







一、逻辑节点概述与分类
对于任何编程语言的学习者,逻辑判断与流程控制都是必修课。在n8n可视化工作流开发中,流程控制节点扮演着编程语言中if/else、循环等核心逻辑的角色。这些节点集中归类于Flow类目下,共包含9种核心控制节点:
| 节点名称 | 功能描述 |
|---|---|
| Filter | 数据过滤,根据条件筛选输入项 |
| If | 条件分支,将数据流分为True/False两个分支 |
| Loop Over Items | 迭代处理,逐项执行子流程并汇总结果 |
| Merge | 数据合并,整合多个分支数据 |
| Compare Datasets | 数据集对比,决策最终输出 |
| Execute Workflow | 子流程调用,执行其他工作流 |
| Stop and Error | 异常终止,中断流程并抛出错误 |
| Switch | 多路路由,实现复杂条件分支 |
| Wait | 延时控制,规避API速率限制 |
二、四大核心节点实战案例
1. 单条件分支处理(IF节点)
场景需求:处理Google Sheets中的文章数据,对含"评论"的标题进行特殊处理
实现方案:
-
配置Google Sheets节点读取原始数据
-
添加If节点设置过滤条件:
{{ $json['标题'] }} contains "评论" -
输出面板显示True Branch(85条)和False Branch(2710条)
进阶技巧:
-
支持AND/OR逻辑组合:
({{ $json['标题'] }} contains "评论") AND ({{ $json['阅读量'] }} > 1000) -
支持6种数据类型判断(字符串、数字、日期等)
2. 多条件路由分发(Switch节点)
场景需求:对"评论"、"高质量"、"要闻"三类文章分别处理
