







你是否遇到过需要批量处理大量文本数据,却苦于手动操作效率低下?本文将手把手教你如何用 n8n + 大模型(如Gemini) 搭建自动化流程,实现工单智能分类。即使你是 零基础新手,也能跟着教程完成:
✅ 从Google Sheets读取数据
✅ 调用AI模型自动分析工单
✅ 将结果回填至表格
全程 可视化操作,无需代码,特别适合处理 重复性文本分析任务。文内含 避坑指南 和 Prompt优化技巧,助你快速落地AI自动化!
1. 文章适合人群
本文适合以下读者:
-
对n8n完全没有了解的新手
-
运维经验几乎为零的初学者
-
希望将大模型能力集成到工作流程中的开发者
本文将基于一个实际案例详细讲解n8n的使用方法,不仅会介绍基础操作,还会分享:
-
开发过程中遇到的典型问题及解决方案
-
从用户心理角度分析的操作建议
-
降低n8n学习曲线的实用技巧
2. 环境准备
在开始前,请确保你已经:
-
购买了n8n官方云服务版
-
或在服务器上部署了n8n(部署方法见:n8n 中文系列教程_06.选择适合的 n8n 安装部署方式:完整指南-CSDN博客)
重要提示:本文涉及的程序需要使用Google API,请提前准备好相关账号和访问权限。
工作思路
程序设计原则
- 免费:尽量使用免费的 API;
- 可复用;
工作方法
- 一切看不懂的东西,第一时间询问 ChatGPT,比如错误码看不懂,就可以直接问 ChatGPT;
