低下。
- 硬超边的局限。已有 HGNN 多采用硬二值关联,要么将顶点完全包含于超边中,要么完全排除。这种刚性划分忽略了视觉语义的连续性与模糊性。例如在部分遮挡场景中,被遮挡区域应以较低权重参与相关超边,而非被完全剔除;而硬超边往往引入顶点冗余或覆盖不足,严重削弱模型性能。
针对上述瓶颈,我们提出了 Soft Hypergraph Neural Network(SoftHGNN),将超图计算方法扩展为既通用又高效的视觉识别框架。
- 核心创新:采用可微分的“软”顶点参与机制,以可学习的超边原型向量替代静态硬超边。模型通过度量视觉 Token 与原型向量的相似度,动态生成语义富集的软超边。每条超边都以可学习的连续权重,柔性地连接所有顶点,自适应地建模视觉特征中的抽象高阶关联。
- 计算效率:仅需维持常规模型规模的软超边集合,就能显著减少计算量,相较传统 HGNN 大幅提升效率。
- 模块化特性:SoftHGNN 可作为“即插即用”模块,方便地集成至各类视觉识别模型,填补现有方法在高阶关联建模方面的空白,从而带来明显的性能提升。
在某些复杂场景中,为了更全面地捕捉丰富的视觉语义关联,可能需要更多候选的软超边。但通常只有其中一小部分对识别任务至关重要。为此,我们引入了 稀疏超边选择机制:预定义较大规模的软超边集合,但仅选取最关键的 k 条进行消息传递;同时设计了 负载均衡正则化,防止超边过度活跃或长期未被选中,确保超边利用的充分与均衡。
为了验证方法的泛化与有效性,我们在五个主流数据集——CIFAR‑10、CIFAR‑100、ShanghaiTech Part‑A、ShanghaiTech Part‑B 以及 MS COCO 上,针对图像分类、群体计数与目标检测三类典型视觉任务进行了大规模实验。结果表明,SoftHGNN 系列方法均能高效准确地捕捉视觉场景中的高阶语义关联,显著提升各项任务性能。
主要贡献:
- 提出 Soft Hypergraph Neural Network(SoftHGNN),通过特征驱动的软超边机制,自适应地刻画视觉特征中的抽象高阶语义关联;
- 设计稀疏超边选择策略,扩展 SoftHGNN 的超边容量同时保持高计算效率,并引入负载均衡正则化以避免超边选择失衡;
- 在五个数据集、三类主流视觉识别任务上进行了大规模实验,充分证明了方法在捕捉高阶语义关联方面的精度与效率优势。
3. 传统超图基础理论
A. 超图
超图是对普通图的一种扩展,用于显式地刻画数据中的高阶关系。形式上,超图可表示为 G = ( V , E ) G=(V,E) G=(V,E),其中 V V V 是顶点集合, E E E 是超边集合。与传统图中每条边只能连接两个顶点不同,超图中的每条超边可以同时连接任意数量的顶点,因此能够自然地捕捉多个顶点之间的复杂高阶关联。超图的结构通常由一个关联矩阵(或称为顶点–超边指示矩阵) H ∈ R ∣ V ∣ × ∣ E ∣ H\in\mathbb{R}^{|V|\times|E|} H∈R∣V∣×∣E∣ 来描述:若顶点 v v v 属于超边 e e e,则 H v , e = 1 H_{v,e}=1 Hv,e=1,否则 H v , e = 0 H_{v,e}=0 Hv,e=0。
B. 超图神经网络
超图神经网络(HGNN)是一类将神经网络与超图结构相结合的表示学习方法,其核心是在超图上进行卷积(或消息传递),以捕捉高阶语义关联。一次典型的超图卷积包含两个阶段的聚合与散播:
- 顶点→超边 聚合:将所有顶点的特征按超边关系聚合到超边上;
- 超边→顶点 散播:再将超边上的信息反馈到顶点上。
记 X ( t ) ∈ R ∣ V ∣ × d X^{(t)}\in\mathbb{R}^{|V|\times d} X(t)∈R∣V∣×d 为第 t t t 层的顶点特征矩阵,超图卷积可写作:
X ( t + 1 ) = σ ( D v − 1 H W D e − 1 H ⊤ X ( t ) Θ ( t ) ) , X^{(t+1)} = \sigma\bigl(D_v^{-1}\,H\,W\,D_e^{-1}\,H^\top\,X^{(t)}\,\Theta^{(t)}\bigr), X(t+1)=σ(Dv−1HWDe−1H⊤X(t)Θ(t)),
其中
-
H H H 是超图的关联矩阵;
-
W ∈ R ∣ E ∣ × ∣ E ∣ W\in\mathbb{R}^{|E|\times|E|} W∈R∣E∣×∣E∣ 为超边权重矩阵,通常取为单位矩阵;
-
Θ ( t ) \Theta^{(t)} Θ(t) 是第 t t t 层的可学习变换矩阵;
-
σ ( ⋅ ) \sigma(\cdot) σ(⋅) 表示非线性激活函数;
-
D v D_v Dv 与 D e D_e De 分别是顶点和超边的度矩阵,其对角元定义为
( D v ) i , i = ∑ e ∈ E H i , e , ( D e ) j , j = ∑ v ∈ V H v , j . (D_v)_{i,i}=\sum_{e\in E}H_{i,e},\quad (D_e)_{j,j}=\sum_{v\in V}H_{v,j}. (Dv)i,i=e∈E∑Hi,e,(De)j,j=v∈V∑Hv,j.