实现方案:
-
配置Switch节点添加三个条件分支:
Rule1: {{ $json['标题'] }} contains "评论" Rule2: {{ $json['标题'] }} contains "高质量" Rule3: {{ $json['标题'] }} contains "要闻" -
默认采用串联模式(首次匹配优先)
-
开启并联模式:Settings → Send data to all matching outputs
性能对比:
| 模式 | 执行效率 | 数据重复 | 适用场景 |
|---|---|---|---|
| 串联模式 | 高 | 无 | 互斥分类 |
| 并联模式 | 中 | 允许 | 多标签重叠分类 |
3. 多分支数据聚合(Merge节点)
场景需求:合并三个处理分支的结果写入数据库
实现步骤:
-
使用两次Merge节点级联合并:
Merge1(分支A+B) → Merge2(合并结果+C) -
选择Append合并模式:
-
要求所有分支数据结构完全一致
-
保留原始数据顺序
-
合并模式对照表:
| 模式 | 数据结构要求 | 输出结果特征 |
|---|---|---|
| Append | 完全一致 | 简单纵向堆叠 |
| Combine | 字段互补 | 横向字段合并 |
| Merge by position | 顺序严格对应 | 按位置强制合并 |
4. 循环控制与批处理(Loop节点)
场景需求:安全获取多个RSS源内容
常规方案:
-
多数节点内置循环处理(自动遍历数组)
-
特殊需求需显式使用Loop Over Items:
Batch Size = 10 // 每批处理量
批处理优势:
-
性能控制:限制并发数量
-
容错机制:单批次失败不影响整体
-
频率控制:配合Wait节点实现速率限制
实战配置:
三、最佳实践建议
-
性能优化:优先使用节点内置循环,减少显式Loop使用
-
错误处理:关键节点后接Stop and Error阻断异常传播
-
调试技巧:利用节点右侧执行面板查看实时数据流
资料推荐
四、案例详解
案例1: Workflow 中对包含“评论”单独处理
我有一张数据表,其中一列是文章标题,我希望在后续的 Workflow 中对包含“评论”的内容单独处理,我该如何操作?(IF 节点用法)
解释:
在这个 case 中,我们使用了 If 节点,使用它来判断标题中是否存在“评论”两个字。
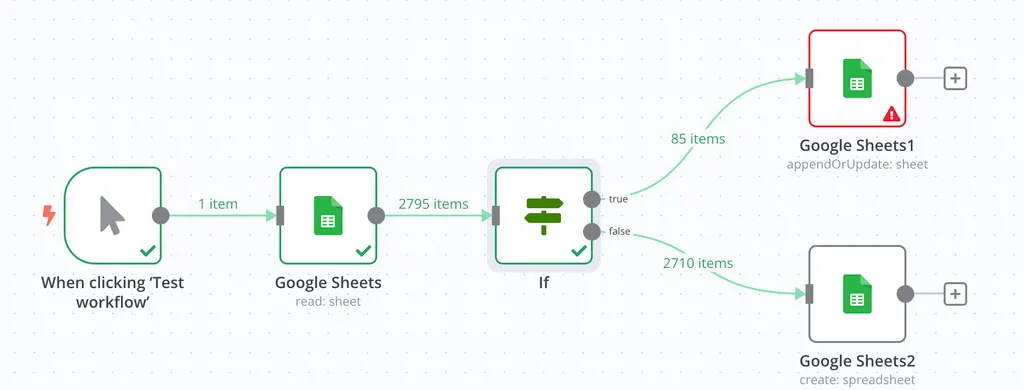
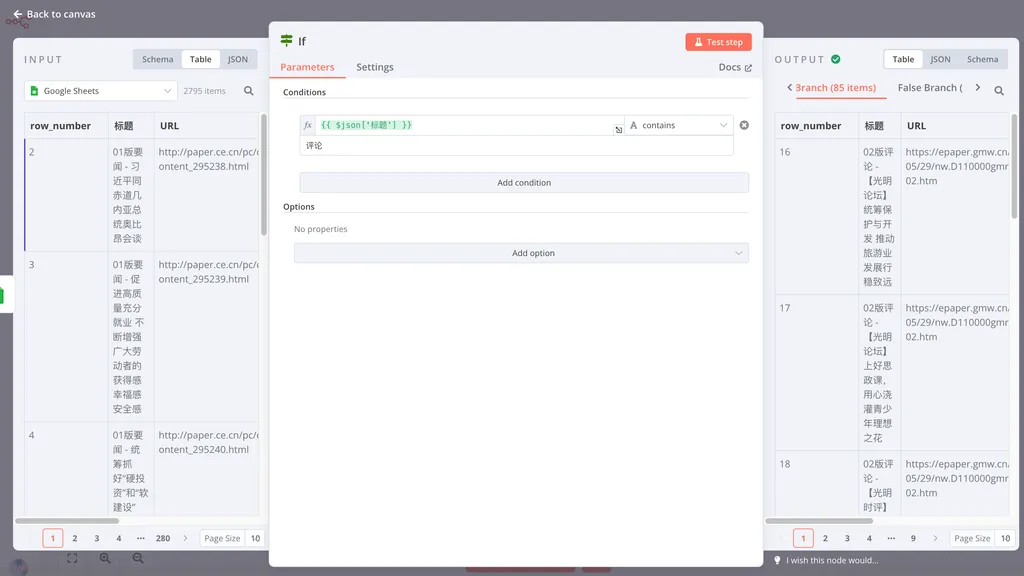
整个 Workflow 首先从给定的 Google Sheets 中读取所有数据,然后在 If 节点里,我们添加了一个 Conditions(条件),这个 Condition 是以 {{ $json['标题'] }} 为判断源,如果它 contains(包含)“评论”二字,就返回 true,否则就返回 false。
在 Output 面板,我们可以看到后续 Workflow 被分为了 True Branch(85 个 item)和 False Branch(2710 个 item)。
测试运行后,回到编辑器页面,我们会看到,对应 True Branch 的 85 个数据被分流到了上面的分叉,False Branch 的分流到了下面的分叉,方便我们可以做后续不同的处理。
- If 的 Conditions 有好多种逻辑,支持字符串、数字、日期与时间、布朗、数组和对象字段类型的判断,这里只做最简单的介绍。对应的判断逻辑你可以在需要的时候自行尝试,或在 n8n 官方文档中查阅。