- 理解 n8n 的界面设计思路,可以阅读上篇分享
n8n 中文系列教程_07.全面解析n8n界面:从入门到精通-CSDN博客 - 每个步骤都要做单步调试;
- 涉及到大模型的环境,单步调试的循环次数要降低,以节省 API 调用次数;
- 大模型 API 往往会在其官网提供调试环境,这种调试环境给出的结果和 API 实际调用可能会有出入,所以在调教 Prompt 时,单步调试 + 看 log 是非常有有必要的,值得庆幸的是 n8n 的 log看起来很好懂。
3. 需求场景分析
3.1 业务背景
假设你是一个SaaS系统负责人,面临以下情况:
-
客户每天产生超过100个疑问,形成工单提交给客服
-
你计划实施3项系统改进
-
需要评估这些改进能解决多少现有问题(即能减少多少工单)
3.2 技术需求
本质上,这是一个文本匹配问题:
-
输入:所有工单的聊天记录内容
-
输出:每条记录与3个已知问题的匹配结果
4. 为什么选择n8n+大模型方案?
4.1 传统方案的局限性
| 方案 | 问题 |
|---|---|
| 直接上传Excel给ChatGPT/Kimi | 1. RAG读取方式无法保证逐行处理 2. 上下文限制(约3万字/次) 3. 3000工单需循环50次 |
| 非结构化数据直接输入 | 1. 大模型幻觉问题 2. 输出结果难以结构化 |
4.2 n8n方案的优势
-
精准控制:每次只处理一个工单,确保质量
-
结构化输出:便于后续统计分析
-