通过上述两步信息传递,HGNN 能够将多个顶点间的高阶关系融入到顶点表征中,从而提升模型的表达能力。
C. 复杂度分析
尽管超图及其神经网络在理论上能够有效建模高阶关联,但在大规模数据上其计算开销也十分可观。
-
超图构建的复杂度
- k‑最近邻(k‑NN)方法:需计算所有顶点对之间的距离,复杂度约为 O ( N 2 D ) O(N^2D) O(N2D),其中 N N N 是顶点数, D D D 是特征维度。
- ε‑球方法:同样需检查每对顶点的距离是否小于阈值 ε,复杂度亦为 O ( N 2 D ) O(N^2D) O(N2D)。
无论哪种方法,最主要的瓶颈都在于成对距离计算,导致对于大规模顶点集的开销呈二次增长。
-
超图神经网络的复杂度
在一次超图卷积中,主要计算来自以下两个矩阵乘法:- H ⊤ X H^\top X H⊤X:复杂度约为 O ( N M D ) O(NMD) O(NMD),其中 M = ∣ E ∣ M=|E| M=∣E∣;
- H F e H\,F_e HFe:同样为 O ( N M D ) O(NMD) O(NMD)。
综合而言,一次卷积的总体复杂度为 O ( N M D ) O(NMD) O(NMD)。在典型场景下,若超边数 M M M 与顶点数 N N N 同阶,则整体复杂度可视为 O ( N 2 D ) O(N^2D) O(N2D),较普通图卷积或自注意力的二次复杂度并无显著优势。
上述分析表明,传统超图方法在大规模视觉数据上存在明显的效率瓶颈,亟需设计更高效的建图与卷积策略。
4. 方法论
A. 软超图的定义
传统的超图通过预定义的规则(如基于几何距离或相似度的阈值)构建超边,使得顶点与超边之间的关系是“全有”或“全无”的二元划分,难以刻画视觉数据中普遍存在的模糊与连续性。软超图则认为,在每一个高阶关系中,所有顶点都以不同程度参与其中,从而形成连续且可微的“软超边”。
形式上,软超图可表示为三元组
G = { X , A } , G = \{X, A\}, G={X,A},
其中 X ∈ R N × D X \in \mathbb{R}^{N\times D} X∈RN×D 为顶点特征矩阵, N N N 表示顶点数(即图像中的令牌数量), D D D 为特征维度; A ∈ [ 0 , 1 ] N × M A \in [0,1]^{N\times M} A∈[0,1]N×M 为参与矩阵,其元素 A i , j A_{i,j} Ai,j 反映顶点 v i v_i vi 在超边 e j e_j ej 中的参与程度。该设计既能更细腻地捕捉顶点—超边关系的连续性,也能通过可学习的方式动态生成超边,适应不同样本的全局语义特征。
B. SoftHGNN 概述
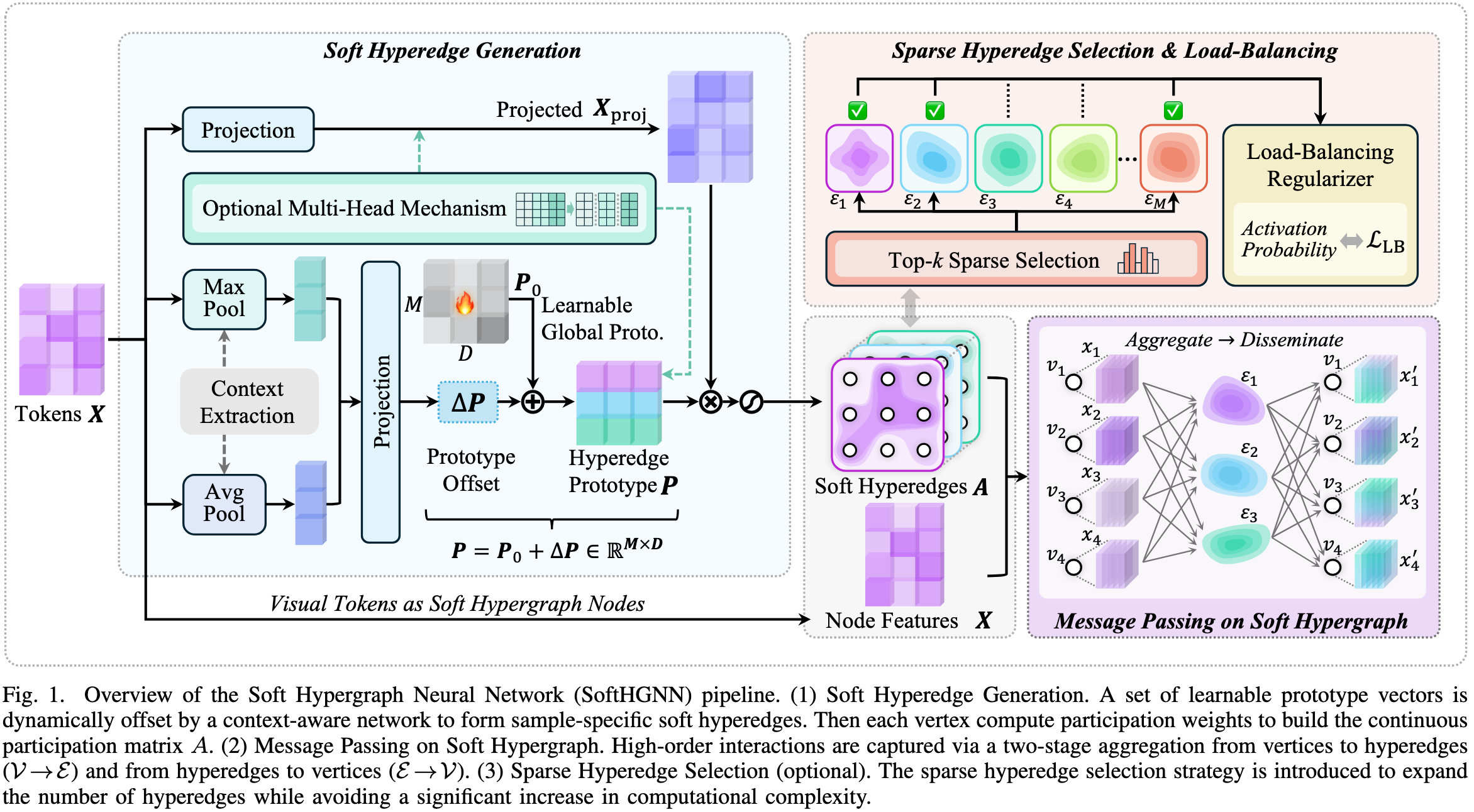
基于软超图的思想,我们提出了 Soft Hypergraph Neural Network(SoftHGNN),作为一套可插拔的高阶关系建模模块,能够嵌入任意视觉识别网络以提升性能。整体架构由三个核心部分组成:
- 软超边生成:利用一组可学习的超边原型向量,并通过上下文感知网络根据全局特征生成样本专属的超边原型;各顶点通过与这些超边原型的语义距离计算参与权重,形成连续的参与矩阵 A A A。
- 软超图消息传递:在构建好的软超图上,先将顶点信息聚合到超边,再将超边信息反向传播到顶点,以捕捉高阶交互。
