







Andrew NG 《machine learning》week 2,class2 —Multivariaze Linear Regression
本节课主要是讲述有多个特征变量情况下的线性回归函数。
2.1 Mutiple Features
多特征变量和单特征变量的差别是参数threa和变量x均是一个n+1维的向量。
2.2 Gradient Descent For Multiple Variables
在多特征变量下线性回归函数的表达式如下图所示:
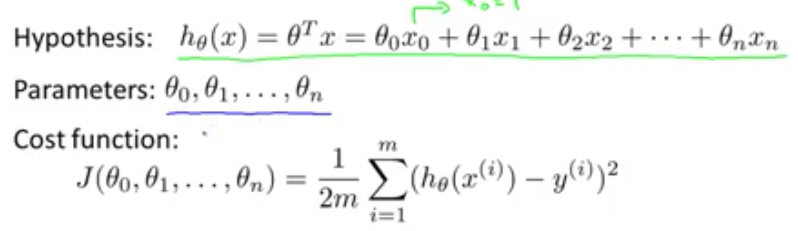
上图还展示了多特征变量的代价函数的表达式。
下图表示了梯度下降函数中参数的更新方法,需要注意的是这些参数需要同时更新。

2.3 Gradient Descent in Practice I - Feature Scaling
对于有多个特征变量的情况下,特征变量的取值范围可能会出现不同,因此需要把特征向量的范围统一化。
特征变量的取值范围不同的时候会出现的一些情况,比如梯度下降比较缓慢,花的时间比较长等.
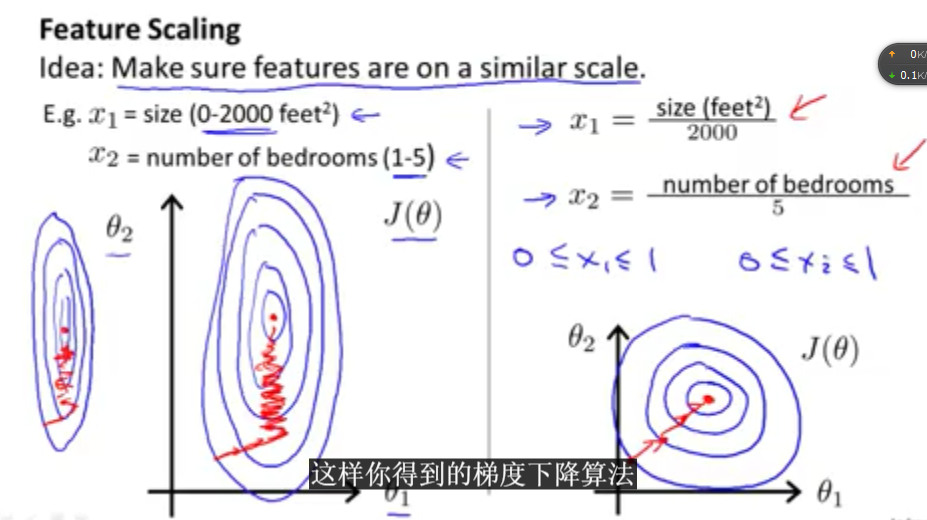
如上图所示,左边的图是未经过参数范围统一化的梯度下降函数的情况,右边的是经过范围统一化之后的情况。
参数经过范围统一化之后的值如图中所示,会在一个较小我的范围内。(-1,1)。
这个参数统一化的方法可以叫做参数均值归一化(mean normalization)。

如上图所示,均值归一化是与平均值有关的,x的值等于x-average/range(就是数值的取值范围)。
2.4 Gradient Descent in Practice I - Learning Rate
本小节主要讨论关于梯度下降的一些实用的技巧。同时也将集中讨论Learning rate—α
对于梯度下降函数,主要是需要考虑以下问题:

学习效率的选择对于梯度下降算法影响较大。
一般来说,梯度下降函数收敛的情况下是每次迭代之后的代价值的变化范围不超过一个较小的值。如下图所示,但是一般都会通过图形来观察函数是否已经达到收敛的状态。图形时较为直观的。如下图:

同时学习率α的选择如果太小,那么收敛的时间会很长,如果选择太大,有可能错过最小值,并且之后代价值不断增加。所以太小、太大并不是很符合。如下图所示:学习率的选择不能过大也不能过小,一般是找出最大值(使代价值增长的学习率)和最小值,然后在这两者之间选择一个合适的学习率α。

2.5 Feature and Polynomial Regression
本小节将会主要讲解多项式表达式。对于一些数据集,二次表达式没办法很好的拟合数据集,因此选用多项式表达式,有些时候可以用一个特征变量来表示。如下图:特征变量只是一个size,但是可以对其采用多次方的方法构成多项式。
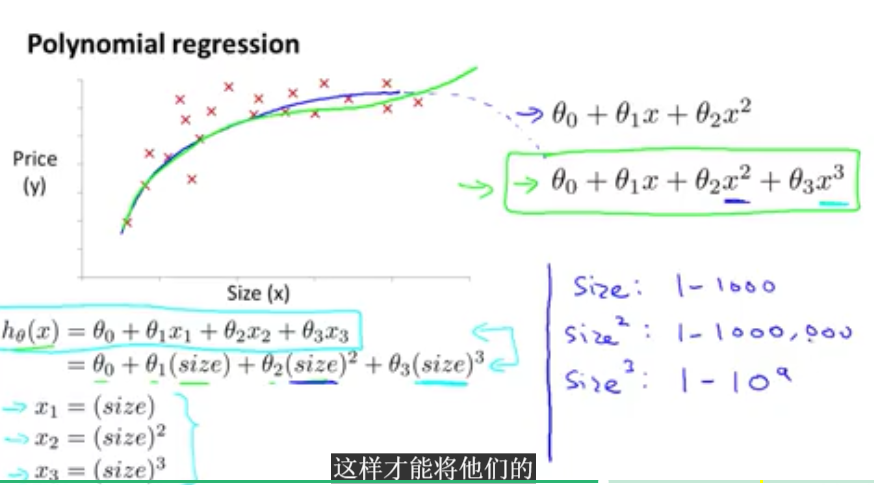
那么线性回归函数的表达式就会有如下两种方式。倍数和平方根的形式。















 9373
9373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