自动化流程:一次配置,重复使用
-
成本优化:仅对必要内容调用大模型API
核心设计原则:将AI作为流程的一部分而非全部,保持人类对关键决策的控制。
5. 完整实现步骤
5.1 第一步:程序触发设置
-
创建新Workflow
-
选择触发器类型:
-
手动触发(适合低频批量处理)
-
定时触发(适合定期执行)
-
文件变化触发(适合实时处理)
-
推荐选择:手动触发(每月执行一次)
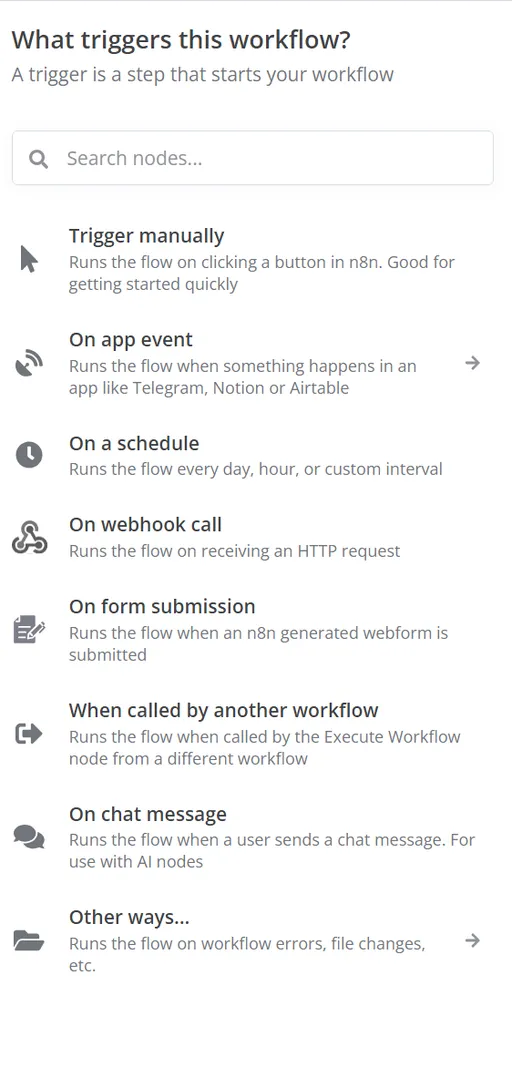
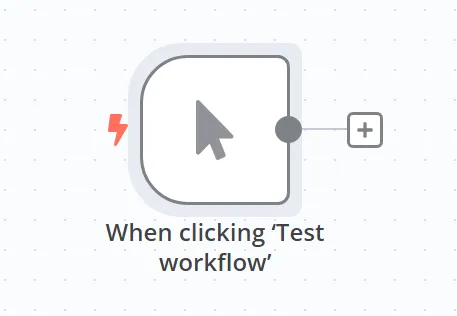
第一个节点如下图所示:
5.2 第二步:工单数据获取
5.2.1 数据源选择
| 选项 | 优缺点 | 适用场景 |
|---|---|---|
| Google Sheets | 云端协作方便 | 推荐选择 |
| 本地文件 | 需服务器访问权限 | 不推荐 |
5.2.2 Google Sheets配置
-
添加"Google Sheets - Get rows in sheet"节点
-
配置OAuth2认证:
-
搜索关键词:"how to create Google sheets OAuth2 single service"
-
按教程创建API凭证
-
常见问题解决:
-
权限错误:确保服务账号有编辑权限
-
读取失败:检查表格URL格式
-
测试数据读取:
-
成功时会显示"X items"(如"7 items")
