







大数据下的机器学习
目前的数据可谓是呈指数级增长,在这样的大数据氛围下,机器学习反而会表现得更好,毕竟有一句话是这么说的”It’s not who has the best algorithm that wins. It’s who has the most data.”。但是一些机器学习的算法在数据量较大的情况下,由于计算所耗时间也会不断增加,所以可以将算法针对大数据的情景进行一定的修改,减少计算量。
1. learning with large datasets
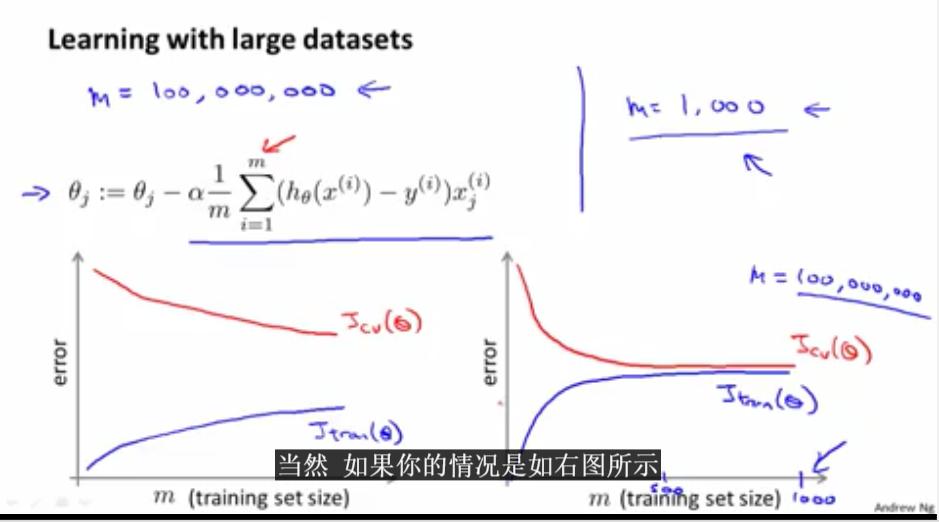
通过画学习曲线来判断多大的数据集就可以进行算法了。如下图,左边的图表示数据集还需要不断增加,但是右边的图表示当数据等于1000的时候就可以不需要增加数据量。
之前我们学习的都是批量的梯度下降算法。算法思想如下:
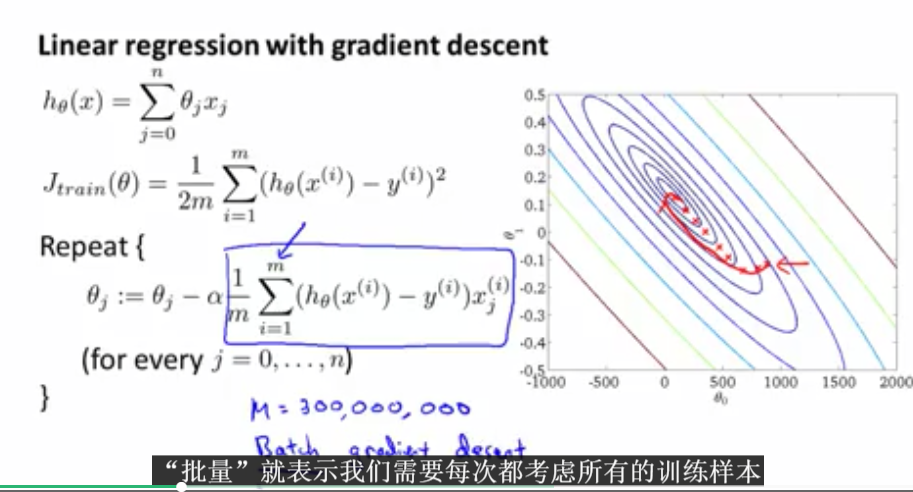
那么梯度下降的思想是什么呢?接下来将进行阐述。

随机梯度下降的过程中,每次只需要计算一个训练数据的导数即可。每循环一次theta就向最优递进一步。那么外层循环多少次呢?一般是1-10次就足够了。
2. mini-bath gradient descent

从上图可知,mini-batch gradient descent的定义。其中b=10,数据集的大小为1000,那么所以每次i的循环是加10,循环次数为1,11,21,31等等。Mini批量梯度下降算法比批量算法要稍微快一些,它是介于批量和随机梯度下降算法之间的算法。但是这个算法也有一定的缺点,那就是有额外的参数b,需要调试这个参数,这也是需要花时间的一件事情,当b等于m的时候,Mini梯度下降算法就相当于批量梯度下降算法了。
3.随机梯度下降收敛
怎么确保随机梯度下降函数是收敛的呢?本小节将会谈论这些问题。并提出如何选择合适的学习效率α。

