







- 近期参加学习该课程,老师和班主任都是美女,学习也很有动力。课程主要讲解了强化学习经典算法:Q-learning、Sarsa、DQN、Policy、 Gradient、DDPG。下面是遇到的一些故障和心得。
环境搭建
!pip install gym 该指令安装环境库,“ !”是在环境下运行,相当于在windows系统中cmd命令下运行。检查是否配置:pip list | grep gym (pip list 查找python已安装库,grep是Linux的查找)
pip instal 安装库时,若库下载很慢时可选择数据下载源,-i 选择数据下载源。
例:pip install gym -i https://pypi.tuna.tsinghua.edu.cn/simple
常见数据源地址为:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple
华中理工大学:http://pypi.hustunique.com
山东理工大学:http://pypi.sdutlinux.org
豆瓣:http://pypi.douban.com/simple
github文件下载慢的原因是从国内访问Amazon库非常慢,可以通过代理的方式、刷新 DNS 缓存,加快速度,但是更简单粗暴的方式是在“码云”上下载,国内的仓库库分享:https://gitee.com/PaddlePaddle/
解决作业中的疑问
作业二中训练后的路径

作业三 DQN 相对作业二中增加了神经网络的概念,其中超参数的调节就是对神经网络的调试。神经网络可以不用很复杂,学习率合适一样可以达到很好的效果。我针对两个128的全连接层设置的学习率是0.007效果还是不错的。
作业四 PG解决Pong
在训练时,训练时间长,假如网络不稳定,或者什么不明原因,网一掉。。。唉。。。
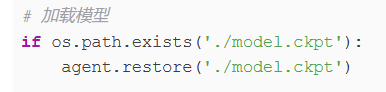
所以训练时,保存模型,还是很好用的,下次加载继续训练。
大作业:使用DDPG解决四轴飞行器悬浮任务
环境的输入是一个16维的向量;
输出是一个4维的向量(代表每一个轴的电压)
ActorModel类输入ops,输出的是logits概率
CriticModel类输入环境和动作,返回奖励
QuadrotorModel, DDPG, QuadrotorAgent 三者嵌套:
在Step4 Training && Test(训练&&测试)中:
在action = np.squeeze(action)后,需要加上一句代码:
action = np.clip(action, -1.0, 1.0)
将动作概率限定在(-1,1)之内















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