-
 |  |
5.3 第三步:集成大模型
5.3.1 模型选择
-
添加"Basic LLM Chain"节点
-
推荐模型:
-
Google Gemini(免费额度)
-
OpenAI GPT(需API Key)
-
免费API获取:
-
创建新Prompt获取API Key
5.3.2 模型配置
-
删除默认的Chat Trigger
-
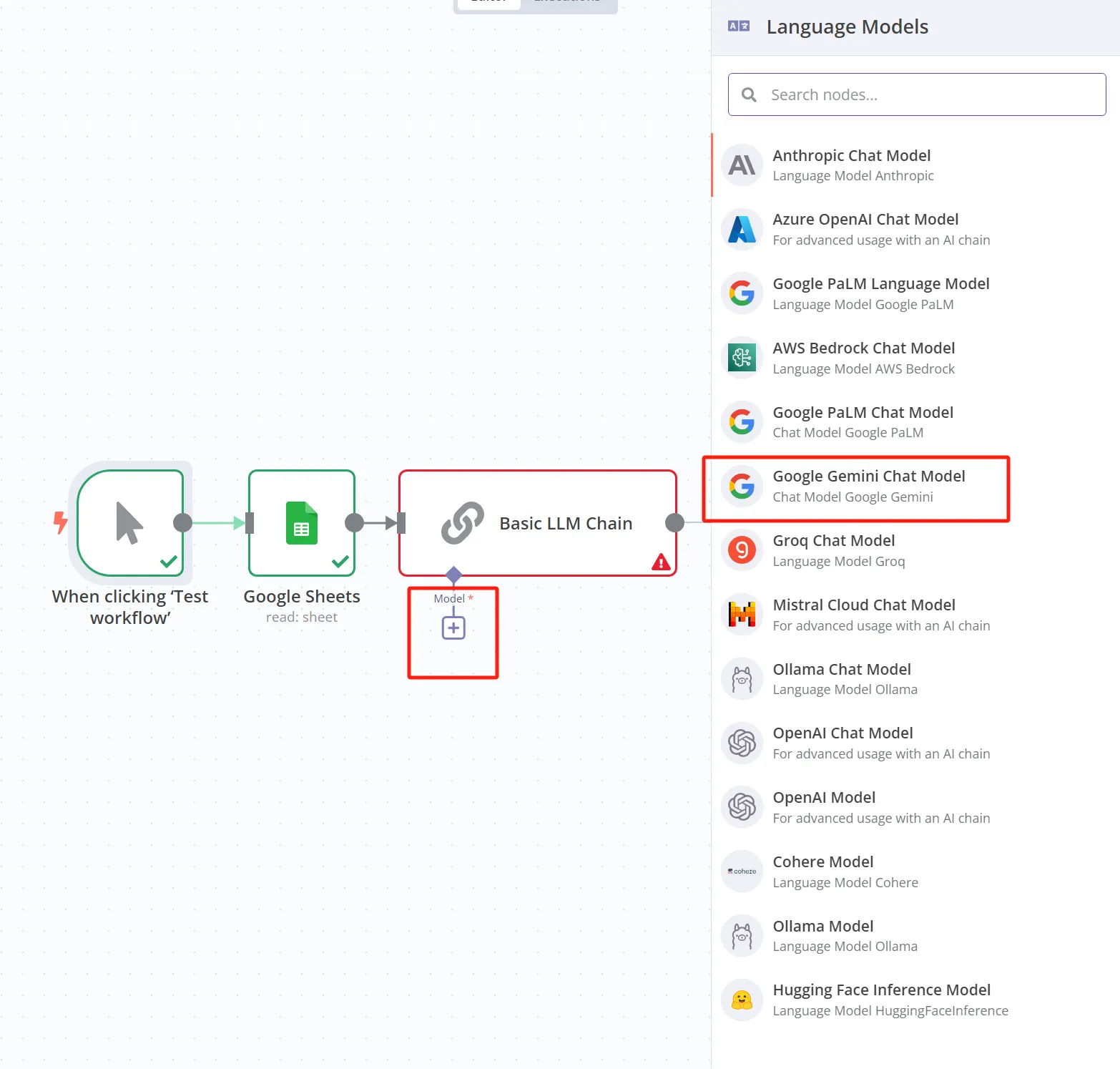
设置Model为"Google Gemini Chat Model"
-
输入获取的API Key
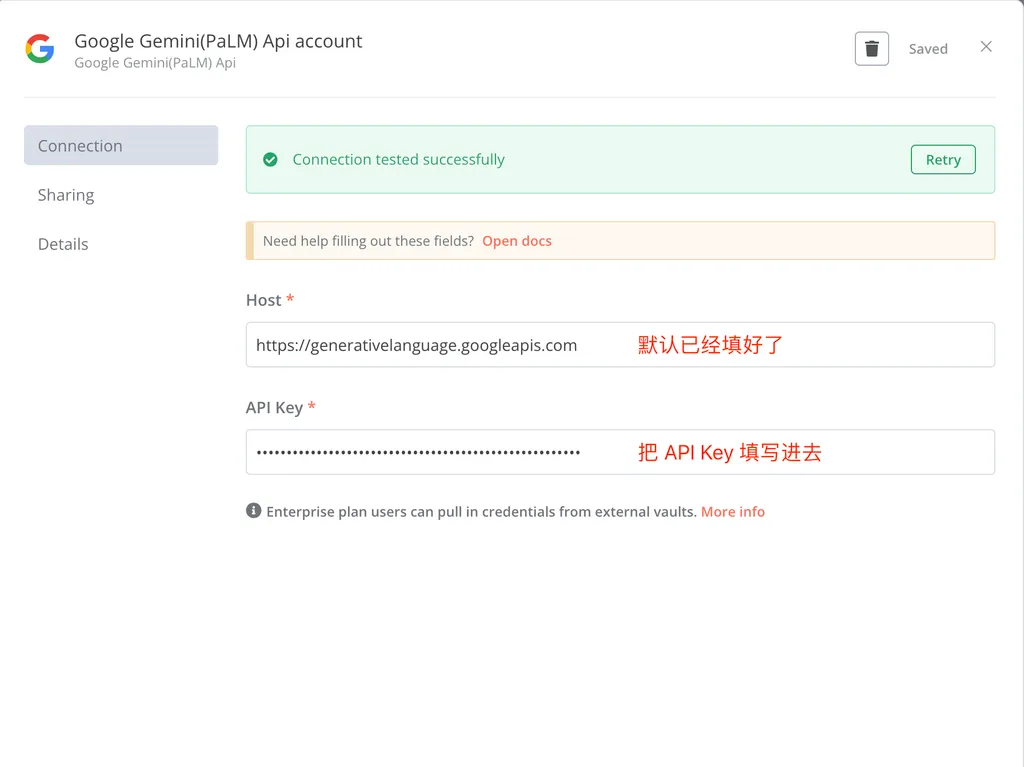
新添加的 AI 节点默认都会带一个接收聊天消息的触发器,但是在咱们的场景里面,我们就是希望 AI 节点能够处理 Excel 的文件内容即可,所以我们可以把这个触发器删掉。
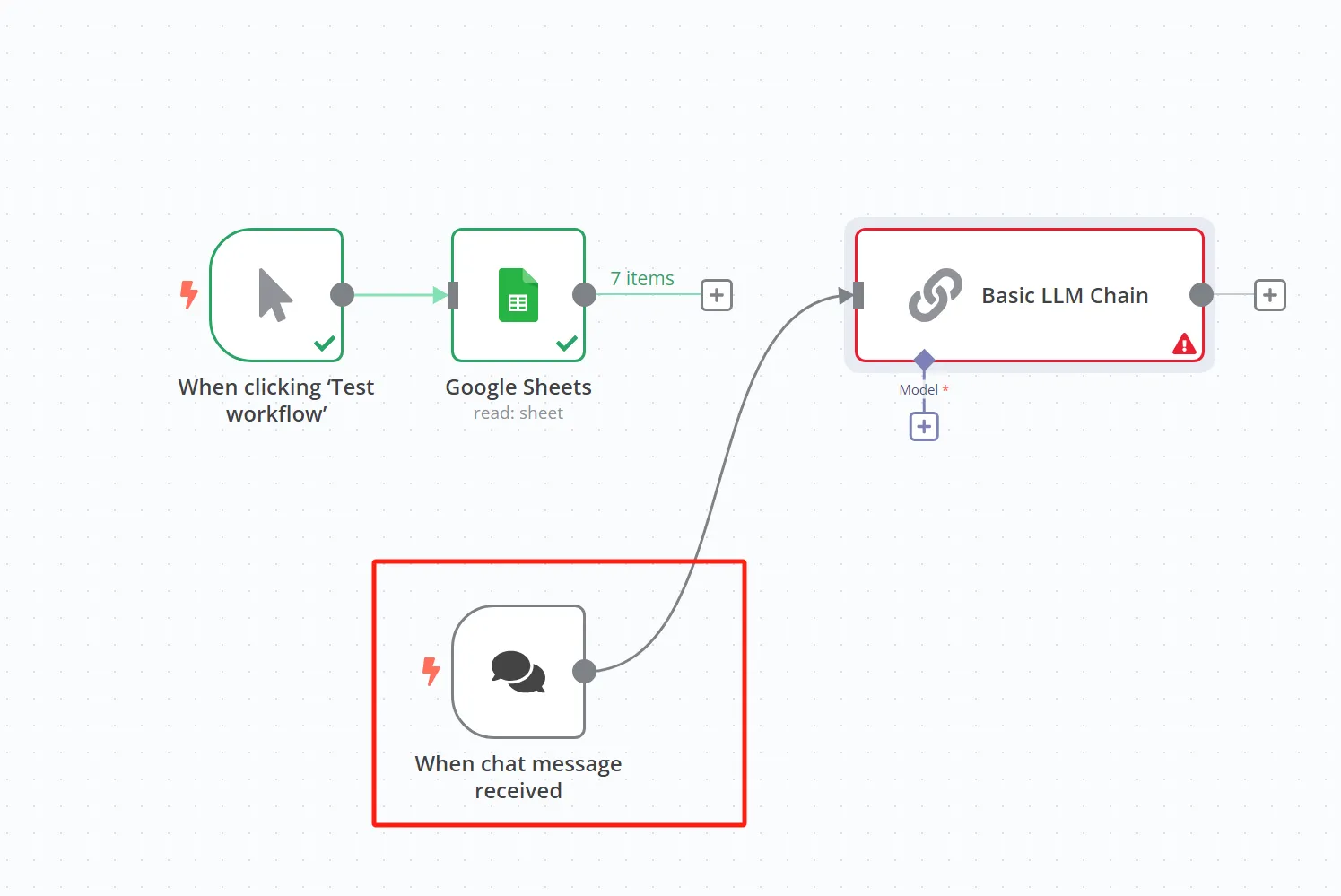
接下来就是要给 LLM 的节点配置一个大模型的 API,我们点击 Model 的 + 号,并且选择 Google Gemini Chat Model。如果你有别的大模型的 API,也可以直接使用。我们这里选择 Google Gemini 的原因是它有免费的额度。
网络提示:如无法直接访问Google服务,建议使用代理工具如CloseAI或WildCard。
