







| 论文标题 | MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer |
|---|---|
| 论文作者 | Sachin Mehta, Mohammad Rastegari |
| 发表日期 | 2022年03月01日 |
| GB引用 | > Sachin Mehta, Mohammad Rastegari. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer[J]. International Conference on Learning Representations (ICLR), 2022. |
| DOI | 10.48550/arXiv.2110.02178 |
论文地址:https://arxiv.org/pdf/2110.02178
摘要
本文提出了一种名为MobileViT的轻量级视觉变换器,用于移动设备上的视觉任务。MobileViT结合了卷积神经网络(CNN)和视觉变换器(ViT)的优点,通过将局部处理替换为全局处理来学习全局表示。实验结果表明,在不同任务和数据集上,MobileViT显著优于基于CNN和ViT的网络。在ImageNet-1k数据集上,MobileViT在约600万参数下达到78.4%的准确率,比MobileNetv3和DeIT分别高出3.2%和6.2%。此外,MobileViT在目标检测和语义分割任务中也表现出色,且具有较低的延迟,适用于移动设备。
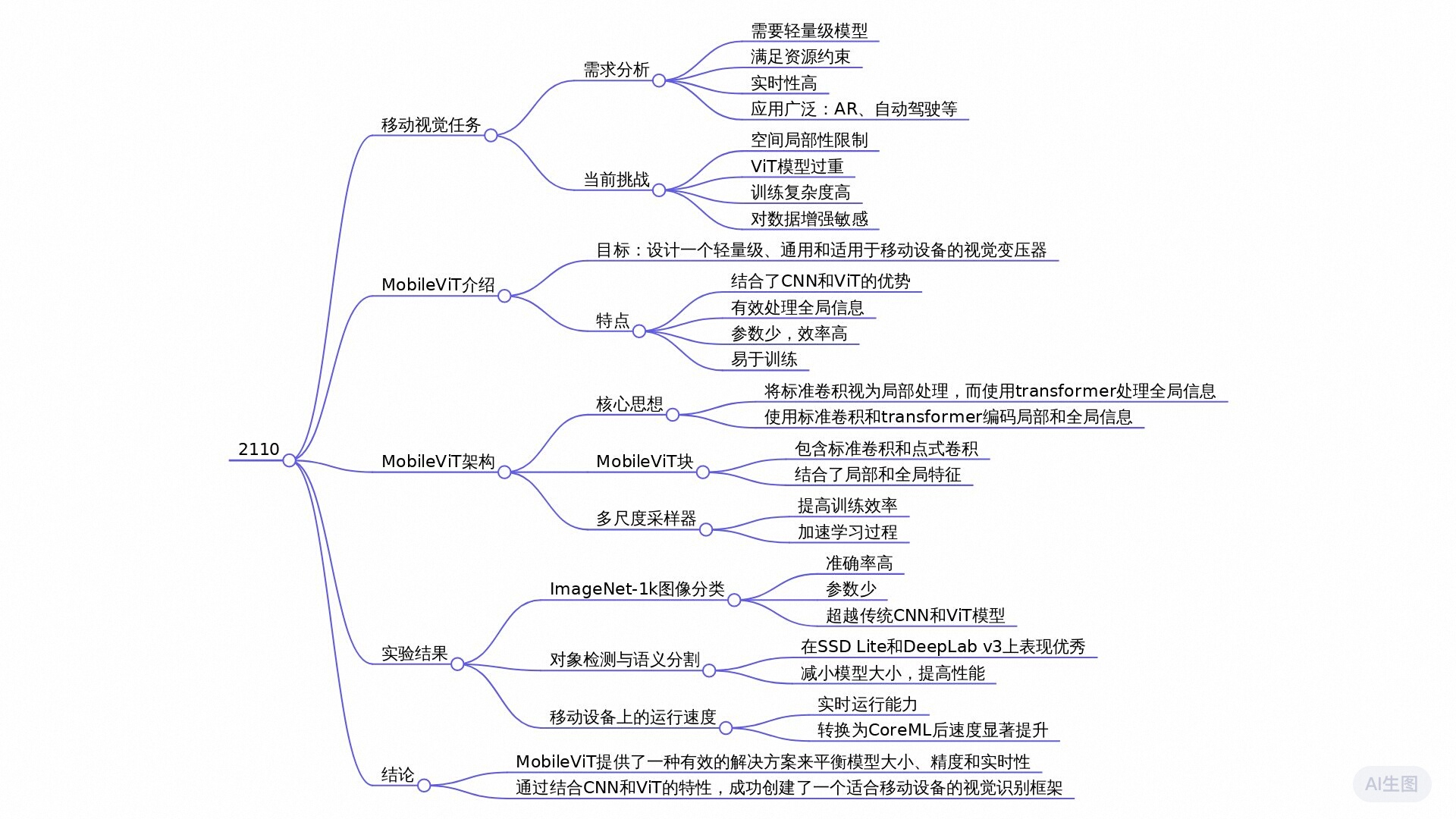
全文摘要
主题概括:
本论文提出了一种新的轻量级视觉变换器(MobileViT),旨在结合卷积神经网络(CNN)和视觉变换器(ViT)的优点,以满足移动设备上视觉任务(如图像分类、目标检测和语义分割)的需求。MobileViT通过引入MobileViT块,实现了局部信息与全局信息的联合处理,从而提高了模型的效率和表现。
主要结论:
- 优越的性能:MobileViT在多个任务和数据集上表现优于传统的CNN和ViT模型。例如,在ImageNet-1k数据集上,MobileViT以大约600万参数实现了78.4%的顶级精度,比相似参数量的MobileNetv3和DeIT分别高3.2%和6.2%。
- 轻量化设计:MobileViT模型的参数数量相对较少(比如设计为5-6百万的模型)且具有快速的推理速度,使其非常适合于资源受限的移动设备。
- 易于训练:与其他ViT模型相比,MobileViT在基本数据增强条件下表现更加稳定和高效,训练时对超参数的敏感度较低,减少了模型优化的复杂性。
- 多功能性:MobileViT不仅在图像分类任务上取得了成功,同时在目标检测和语义分割上也展示了良好的克服能力,证明了其作为通用特征提取器的效用。
独特之处:
与当前许多研究不同,MobileViT不仅针对模型性能进行了优化,同时考虑到了移动设备的实际应用需求,强调了低延迟和轻量特性。此外,该模型独特的设计使得在局部和全局信息处理上能够高效结合,开创了针对移动视觉任务的新方法。通过开源代码,研究者们可以更容易地应用和改进MobileViT,以促进移动视觉技术的发展。
研究问题
如何结合卷积神经网络(CNNs)和视觉变换器(ViTs)的优点来构建轻量级且低延迟的移动设备适用网络?
研究方法
实验研究: 本文通过设计和实现MobileViT模型,在ImageNet-1k数据集上从零开始训练,并与其他轻量级和 heavyweight 的CNN及Vision Transformer模型进行了对比实验,验证了MobileViT在图像分类任务上的优越性能。
混合方法研究: MobileViT结合了卷积神经网络(CNNs)和变换器(Transformers)的优点,通过引入MobileViT块来同时处理局部和全局信息。这种方法融合了两种不同的技术,旨在创建一个既具备CNN的局部感知能力又具有Transformer全局处理能力的轻量级模型。
比较研究: 文章中展示了MobileViT在不同参数预算下与MobileNetv3、DeiT等模型的性能对比,特别是在ImageNet-1k数据集上的表现,证明了MobileViT的优越性。
研究思路
这篇论文提出了一种新型的轻量级视觉变换器网络模型,称为MobileViT,旨在结合卷积神经网络(CNN)和视觉变换器(ViT)的优点,以满足移动视觉任务对模型轻量化和快速推理的需求。
MobileViT的理论框架基于以下几个核心理论基础:
- 卷积神经网络(CNN):CNN在处理视觉数据时,能通过空间归纳偏见有效学习局部特征,已被广泛应用于各种计算机视觉任务。然而,传统的CNN对全球信息的建模能力不足,限制了其在复杂任务中的表现。
- 视觉变换器(ViT):ViT通过自注意力机制在全局范围内建立特征间的关系,能够捕捉图像中的长程依赖性。虽然它在准确性上优于CNN,但由于模型较大,需要更多参数,因此在移动设备上实现存在困难。
论文采用了以下具体方法与技术路线:
- MobileViT模块设计:MobileViT模块通过将局部卷积与全局变换结合,创建了一种新的信息处理方式。具体来说,它使用标准的局部卷积层来学习局部特征,然后通过变换器来建模全局特征。通过展开和折叠(unfolding and folding)操作,有效地将局部信息整合到全局特征中,从而使得每个像素能够访问全图的特征。
- 训练过程与样本多样性:论文中还提出了一种多尺度采样器,用于提高训练效率和模型的泛化能力。多尺度训练可以使模型在不同分辨率下均衡学习,提高了模型对未见数据的表现。
MobileViT
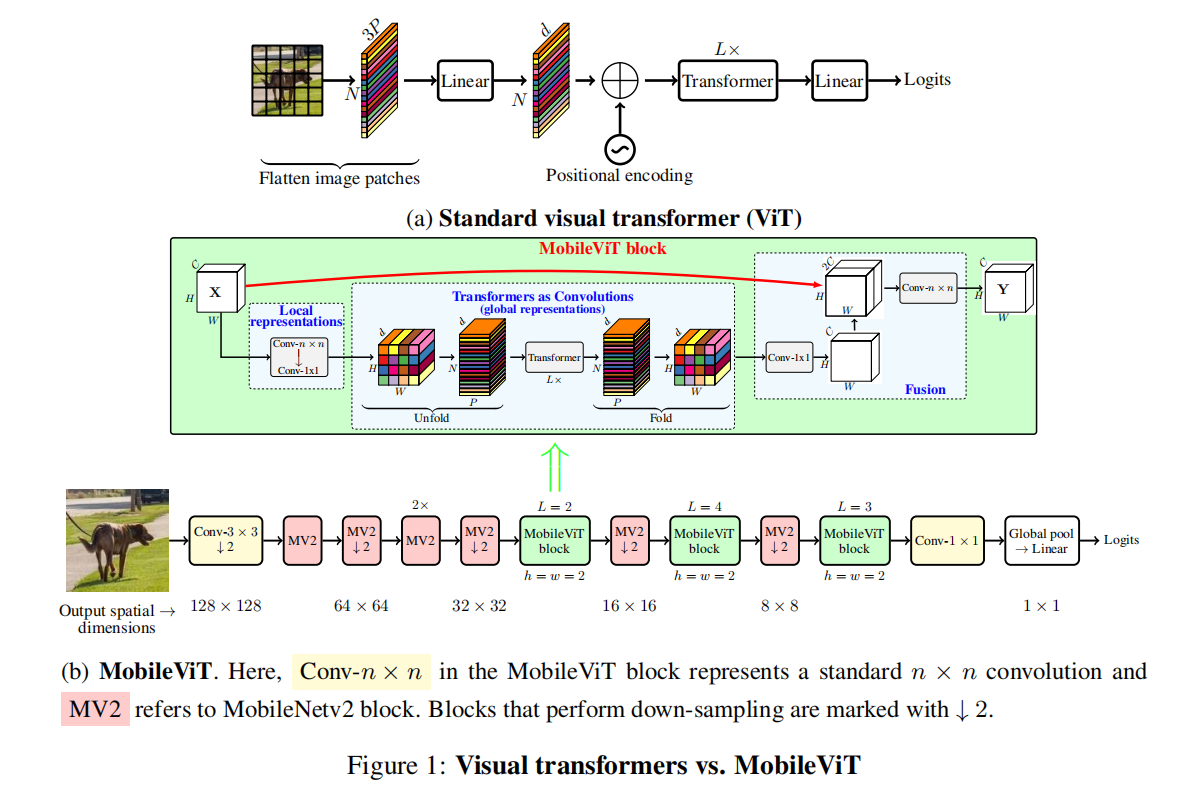
