







tensorflow.python.framework.errors_impl.ResourceExhaustedError: 2 root error(s) found.
(0) Resource exhausted: OOM when allocating tensor with shape[16,100,1024] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node training/Adam/gradients/Transformer-1-MultiHeadSelfAttention-Norm/truediv_grad/Neg}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.[[Mean/_901]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.(1) Resource exhausted: OOM when allocating tensor with shape[16,100,1024] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node training/Adam/gradients/Transformer-1-MultiHeadSelfAttention-Norm/truediv_grad/Neg}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.0 successful operations.
0 derived errors ignored.
这主要是因为模型太大导致GPU显存不足或者剩余显存太小所导致的错误
建议依次采取以下解决方案
解决方案1:缩小模型batchsize大小
尝试逐渐缩小batchsize大小,若batchsize过小严重影响训练时间或者当batchsize=1时依旧存在上述问题,则建议尝试方案2
解决方案2:扩大显存大小
可以采取的方案有解除GPU资源占用或者扩大GPU
1 解除GPU资源占用
在cmd中输入以下命令获取GPU进程情况
nvidia-smi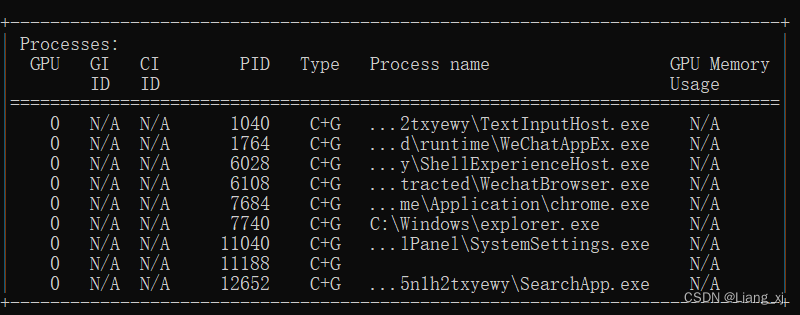
然后杀死相应进程
taskkill /PID PID号此方案一般只会在杀死的PID的占用相当大且本身GPU不受限的情况下才会奏效
2 扩大GPU
包括更换硬件或者使用在线GPU进行训练
解决方案3:改用内存CPU训练
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"总结:方案1是在模型训练大小上进行的修改,方案2和方案3是在硬件使用上进行的修改
建议:有预算的情况下可以更换硬件,如果预算有限建议使用在线GPU进行训练














 5687
5687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