登录到 https://aistudio.google.com/ 可以在 google 的 AIStuido 白嫖免费的 Gemini 的 API;
注意,Gemini 目前只面向特定区域的用户开放 API,所以你一定要确保自己上网的方式是正确的。
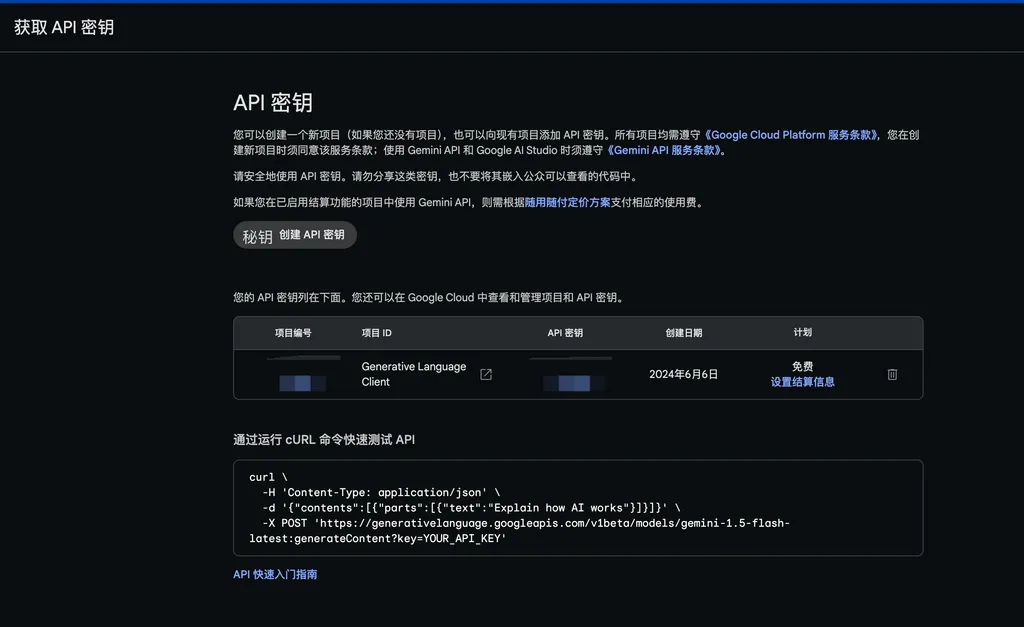
然后把创建好的密钥填写到 n8n 的界面上面去,这样模型就挂载好了。
5.4 第四步:提示词工程
5.4.1 提示词模板
5.4.2 n8n中的变量插入
-
选择"Define below"模式
-
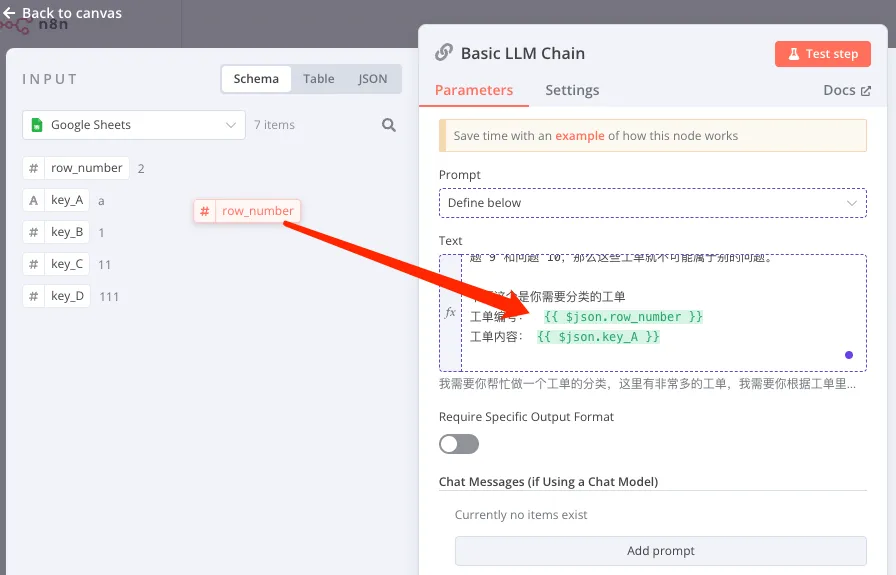
通过拖拽方式插入变量:
-
工单编号:从上游节点拖入
-
工单内容:从上游节点拖入
-
调试技巧:
-
先在Google AI Studio测试Prompt
-
在n8n中使用"Test Step"功能
-
查看Logs中的输入输出
5.5 第五步:结果回写
-
添加"Google Sheets - Append or update row"节点
-
配置要点:
-
使用工单编号作为匹配键("use to match"标识)
-
将大模型输出映射到目标列
-
-
测试确认:
-
检查Sheets中数据是否更新
-
验证数据对应关系是否正确
-
隐式参数传递:n8n会自动维护跨节点的数据关联,无需手动匹配。
现在我们获得了已经大模型打标的结果,下一步就应该讲这些结果回填到 Sheets 之中。
