










你好,我是小白~
今天给大家带来的是十大属于处理技巧,涉及到的有:
-
缺失值处理(Handling Missing Values)
-
数据标准化(Data Normalization)
-
数据归一化(Data Scaling)
-
类别编码(Categorical Encoding)
-
数据降维(Dimensionality Reduction)
-
数据去重(Removing Duplicates)
-
数据分箱(Data Binning)
-
特征选择(Feature Selection)
-
数据变换(Data Transformation)
-
数据平衡处理(Handling Imbalanced Data)
具体原理和使用方式,下面和大家一起聊聊~
1. 缺失值处理(Handling Missing Values)
介绍
在现实数据集中,缺失值的存在是普遍现象。直接包含缺失值的数据会使机器学习模型无法有效训练,因此常见的缺失值处理方法包括删除缺失值、均值插补、中位数插补、众数插补以及基于回归模型的插补等。
核心点
-
删除法:直接去掉含有缺失值的行或列。
-
插补法:使用均值、中位数、众数或回归模型来填补缺失值。
原理
假设我们有一个特征 ,其中存在一些缺失值。最简单的插补方式是用均值来替换缺失值。假设缺失值为 ,则均值插补的公式为:
(用非缺失数据的均值填补缺失值)
可以类似地用中位数或众数来插补。
核心公式
均值插补:
(均值插补公式)
代码示例
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.impute import SimpleImputer # 创建虚拟数据集 np.random.seed(0) data = {'A': [1, 2, np.nan, 4, 5], 'B': [np.nan, 2, 3, 4, 5], 'C': [1, 2, 3, np.nan, 5], 'D': [1, 2, np.nan, np.nan, 5]} df = pd.DataFrame(data) # 使用均值插补 imputer = SimpleImputer(strategy='mean') df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns) # 绘制原始数据和填补后的数据对比 fig, ax = plt.subplots(figsize=(10, 6)) # 原始数据 ax.scatter(range(len(df)), df['A'], color='red', label='A: Original', marker='o') ax.scatter(range(len(df)), df['B'], color='blue', label='B: Original', marker='x') # 插补后的数据 ax.scatter(range(len(df_imputed)), df_imputed['A'], color='green', label='A: Imputed', marker='s') ax.scatter(range(len(df_imputed)), df_imputed['B'], color='orange', label='B: Imputed', marker='d') # 设置图例和标题 ax.legend() ax.set_title('Original vs Imputed Data (Mean Imputation)') ax.set_xlabel('Index') ax.set_ylabel('Value') plt.show()
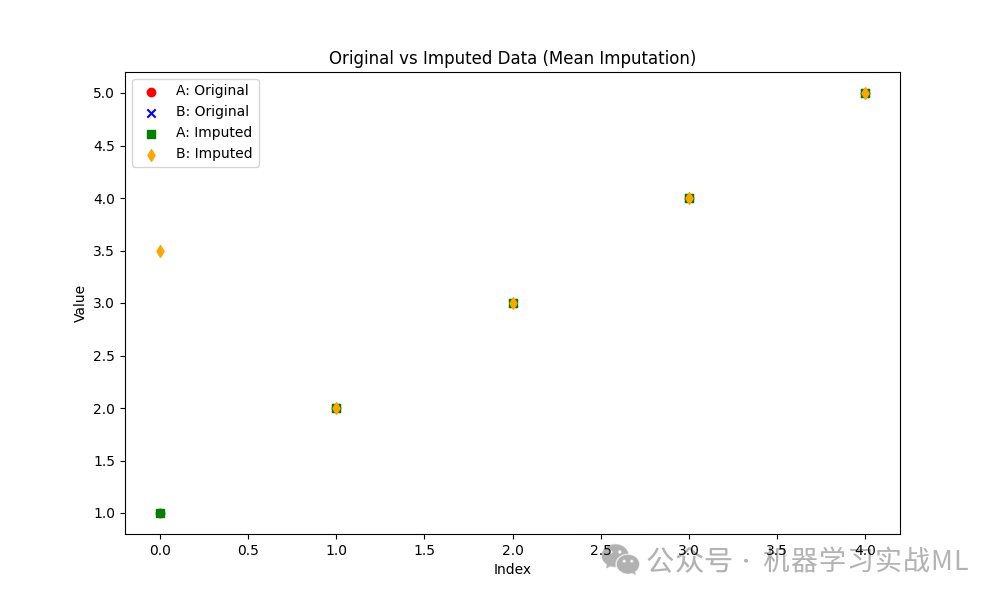
红色和蓝色点表示原始数据中的特征 A 和 B,包含了一些缺失值。
绿色和橙色点表示经过均值插补后的数据,可以看到缺失值被合理填补。
2. 数据标准化(Data Normalization)
介绍
数据标准化是将特征值变换到同一量纲,使得每个特征的均值为 0,标准差为 1。标准化有助于距离度量模型(如 KNN、SVM)的收敛,并使模型不因不同尺度的特征而偏向某些特征。
核心点
-
目标:让每个特征都具有相同的均值和标准差,消除尺度不同带来的影响。
-
应用场景:适用于梯度下降算法、距离度量类算法等。
原理
标准化的过程是将每个特征值减去该特征的均值,再除以该特征的标准差,使得每个特征转换后的均值为 0,方差为 1。
核心公式
假设 是一个特征,标准化的公式为:
其中, 是均值, 是标准差。
均值 :
标准差 :
代码示例
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler # 创建虚拟数据集 np.random.seed(42) data = np.random.randint(1, 100, size=(10, 2)) df = pd.DataFrame(data, columns=['Feature1', 'Feature2']) # 标准化处理 scaler = StandardScaler() df_scaled = pd.DataFrame(scaler.fit_transform(df), columns=df.columns) # 绘制原始数据与标准化后的数据对比 fig, ax = plt.subplots(figsize=(10, 6)) # 原始数据 ax.scatter(range(len(df)), df['Feature1'], color='red', label='Feature1: Original', marker='o') ax.scatter(range(len(df)), df['Feature2'], color='blue', label='Feature2: Original', marker='x') # 标准化后的数据 ax.scatter(range(len(df_scaled)), df_scaled['Feature1'], color='green', label='Feature1: Scaled', marker='s') ax.scatter(range(len(df_scaled)), df_scaled['Feature2'], color='orange', label='Feature2: Scaled', marker='d') # 设置图例和标题 ax.legend() ax.set_title('Original vs Scaled Data (Standardization)') ax.set_xlabel('Index') ax.set_ylabel('Value') plt.show()