- If 支持多个 Conditions 之间用 AND(且)与 OR(或)连接。比如你可以在一个 If 中设置它判断“包含评论”且“包含高质量”,或者实质它判断“包含评论”或“包含高质量”。
- 分批处理数据,以控制 Workflow 的性能消耗;
- 你十分确定输入进来的数据有时会导致节点运行错误,你希望在某一行运行错误的情况下,剩下的行依然能继续处理;
- 你希望控制数据处理的频度,以保障第三方 API 可以正常运行。
案例2:对“包含评论”、“包含高质量”、”包含要闻“的内容分别单独处理
我有一张数据表,其中一列是文章标题,我希望在后续的 Workflow 中对“包含评论”、“包含高质量”、”包含要闻“的内容分别单独处理,我该如何操作?(Switch 节点用法)
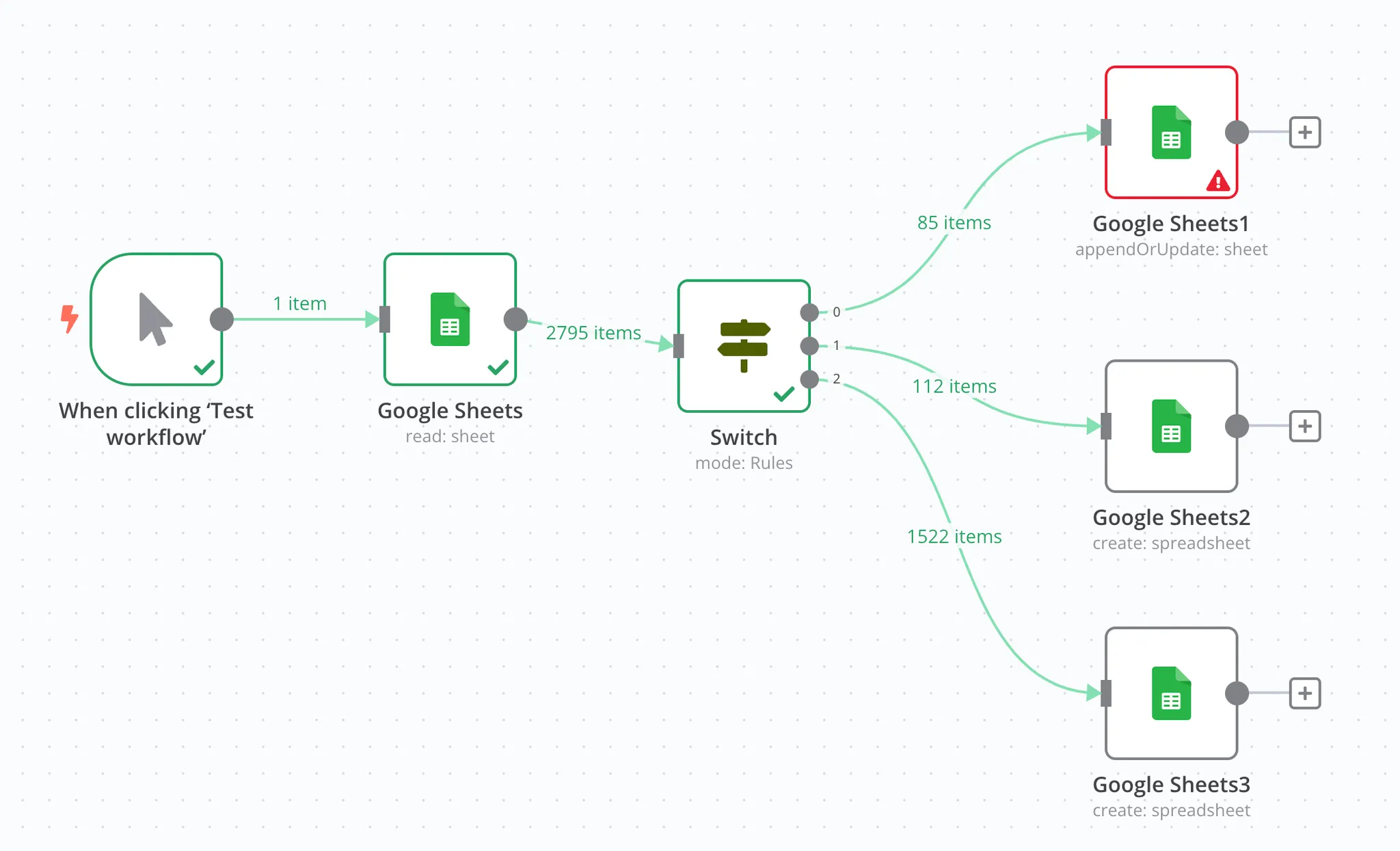
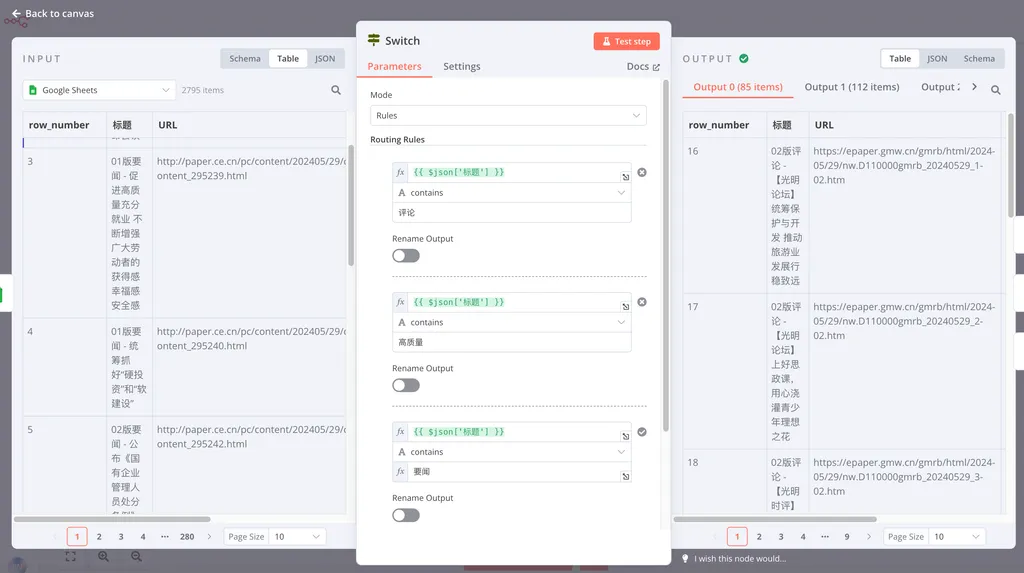
经过 If 的学习,你应该会意识到,这个案例中的判断,其实可以通过设置多层 If 来实现。比如先处理包含评论的,再处理包含高质量的,最后再处理包含要闻的。但这样会增加 Workflow 的复杂程度,还会降低它的运行效率。因此,在面临这种需要处理两个以上分叉路径的逻辑时,我们就可以用更复杂的 Switch 来处理。
Switch 节点支持你添加多个判断逻辑,它会根据每个判断逻辑将匹配的数据送往对应的分叉。可以看到,在我们运行之后,数据流被分为了三叉,分别是标题里有评论的,标题里有高质量的和标题里有要闻的。
在默认情况下,Switch 节点遵循串联的判断模式,也就是它会按照你在参数页面配置路由规则的上下顺序,从上到下判断。一条数据如果已经被匹配到了分叉 1,它就不会再出现在分叉 2 里,哪怕它也符合分叉 2 的判断逻辑。