一个标准 ViT 模型,如图 1a 所示,将输入 X ∈ R H × W × C \mathbf{X}\in\mathbb{R}^{H\times W\times C} X∈RH×W×C转换为一个扁平化的块 X f ∈ R N × P C \mathbf{X}_f\in\mathbb{R}^{N\times PC} Xf∈RN×PC,并将其投影到一个固定大小的 d d d维空间中 X p ∈ R N × d \mathbf{X}_p\in\mathbb{R}^{N\times d} Xp∈RN×d,然后使用 L L L个自注意力堆栈来学习跨块表示。视觉 Transformer 中的自我注意计算成本为 O ( N 2 d ) O(N^{2}d) O(N2d)。其中, C 、 H C、H C、H和 W W W分别代表张量的通道数、高度和宽度, P = w h P = wh P=wh是具有高度 h h h和宽度 w w w的块中的像素数, N N N是块的数量。由于这些模型忽略了卷积神经网络固有的空间归纳偏置,因此需要更多的参数来学习视觉表示。例如,基于 ViT 的DPT(Dosovitskiy等人,2021)比基于 CNN 的 DeepLabv3(Chen等人,2017)多学习了6倍的参数,以提供类似的分割性能(DPT vs. DeepLabv3:345M vs. 59M)。此外,与卷积神经网络相比,这些模型在优化方面表现不佳。这些模型对 L2 正则化敏感,并且需要大量的数据增强来防止过拟合(Touvron等人,2021a;Xiao等人,2021)。
本文介绍了一种轻量级的 Vision Transformer 模型,名为 MobileViT。其核心思想是使用 Transformer 学习全局表示,就像卷积一样。这使我们能够隐式地在网络中引入类似卷积的性质(例如空间偏差),并使用简单的训练技巧学习表示(例如基本的数据增强),并轻松地将 MobileViT 集成到下游架构中(例如用于分割任务的 DeepLabv3)。
MobileViT Block
MobileViT块如图 1b 所示,MobileViT 块旨在用更少的参数来建模输入张量中的局部和全局信息。形式化地,对于给定的输入张量 X ∈ R H × W × C \mathbf{X}\in\mathbb{R}^{H\times W\times C} X∈RH×W×C,MobileViT 应用一个 n × n n\times n n×n的标准卷积层后跟一个逐元素(或1×1)卷积层来产生 X L ∈ R H × W × d \mathbf{X}_L\in\mathbb{R}^{H\times W\times d} XL∈RH×W×d。 n × n n\times n n×n卷积层编码了局部空间信息,而逐点卷积通过学习输入通道的线性组合,将张量投影到高维空间(即 d d d维空间,其中 d > C d > C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3653
3653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











