







重要的事情说三遍:
函数允许将程序结构化为执行单个任务的代码段。
在 C++ 中,函数是一组语句,赋予一个名字,可以在程序的某个位置调用它。定义函数的最常见语法是:
type name (parameter1, parameter2, ...) { statements }
其中:
type是函数返回值的类型。name是函数调用时使用的标识符。parameters(需要多少参数就写多少):每个参数由类型和标识符组成,每个参数之间用逗号分隔。每个参数看起来就像一个常规的变量声明(例如:int x),实际上在函数中充当局部变量。参数的目的是允许将参数从调用位置传递到函数。statements是函数体。它是一组被大括号 { } 包围的语句,指定函数的实际操作。
让我们来看一个例子:
// 函数示例
#include <iostream>
using namespace std;
int addition (int a, int b)
{
int r;
r = a + b;
return r;
}
int main ()
{
int z;
z = addition (5, 3);
cout << "结果是 " << z;
}
这个程序分为两个函数:addition 和 main。记住,无论它们定义的顺序如何,C++ 程序总是从 main 开始调用。实际上,main 是唯一自动调用的函数,其他任何函数的代码仅在从 main 调用时才会执行(直接或间接)。
在上面的例子中,main 以声明 int 类型的变量 z 开始,然后立即执行第一个函数调用:调用 addition。函数调用的结构与其声明非常相似。在上面的例子中,对 addition 的调用可以与之前几行定义进行比较:
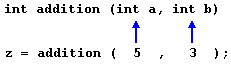
函数声明中的参数与函数调用中传递的参数有明确的对应关系。调用将两个值 5 和 3 传递给函数;它们对应于函数 addition 中声明的参数 a 和 b。
在从 main 中调用函数的那一刻,控制权传递给函数 addition:此时,main 的执行停止,直到 addition 函数结束后才恢复。在函数调用的那一刻,两个参数(5 和 3)的值被复制到函数内部的局部变量 int a 和 int b 中。
然后,在 addition 中,声明了另一个局部变量(int r),并通过表达式 r = a + b 将 a 加 b 的结果赋给 r;在这种情况下,a 为 5 且 b 为 3,因此 8 被赋给 r。
函数中的最后一条语句:
return r;
结束了函数 addition,并将控制权返回到调用该函数的点;在这种情况下,返回到函数 main。在此精确时刻,程序在 main 中恢复其过程,返回到由于调用 addition 而被中断的点。同时,由于 addition 有一个返回类型,该调用被评估为具有一个值,这个值是结束 addition 的返回语句中指定的值:在这种情况下,是局部变量 r 的值,而在返回语句时 r 的值为 8。

因此,调用 addition 是一个带有函数返回值的表达式,在这种情况下,该值 8 被赋给 z。就好像整个函数调用(addition(5,3))被其返回的值(即 8)替换一样。
然后 main 只需调用:
cout << "结果是 " << z;
一个函数实际上可以在程序中被多次调用,并且其参数不仅限于字面量:
// 函数示例
#include <iostream>
using namespace std;
int subtraction (int a, int b)
{
int r;
r = a - b;
return r;
}
int main ()
{
int x = 5, y = 3, z;
z = subtraction (7, 2);
cout << "第一个结果是 " << z << '\n';
cout << "第二个结果是 " << subtraction (7, 2) << '\n';
cout << "第三个结果是 " << subtraction (x, y) << '\n';
z = 4 + subtraction (x, y);
cout << "第四个结果是 " << z << '\n';
}
类似于上一个例子中的 addition 函数,这个例子定义了一个 subtraction 函数,该函数仅返回其两个参数之间的差值。这次,main 多次调用这个函数,展示了调用函数的更多可能方式。
让我们检查每个调用,记住每个函数调用本身都是一个表达式,它的值是返回的值。你可以将其视为函数调用本身被其返回的值所替代:
z = subtraction (7, 2);
cout << "第一个结果是 " << z;
如果我们将函数调用替换为它返回的值(即 5),我们将得到:
z = 5;
cout << "第一个结果是 " << z;
使用相同的步骤,我们可以解释:
cout << "第二个结果是 " << subtraction (7, 2);
作为:
cout << "第二个结果是 " << 5;
因为 5 是 subtraction (7, 2) 返回的值。
在以下情况下:
cout << "第三个结果是 " << subtraction (x, y);
传递给 subtraction 的参数是变量而不是字面量。这也是有效的,并且可以正常工作。函数在调用时接收 x 和 y 的值:分别为 5 和 3,返回结果为 2。
第四个调用也类似:
z = 4 + subtraction (x, y);
唯一的区别是现在函数调用也是加法运算的一个操作数。再次,将函数调用替换为其结果:6。由于加法的交换性,上述语句也可以写成:
z = subtraction (x, y) + 4;
结果完全相同。注意,分号不一定放在函数调用之后,而是总是放在整个语句的末尾。同样,通过替换函数调用为其返回值,可以轻松地再次看到逻辑:
z = 4 + 2; // 相当于 z = 4 + subtraction (x, y);
z = 2 + 4; // 相当于 z = subtraction (x, y) + 4;
无类型的函数。使用 void
上面显示的函数语法:
type name (argument1, argument2 ...) { statements }
要求声明以类型开头。这是函数返回值的类型。但如果函数不需要返回值怎么办?在这种情况下,使用的类型是 void,这是一种表示没有值的特殊类型。例如,一个仅打印消息的函数可能不需要返回任何值:
// void 函数示例
#include <iostream>
using namespace std;
void printmessage ()
{
cout << "我是一函数!";
}
int main ()
{
printmessage ();
}
void 也可以在函数的参数列表中使用,以明确指定函数在调用时不接受任何实际参数。例如,printmessage 可以声明为:
void printmessage (void)
{
cout << "我是一函数!";
}
在 C++ 中,可以使用空参数列表代替 void,含义相同,但 void 在参数列表中的使用是由 C 语言推广的,在 C 语言中这是一个要求。
无论如何,函数名后面的括号在任何情况下都是必需的,无论是在声明时还是在调用时。即使函数不接受任何参数,也应始终在函数名后附上一个空括号。请参见前面示例中的 printmessage 调用:
printmessage ();
括号是区分函数和其他类型声明或语句的标志。以下代码不会调用函数:
printmessage;
main 的返回值
你可能注意到 main 的返回类型是 int,但在本章和前几章的大多数示例中,main 实际上并没有返回任何值。
有一个例外:如果 main 的执行在没有遇到 return 语句的情况下正常结束,编译器会假定函数以隐式 return 语句结束:
return 0;
请注意,这仅适用于函数 main,这是由于历史原因。所有其他具有返回类型的函数都必须以包含返回值的 return 语句结束,即使从未使用过。
当 main 返回零(隐式或显式),环境将其解释为:程序成功结束。其他值也可以由 main 返回,并且某些环境以某种方式允许调用者访问该值,尽管这种行为并不要求或在平台之间具有可移植性。以下是 main 的返回值在所有平台上均以相同方式解释的保证值:
| 值 | 描述 |
|---|---|
0 | 程序成功 |
EXIT_SUCCESS | 程序成功(同上)。 此值在头文件 <cstdlib> 中定义。 |
EXIT_FAILURE | 程序失败。 此值在头文件 <cstdlib> 中定义。 |
由于 main 的隐式 return 0; 语句是一个特殊例外,一些作者认为显式编写该语句是一种好习惯。
按值传递和按引用传递的参数
在之前看到的函数中,参数总是按值传递的。这意味着在调用函数时,传递给函数的是调用时这些参数的值的副本,这些值被复制到函数参数表示的变量中。例如:
int x=5, y=3, z;
z = addition (x, y);
在这种情况下,addition 函数传递了 5 和 3,这些是 x 和 y 的值的副本。这些值(5 和 3)用于初始化函数定义中设置为参数的变量,但在函数内对这些变量的任何修改都不会影响函数外部的变量 x 和 y 的值,因为在调用时传递给函数的不是 x 和 y 本身,而只是它们在那一刻的值的副本。

然而,在某些情况下,从函数内部访问外部变量可能是有用的。为此,可以按引用传递参数,而不是按值传递。例如,以下代码中的 duplicate 函数将其三个参数的值加倍,从而调用时修改了用作参数的变量:
// 按引用传递参数
#include <iostream>
using namespace std;
void duplicate (int& a, int& b, int& c)
{
a *= 2;
b *= 2;
c *= 2;
}
int main ()
{
int x = 1, y = 3, z = 7;