如果,你需要 Switch 节点在各路由规则之间采用并联方式判断,那么你需要在 Options 里开启 Send data to all matching outputs。这样的话,一条数据在同时满足分叉 1 和分叉 2 的情况下,它就会同时出现在两个分叉里。
案例3:合并回一个数据流写进库里
我从数据表中筛选出了对“包含评论”、“包含高质量”和”包含要闻“的内容,我现在分别对他们的数据处理已经完成,现在希望把它们合并回一个数据流写进库里,怎么办?(Merge 节点用法)
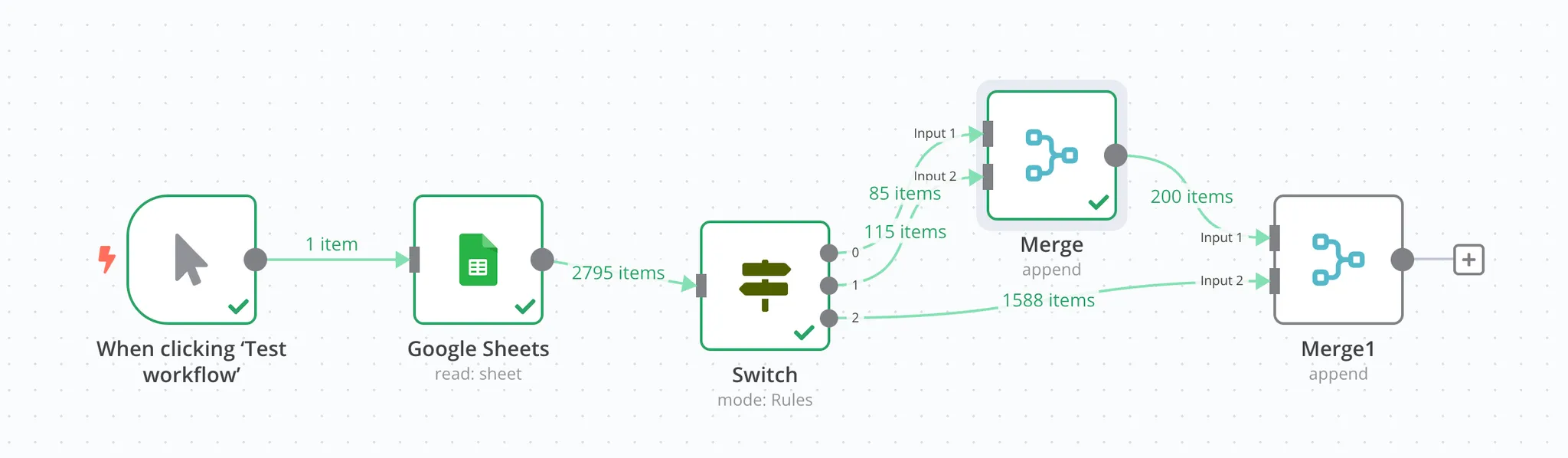
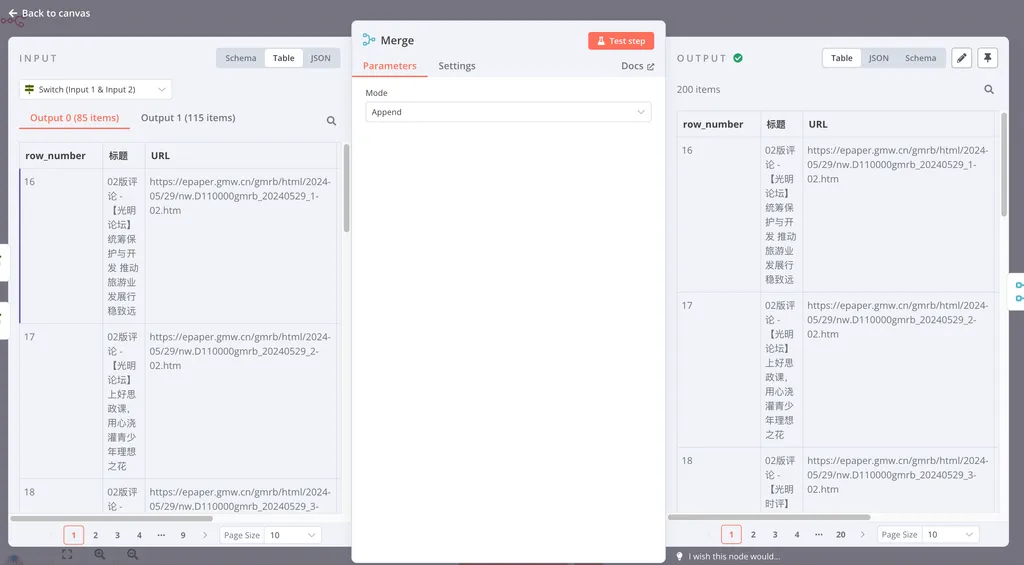
在这里,我们需要使用 Merge 节点。
由于 Merge 节点一次只能合并两个分叉,所以我们要合并两次,先合并两个,再将第三个与已经合并后的分叉进行合并。
由于我们的三个分叉出来的数据流在 表头(属性) 上是一致的,因此我们可以直接选择 Append 作为合并模式。
Merge 节点支持三种合并模式,官方文档给出了详细的解释,直接看图会更加清晰:
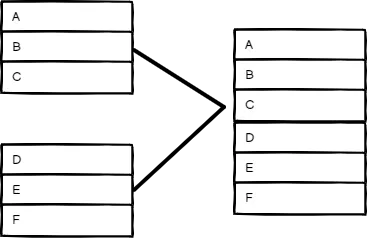 | 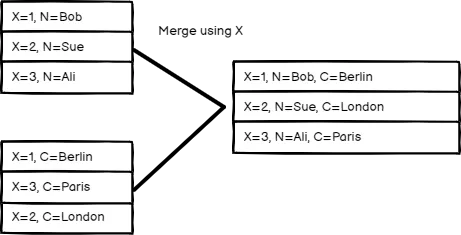 | 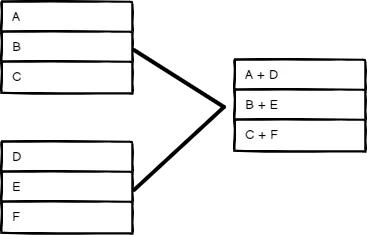 |
| Append | Combine | Merge by position |
简答来说:
Append - 直接将分叉 2 的数据加在分叉 1 的后面,适用于表头 表头(属性) 完全一致的两个分叉合并。
Combine - 将分叉 2 与分叉 1 同一索引的不同表头(属性)合并到一起,比如:分叉 2 里有姓名和年龄,分叉 1 里有姓名和性别,通过 Combine,你就能获得一个包含姓名、年龄和性别的数据表。
