







1. SD文生图基本原理
接下来是ComfyUI工作流基础介绍。
1.2.1. SD1.5文生图工作流
ComfyUI是一个节点式开源工具,能够通过节点之间的连接调用SD文生图流程。文生图的过程如下所示,对应工作流见附件。
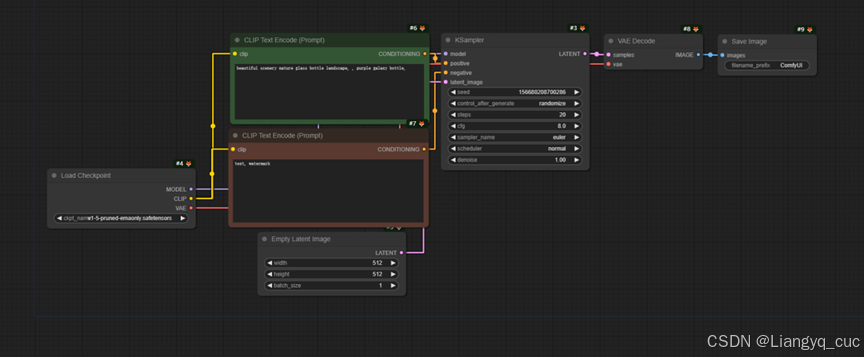
Load Checkpoint加载SD大模型,然后连接LoRA模型,在绿色、红色的CLIP Text Encode中分别输入正向提示词和负向提示词,最后进入Ksampler采样器。此外还需要输入潜空间的图像,如这里输入了empty latent image,可以理解为随机噪声图像。
采样Ksampler通过种子数seed的不同增加文生图过程的随机性,通过调整step采样步长、cfg提示词相关性、samper_name采样方法调整生成图像的质量和细节差异,通过denoise去噪程度控制生成图像与输入的潜空间图像的差异程度。经过指定步数的采样后,输出了潜空间的图像,该图像经过VAE解码就得到了像素空间中的最终结果,即人类能够理解的图像。
1.2.2. SDXL、SD3工作流
SDXL工作流
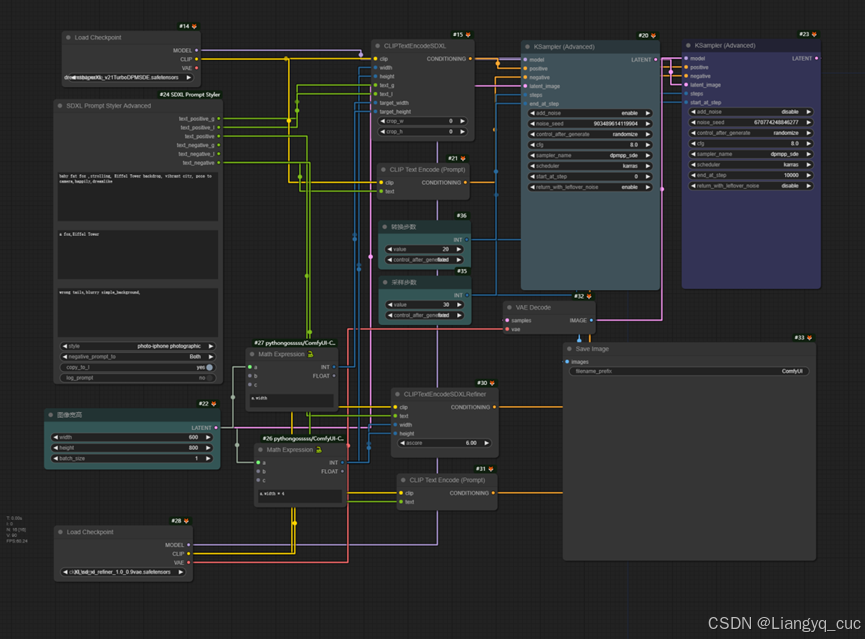
对应SDXL模型架构,SDXL通过连接Base和Refiner两个大模型进行生成。SDXL模型按照SD1.5的使用方法也可以取得较好的效果,使用两个大模型在图像细节上会获得提升。
在这个工作流中,使用了Base和Refiner两个大模型,对应有2个Ksampler,设置总采样步数30步,base对应的采样器执行前20步,base采样器输出的latent直接作为refiner采样的输入,refiner对应的采样器执行20到30步,且关闭了add_noise。另外值得注意的是使用了SDXL对应的CLIP编码,同时CLIP空间比图像空间大2-4倍,所以对base的CLIP编码宽高进行了放大操作。2-1SDXL base+refiner文生图(工作流见附件)