duplicate (x, y, z);
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
为了访问其参数,函数将其参数声明为引用。在 C++ 中,引用用跟在参数类型后的 &(&)表示,如上例中的 duplicate 参数。
当变量按引用传递时,传递的不再是副本,而是变量本身,函数参数表示的变量与传递给函数的参数相关联,并且在函数内部对相应的局部变量的任何修改都反映在调用时传递的变量中。
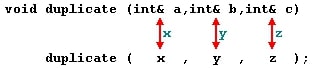
实际上,a、b 和 c 成为调用函数时传递的参数 x、y 和 z 的别名,并且在函数内对 a 的任何更改实际上是修改了函数外部的变量 x。对 b 的任何更改都会修改 y,对 c 的任何更改都会修改 z。这就是为什么当函数 duplicate 修改变量 a、b 和 c 的值时,x、y 和 z 的值也会受到影响。
如果将 duplicate 定义为:
void duplicate (int& a, int& b, int& c)
改为定义为没有 & 的情况:
void duplicate (int a, int b, int c)
变量不会按引用传递,而是按值传递,创建其值的副本。在这种情况下,程序的输出将是 x、y 和 z 未被修改的值(即 1、3 和 7)。
效率考虑和 const 引用
使用按值传递参数调用函数会导致值的副本被创建。对于 int 之类的基本类型来说,这是一个相对便宜的操作,但如果参数是一个大型复合类型,可能会导致某些开销。例如,考虑以下函数:
string concatenate (string a, string b)
{
return a + b;
}
此函数将两个字符串作为参数(按值),并返回连接它们的结果。通过按值传递参数,函数强制 a 和 b 在调用函数时成为传递的参数的副本。如果这些是长字符串,这可能意味着仅仅为了函数调用就复制了大量数据。
但如果将两个参数都设为引用,则可以完全避免此复制:
string concatenate (string& a, string& b)
{
return a + b;
}
按引用传递参数不需要复制。函数直接在传递的字符串(参数的别名)上操作,最多可能意味着将某些指针传递给函数。在这方面,采用引用的 concatenate 函数版本比采用值的版本更有效,因为它不需要复制昂贵的字符串。
另一方面,带有引用参数的函数通常被认为是修改传递参数的函数,因为这是引用参数的实际用途。
解决方案是函数保证其引用参数不会被该函数修改。这可以通过将参数限定为常量来实现:
string concatenate (const string& a, const string& b)
{
return a + b;
}
通过将它们限定为 const,函数被禁止修改 a 和 b 的值,但实际上可以作为引用(参数的别名)访问它们的值,而不必实际复制字符串。
因此,const 引用提供了与按值传递参数类似的功能,但对于大类型的参数提高了效率。这就是为什么在 C++ 中,const 引用在复合类型的参数中非常流行。然而,对于大多数基本类型,效率上没有显著差异,在某些情况下,const 引用甚至可能效率更低!
内联函数(Inline functions)
调用函数通常会导致某些开销(堆栈参数、跳转等),因此对于非常短的函数,简单地在调用函数的位置插入函数代码可能比正式调用函数的过程更有效。
在函数声明前加上 inline 说明符,通知编译器在特定函数中更倾向于内联扩展而不是通常的函数调用机制。这完全不会改变函数的行为,但仅仅是为了向编译器表明,该函数生成的代码应插入到每个调用函数的位置,而不是通过常规的函数调用来调用它。
例如,上面的 concatenate 函数可以声明为内联函数:
inline string concatenate (const string& a, const string& b)
{
return a + b;
}
这通知编译器,在调用 concatenate 时,程序更倾向于内联展开该函数,而不是执行常规调用。inline 仅在函数声明中指定,而不是在调用时指定。
请注意,大多数编译器在看到有机会提高效率时,已经优化代码以生成内联函数,即使没有明确标记为 inline。因此,该说明符仅指示编译器该函数更倾向于内联,但编译器可以自由选择不内联并进行其他优化。在 C++ 中,优化是一项委托给编译器的任务,只要生成的代码行为符合代码指定的行为,编译器可以自由生成任何代码。
参数的默认值
在 C++ 中,函数还可以具有可选参数,这样在调用时不需要为所有参数传递实参。例如,一个具有三个参数的函数可以仅用两个参数来调用。为此,函数必须为其最后一个参数包含一个默认值,当用较少的参数调用时,函数将使用该默认值。例如:
// 函数中的默认值
#include <iostream>
using namespace std;
int divide (int a, int b=2)
{
int r;