Merge by Position - 按分叉 2 和分叉 1 的数据位置,直接把两个数据强加在一起。适用范围比较窄,我想不到啥用处。
案例4:从多个 RSS 处获取内容怎么办?(Loop 节点用法)
n8n 中支持 Loop Over Items 节点来创造一个循环。但是,在大部分情况下你不需要该节点来创造循环。
哈哈,是不是被绕晕了?
事情是这样的,当我们在日常编程的时候,我们如果需要对一个数据表中的每一行进行处理,我们首先想到的是需要构造一个循环,但对于 n8n 来说它考虑到了这种常见用法,因此许多 n8n 中的节点是内置循环的。
比如,上游节点传来了一个包含 10 行包含 URL 的数据表,你在当前节点想用 RSS Read 读取这 10 个 RSS 地址里的内容,你实际上不需要用到 Loop Over Items。在默认情况下,当你就将一个数组变量拖动到当前节点的时候,当前节点就会将数组变量中的每一行都执行一遍:
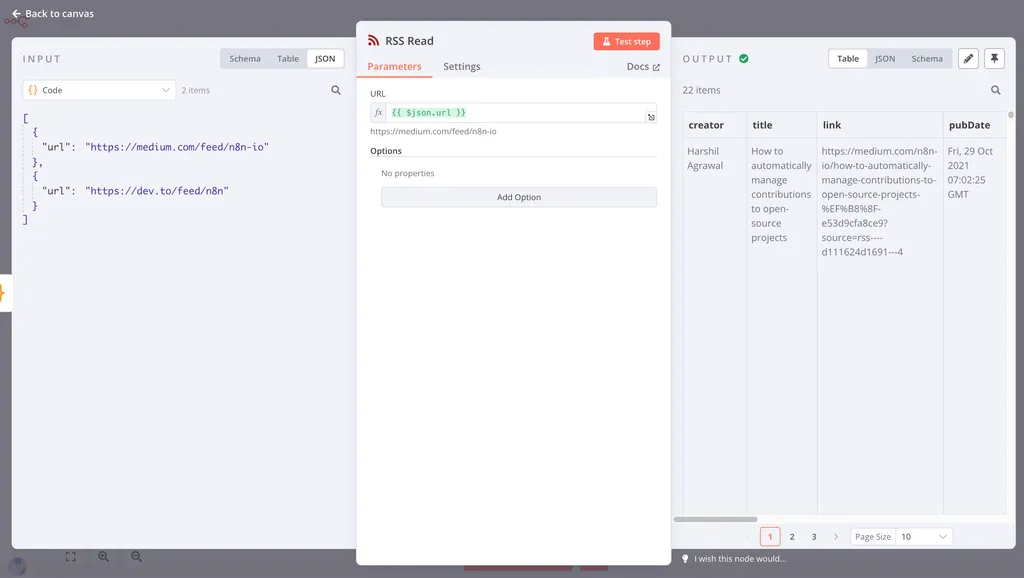
如果你想让某个节点在处理某个数组变量里的值时,只运行一次,你需要在节点的 Settings 页面打开 Execute Once 选项。
n8n 节点中的内置循环,甚至包含了依据条件结束循环,你只需要这样连接一个 If 节点即可:
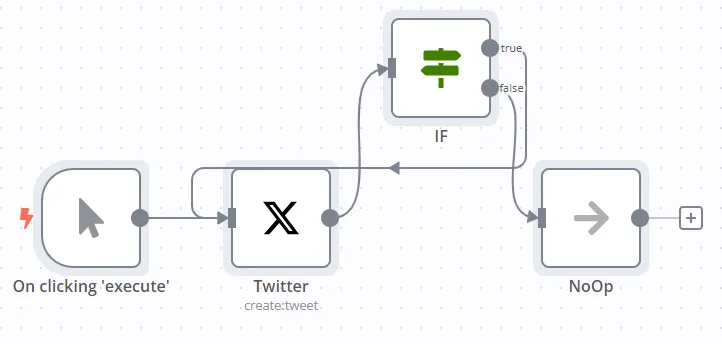
在这个官方示例中,If 的 Ture 分叉被指回了 Twitter 节点的输入端。而 If 节点中的判断条件为:
{{$runIndex}} Smaller 4这意味着,在 Twitter 节点被运行到第 5 次时,节点会进入 false 分叉结束循环。
这个示例 Workflow 的结果是,会自动在 Twitter 上发送 5 遍 Hello from n8n!
