






大家好,本文将围绕利用python爬取简单网页数据步骤展开说明,python怎么爬取网站上的数据是一个很多人都想弄明白的事情,想搞清楚python怎么爬取网站所有网页需要先了解以下几个事情。

在开始之前,我们需要了解内链和外链到底是什么~
内链:同一网站域名下的内容页面之间的互相链接(自己网站的内容链接到自己网站的内部页面,也称之为站内链接)
外链:在自己的网站导入别人的网站(比如有些网站加入了百度这个链接,而百度就是这个网站的外链)
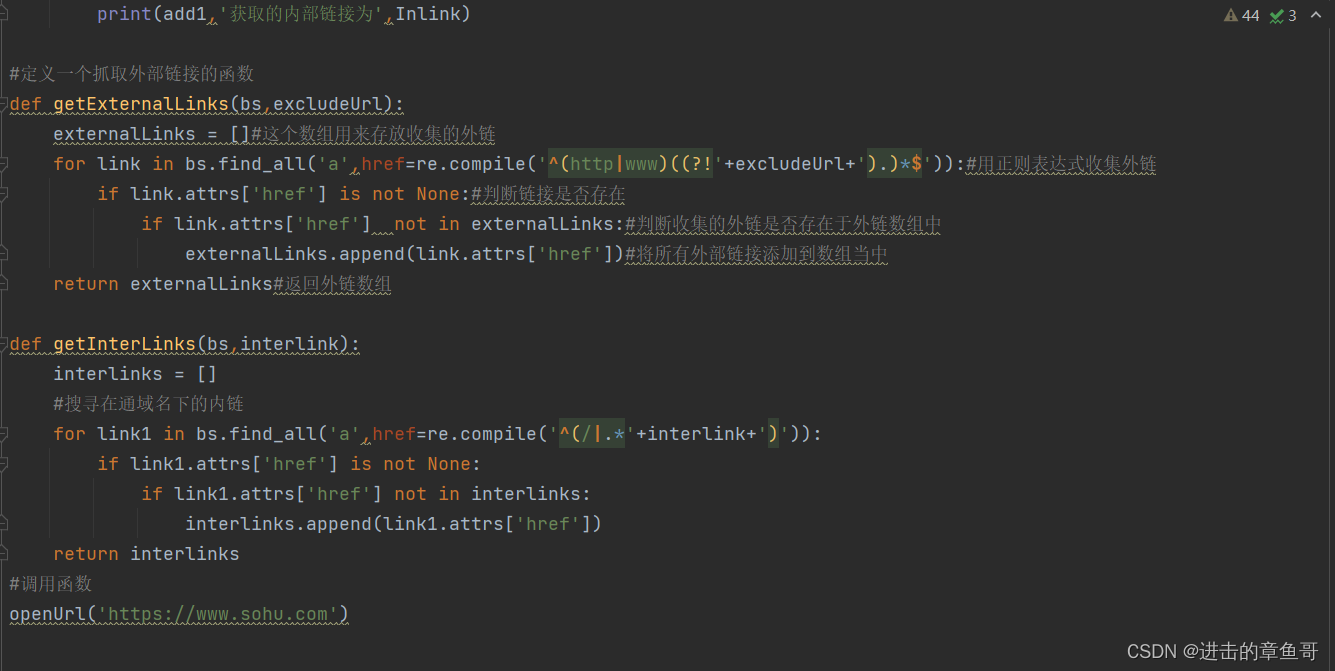
正文开始了,思路是先收集网页的所有链接,通过正则表达式筛选即可
通过观察可以发现外链一般以http或者www开始 那么我们的正则表达式可以写成
re.compile('^(http|www)((?!'+excludeUrl+').)*$')) (注释括号内的(?!'+excludeUrl+')意思是排除搜索的外链与网址相同)
而内链一般以 / 开头 那么正则表达式为 re.compile('^(/|.*'+includeUrl+')')) .......这个正则表达式弄了半天也搞不懂,这里我就理解为匹配includeUrl+以/开头的内链接 或者 是以/开头的链接
代码如下:

运行效果:

积累:
urllib.parse模块 :用来解析url网址
语法: urlparse(url).xxx
xxx = {scheme(网络协议),netloc(服务器位置),path(路径),params(参数),query(查询条件),fragment(片段)}
如 https://www.hahaha.com/local.zhangyuge?id=1
那么 scheme = 'https'
netloc = 'www.hahaha.com '
path =' local.zhangyuge'
query =' id=1'














 4787
4787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









