










爬取豆瓣短评之《哥斯拉大战金刚 Godzilla vs Kong》
近期上映的很火的一部电影,不知道你们都带女朋友看了没,昨天我试着用爬虫爬了一下热评,给大家展示一下
需要用到的库
1、requests库,最经典的爬虫库
2、jieba库,经典的中文分词库
3、stylecloud库,生成图云
4、
1、抓数据
上一篇博客就写到,豆瓣每部电影都有一个编号,这个编号再url中可以看到
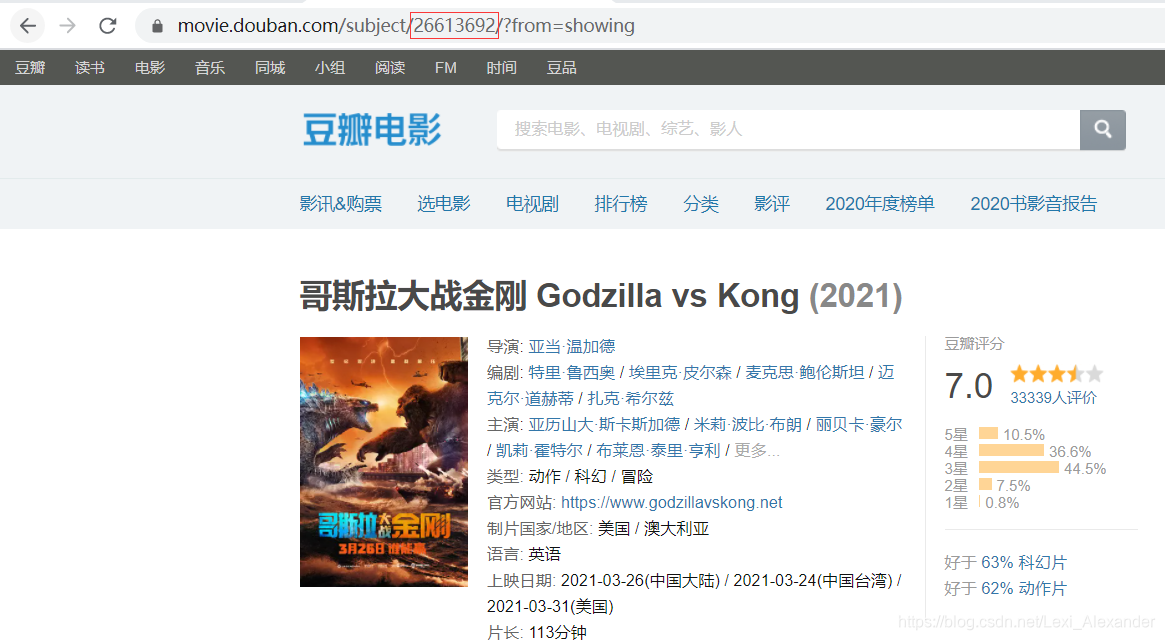
我们得到电影的id号之后,就可以开始啦
import requests
from stylecloud import gen_stylecloud
import jieba
import re
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0'
}
def jieba_cloud(file_name, icon):
with open(file_name, 'r', encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list) # 分词用 隔开
# 制作中文词云
icon_name = " "
if icon == "1":
icon_name = ''
elif icon == "2":
icon_name = "fas fa-dragon"
elif icon == "3":
icon_name = "fas fa-dog"
elif icon == "4":
icon_name = "fas fa-cat"
elif icon == "5":
icon_name = "fas fa-dove"
elif icon == "6":
icon_name = "fab fa-qq"
pic = str(icon) + '.png'
if icon_name is not None and len(icon_name) > 0:
gen_stylecloud(text=result, icon_name=icon_name, font_path='simsun.ttc', output_name=pic)
else:
gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic)
return pic
def spider_comment(movie_id, page):
comment_list = []
with open("douban.txt", "a+", encoding='utf-8') as f:
for i in range(1,page+1):
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \
% (movie_id, (i - 1) * 20)
req = requests.get(url, headers=headers)
req.encoding = 'utf-8'
comments = re.findall('<span class="short">(.*)</span>', req.text)
f.writelines('\n'.join(comments))
print(comments)
# 主函数
if __name__ == '__main__':
movie_id = '26613692'
page = 10
spider_comment(movie_id, page)
jieba_cloud("douban.txt", "1")
jieba_cloud("douban.txt", "2")
jieba_cloud("douban.txt", "3")
jieba_cloud("douban.txt", "4")
jieba_cloud("douban.txt", "5")
jieba_cloud("douban.txt", "6")
运行代码

最后看结果


















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