但是,在一些特殊的情况下(比如想要分批处理),我就想用 Loop 来构造循环怎么办?
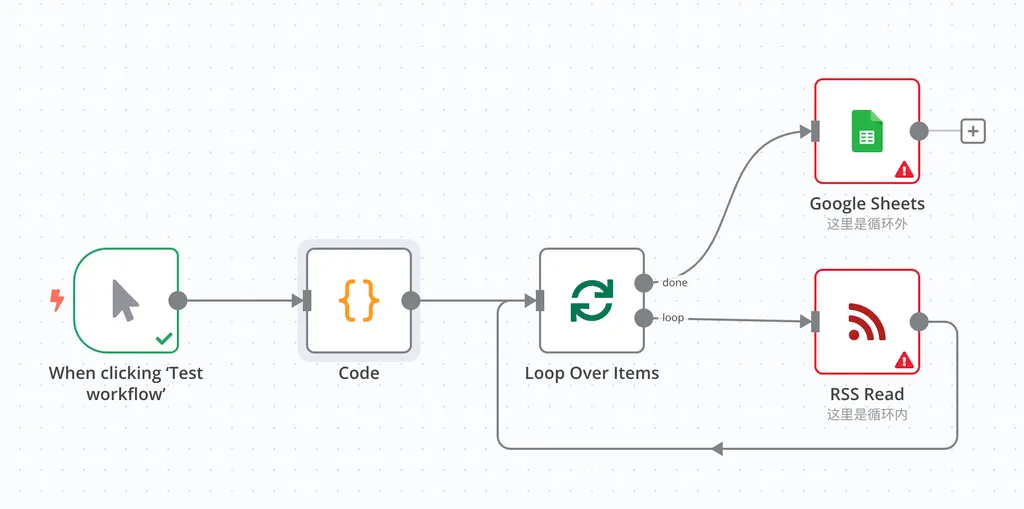
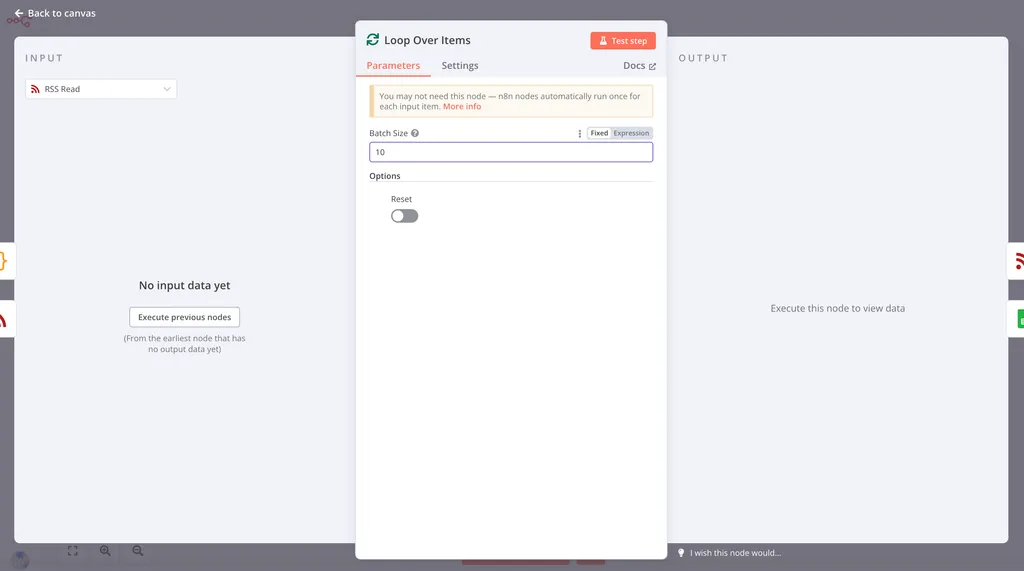
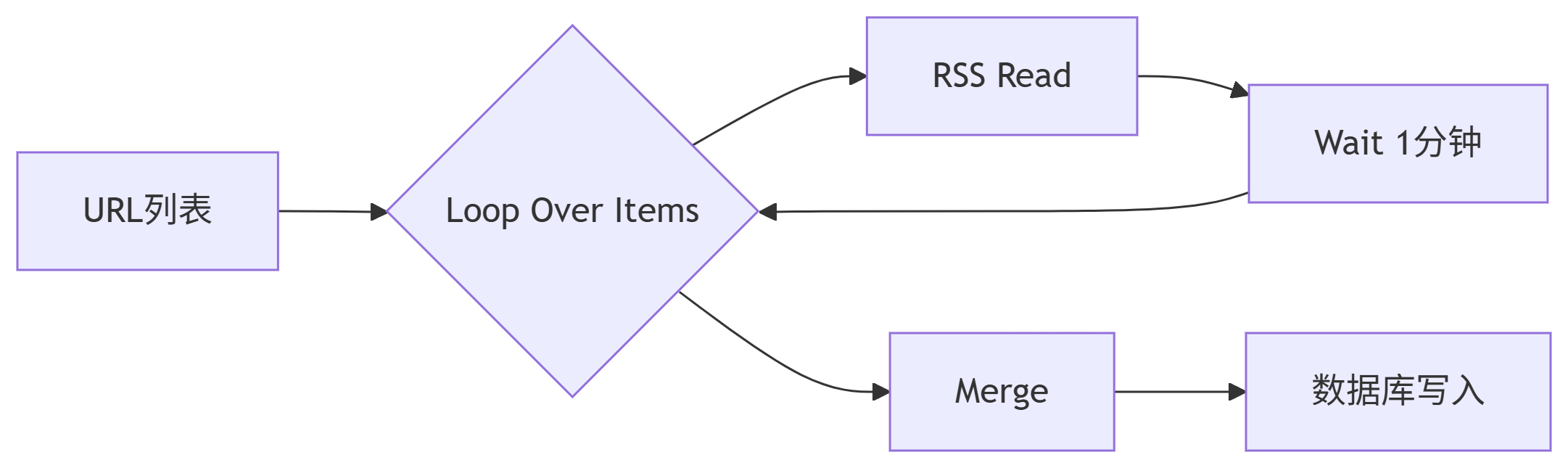
在这个 Workflow 中,我们就添加了一个 Loop Over Items,它会将上游传递过来的 URL,分批次循环执行 RSS Read。当所有的批次执行完毕之后,数据被合并推送到 done 分叉,执行后续的循环外操作。
与直接用 RSS Read 内置循环的区别是,在这里我将 Loop Over Items 的 Batch Size 参数设置为了 10。这意味着,它会首先将上游传递过来的数据,拆分成 10 行一包,每次只向循环中的 RSS Read 发送 10 包。这时,如果我在循环内加一个 Wait 节点,并且设置为 Wait 1 分钟,就可以有效的控制每分钟只对 10 个 RSS 地址发起请求,拉长请求间隔,避免被对方服务器封禁。
根据官方说明,建议使用 Loop Over Items 的场景有:
- 分批处理数据,以控制 Workflow 的性能消耗;
- 你十分确定输入进来的数据有时会导致节点运行错误,你希望在某一行运行错误的情况下,剩下的行依然能继续处理;
- 你希望控制数据处理的频度,以保障第三方 API 可以正常运行。
如果觉得有帮助,欢迎点赞⭐收藏!接下来会持续更新n8n系列教程。


















 4628
4628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









