







引言:为什么模型微调值得学习?
今天我们将深入探讨大模型的核心进阶技术——模型微调。这项技术能让你打造出真正满足特定场景需求、符合个人使用习惯的个性化AI助手。最近"大模型算命"话题热度飙升,本文就以打造专业"算命大师"为例,带大家完整走通微调全流程。
效果对比(微调前后)
 |  |
-
微调前:"你的运势看起来不错"
-
微调后:"根据八字排盘,当前正印透干,流年遇天乙贵人,建议把握农历三月后的职业发展机遇..."]
一、破除误区:微调其实没有想象中困难
很多初学者看到"微调"概念就望而却步,认为这是专业开发者的领域。但实际情况是:
-
工具成熟化:DeepSeek等开源社区提供了大量易用工具
-
流程标准化:主流平台已将微调流程产品化
-
资源平民化:Colab等平台提供免费算力资源
即使是非技术背景的爱好者,通过本文指导也能在1小时内完成首次微调实践。
二、核心问题:什么情况下需要微调?
在开始实操前,必须明确微调的应用场景。通用大模型(如GPT、DeepSeek)虽然能力强大,但在特定场景下仍存在局限:
2.1 领域专业化需求
问题本质:通用模型缺乏垂直领域的深度知识
典型案例:
-
医学诊断:需要准确识别"肌酐升高"与"肾小球滤过率下降"的关联性
-
命理分析:需理解"伤官见官"等专业术语的命理含义
微调价值:注入领域专业术语和知识框架
2.2 任务适配需求
问题本质:输出形式与业务需求不匹配
典型案例:
-
法律咨询:需要严谨的法条引用(如"根据《民法典》第143条...")
-
文案创作:需保持特定的品牌话术风格
微调价值:调整输出结构和表达方式
2.3 能力纠偏需求
问题本质:模型存在系统性偏差
典型案例:
-
民俗预测:避免用科学解释替代传统命理逻辑
-
敏感话题:处理宗教、政治等话题时的立场校准
微调价值:修正模型认知偏差
2.4 安全与成本考量
特殊优势:
-
数据隐私:医疗/金融等敏感数据可本地处理
-
成本效益:相比从头训练可节省90%+算力成本
三、技术选型:长文本vs知识库vs微调
很多开发者会困惑:有了长上下文和RAG技术,为什么还需要微调?我们用考试类比说明:
| 技术方案 | 类比说明 | 优势 | 局限 | 适用场景 |
|---|---|---|---|---|
| 长文本 | 开卷考试(题目即答案) | 保持上下文连贯性 | 受限于窗口长度 | 长文档摘要、复杂逻辑推理 |
| 知识库 | 开卷考试(可查资料) | 实时更新知识 | 检索质量依赖向量库 | 客服问答、事实查询 |
| 微调 | 考前特训(内化知识) | 响应速度快 | 需要训练数据 | 专业领域咨询、风格化输出 |
关键结论:当需要模型内化专业知识或形成特定推理逻辑时,微调是不可替代的方案。
四、微调全流程详解(7个关键步骤)
4.1 整体流程图
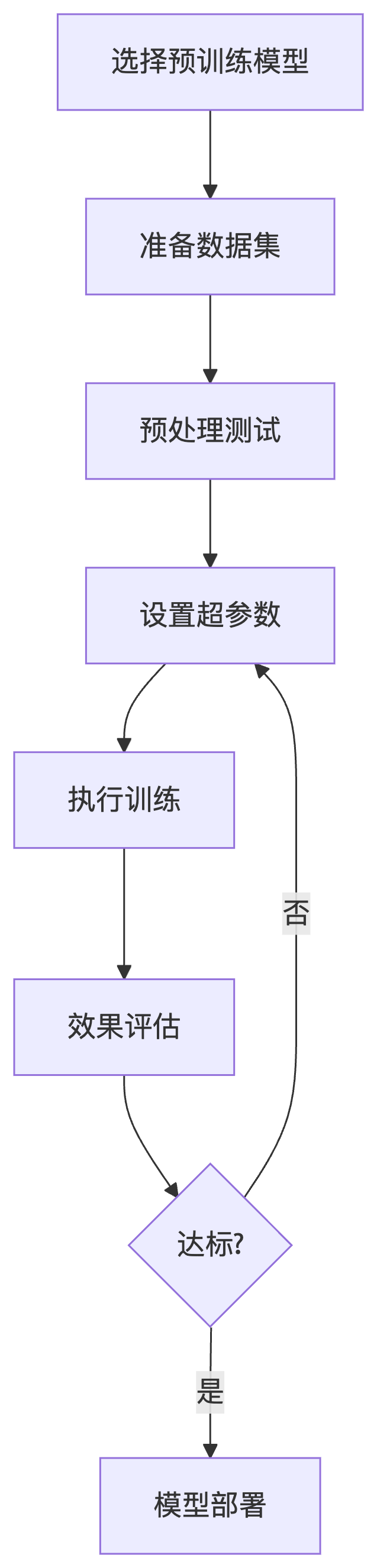
4.2 核心概念解析
-
预训练模型选择
-
基础模型:Qwen、LLaMA、DeepSeek等
-
选择建议:7B参数模型适合大多数消费级显卡
-
-
数据集准备规范
-
数据格式示例(JSONL):
{"instruction":"分析生辰八字","input":"壬寅年 癸卯月 戊戌日 庚申时","output":"日主戊土得月令..."}-
数据量建议:至少500组高质量样本
-
-
关键超参数说明
参数 作用 推荐值 learning_rate 控制参数更新幅度 3e-5 num_epochs 训练轮次 3-5 batch_size 每次训练样本数 根据显存调整
五、平台实操:硅基流动微调演示
目前市面上很多 AI 相关平台都提供了在线微调模型的能力,比如我们以最近比较火的硅基流动为例:
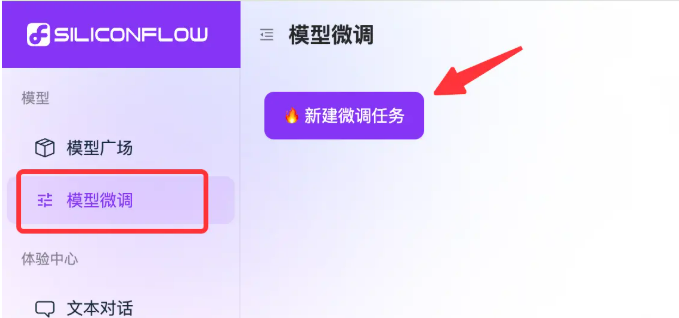
5.1 创建微调任务
-
登录硅基流动控制台
-
选择"模型微调"功能
-
创建新任务
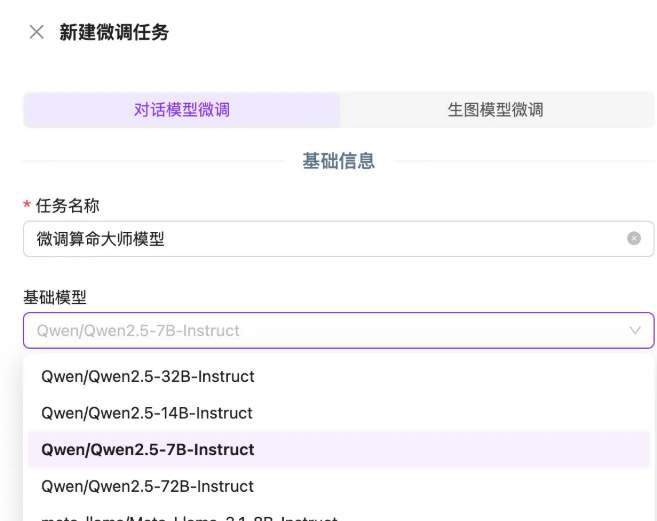
5.2 模型选择
-
当前支持模型:Qwen2.5-7B等
-
选择建议:中文任务优先选Qwen系列
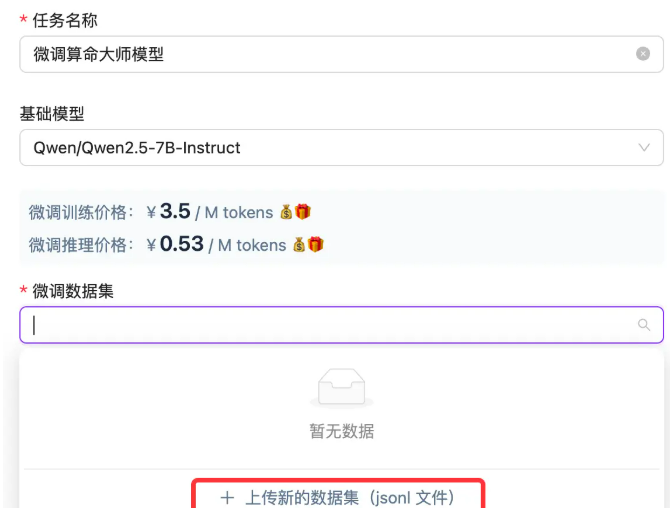
5.3 数据准备技巧
-
命名规范:建议包含领域标识(如fortunetelling)