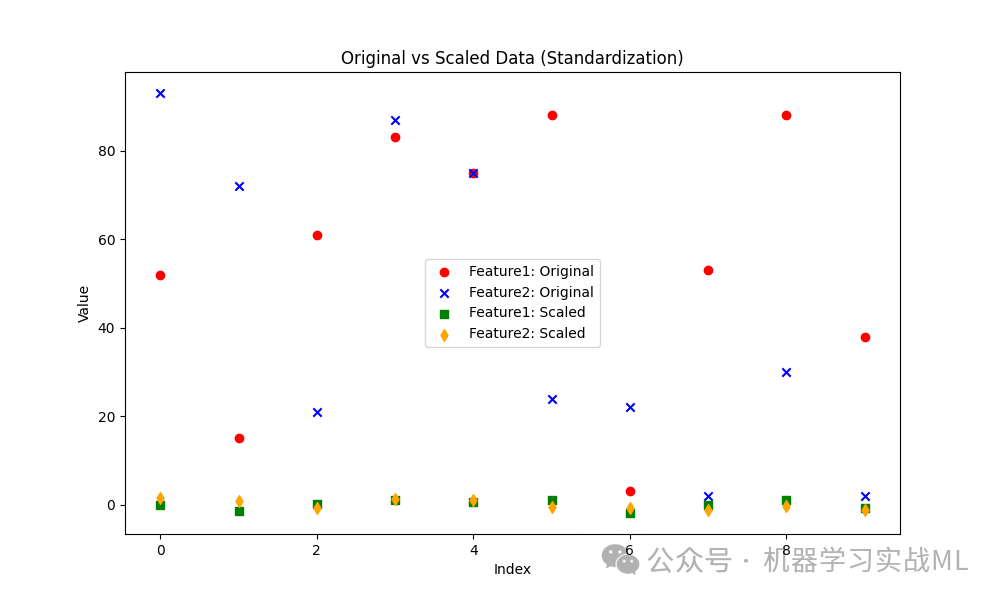
红色和蓝色点表示原始数据的两个特征,特征值范围较大。
绿色和橙色点表示经过标准化后的数据,特征值缩放至均值为 0,方差为 1。
3. 数据归一化(Data Scaling)
介绍
数据归一化是将特征缩放到一个固定的范围内,通常为 [0, 1]。这在神经网络或距离度量类模型中尤为重要,因为模型可能对特征的量纲差异非常敏感。
核心点
-
目标:将特征值缩放到同一范围内,消除不同特征之间量级差异对模型的影响。
-
应用场景:适用于神经网络、KNN 等对量纲敏感的算法。
原理
归一化将特征按比例缩放到特定区间(如 [0, 1])。最常见的方法是 min-max scaling,它根据每个特征的最小值和最大值进行缩放。
核心公式
假设特征 ,归一化的公式为:
其中, 和 分别是特征的最小值和最大值。
代码示例
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.preprocessing import MinMaxScaler # 创建虚拟数据集 data = np.random.randint(1, 100, size=(10, 2)) df = pd.DataFrame(data, columns=['Feature1', 'Feature2']) # 归一化处理 scaler = MinMaxScaler() df_scaled = pd.DataFrame(scaler.fit_transform(df), columns=df.columns) # 绘制原始数据与归一化后的数据对比 fig, ax = plt.subplots(figsize=(10, 6)) # 原始数据 ax.scatter(range(len(df)), df['Feature1'], color='red', label='Feature1: Original', marker='o') ax.scatter(range(len(df)), df['Feature2'], color='blue', label='Feature2: Original', marker='x') # 归一化后的数据 ax.scatter(range(len(df_scaled)), df_scaled['Feature1'], color='green', label='Feature1: Scaled', marker='s') ax.scatter(range(len(df_scaled)), df_scaled['Feature2'], color='orange', label='Feature2: Scaled', marker='d') # 设置图例和标题 ax.legend() ax.set_title('Original vs Scaled Data (Normalization)') ax.set_xlabel('Index') ax.set_ylabel('Value') plt.show()
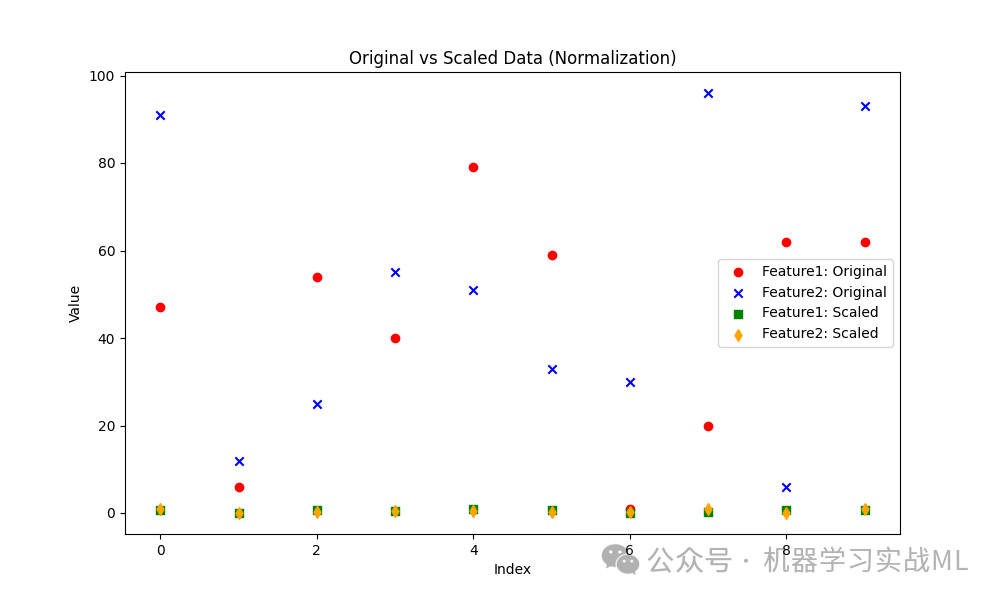
红色和蓝色点表示原始数据,数据的范围较广。
绿色和橙色点表示归一化后的数据,数据范围被缩放至 [0, 1]。
4. 类别编码(Categorical Encoding)
介绍
在处理类别数据时,常用的编码方法包括标签编码和独热编码。独热编码(One-Hot Encoding)是将类别数据转化为二进制向量的过程。
核心点
-
目标:将类别型特征转化为数值型特征,适用于大多数机器学习模型。
-
应用场景:常用于回归和分类任务中对离散变量的处理。
原理
假设类别数据 ,独热编码将每个类别 转换为一个长度为 的向量,其中只有第 位为 1,其余为 0。
核心公式
独热编码公式:
其中, 的位置对应类别 的索引。
代码示例
import pandas as pd import matplotlib.pyplot as plt from sklearn.preprocessing import OneHotEncoder # 创建虚拟数据集 data = {'Category': ['A', 'B', 'C', 'A', 'B']} df = pd.DataFrame(data) # 独热编码 encoder = OneHotEncoder(sparse=False) encoded_data = encoder.fit_transform(df[['Category']]) df_encoded = pd.DataFrame(encoded_data, columns=encoder.categories_) # 可视化原始数据与独热编码后的数据对比 fig, ax = plt.subplots(figsize=(8, 4)) ax.matshow(encoded_data, cmap='coolwarm') ax.set_title('One-Hot Encoding Representation') plt.xlabel('Encoded Categories') plt.ylabel('Samples') plt.show()
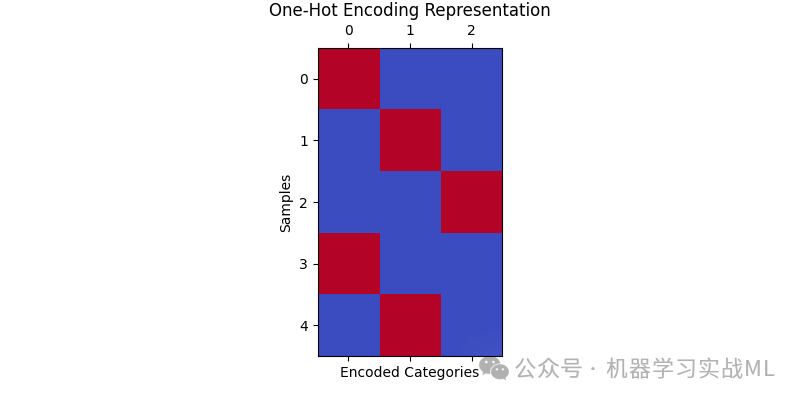
矩阵图展示了类别变量通过独热编码转化为二进制矩阵的过程。
5. 数据分箱(Binning)
介绍
数据分箱是一种将连续特征离散化的方法,通过将数值型数据划分为多个区间,将其转换为类别型数据。这在处理有序的连续数据时非常有用,能够减少数据的复杂性,增强模型的稳定性。
核心点
-
目标:将连续型变量分成多个类别,减少特征的噪声,并简化特征分布。