- 稀疏软超边选择(可选):在复杂场景中,先生成大量候选软超边,再通过稀疏选择策略仅保留最重要的部分,并配以负载均衡正则,防止部分超边过度或不足激活。
SoftHGNN 整体框架如图 1 所示,后续将对各模块做详细阐述。
C. 软超边生成
该模块根据输入顶点特征 X X X 动态构建参与矩阵 A A A,包括三步:
-
动态超边原型生成
预定义一组全局共享的可学习超边原型 P 0 ∈ R M × D P_0 \in \mathbb{R}^{M\times D} P0∈RM×D,并对每个样本提取全局上下文特征 f g l o b a l f_{\mathrm{global}} fglobal:对顶点特征矩阵 X ∈ R N × D X \in \mathbb{R}^{N\times D} X∈RN×D 分别做平均和最大池化,再拼接得到 f g l o b a l ∈ R 2 D f_{\mathrm{global}}\in\mathbb{R}^{2D} fglobal∈R2D。上下文感知网络 ϕ \phi ϕ 将其映射为偏移量 Δ P \Delta P ΔP,从而得到样本专属原型P = P 0 + Δ P . P = P_0 + \Delta P. P=P0+ΔP.
该设计既保留了全局共享先验,又注入了样本级别的上下文信息,有助于准确捕捉高阶语义。
-
顶点特征预投影
为增强语义表现,将顶点特征线性变换到新空间X p r o j = W p r e X , W p r e ∈ R D × D , X_{\mathrm{proj}} = W_{\mathrm{pre}}\,X,\quad W_{\mathrm{pre}}\in\mathbb{R}^{D\times D}, Xproj=WpreX,Wpre∈RD×D,
并拆分为 h h h 个头,每个头维度为 D h e a d = D / h D_{\mathrm{head}} = D/h Dhead=D/h,以多头机制捕捉多样化子空间的高阶关系。
-
参与矩阵生成
在每个头内,计算顶点与超边原型的点积相似度并除以 D h e a d \sqrt{D_{\mathrm{head}}} Dhead 以稳定梯度,得到相似度矩阵S ( τ ) = X h e a d s ( τ ) ( P h e a d s ( τ ) ) ⊤ D h e a d ∈ R N × M , S^{(\tau)} = \frac{X^{(\tau)}_{\mathrm{heads}}\,(P^{(\tau)}_{\mathrm{heads}})^\top}{\sqrt{D_{\mathrm{head}}}}\in\mathbb{R}^{N\times M}, S(τ)=DheadXheads(τ)(Pheads(τ))⊤∈RN×M,
然后对所有头求平均并对每行做 Softmax,得到最终连续可微的参与矩阵
A i , j = exp ( S i , j ) ∑ k = 1 M exp ( S i , k ) , i = 1 , … , N , j = 1 , … , M . A_{i,j} = \frac{\exp(S_{i,j})}{\sum_{k=1}^M\exp(S_{i,k})},\quad i=1,\dots,N,\;j=1,\dots,M. Ai,j=∑k=1Mexp(Si,k)exp(Si,j),i=1,…,N,j=1,…,M.