所以我们需要在大模型节点的下一个步骤新增一个 Google Sheets 的节点。和上一个节点有所不同,上个节点我们的需求是读取这个 Sheets 页的全部数据,这次我们需要更新数据,给每一行数据附上大模型打标的结果。
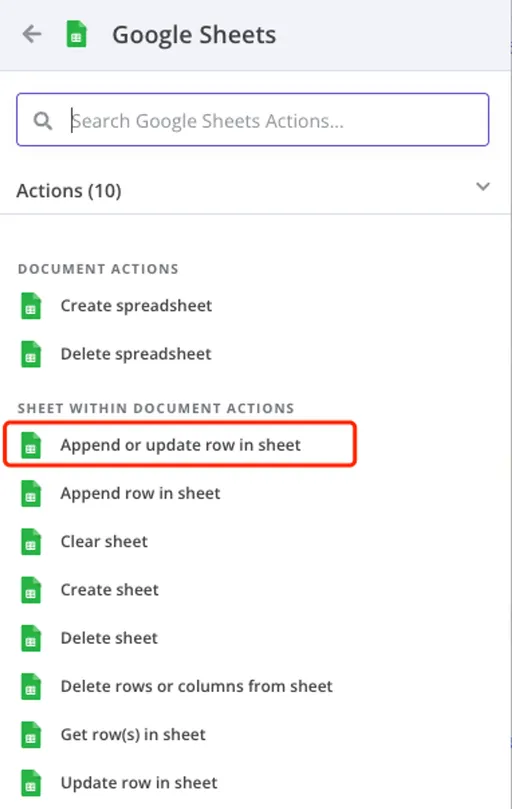
所以我们需要根据自己的需求选择 Append or update row in sheet 的选项。由于 Token 之前已经配置过了,所以这次这个节点不需要再额外配置 Token。
选择这个节点界面如下图所示:
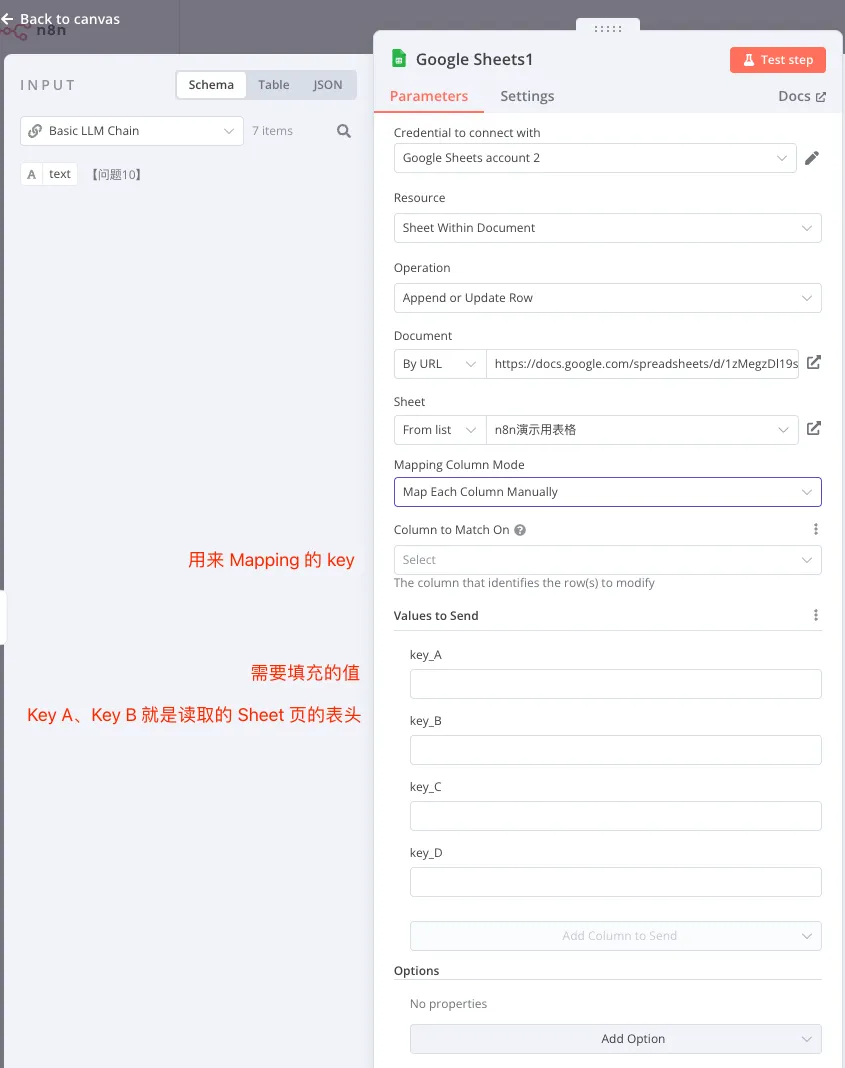
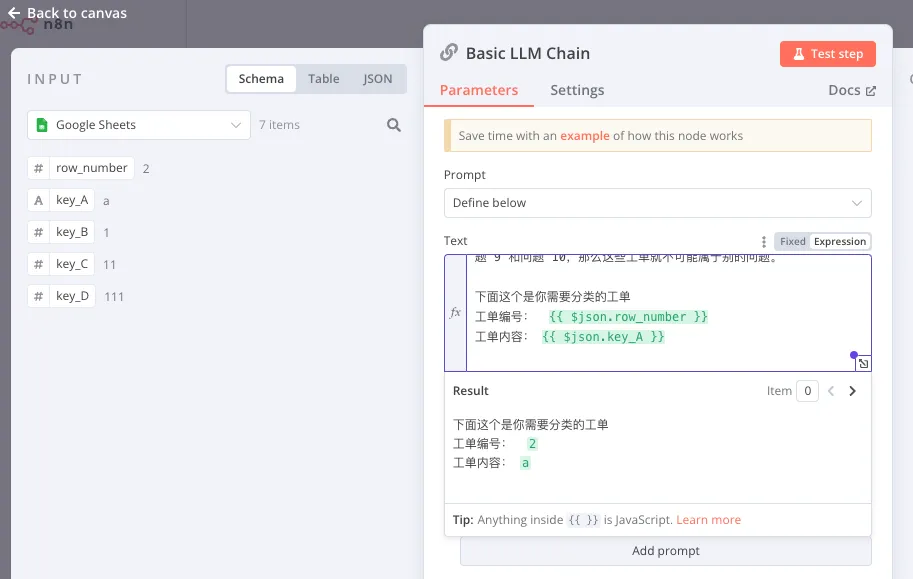
将大模型的结果填充到表格内,首先需要一列数据,比如工单编号作为唯一的关联标识,不然程序就不知道该将哪个值填充到哪里去。
这个时候就会发现大模型输出的时候只输出了问题分类,没有输出编号,但是这个时候不需要调整 Prompt,因为 n8n 自带了隐式参数传递。
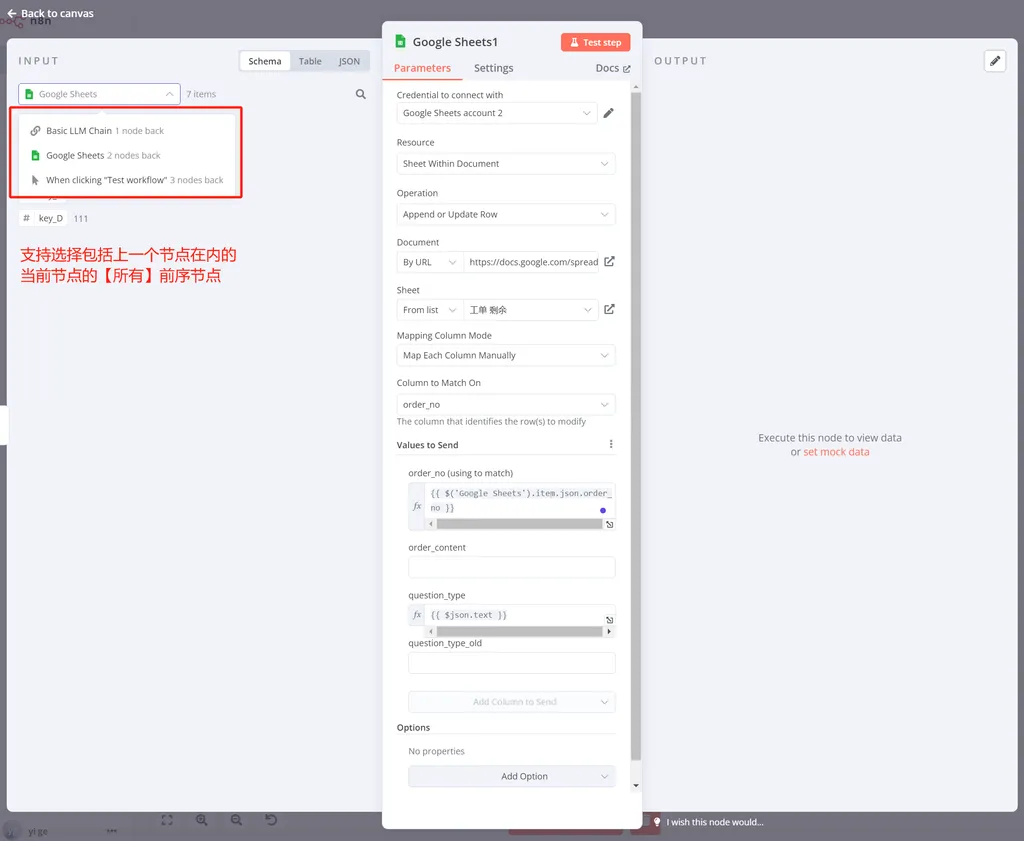
在选择入参区域的变量时,不仅仅可以选择上一个节点的变量,也可以选择上上个,上上上个等所有前序节点的变量。这些复数个数据之间经过多个程序处理传递,但是 n8n 会在系统内部自动把他们关联起来,确保他们内部是唯一关联的,所以你不需要担心数据会不会“串错”。这就是 n8n 内部很重要的隐式传递的设计思路。