-
应用场景:适用于回归问题、决策树模型等,尤其是在特征数据存在极值时。
原理
假设特征 是一个连续变量,分箱的过程是将特征 划分为 个区间 ,每个 被映射到某个区间。
可以采用等宽分箱或等频分箱:
-
等宽分箱:将数据按相等区间长度进行划分。
-
等频分箱:将数据按相等频率进行划分。
核心公式
等宽分箱公式:
其中 和 分别是特征 的最小值和最大值, 是分箱的数量。
等频分箱公式:按排序后的数值均匀划分。
代码示例
# 创建虚拟数据集 data = {'Feature': np.random.randint(0, 100, size=100)} df = pd.DataFrame(data) # 等宽分箱 df['Binned'] = pd.cut(df['Feature'], bins=5) # 等频分箱 df['Binned_freq'] = pd.qcut(df['Feature'], q=5) # 绘制直方图和分箱后的箱线图 fig, ax = plt.subplots(1, 2, figsize=(14, 6)) # 绘制直方图(原始数据) ax[0].hist(df['Feature'], bins=20, color='blue', alpha=0.7) ax[0].set_title('Histogram of Original Data') # 绘制箱线图(分箱后数据) df.boxplot(column='Feature', by='Binned', ax=ax[1]) ax[1].set_title('Boxplot of Binned Data (Equal Width)') plt.suptitle('') plt.show()
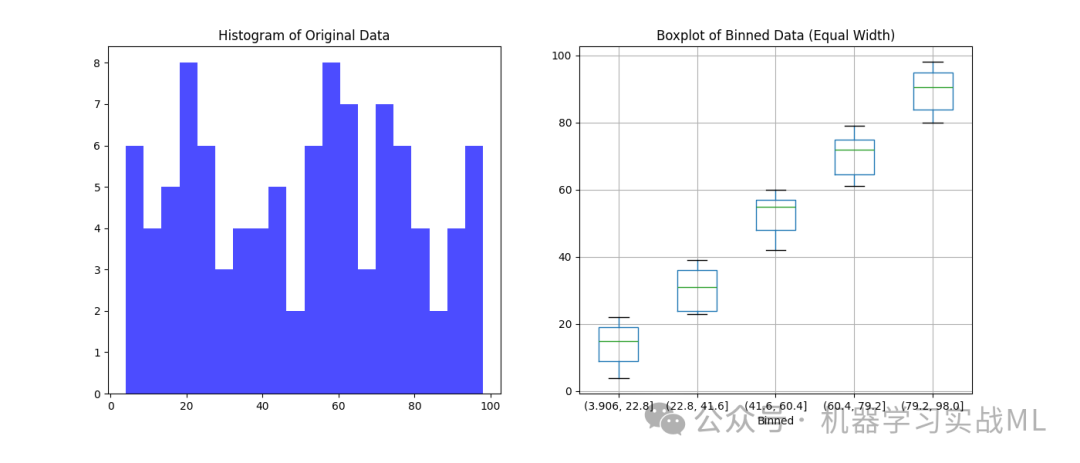
左侧的直方图显示了原始数据的分布,特征值在 0-100 范围内。
右侧的箱线图展示了等宽分箱后的数据分布,每个区间内数据的变化范围较大,但区间划分明确。
6. 特征选择(Feature Selection)
介绍
特征选择是从原始特征集中选择出最具代表性的一部分特征,去掉冗余的或无关的特征。常用方法包括过滤法、包裹法和嵌入法。
核心点
-
目标:减少特征空间,降低模型复杂性,提高训练效率,同时减少过拟合风险。
-
应用场景:适用于高维数据集和存在大量无关特征的任务。
原理
特征选择方法可以分为以下三类:
-
过滤法:通过统计指标(如方差、相关系数)选择特征。
-
包裹法:通过模型性能(如递归特征消除,RFE)选择特征。
-
嵌入法:在模型训练过程中嵌入特征选择,如 L1 正则化中的 LASSO 回归。
核心公式
LASSO 回归(嵌入法)的目标是通过引入 L1 正则化来选择特征,优化目标函数为:
其中, 是正则化强度, 是模型的系数。
当 较大时,某些系数 会被收缩到 0,这相当于选择性地去除了无关特征。
代码示例
import numpy as np import pandas as pd from sklearn.datasets import make_regression from sklearn.linear_model import Lasso import matplotlib.pyplot as plt # 创建虚拟数据集 X, y = make_regression(n_samples=100, n_features=10, noise=0.1) # 使用 LASSO 回归进行特征选择 lasso = Lasso(alpha=0.1) lasso.fit(X, y) # 绘制特征重要性图 fig, ax = plt.subplots(figsize=(10, 6)) ax.bar(range(len(lasso.coef_)), lasso.coef_, color='blue') ax.set_title('Feature Importance (Lasso)') ax.set_xlabel('Feature Index') ax.set_ylabel('Coefficient Value') # 绘制特征值分布图 ax2 = ax.twinx() ax2.plot(range(len(lasso.coef_)), np.abs(lasso.coef_), 'r--') ax2.set_ylabel('Absolute Coefficient Value') plt.show()
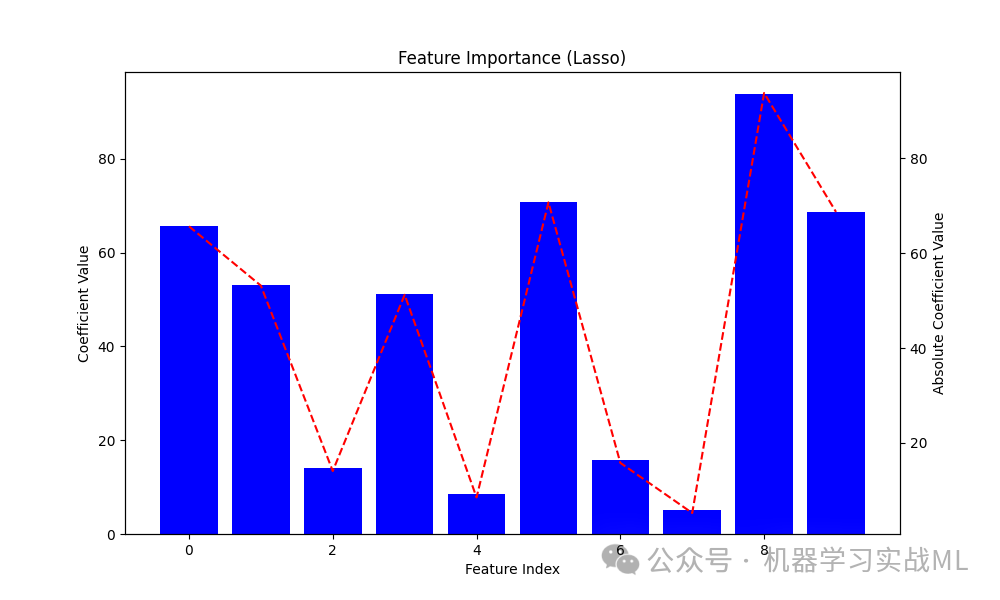
蓝色的柱状图显示了每个特征的系数值,系数为 0 的特征被移除。
红色虚线显示了特征的绝对重要性值,帮助直观了解哪些特征对模型的贡献最大。
7. 特征缩放(Feature Scaling)
介绍
特征缩放是将数据按比例缩放到一个范围内,通常为 [0, 1] 或 [-1, 1]。缩放后的数据可以加快梯度下降算法的收敛速度,避免模型被某些尺度较大的特征支配。
核心点
-
目标:平衡各特征的量纲,避免某些特征对模型的影响过大。
-
应用场景:特别适用于基于距离的模型,如 KNN、SVM。
原理
特征缩放与归一化相似,但更多关注的是缩放各特征到一定范围而非严格的归一化。
核心公式
常用的特征缩放公式为 Min-Max Scaling:
代码示例
from sklearn.preprocessing import MinMaxScaler # 创建虚拟数据集 data = np.random.randint(1, 100, size=(50, 2)) df = pd.DataFrame(data, columns=['Feature1', 'Feature2']) # 特征缩放 scaler = MinMaxScaler() df_scaled = pd.DataFrame(scaler.fit_transform(df), columns=df.columns) # 绘制原始数据与缩放后数据对比 fig, ax = plt.subplots(1, 2, figsize=(12, 6)) # 原始数据散点图 ax[0].scatter(df['Feature1'], df['Feature2'], color='blue', label='Original Data') ax[0].set_title('Original Data') ax[0].set_xlabel('Feature 1') ax[0].set_ylabel('Feature 2') # 缩放后数据散点图 ax[1].scatter(df_scaled['Feature1'], df_scaled['Feature2'], color='green', label='Scaled Data') ax[1].set_title('Scaled Data (Min-Max)') ax[1].set_xlabel('Feature 1') ax[1].set_ylabel('Feature 2') plt.show()