这一机制使每个顶点可根据语义相似度,以不同程度参与各软超边,实现更细粒度的高阶关联建模。
D. 软超图上的消息传递
在构建的软超图上,通过双阶段聚合与散播捕捉高阶交互:
-
从顶点到软超边的聚合
对超边 e m e_m em,聚合所有顶点的特征加权和:f m = ∑ i = 1 N A i , m x i , x i ∈ R D , f_m = \sum_{i=1}^N A_{i,m}\,x_i,\quad x_i\in\mathbb{R}^D, fm=i=1∑NAi,mxi,xi∈RD,
并通过线性变换与非线性激活进一步映射为超边特征
f m ′ = σ ( W e f m ) . f'_m = \sigma\bigl(W_e\,f_m\bigr). fm′=σ(Wefm).
-
从软超边到顶点的信息散播
对顶点 v i v_i vi,将所有软超边信息汇聚回顶点:x ~ i = ∑ m = 1 M A i , m f m ′ , x i ′ = σ ( W n x ~ i ) , \tilde x_i = \sum_{m=1}^M A_{i,m}\,f'_m, \quad x'_i = \sigma\bigl(W_n\,\tilde x_i\bigr), x~i=m=1∑MAi,mfm′,xi′=σ(Wnx~i),
其中 W e , W n W_e, W_n We,Wn 分别为超边和顶点的变换矩阵, σ \sigma σ 为激活函数。
以上过程可合并为矩阵形式:
X ′ = σ ( A σ ( A ⊤ X W e ⊤ ) W n ⊤ ) . X' = \sigma\Bigl(A\,\sigma\bigl(A^\top XW_e^\top\bigr)\,W_n^\top\Bigr). X′=σ(Aσ(A⊤XWe⊤)Wn⊤).
E. 稀疏软超边选择与负载均衡
在复杂场景中,需生成更多软超边以覆盖丰富高阶关联,但全量参与会带来冗余与计算负担。为此:
-
稀疏超边选择策略