所以我们可以选择 Key A 作为关联的变量,同时把上上个节点读取到的 Key_A 的值填充进去,选中作为关联键的变量会有一个 useing to match 的标识。
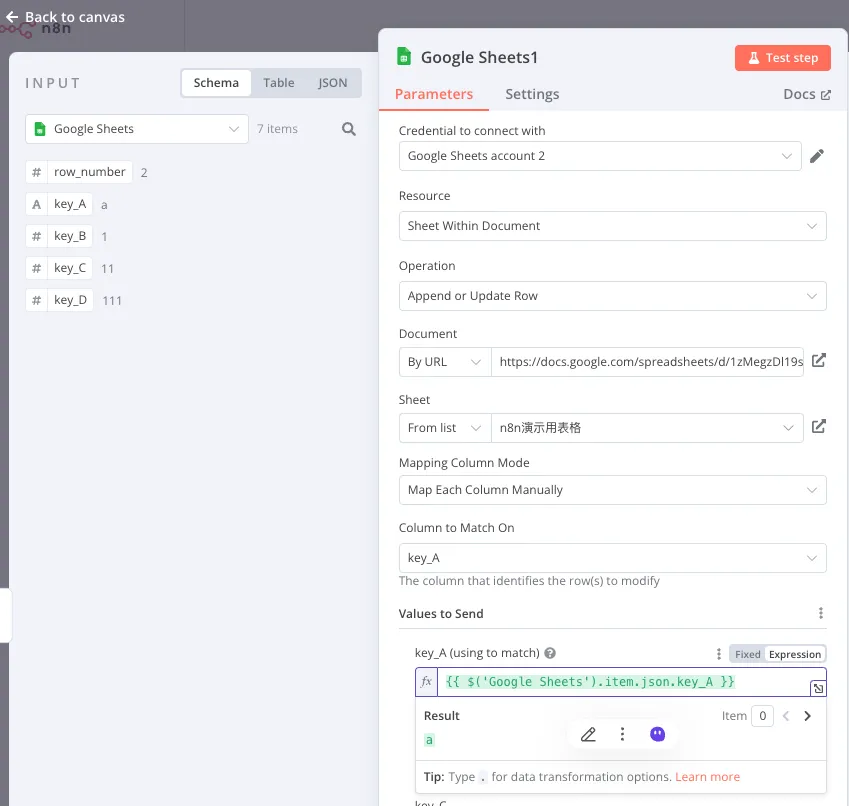
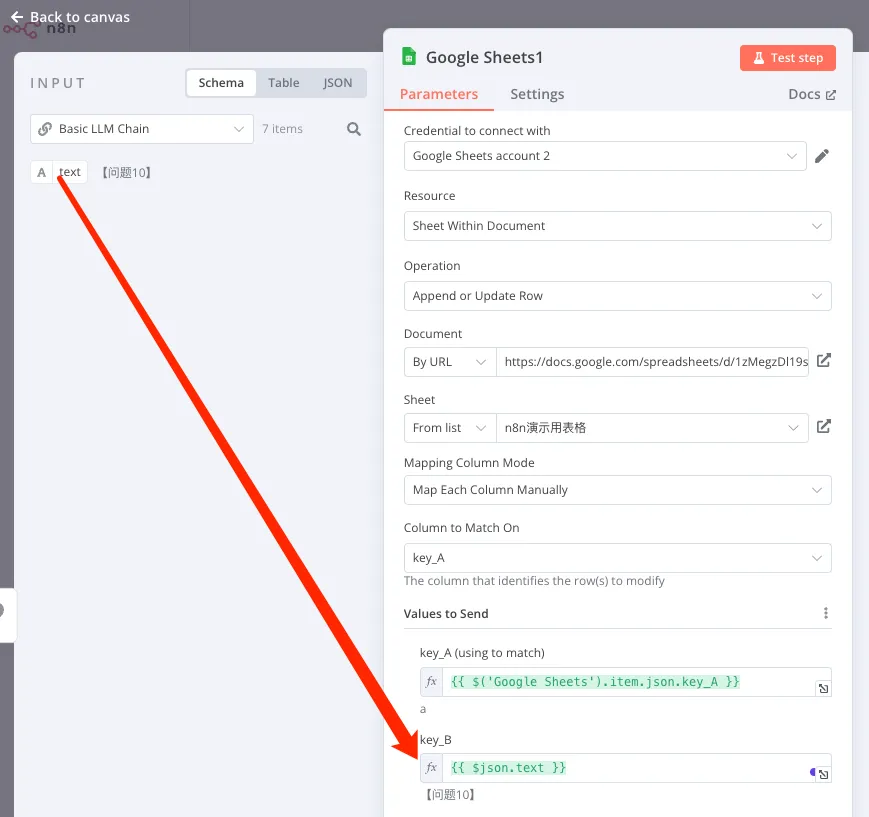
然后把大模型的结果填充到 Key_B 之中去,这样程序就会把 Key_B 的值替换成大模型输出的 Text 信息。
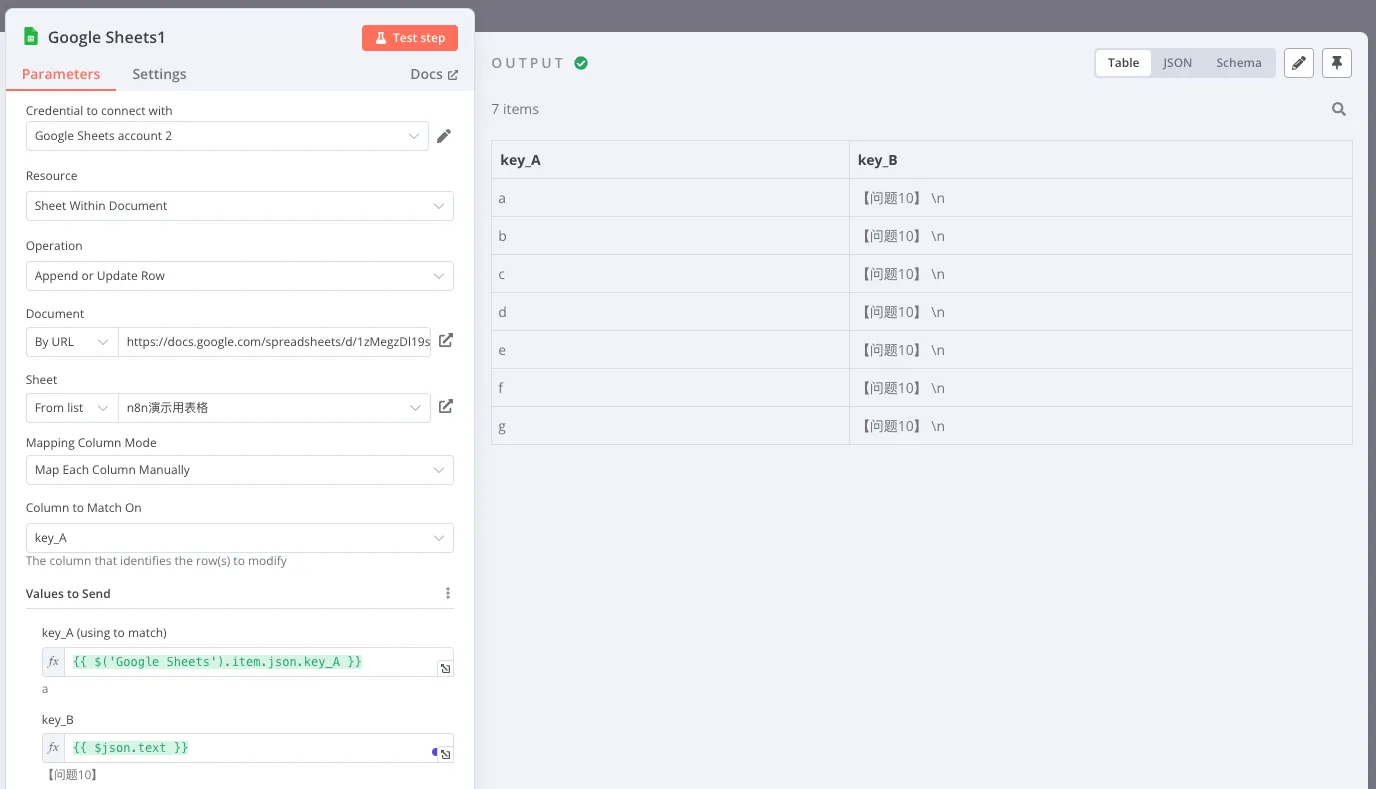
点击 Test Step,程序开始之行,Key B 的数据已经被得到了替换。
打开 Google Sheets,也会发现已经被替换了。
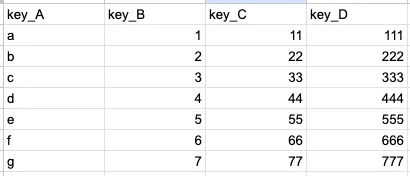 | 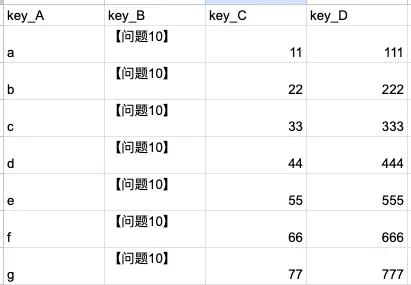 |
| 替换前 | 替换后 |
6. n8n核心设计哲学
通过本案例,可以体会n8n的三大核心理念:
6.1 循环优先设计
-
自动处理批量数据
-
可视化显示处理进度(如"X items")
-
极大提升重复任务效率
6.2 隐式参数传递
-
自动维护数据关联
-
支持跨节点变量引用
-
消除手动匹配的繁琐
6.3 开发友好特性
-