r = a / b;
return (r);
}
int main ()
{
cout << divide (12) << '\n';
cout << divide (20, 4) << '\n';
return 0;
}
在这个例子中,有两个对函数 divide 的调用。在第一个调用中:
divide (12)
调用只向函数传递一个参数,即使函数有两个参数。在这种情况下,函数假定第二个参数为 2(注意函数定义,声明其第二个参数为 int b=2)。因此,结果是 6。
在第二次调用中:
divide (20, 4)
调用向函数传递两个参数。因此,b 的默认值(int b=2)被忽略,b 取传递的参数值,即 4,得到的结果是 5。
声明函数
在 C++ 中,标识符只能在声明之后的表达式中使用。例如,不能在声明之前使用某个变量 x,如:
int x;
同样的规则也适用于函数。在被声明之前不能调用函数。这就是为什么在之前的所有函数示例中,函数总是在 main 函数之前定义,因为 main 函数是调用其他函数的函数。如果在 main 之前定义函数,这将违反函数必须在使用前声明的规则,因此不会编译通过。
函数的原型可以在不完全定义函数的情况下声明,只提供足够的细节以便在调用函数时了解涉及的类型。当然,该函数必须在代码的其他地方定义。但是,一旦这样声明,它就可以被调用了。
声明必须包含涉及的所有类型(返回类型和其参数的类型),使用与函数定义相同的语法,但用结束的分号替换函数体(语句块)。
参数列表不需要包含参数名,只需要其类型。然而,可以指定参数名,但它们是可选的,并且不需要与函数定义中的参数名完全匹配。例如,一个名为 protofunction、带有两个 int 参数的函数可以使用以下语句之一声明:
int protofunction (int first, int second);
int protofunction (int, int);
无论如何,包含每个参数的名称总是提高声明的可读性。
// 声明函数原型
#include <iostream>
using namespace std;
void odd (int x);
void even (int x);
int main()
{
int i;
do {
cout << "请输入数字(0 退出):";
cin >> i;
odd (i);
} while (i != 0);
return 0;
}
void odd (int x)
{
if ((x % 2) != 0) cout << "这是奇数。\n";
else even (x);
}
void even (int x)
{
if ((x % 2) == 0) cout << "这是偶数。\n";
else odd (x);
}
这个例子确实不是效率的例子。你可能自己可以编写这个程序的一个版本,代码量减少一半。不过,这个例子说明了函数可以在定义之前声明:
以下几行:
void odd (int a);
void even (int a);
声明了函数的原型。它们已经包含了调用它们所需的所有内容:名称、参数类型和返回类型(在这种情况下为 void)。通过这些原型声明,它们可以在完全定义之前被调用,这样就可以在调用它们的函数(如 main)之前放置这些函数的定义。
但是,在定义之前声明函数不仅仅有助于在代码中重新组织函数的顺序。在某些情况下,例如在这种特定情况下,至少需要一个声明,因为 odd 和 even 是相互调用的;在 odd 中调用 even,在 even 中调用 odd。因此,无法将代码结构化为 odd 在 even 之前定义,even 在 odd 之前定义。
递归(Recursivity)
递归是函数自我调用的属性。它对于某些任务非常有用,例如排序元素或计算数字的阶乘。例如,为了获得一个数字的阶乘 (n!),数学公式是:
n! = n * (n-1) * (n-2) * (n-3) ... * 1
更具体地说,5!(5 的阶乘)是:
5! = 5 * 4 * 3 * 2 * 1 = 120
而在 C++ 中计算这个的递归函数可以是:
// 阶乘计算器
#include <iostream>
using namespace std;
long factorial (long a)
{
if (a > 1)
return (a * factorial (a-1));
else
return 1;
}
int main ()
{
long number = 9;
cout << number << "! = " << factorial (number);
return 0;
}
注意在 factorial 函数中我们包含了对自身的调用,但仅当传递的参数大于 1 时,因为否则函数将执行一个无限递归循环,一旦它达到 0,它将继续乘以所有负数(可能在运行时某个时刻引发堆栈溢出)。















 1336
1336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