将 M M M 条超边分为固定超边集 E f i x e d E_{\mathrm{fixed}} Efixed(始终激活)和动态超边集 E d y n E_{\mathrm{dyn}} Edyn。对每条动态超边 e j e_j ej 计算其全局激活分数g j = ∑ i = 1 N S i , j d y n , j = 1 , … , M d y n , g_j = \sum_{i=1}^N S^{\mathrm{dyn}}_{i,j},\quad j=1,\dots,M_{\mathrm{dyn}}, gj=i=1∑NSi,jdyn,j=1,…,Mdyn,
然后选取得分最高的前 k k k 条超边与固定集并集,得到新的参与矩阵,最后再做 Softmax 归一化,以保持可微。
-
负载均衡正则
为防止部分超边被过度或不足激活,记录前 T T T 次前向传播中每条动态超边的选中情况,计算其经验激活概率 p j p_j pj,并与理想均匀分布 p t a r g e t = k / M d y n p_{\mathrm{target}}=k/M_{\mathrm{dyn}} ptarget=k/Mdyn 做均方差,构建正则项L L B = 1 M d y n ∑ j = 1 M d y n ( p j − p t a r g e t ) 2 , \mathcal{L}_{\mathrm{LB}} = \frac{1}{M_{\mathrm{dyn}}}\sum_{j=1}^{M_{\mathrm{dyn}}}(p_j - p_{\mathrm{target}})^2, LLB=Mdyn1j=1∑Mdyn(pj−ptarget)2,
以鼓励所有超边均匀贡献。
F. SoftHGNN 的复杂度分析
为了评估可扩展性,从理论角度分析 SoftHGNN 各阶段的计算复杂度:
-
软超边生成阶段
- 超边原型偏移预测:依赖全局上下文向量,复杂度约为 O ( N D ) O(ND) O(ND)。
- 多头投影与相似度计算:每个头需计算点积相似度,约需 O ( N × M × ( D / h ) ) O(N\times M\times (D/h)) O(N×M×(D/h)) 次运算,汇总后总计 O ( N M D ) O(NMD) O(NMD)。
-
消息传递阶段
- 顶点到超边聚合:矩阵乘 A ⊤ X A^\top X A⊤X,复杂度 O ( N M D ) O(NMD) O(NMD)。