在随机梯度下降算法中,不需要画出每次计算的代价函数,只需要对最后的1000次代价函数求平均画出来就好。这个计算必须在下一次迭代之前进行。
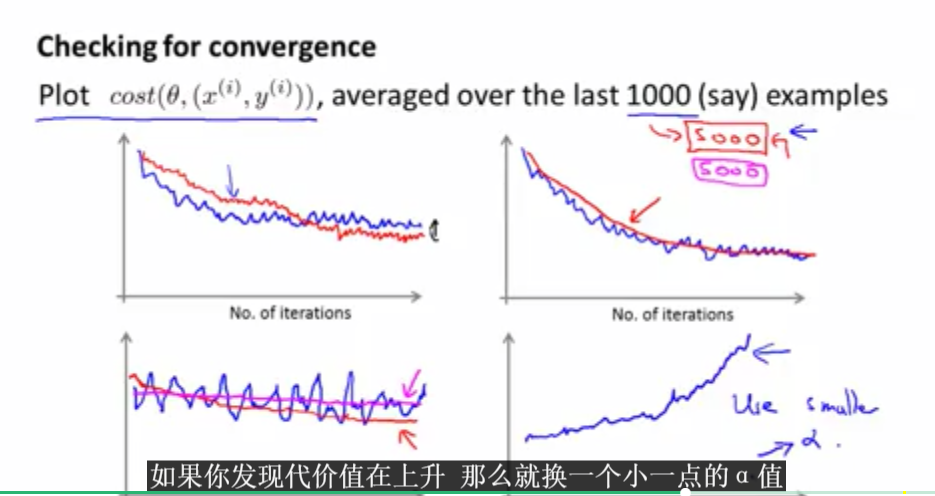
上图表示的是随机梯度下降函数中代价函数曲线会出现的各种情况。
4. online learning
目前许多大型网络公司或者网站都使用了在线学习算法,从大量进出网站的用户进行学习。通过用户数据流来进行学习,来加强网站的优化,比如根据用户的偏好,实时的推送相关的信息。

上图展示了在线学习算法的一个应用实例,在线学习算法和随机梯度下降算法很相似,只不过它采用的不是固定的数据集,而是数据流。对于变化的用户数据能够及时应变。
5.map reduce and data parallelism
相比梯度下降算法,映射化简方法更能处理大规模数据的情况。
映射化简的思想如下:
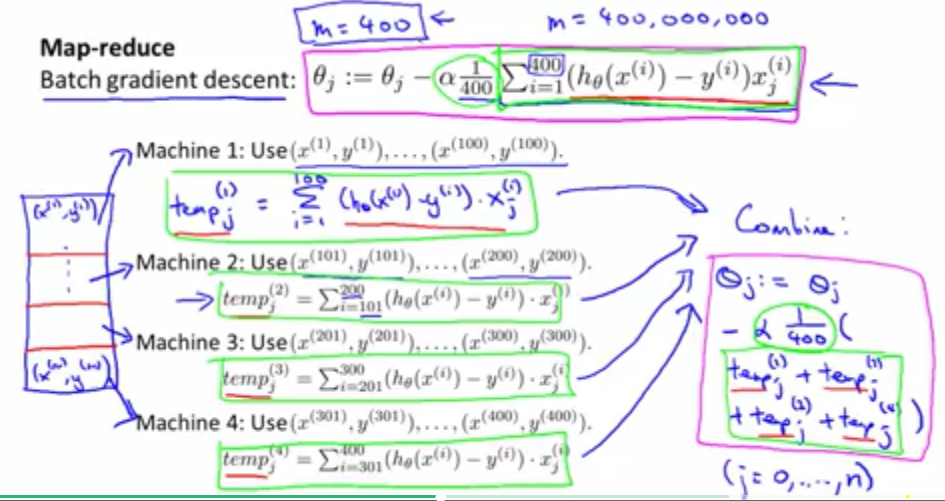
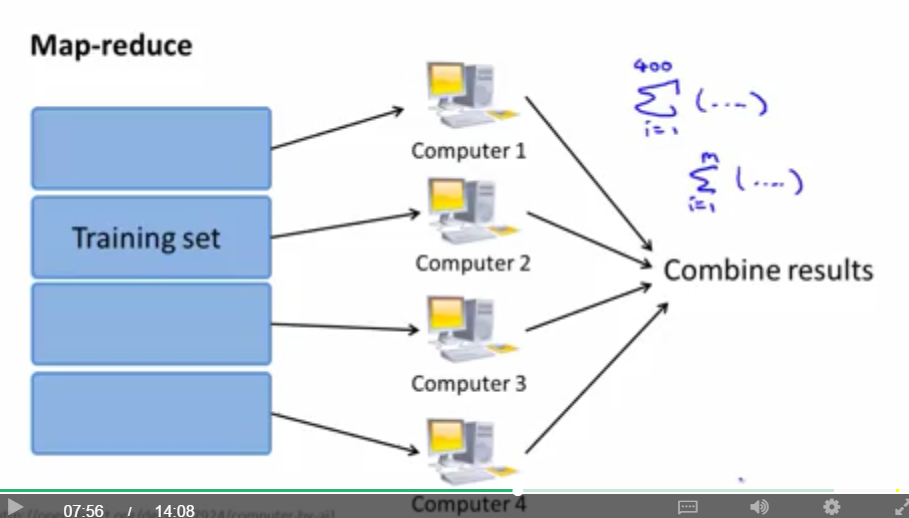
对于映射化简,其实就是将数据并行处理,看能否用映射化简的时候,先看看算法能不能拆分能结果数据之和。
可以将映射化简放在多台计算机上,也可以放在一台具有多个CPU以及多核的计算机内实现。当然,目前实现了映射化简的系统也已经出现了,比如hadoop等。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