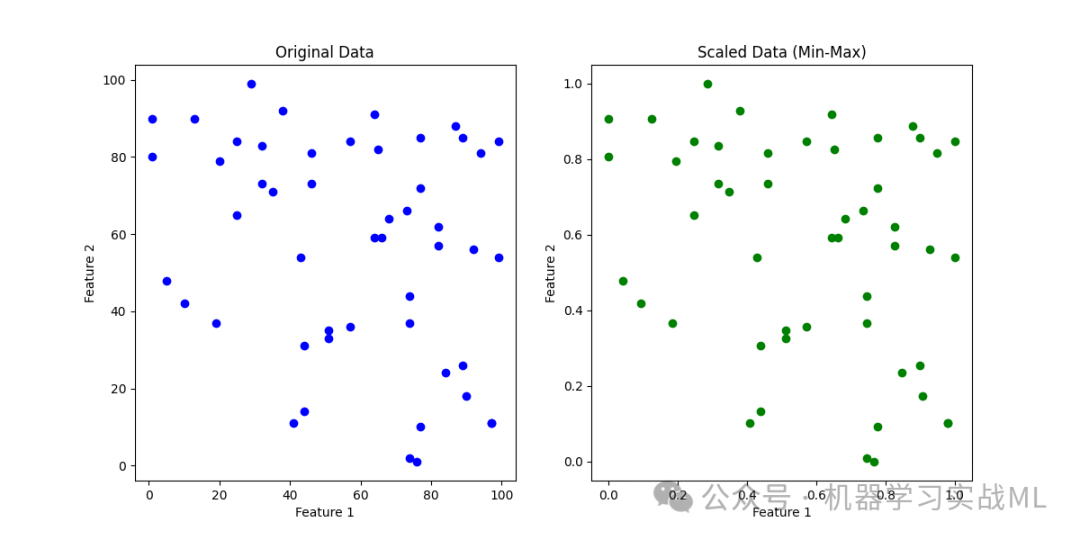
左侧的散点图显示了原始特征数据的分布。
右侧的散点图则展示了经过 Min-Max 缩放后的特征数据,所有数据点被缩放到 [0, 1] 的范围。
8. 主成分分析(Principal Component Analysis, PCA)
介绍
PCA 是一种常用的降维技术,通过线性变换将数据从高维空间映射到低维空间,同时尽可能保留原始数据中的方差。PCA 的目标是找到特征空间中的主成分,这些主成分是数据方差最大的方向。
核心点
-
目标:通过线性变换将数据降维到更低的维度,同时保留数据的主要变异性。
-
应用场景:高维数据的降维,特征提取,数据可视化。
原理
PCA 的过程如下:
-
中心化数据:对每个特征减去其均值,使得数据的均值为 0。
-
计算协方差矩阵:协方差矩阵描述了特征之间的线性关系。
-
计算特征值和特征向量:特征值表示主成分的方差大小,特征向量表示主成分的方向。
-
选择主成分:选择特征值最大的前 个特征向量作为主成分。
-
转换数据:将数据投影到选定的主成分上。
核心公式
协方差矩阵计算:
其中, 是中心化后的数据矩阵。
特征值和特征向量:
解特征方程:
其中, 是特征值, 是特征向量。
数据转换:
其中, 是选择的主成分构成的矩阵。
代码示例
from sklearn.decomposition import PCA import numpy as np import matplotlib.pyplot as plt # 创建虚拟数据集 np.random.seed(0) X = np.random.rand(100, 3) # 100 个样本,3 个特征 # PCA 降维 pca = PCA(n_components=2) X_pca = pca.fit_transform(X) # 绘制原始数据和 PCA 降维后的数据 fig, ax = plt.subplots(1, 2, figsize=(12, 6)) # 原始数据的散点图 ax[0].scatter(X[:, 0], X[:, 1], c='blue', label='Original Data') ax[0].set_title('Original Data') ax[0].set_xlabel('Feature 1') ax[0].set_ylabel('Feature 2') # PCA 降维后的散点图 ax[1].scatter(X_pca[:, 0], X_pca[:, 1], c='green', label='PCA Data') ax[1].set_title('PCA Transformed Data') ax[1].set_xlabel('Principal Component 1') ax[1].set_ylabel('Principal Component 2') plt.show()
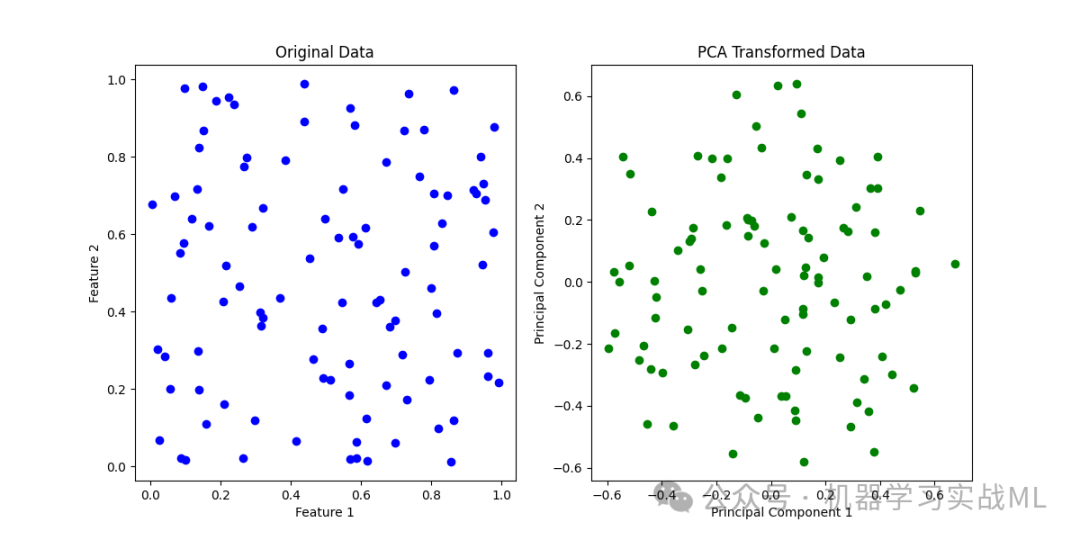
左侧的散点图显示了原始数据在前两个特征上的分布。
右侧的散点图展示了通过 PCA 降维后的数据,数据被投影到两个主成分上,特征维度大大减少但主要的信息被保留。
9. 特征工程(Feature Engineering)
介绍
特征工程是创建新的特征或变换现有特征的过程,以提高模型的表现。这包括特征构造、特征选择、特征缩放等。
核心点
-
目标:通过创建新的特征或变换特征,增加模型的预测能力。
-
应用场景:数据预处理、模型优化。
原理
特征工程的步骤通常包括:
-
特征构造:基于现有特征创建新特征(如特征交互、组合)。
-
特征选择:选择对模型最有用的特征。
-
特征转换:如对数变换、平方根变换等,处理特征的非线性关系。
核心公式
特征构造示例(如特征交互): 假设有两个特征 和 ,新的交互特征为:
代码示例
import pandas as pd import numpy as np import matplotlib.pyplot as plt # 创建虚拟数据集 data = {'Feature1': np.random.rand(100), 'Feature2': np.random.rand(100)} df = pd.DataFrame(data) # 特征工程:构造特征交互 df['Feature_Interaction'] = df['Feature1'] * df['Feature2'] # 绘制特征原始分布和交互特征 fig, ax = plt.subplots(1, 2, figsize=(12, 6)) # 原始特征的散点图 ax[0].scatter(df['Feature1'], df['Feature2'], c='blue', label='Feature1 vs Feature2') ax[0].set_title('Original Features') ax[0].set_xlabel('Feature 1') ax[0].set_ylabel('Feature 2') # 交互特征的分布图 ax[1].hist(df['Feature_Interaction'], bins=30, color='green', edgecolor='black') ax[1].set_title('Feature Interaction') ax[1].set_xlabel('Feature Interaction Value') ax[1].set_ylabel('Frequency') plt.show()