- 超边到顶点散播:矩阵乘 A F e ′ A\,F'_e AFe′,同样为 O ( N M D ) O(NMD) O(NMD)。
综合来看,SoftHGNN 的主要计算成本为 O ( N M D ) O(NMD) O(NMD)。在常见设置下,超边数 M M M (通常为一个较小的常数,如4,8,16)和特征维度 D D D 都可视为常数,因此 SoftHGNN 难以被视为线性 O ( N ) O(N) O(N) 增长,显著优于自注意力或传统 HGNN 的二次增长 O ( N 2 ) O(N^2) O(N2)。
5. 实验结果
A. 任务与数据集
为验证所提方法的优越性与通用性,我们在三类典型的视觉识别任务上进行了大规模实验:图像分类、群体计数和目标检测。共使用五个广泛应用的数据集:
- 图像分类:采用 CIFAR‑10 和 CIFAR‑100 数据集。CIFAR‑10 包含 60,000 张彩色图像,分为 10 类,每类 6,000 张;其中 5,000 张用于训练,1,000 张用于测试。CIFAR‑100 则扩展为 100 类,每类包含 600 张图像,训练集为 500 张,测试集为 100 张。
- 群体计数:使用 ShanghaiTech Part‑A 和 Part‑B 数据集。Part‑A 包含 482 张以稠密人群为主的图像,其中 300 张用于训练,182 张用于测试;Part‑B 包含 716 张较为稀疏的人群图像,训练集 400 张,测试集 316 张。
- 目标检测:选用 MS COCO 数据集,包含超过 328,000 张图像,涵盖 80 个物体类别,并提供边界框和实例分割掩码,是目标检测领域的标杆数据集。
B. 评估指标
- 图像分类:采用分类准确率(Accuracy)作为主要评价指标。
- 群体计数:使用平均绝对误差(MAE)和均方误差(MSE)衡量计数精度。
- 目标检测:采用 AP50(IoU 阈值为 0.5 时的平均精度)和 AP50:95(IoU 从 0.5 到 0.95、步长 0.05 时的平均精度)评估检测性能;同时报告模型的浮点运算量(FLOPs)、延迟(Latency)和参数量。
