







1、算法推理:
这里算法推理和代码复现原型参考:https://blog.csdn.net/zouxy09/article/details/20319673
2、算法应用背景-课题设计:
企业财务风险预警是企业风险预警系统的一个重要组成部分,它能有效的预知部分财务风险。本课题将风险公司记为ST,非风险公司记为非ST,ST判断标准如下:
1.)连续两年年报显示净利润为负值
2)净资产收益率、总资产净利润率为负值。
其影响特征变量如下:
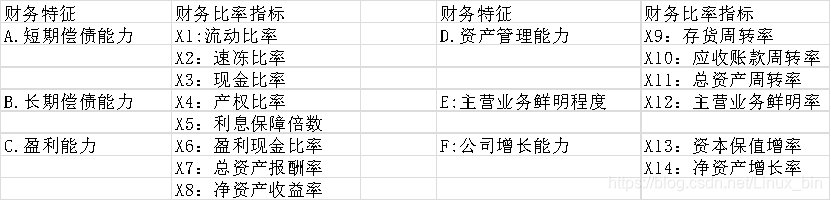
注: 现金比率= 货币资金÷ 流动负债;
盈利现金比率= 经营活动的现金净流量÷ 净利润;
主营业务鲜明程度= 主营业务利润÷ |净利润|;
请利用2018年的财务指标相关数据,构建基于BP神经网络的财务风险预警模型。
3、代码复现
3.1 train & predict
from numpy import *
import matplotlib.pyplot as plt
import time
import numpy as np
from data import Dataset
import pickle
# calculate the sigmoid function
#算法推理来自于:https://blog.csdn.net/zouxy09/article/details/20319673
#commit code to https://github.com/Linby1103/Pre-warning.git
class LR(object):
def __init__(self,train_data,label_):
self.traindata=train_data
self.label=label_
def sigmoid(self,z):
return 1.0 / (1 + exp(-z))
def train(self,opts,weight_path="weights.pkl"):
# train a logistic regression model using some optional optimize algorithm
# traindata is a mat datatype, each row stands for one sample
#label is mat datatype too, each row is the corresponding label
#opts is optimize option include step and maximum number of iterations
# calculate training time
startTime = time.time()
numSamples, numFeatures = shape(self.traindata)
alpha = opts['alpha'];
maxIter = opts['maxIter']
weights = ones((numFeatures, 1))
# optimize through gradient descent algorilthm
for k in range(maxIter):
if opts['optimizeType'] == 'gradDescent': # gradient descent algorilthm
output = self.sigmoid(self.traindata * weights)
error = self.label - output
weights = weights + alpha * self.traindata.transpose() * error # (y-err)*x BP
elif opts['optimizeType'] == 'stocGradDescent': # stochastic gradient descent
for i in range(numSamples):
output = self.sigmoid(self.traindata[i, :] * weights)#注意这traindata是转化为mat类型的数据,所以这里用* 和用dot做矩阵的乘法是一样的
error = self.label[i, 0] - output
weights = weights + alpha * self.traindata[i, :].transpose() * error
elif opts['optimizeType'] == 'smoothStocGradDescent': # smooth stochastic gradient descent
# randomly select samples to optimize for reducing cycle fluctuations
dataIndex = range(numSamples)
for i in range(numSamples):
alpha = 4.0 / (1.0 + k + i) + 0.01
randIndex = int(random.uniform(0, len(dataIndex)))
output = self.sigmoid(self.traindata[randIndex, :] * weights)
error = self.label[randIndex, 0] - output
weights = weights + alpha * self.traindata[randIndex, :].transpose() * error
del (dataIndex[randIndex]) # during one interation, delete the optimized sample
else:
raise NameError('Not support optimize method type!')