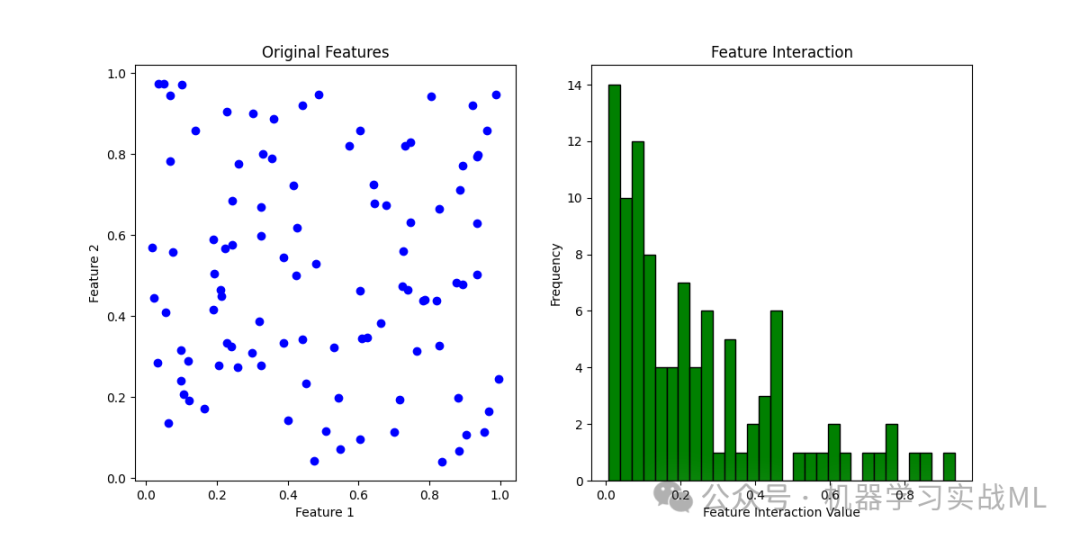
左侧的散点图展示了原始两个特征的关系。
右侧的直方图展示了新创建的交互特征的分布,这种特征可能捕捉了原始特征之间的交互信息。
10. 异常值检测(Outlier Detection)
介绍
异常值检测是识别数据集中异常点的过程,这些异常点与其他数据点显著不同。常用的方法包括 Z-score、IQR(四分位距)和基于模型的检测方法。
核心点
-
目标:识别和处理那些与大多数数据点显著不同的异常点。
-
应用场景:数据清洗、模型提升(移除异常点可能提升模型表现)。
原理
Z-score 方法:计算每个数据点的 Z-score,Z-score 超过某个阈值的数据点被视为异常点。
其中, 是均值, 是标准差。
IQR 方法:计算数据的四分位距(IQR),通常取下限为 ,上限为 。
核心公式
IQR 计算:
异常值下限和上限:
下限
上限
代码示例
import pandas as pd import numpy as np import matplotlib.pyplot as plt from scipy import stats # 创建虚拟数据集 np.random.seed(0) data = np.random.normal(loc=0, scale=1, size=100) data_with_outliers = np.concatenate([data, [10, 12, 15]]) # 计算 Z-score z_scores = stats.zscore(data_with_outliers) # 使用 IQR 方法检测异常值 Q1 = np.percentile(data_with_outliers, 25) Q3 = np.percentile(data_with_outliers, 75) IQR = Q3 - Q1 lower_bound = Q1 - 1.5 * IQR upper_bound = Q3 + 1.5 * IQR # 绘制数据和异常值检测 fig, ax = plt.subplots(figsize=(10, 6)) # 数据分布图 ax.hist(data_with_outliers, bins=20, color='blue', edgecolor='black', alpha=0.7, label='Data Distribution') # 标记异常值 outliers = data_with_outliers[(data_with_outliers < lower_bound) | (data_with_outliers > upper_bound)] ax.scatter(outliers, np.zeros_like(outliers), color='red', marker='x', label='Outliers') ax.set_title('Outlier Detection') ax.set_xlabel('Value') ax.set_ylabel('Frequency') ax.legend() plt.show()
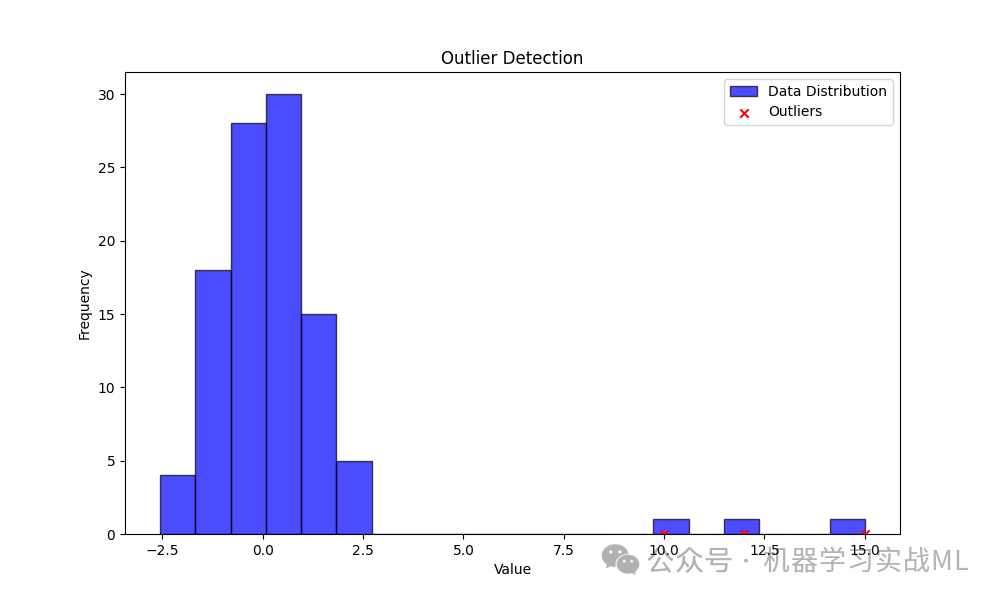
直方图展示了数据的分布,其中大多数数据点集中在较小的范围内。
红色的标记点表示通过 IQR 方法检测到的异常值,这些点显著偏离了其他数据点的分布。
黑客/网络安全学习路线
对于从来没有接触过黑客/网络安全的同学,目前网络安全、信息安全也是计算机大学生毕业薪资相对较高的学科。
大白也帮大家准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
这也是耗费了大白近四个月的时间,吐血整理,文章非常非常长,觉得有用的话,希望粉丝朋友帮忙点个**「分享」「收藏」「在看」「赞」**
网络安全/渗透测试法律法规必知必会****
今天大白就帮想学黑客/网络安全技术的朋友们入门必须先了解法律法律。
【网络安全零基础入门必知必会】什么是黑客、白客、红客、极客、脚本小子?(02)
【网络安全零基础入门必知必会】网络安全专业术语全面解析(05)
【网络安全入门必知必会】《中华人民共和国网络安全法》(06)
【网络安全零基础入门必知必会】《计算机信息系统安全保护条例》(07)
【网络安全零基础入门必知必会】《中国计算机信息网络国际联网管理暂行规定》(08)
【网络安全零基础入门必知必会】《计算机信息网络国际互联网安全保护管理办法》(09)
【网络安全零基础入门必知必会】《互联网信息服务管理办法》(10)
【网络安全零基础入门必知必会】《计算机信息系统安全专用产品检测和销售许可证管理办法》(11)
【网络安全零基础入门必知必会】《通信网络安全防护管理办法》(12)
【网络安全零基础入门必知必会】《中华人民共和国国家安全法》(13)
【网络安全零基础入门必知必会】《中华人民共和国数据安全法》(14)
【网络安全零基础入门必知必会】《中华人民共和国个人信息保护法》(15)
【网络安全零基础入门必知必会】《网络产品安全漏洞管理规定》(16)
网络安全/渗透测试linux入门必知必会
【网络安全零基础入门必知必会】什么是Linux?Linux系统的组成与版本?什么是命令(01)
【网络安全零基础入门必知必会】VMware下载安装,使用VMware新建虚拟机,远程管理工具(02)
【网络安全零基础入门必知必会】VMware常用操作指南(非常详细)零基础入门到精通,收藏这一篇就够了(03)
【网络安全零基础入门必知必会】CentOS7安装流程步骤教程(非常详细)零基入门到精通,收藏这一篇就够了(04)
【网络安全零基础入门必知必会】Linux系统目录结构详细介绍(05)
【网络安全零基础入门必知必会】Linux 命令大全(非常详细)零基础入门到精通,收藏这一篇就够了(06)
【网络安全零基础入门必知必会】linux安全加固(非常详细)零基础入门到精通,收藏这一篇就够了(07)
网络安全/渗透测试****计算机网络入门必知必会****
【网络安全零基础入门必知必会】TCP/IP协议深入解析(非常详细)零基础入门到精通,收藏这一篇就够了(01)
【网络安全零基础入门必知必会】什么是HTTP数据包&Http数据包分析(非常详细)零基础入门到精通,收藏这一篇就够了(02)