C. 实验设置
所有实验均在 NVIDIA RTX 4090 GPU 上进行:图像分类与群体计数任务使用单卡训练,目标检测任务并行使用 8 卡。
- 基础模型:图像分类以 Vision Transformer 为基线;群体计数以 Transformer 基础的 CCTrans 为基线;目标检测则选用 YOLO11 和 YOLOv12。
- 超参数:学习率固定为 1×10–4,优化器为 Adam,采用余弦退火调度;数据增强包括随机裁剪、随机缩放和水平翻转。
- SoftHGNN 设置:默认为 8 个注意力头、8 条软超边;在稀疏超边选择版本(SoftHGNN‑SeS)中,固定超边数为 16,动态候选超边为 32,稀疏率 50%。
D. 定量结果
1) 图像分类
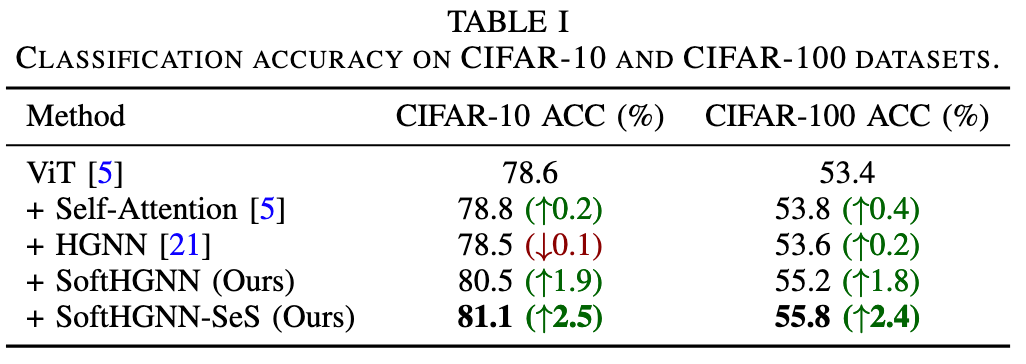
在 CIFAR‑10 上,集成 Self‑Attention 模块并未带来显著变化;传统 HGNN 略有波动;而 SoftHGNN 分别比基线提升约 1.9% 的准确率;引入稀疏超边选择后(SoftHGNN‑SeS),进一步提升至约 2.5%。在 CIFAR‑100 上,SoftHGNN 和 SoftHGNN‑SeS 的提升幅度分别约为 1.8% 和 2.4%。
2) 群体计数
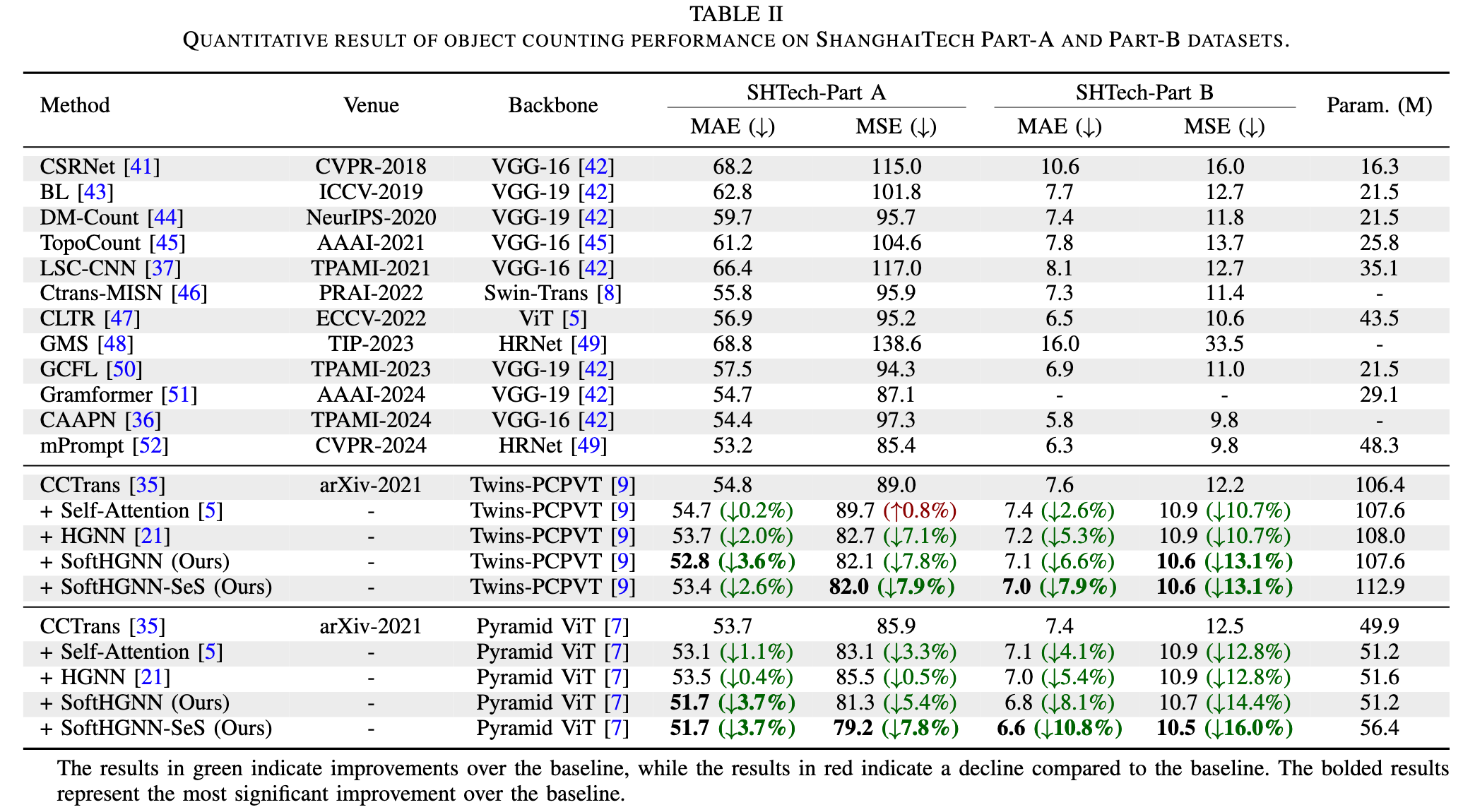
在 ShanghaiTech Part‑A 和 Part‑B 上,使用 Twins‑PCPVT 骨干网时,SoftHGNN 系列在 Part‑A 的 MAE 和 MSE 分别提升约 3.6% 和 7.9%,在 Part‑B 的 MAE 和 MSE 分别提升约 7.9% 和 13.1%。改用 PVT 骨干网时,提升幅度更大:Part‑A 的 MAE 与 MSE 分别提升至约 3.7% 和 7.8%,Part‑B 分别提升至约 10.8% 和 16.0%。尽管性能显著提升,SoftHGNN 仅增加约 1M 参数,SoftHGNN‑SeS 增加约 6M 参数。
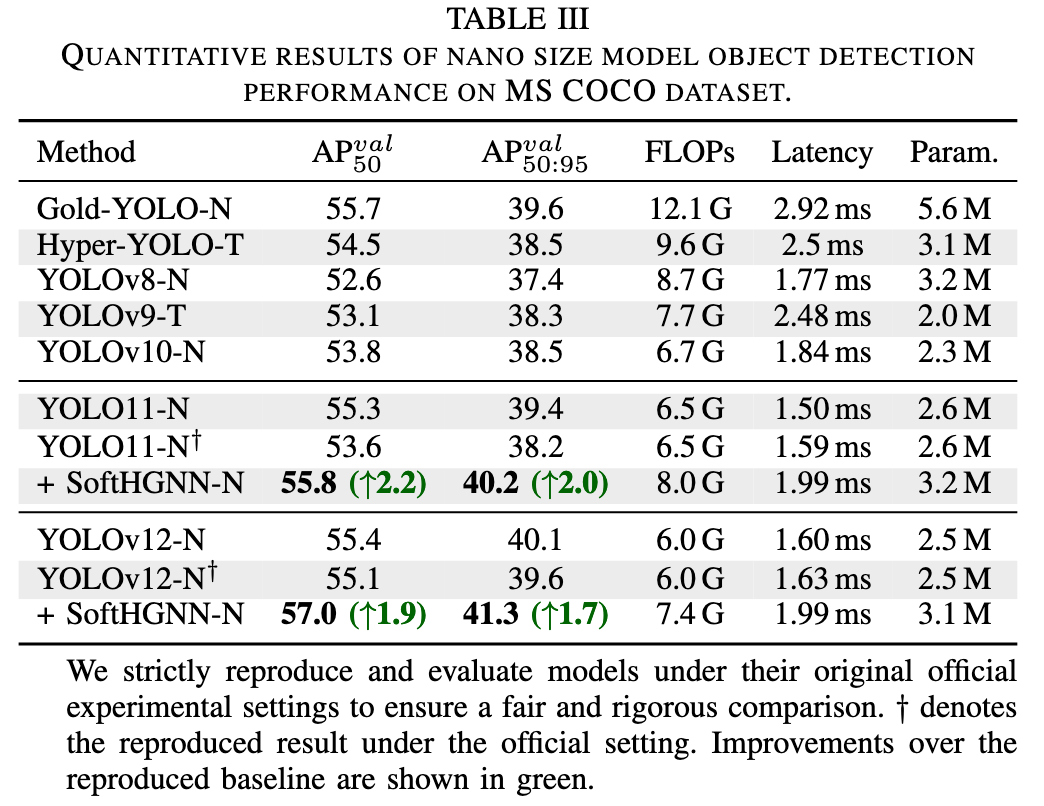