-
数据格式:支持JSON/CSV等多种格式
-
验证集:建议保留20%数据用于效果评估
5.4 参数配置建议
{
"learning_rate": 3e-5,
"per_device_train_batch_size": 4,
"num_train_epochs": 5,
"weight_decay": 0.01
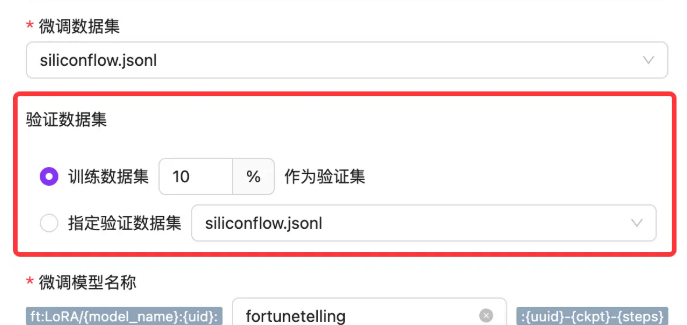
}验证数据集
数据集上传完成后,下一步就是输入一个微调后模型的名字,以及设置验证数据集。
首先我们想要微调一个算命大师模型,那我们就以 fortunetelling 来命名:
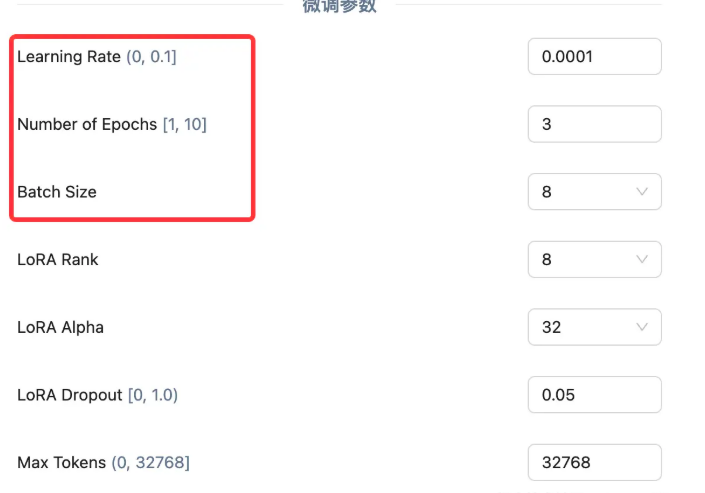
超参数设置
最后就是设置一些模型训练的 “超参数” 了,给出可以设置的参数非常多,我们这里只介绍最关键的三个参数:
六、进阶优化策略
6.1 数据增强方法
-
同义替换:使用大模型生成表达变体
-
知识蒸馏:从GPT-4等高级模型生成训练数据
6.2 参数调优技巧
-
学习率预热:前10%训练步逐步提高学习率
-
梯度裁剪:设置max_grad_norm=1.0避免梯度爆炸
6.3 效果评估指标
-
专业度:领域术语使用准确率
-
一致性:多次询问的答案稳定性
-
安全性:避免有害内容生成
七、常见问题解答
Q:需要多少训练数据?
A:基础效果需500+条,专业级建议3000+条
Q:训练时间多久?
A:7B模型在A100上约需2-4小时
Q:如何避免过拟合?
A:建议使用早停法(early stopping)
结语:开始你的第一次微调
现在你已经掌握了:
✅ 微调的核心价值判断
✅ 完整的技术实现流程
✅ 平台实操的具体方法
不妨立即尝试在硅基流动平台创建你的第一个"算命大师"微调任务。记住,最好的学习方式就是动手实践!遇到问题欢迎在评论区交流讨论。有用的话记得点赞收藏噜!


















 4620
4620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