【网络安全零基础入门必知必会】计算机网络—子网划分、子网掩码和网关(非常详细)零基础入门到精通,收藏这一篇就够了(03)
网络安全/渗透测试入门之HTML入门必知必会
【网络安全零基础入门必知必会】什么是HTML&HTML基本结构&HTML基本使用(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全零基础入门必知必会】VScode、PhpStorm的安装使用、Php的环境配置,零基础入门到精通,收藏这一篇就够了2
【网络安全零基础入门必知必会】HTML之编写登录和文件上传(非常详细)零基础入门到精通,收藏这一篇就够了3
网络安全/渗透测试入门之Javascript入门必知必会
【网络安全零基础入门必知必会】Javascript语法基础(非常详细)零基础入门到精通,收藏这一篇就够了(01)
【网络安全零基础入门必知必会】Javascript实现Post请求、Ajax请求、输出数据到页面、实现前进后退、文件上传(02)
网络安全/渗透测试入门之Shell入门必知必会
【网络安全零基础入门必知必会】Shell编程基础入门(非常详细)零基础入门到精通,收藏这一篇就够了(第七章)
网络安全/渗透测试入门之PHP入门必知必会
【网络安全零基础入门】PHP环境搭建、安装Apache、安装与配置MySQL(非常详细)零基础入门到精通,收藏这一篇就够(01)
【网络安全零基础入门】PHP基础语法(非常详细)零基础入门到精通,收藏这一篇就够了(02)
【网络安全零基础入门必知必会】PHP+Bootstrap实现表单校验功能、PHP+MYSQL实现简单的用户注册登录功能(03)
网络安全/渗透测试入门之MySQL入门必知必会
【网络安全零基础入门必知必会】MySQL数据库基础知识/安装(非常详细)零基础入门到精通,收藏这一篇就够了(01)
【网络安全零基础入门必知必会】SQL语言入门(非常详细)零基础入门到精通,收藏这一篇就够了(02)
【网络安全零基础入门必知必会】MySQL函数使用大全(非常详细)零基础入门到精通,收藏这一篇就够了(03)
【网络安全零基础入门必知必会】MySQL多表查询语法(非常详细)零基础入门到精通,收藏这一篇就够了(04)
****网络安全/渗透测试入门之Python入门必知必会
【网络安全零基础入门必知必会】之Python+Pycharm安装保姆级教程,Python环境配置使用指南,收藏这一篇就够了【1】
【网络安全零基础入门必知必会】之Python编程入门教程(非常详细)零基础入门到精通,收藏这一篇就够了(2)
python入门教程python开发基本流程控制if … else
python入门教程之python开发可变和不可变数据类型和hash
【网络安全零基础入门必知必会】之10个python爬虫入门实例(非常详细)零基础入门到精通,收藏这一篇就够了(3)
****网络安全/渗透测试入门之SQL注入入门必知必会
【网络安全渗透测试零基础入门必知必会】之初识SQL注入(非常详细)零基础入门到精通,收藏这一篇就够了(1)
【网络安全渗透测试零基础入门必知必会】之SQL手工注入基础语法&工具介绍(2)
【网络安全渗透测试零基础入门必知必会】之SQL注入实战(非常详细)零基础入门到精通,收藏这一篇就够了(3)
【网络安全渗透测试零基础入门必知必会】之SQLmap安装&实战(非常详细)零基础入门到精通,收藏这一篇就够了(4)
【网络安全渗透测试零基础入门必知必会】之SQL防御(非常详细)零基础入门到精通,收藏这一篇就够了(4)
****网络安全/渗透测试入门之XSS攻击入门必知必会
【网络安全渗透测试零基础入门必知必会】之XSS攻击基本概念和原理介绍(非常详细)零基础入门到精通,收藏这一篇就够了(1)
网络安全渗透测试零基础入门必知必会】之XSS攻击获取用户cookie和用户密码(实战演示)零基础入门到精通收藏这一篇就够了(2)
【网络安全渗透测试零基础入门必知必会】之XSS攻击获取键盘记录(实战演示)零基础入门到精通收藏这一篇就够了(3)
【网络安全渗透测试零基础入门必知必会】之xss-platform平台的入门搭建(非常详细)零基础入门到精通,收藏这一篇就够了4
【网络安全渗透测试入门】之XSS漏洞检测、利用和防御机制XSS游戏(非常详细)零基础入门到精通,收藏这一篇就够了5
****网络安全/渗透测试入门文件上传攻击与防御入门必知必会
【网络安全渗透测试零基础入门必知必会】之什么是文件包含漏洞&分类(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全渗透测试零基础入门必知必会】之cve实际漏洞案例解析(非常详细)零基础入门到精通, 收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之PHP伪协议精讲(文件包含漏洞)零基础入门到精通,收藏这一篇就够了3
【网络安全渗透测试零基础入门必知必会】之如何搭建 DVWA 靶场保姆级教程(非常详细)零基础入门到精通,收藏这一篇就够了4
【网络安全渗透测试零基础入门必知必会】之Web漏洞-文件包含漏洞超详细全解(附实例)5
【网络安全渗透测试零基础入门必知必会】之文件上传漏洞修复方案6
****网络安全/渗透测试入门CSRF渗透与防御必知必会
【网络安全渗透测试零基础入门必知必会】之CSRF漏洞概述和原理(非常详细)零基础入门到精通, 收藏这一篇就够了1
【网络安全渗透测试零基础入门必知必会】之CSRF攻击的危害&分类(非常详细)零基础入门到精通, 收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之XSS与CSRF的区别(非常详细)零基础入门到精通, 收藏这一篇就够了3
【网络安全渗透测试零基础入门必知必会】之CSRF漏洞挖掘与自动化工具(非常详细)零基础入门到精通,收藏这一篇就够了4
【网络安全渗透测试零基础入门必知必会】之CSRF请求伪造&Referer同源&置空&配合XSS&Token值校验&复用删除5
****网络安全/渗透测试入门SSRF渗透与防御必知必会
【网络安全渗透测试零基础入门必知必会】之SSRF漏洞概述及原理(非常详细)零基础入门到精通,收藏这一篇就够了 1