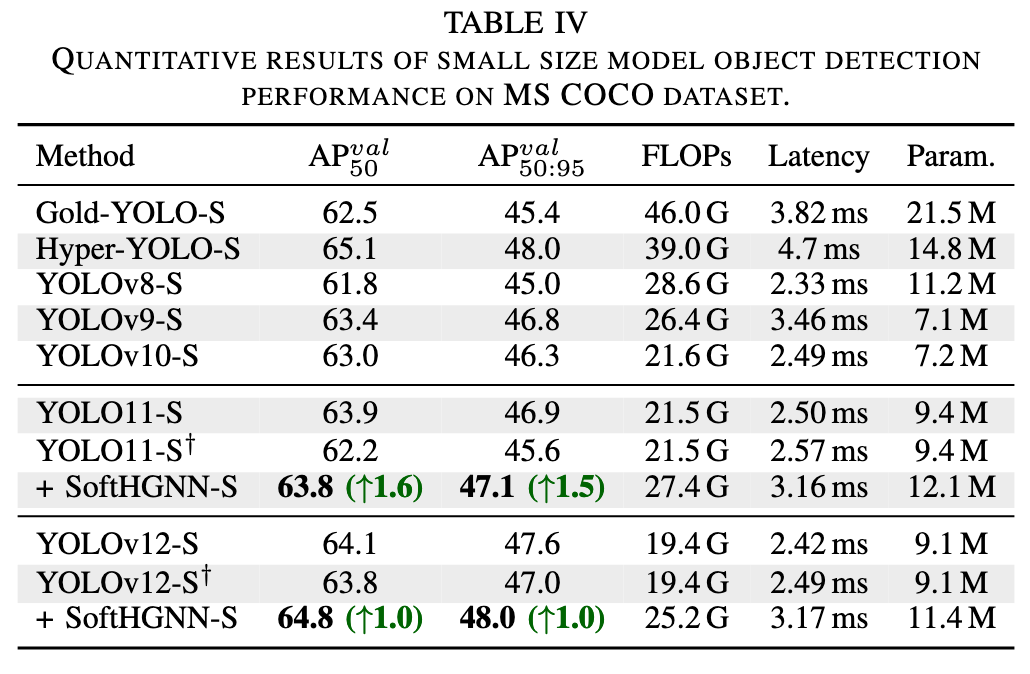
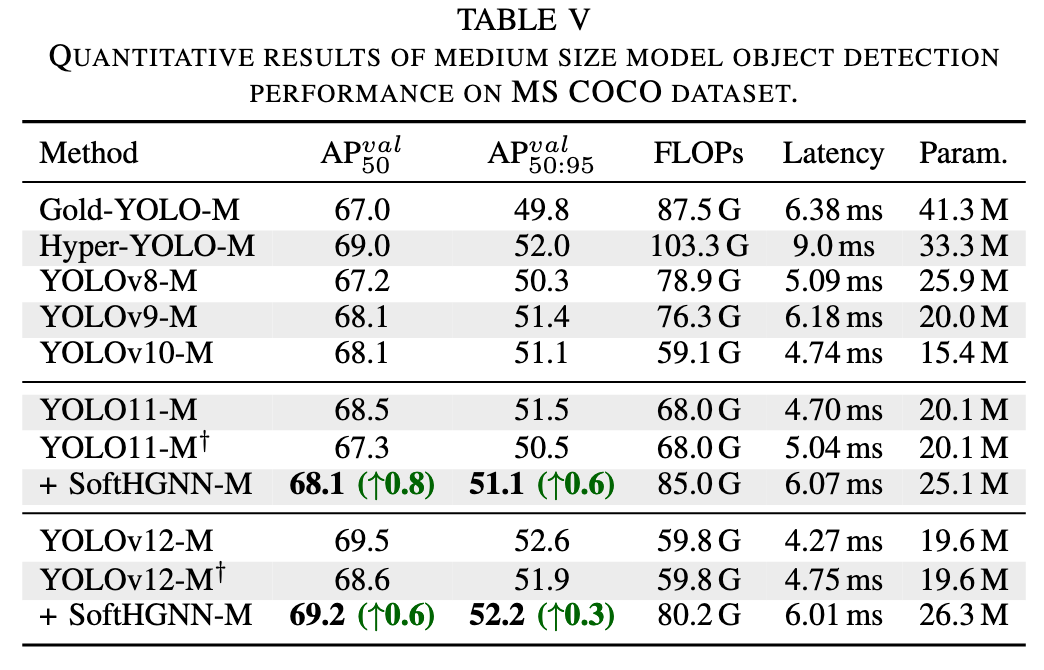
3) 目标检测
在 MS COCO 上,我们对 YOLO11 和 YOLOv12 的 Nano、Small、Medium 三种规模模型分别进行了实验:
- Nano 规模:SoftHGNN‑N 相较原版分别在 AP50 上提升约 2.2% 和 1.9%,在 AP50:95 上提升约 2.0% 和 1.7%。
- Small 规模:SoftHGNN‑S 在 AP50 上分别提升约 1.6% 和 1.0%,AP50:95 上分别提升约 1.5% 和 1.0%。
- Medium 规模:SoftHGNN‑M 在 AP50 上分别提升约 0.8% 和 0.6%,AP50:95 上分别提升约 0.6% 和 0.3%。
同时,我们将 SoftHGNN 基于卷积分支的特征融合与分发模块(Fuse to SoftHGNN)插入 Detection Neck,充分利用软超边对多尺度特征的高阶关联建模。
E. 消融研究
1) 超参数敏感性
以 ShanghaiTech Part‑A 为例,固定软超边数为 8,测试注意力头数在 1、4、8、16 时的 MAE 与 MSE,结果在 4 或 8 头时表现最佳,最佳配置为 8 头;随后固定头数为 8,测试软超边数为 4、8、16、32,结果在 8 或 16 条时效果较优,以 8 条超边最为理想。过多超边并不总能提升性能,可能因过度冗余或对次要关联的过拟合所致。

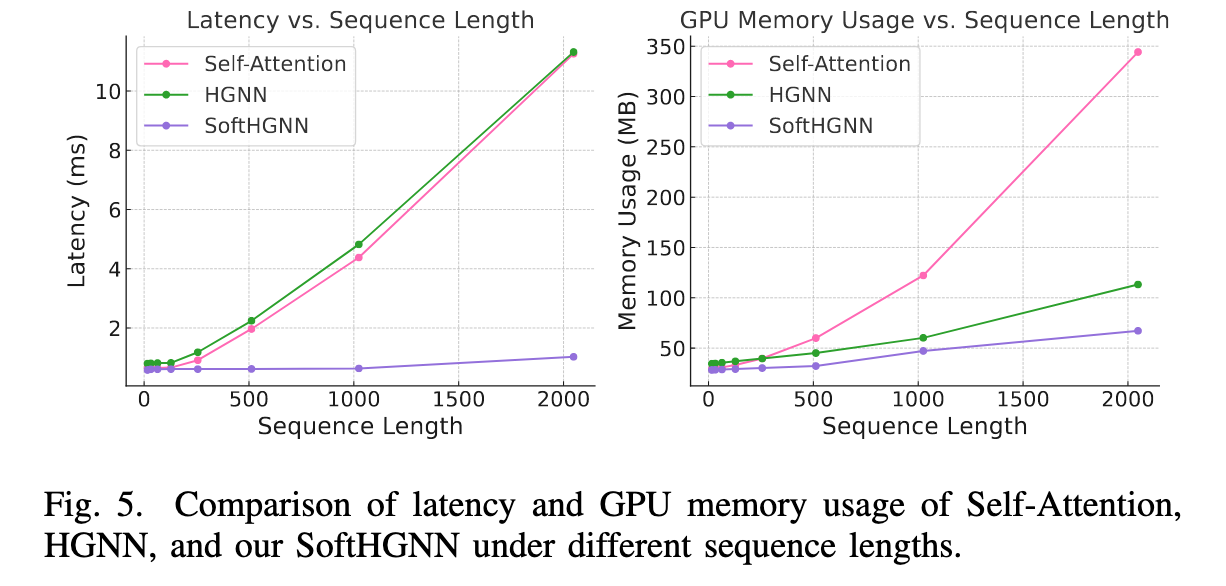
2) 计算效率
对比 Self‑Attention、传统 HGNN 与 SoftHGNN 在不同序列长度下的延迟与显存占用,结果表明随着序列长度增加,SoftHGNN 的延迟与显存占用呈线性增长,而前两者表现为二次增长,验证了 SoftHGNN 在长序列场景下的计算效率优势。

















 5037
5037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