SD3工作流
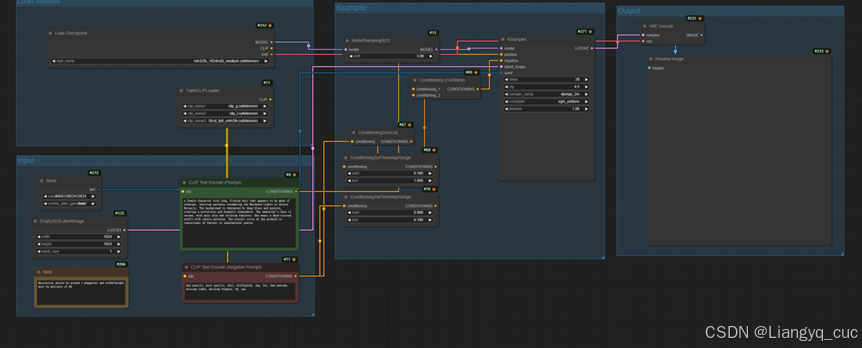
SD3基本思路与SD1.5工作流类似。不同之处在于,SD3 medium的大模型有内置CLIP和无内置版本,若使用无内置版本需要外接3个Clip模型。此外还需要使用SD3专用的emptylatentimage、condition节点。但目前就开源内容和模型能力来说,通常不推荐SD3模型。3-1 SD3文生图基础工作流(工作流见附件)
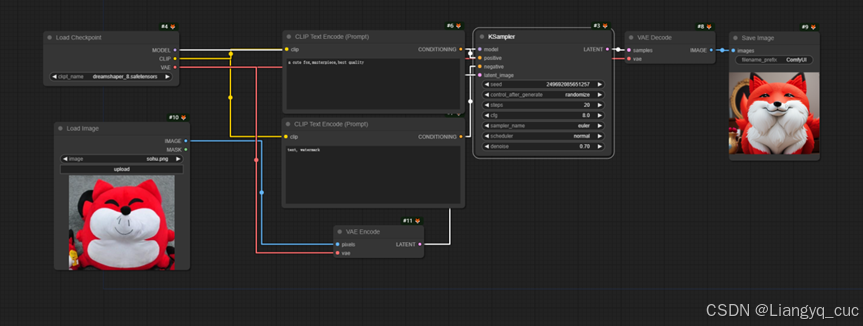
1.2.3. SD1.5图生图
在ComfyUI中进行文生图时,向Ksampler输入了一个Empty Latent Image,设置了输出图像尺寸和每一次运行生成的图像数,让采样器从一个随机的高斯噪声开始去噪得到最终图像。
Empty Latent Image相当于向采样器提供了一个只有尺寸信息的空图像,当我们把它替换为带有像素的普通图像时,就相当于将文生图转为图生图了。只需要在图片和采样器之间加一个编码器节点 VAE Encode,它的作用是将图像转换为 Latent Image 传递给采样器。
在进行图生图时,需要注意Ksampler的Denoise,代表重绘幅度,该值越大,则与原图越不相似,值越小与原图越相似。4-1 SD1.5基本图生图(工作流见附件)
如下图是在不同的种子数下,增大Denoise对生成图像的影响,随着denoise增大,与原图相似度越来越小。

文章内容整理总结自互联网,如有引用未标明出,请拨冗指正。

















 4070
4070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