【网络安全渗透测试零基础入门必知必会】之SSRF相关函数和协议(非常详细)零基础入门到精通,收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之SSRF漏洞原理攻击与防御(非常详细)零基础入门到精通,收藏这一篇就够了3**
**
****网络安全/渗透测试入门XXE渗透与防御必知必会
【网络安全渗透测试零基础入门必知必会】之XML外部实体注入(非常详细)零基础入门到精通,收藏这一篇就够了1
网络安全渗透测试零基础入门必知必会】之XXE的攻击与危害(非常详细)零基础入门到精通,收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之XXE漏洞漏洞及利用方法解析(非常详细)零基础入门到精通,收藏这一篇就够了3
【网络安全渗透测试零基础入门必知必会】之微信XXE安全漏洞处理(非常详细)零基础入门到精通,收藏这一篇就够了4
****网络安全/渗透测试入门远程代码执行渗透与防御必知必会
【网络安全渗透测试零基础入门必知必会】之远程代码执行原理介绍(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全零基础入门必知必会】之CVE-2021-4034漏洞原理解析(非常详细)零基础入门到精通,收藏这一篇就够了2
【网络安全零基础入门必知必会】之PHP远程命令执行与代码执行原理利用与常见绕过总结3
【网络安全零基础入门必知必会】之WEB安全渗透测试-pikachu&DVWA靶场搭建教程,零基础入门到精通,收藏这一篇就够了4
****网络安全/渗透测试入门反序列化渗透与防御必知必会
【网络安全零基础入门必知必会】之什么是PHP对象反序列化操作(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全零基础渗透测试入门必知必会】之php反序列化漏洞原理解析、如何防御此漏洞?如何利用此漏洞?2
【网络安全渗透测试零基础入门必知必会】之Java 反序列化漏洞(非常详细)零基础入门到精通,收藏这一篇就够了3
【网络安全渗透测试零基础入门必知必会】之Java反序列化漏洞及实例解析(非常详细)零基础入门到精通,收藏这一篇就够了4
【网络安全渗透测试零基础入门必知必会】之CTF题目解析Java代码审计中的反序列化漏洞,以及其他漏洞的组合利用5
网络安全/渗透测试**入门逻辑漏洞必知必会**
【网络安全渗透测试零基础入门必知必会】之一文带你0基础挖到逻辑漏洞(非常详细)零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门暴力猜解与防御必知必会
【网络安全渗透测试零基础入门必知必会】之密码安全概述(非常详细)零基础入门到精通,收藏这一篇就够了1
【网络安全渗透测试零基础入门必知必会】之什么样的密码是不安全的?(非常详细)零基础入门到精通,收藏这一篇就够了2
【网络安全渗透测试零基础入门必知必会】之密码猜解思路(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之利用Python暴力破解邻居家WiFi密码、压缩包密码,收藏这一篇就够了4
【网络安全渗透测试零基础入门必知必会】之BurpSuite密码爆破实例演示,零基础入门到精通,收藏这一篇就够了5
【网络安全渗透测试零基础入门必知必会】之Hydra密码爆破工具使用教程图文教程,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之暴力破解medusa,零基础入门到精通,收藏这一篇就够了7
【网络安全渗透测试零基础入门必知必会】之Metasploit抓取密码,零基础入门到精通,收藏这一篇就够了8
****网络安全/渗透测试入门掌握Redis未授权访问漏洞必知必会
【网络安全渗透测试零基础入门必知必会】之Redis未授权访问漏洞,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Redis服务器被攻击后该如何安全加固,零基础入门到精通,收藏这一篇就够了**
**
网络安全/渗透测试入门掌握**ARP渗透与防御关必知必会**
【网络安全渗透测试零基础入门必知必会】之ARP攻击原理解析,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之ARP流量分析,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之ARP防御策略与实践指南,零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门掌握系统权限提升渗透与防御关****必知必会
【网络安全渗透测试零基础入门必知必会】之Windows提权常用命令,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Windows权限提升实战,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之linux 提权(非常详细)零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门掌握Dos与DDos渗透与防御相关****必知必会
【网络安全渗透测试零基础入门必知必会】之DoS与DDoS攻击原理(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Syn-Flood攻击原理解析(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之IP源地址欺骗与dos攻击,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之SNMP放大攻击原理及实战演示,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之NTP放大攻击原理,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之什么是CC攻击?CC攻击怎么防御?,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之如何防御DDOS的攻击?零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门掌握无线网络安全渗透与防御相关****必知必会