print('training finished! %fs!' % (time.time() - startTime))
try:
pickf = open(weight_path, 'wb')
print("Save weight to {}".format(weight_path))
data = {"weight": weights}
pickle.dump(data, pickf)
except Exception as e:
print("Write weight to {} fail! {}".format(pickf,e))
pickf.close()
finally:
pickf.close()
# test trained Logistic Regression model given test set
def predict(self,weights, test_x, test_y):
numSamples, numFeatures = shape(test_x)
matchCount = 0
result=[]
for i in range(numSamples):
prob = 1 if self.sigmoid(test_x[i, :] * weights)[0, 0] > 0.5 else 0
result.append(prob)
if prob == bool(test_y[i, 0]):
matchCount += 1
accuracy = float(matchCount) / numSamples
print("accuracy={}".format(accuracy))
return result
def load_weight(self,path):
weight={}
try:
weight = pickle.load(open(path,'rb'))["weight"]
print(weight.shape)
except Exception as e:
print("Load weight faild! {}".format(e))
finally:
return weight
def loadData():
train_x = []
train_y = []
fileIn = open('./data/testdata.txt')
for line in fileIn.readlines():
lineArr = line.strip().split()
train_x.append([1.0, float(lineArr[0]), float(lineArr[1])])
train_y.append(float(lineArr[2]))
return mat(train_x), mat(train_y).transpose()
if __name__=="__main__":
STATUS = ['非ST','ST']
save_model="weights.pkl"
train, label = Dataset.GetDatafromDict()
trainarrayx=mat(train)
labelarray=mat(label).transpose()
logistreg = LR(trainarrayx,labelarray)
# print(trainarrayx.shape,labelarray.shape)
opts={"alpha":0.001,"maxIter":200,"optimizeType":"gradDescent"}
logistreg.train(opts,save_model)
weights=logistreg.load_weight(save_model)
res=logistreg.predict(weights,trainarrayx,labelarray)
for i in range(len(res)):
print("预测结果 :{}---原始数据:{}".format(STATUS[res[i]], STATUS[label[i]]))
3.2 Create dataset-数据来源于excel
import xlrd
import os
import numpy as np
class ExcelReade(object):
def __init__(self, excel_name, sheet_name):
"""
# 我把excel放在工程包的当前文件夹中:
# 1.需要先获取到工程文件的地址
# 2.再找到excel的文件地址(比写死的绝对路径灵活)
os.path.relpath(__file__)
1.根据系统获取绝对路径
2.会根据电脑系统自动匹配路径:mac路径用/,windows路径用\
3.直接使用__file__方法是不会自动适配环境的
"""
self.excel_path = excel_name
# 打开指定的excel文件
self.date = xlrd.open_workbook(self.excel_path)
# 找到指定的sheet页
self.table = self.date.sheet_by_name(sheet_name)
self.rows = self.table.nrows # 获取总行数
self.cols = self.table.ncols # 获取总列数
def data_dict(self):
if self.rows <= 1:
print("总行数小于等于1,路径:", end='')
print(self.excel_path)
return False
else:
# 将列表的第一行设置为字典的key值
keys = self.table.row_values(0)
# 定义一个数组
data = []
# 从第二行开始读取数据,循环rows(总行数)-1次
for i in range(1, self.rows):
# 循环内定义一个字典,每次循环都会清空
dict = {}
# 从第一列开始读取数据,循环cols(总列数)次
for j in range(0, self.cols):
# 将value值关联同一列的key值
dict[keys[j]] = self.table.row_values(i)[j] if self.table.row_values(i)[j] != "NULL" else "0"
# 将关联后的字典放到数组里
data.append(dict)
return data
#Stkcd 净利润2017 净利润2018 净资产收益率 总资产净利润率 x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14
def GetDatafromDict():
start = ExcelReade('./data/dataset.xlsx', 'Sheet1')
data = start.data_dict()
train=[]
label=[]
for i in range(len(data)):
array=[]
array.append(float(data[i]['净利润2017']))
array.append(float(data[i]['净利润2018']))
array.append(float(data[i]['净资产收益率']))
array.append(float(data[i]['总资产净利润率']))
array.append(float(data[i]['x1']))
array.append(float(data[i]['x2']))
array.append(float(data[i]['x3']))
array.append(float(data[i]['x4']))
array.append(float(data[i]['x5']))
array.append(float(data[i]['x6']))
array.append(float(data[i]['x7']))
array.append(float(data[i]['x8']))
array.append(float(data[i]['x9']))
array.append(float(data[i]['x10']))
array.append(float(data[i]['x11']))
array.append(float(data[i]['x12']))
array.append(float(data[i]['x13']))
array.append(float(data[i]['x14']))
train.append(array)
if float(data[i]['净利润2017'])*float(data[i]['净利润2018'])<0:
label.append(0)
else:
label.append(1)
return np.array(train) ,np.array(label)
if __name__ == '__main__':
start = ExcelReade('C:/Users/91324/Desktop/datasset.xlsx','Sheet1')
data = start.data_dict()
GetDatafromDict(data)
数据集,代码上传至:https://github.com/Linby1103/Pre-warning.git

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