单步调试:
-
每个节点独立测试
-
快速定位问题
-
-
日志清晰:
-
完整记录输入输出
-
便于Prompt调优
-
-
可视化编排:
-
直观的流程图展示
-
降低理解成本
-
7. 进阶建议
-
性能优化:
-
批量处理时限制并发数
-
设置适当的API调用间隔
-
-
错误处理:
-
添加重试机制
-
设置失败通知
-
-
扩展应用:
-
将结果导入BI工具分析
-
添加自动报告生成功能
-
8. 总结
通过一个实际的工单分类场景,完整展示了:
-
n8n基础操作流程
-
大模型集成方法
-
典型问题解决方案
-
最佳实践建议
核心价值:通过n8n的可视化编排能力,将大模型的智能与结构化数据处理完美结合,创造出远超单独使用ChatGPT的实用价值。
资料推荐
- n8n 中文系列教程_07.全面解析n8n界面:从入门到精通-CSDN博客
- n8n 中文系列教程_06.选择适合的 n8n 安装部署方式:完整指南-CSDN博客
- n8n 中文系列教程_05.如何在本机部署/安装 n8n(详细图文教程)-CSDN博客
- 💡大模型中转API推荐
- ✨中转使用教程
希望这篇指南能帮助你快速上手n8n,开启自动化工作流之旅!如何部署请参考本专栏05-06篇.有用的话记得点赞收藏噜!


















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