【网络安全渗透测试零基础入门必知必会】之Aircrack-ng详细使用安装教程,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之aircrack-ng破解wifi密码(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之WEB渗透近源攻击,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之无线渗透|Wi-Fi渗透思路,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之渗透WEP新思路Hirte原理解析,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之WPS的漏洞原理解析,零基础入门到精通,收藏这一篇就够了
网络安全/渗透测试入门掌握木马免杀问题与防御********必知必会
【网络安全渗透测试零基础入门必知必会】之Metasploit – 木马生成原理和方法,零基础入门到精通,收藏这篇就够了
【网络安全渗透测试零基础入门必知必会】之MSF使用教程永恒之蓝漏洞扫描与利用,收藏这一篇就够了
网络安全/渗透测试入门掌握Vulnhub靶场实战********必知必会
【网络安全渗透测试零基础入门必知必会】之Vulnhub靶机Prime使用指南,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Vulnhub靶场Breach1.0解析,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之vulnhub靶场之DC-9,零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Vulnhub靶机Kioptrix level-4 多种姿势渗透详解,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之Vulnhub靶场PWNOS: 2.0 多种渗透方法,收藏这一篇就够了
网络安全/渗透测试入门掌握社会工程学必知必会
【网络安全渗透测试零基础入门必知必会】之什么是社会工程学?定义、类型、攻击技术,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之社会工程学之香农-韦弗模式,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之社工学smcr通信模型,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之社会工程学之社工步骤整理(附相应工具下载)收藏这一篇就够了
网络安全/渗透测试入门掌握********渗透测试工具使用******必知必会**
2024版最新Kali Linux操作系统安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
【网络安全渗透测试零基础入门必知必会】之渗透测试工具大全之Nmap安装使用命令指南,零基础入门到精通,收藏这一篇就够了
2024版最新AWVS安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新burpsuite安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新owasp_zap安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新Sqlmap安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新Metasploit安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新Nessus下载安装激活使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
2024版最新Wireshark安装使用教程(非常详细)零基础入门到精通,收藏这一篇就够了
觉得有用的话,希望粉丝朋友帮大白点个**「分享」「收藏」「在看」「赞」**

黑客/网络安全学习包


资料目录
-
成长路线图&学习规划
-
配套视频教程
-
SRC&黑客文籍
-
护网行动资料
-
黑客必读书单
-
面试题合集
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

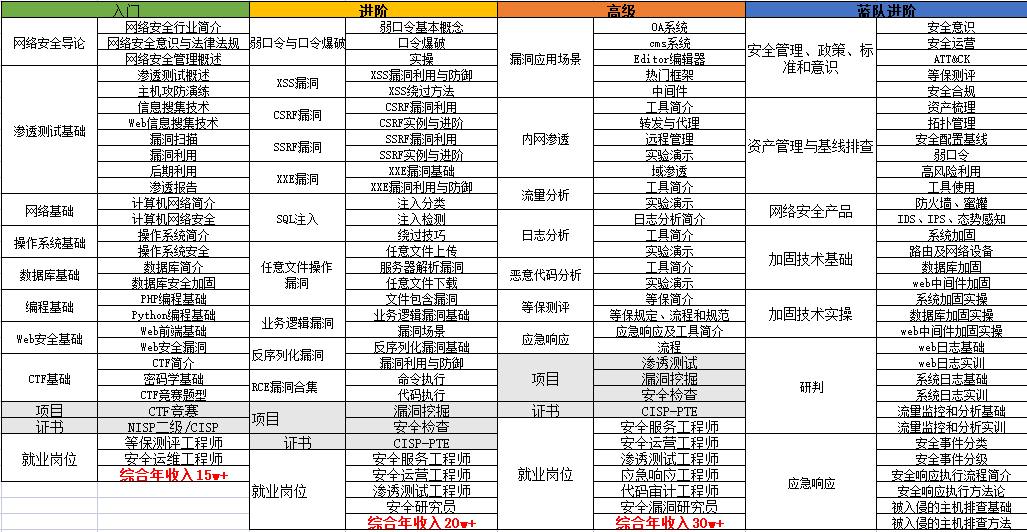
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
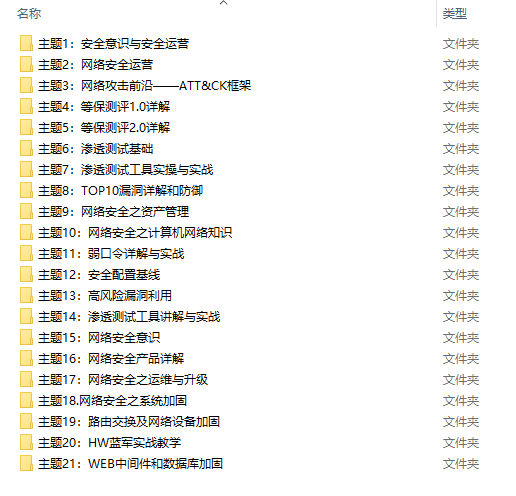
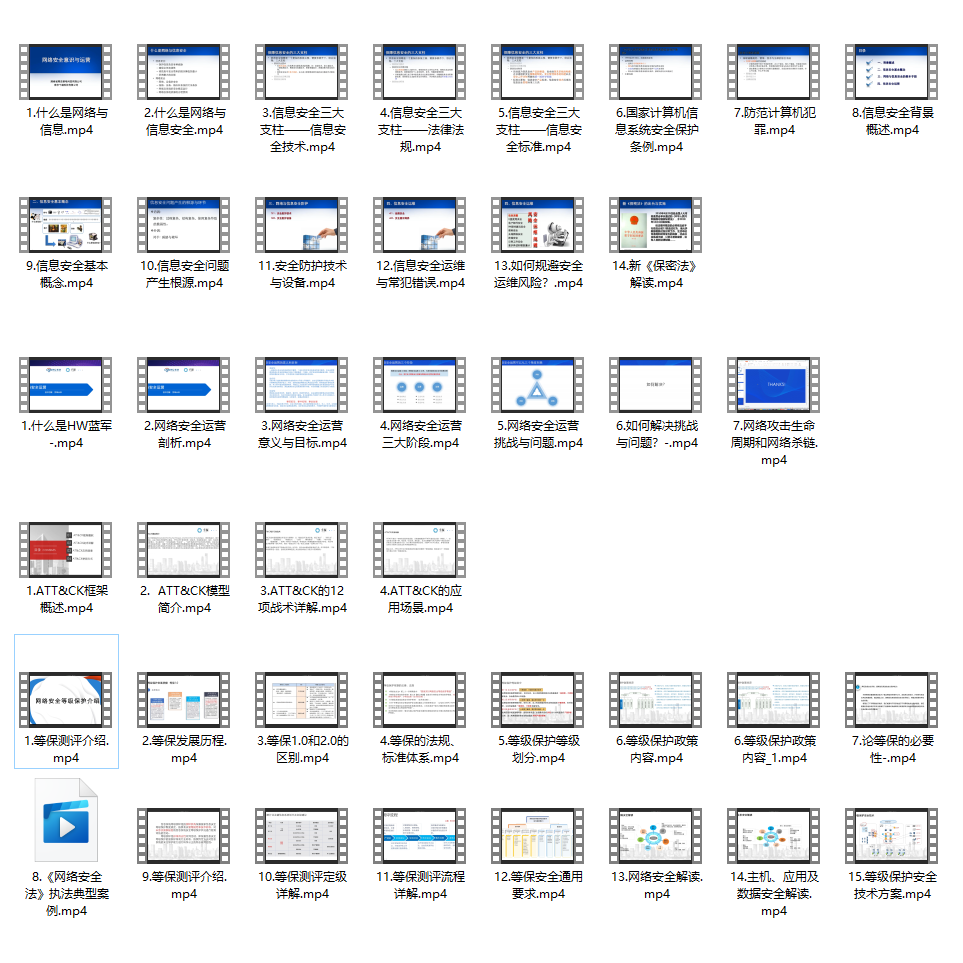
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.SRC&黑客文籍
大家最喜欢也是最关心的SRC技术文籍&黑客技术也有收录
SRC技术文籍:

黑客资料由于是敏感资源,这里不能直接展示哦!
4.护网行动资料
其中关于HW护网行动,也准备了对应的资料,这些内容可相当于比赛的金手指!
5.黑客必读书单
**

**
6.面试题合集
当你自学到这里,你就要开始思考找工作的事情了,而工作绕不开的就是真题和面试题。
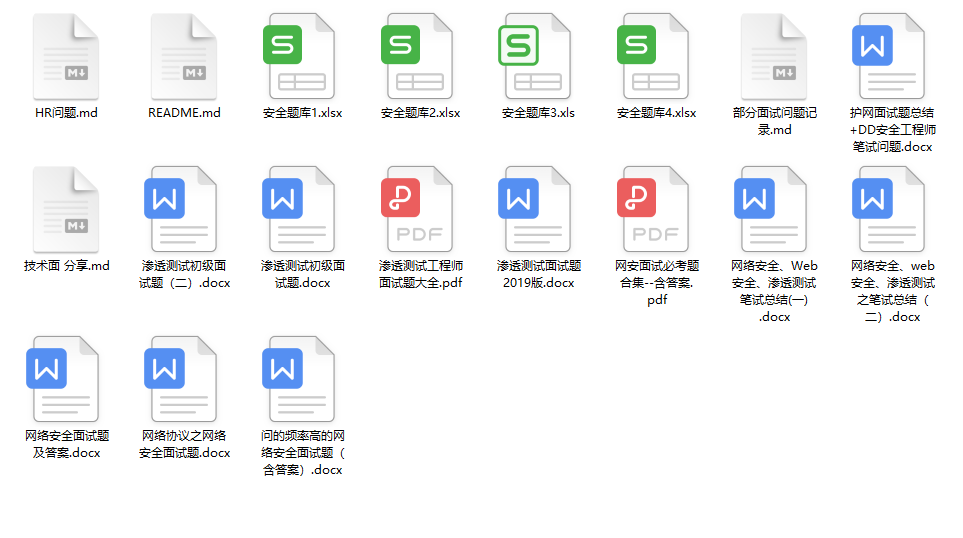
更多内容为防止和谐,可以扫描获取~

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









