







| 论文标题 | Separable Self-attention for Mobile Vision Transformers |
|---|---|
| 论文作者 | Sachin Mehta, Mohammad Rastegari |
| 发表日期 | 2023年06月01日 |
| GB引用 | > Sachin Mehta, Mohammad Rastegari. Separable Self-attention for Mobile Vision Transformers[J]. Transactions on Machine Learning Research(TMLR), 2023, 2835-8856. |
| DOI | 10.48550/arXiv.2206.02680 |
论文地址:https://arxiv.org/pdf/2206.02680
摘要
本文提出了一种可分离自注意力机制,以解决移动视觉变换器(MobileViT)中多头自注意力(MHA)造成的效率瓶颈。现有的MHA方法在处理k个标记时的时间复杂度为O(k²),这在资源受限的设备上会导致高延迟。新提出的可分离自注意力方法将复杂度降低到O(k),并通过元素级操作(如加法和乘法)来计算自注意力,从而改善了推理速度。经过实验证明,改进后的模型MobileViTv2在多个移动视觉任务上达到了最先进的性能,包括在ImageNet数据集上取得了75.6%的Top-1准确率,相比MobileViT提高了约1%,且在移动设备上快了3.2倍。该研究展示了可分离自注意力在资源受限设备上的有效性,为未来的视觉模型优化提供了新的方向。
全文摘要
这篇论文的主题是针对移动视觉任务提出了一种新颖的分离自注意力机制,称为“可分离自注意力”,以优化Transformer中多头自注意力的计算效率。
研究背景是,尽管移动视觉变压器(MobileViT)在各项移动视觉任务中展现出卓越的性能,但其主要瓶颈在于多头自注意力(MHA)操作的高延迟。
论文的主要结论是,提出的可分离自注意力方法将其时间复杂度从O(k²)降低到O(k),从而显著提高在资源受限设备上的推理速度。不同于传统的MHA必须通过批量矩阵乘法等高成本操作来计算注意力矩阵,可分离自注意力采用逐元素操作,极大地提升了计算效率。实验结果表明,改进后的模型MobileViTv2在多项移动视觉任务中性能出众,如在ImageNet图像分类任务中,MobileViTv2的Top-1准确率为75.6%,比前一版本MobileViT提高了约1%,同时在移动设备上推理速度快了3.2倍。
论文的独特之处在于它提出了一种切实可行的自注意力优化策略,使得Transformer架构更适合移动设备。此外,MobileViTv2具有更少的参数与更好的性能,使其在实际应用中更具优势。
研究问题
能否优化变压器块中的自注意力机制以适应资源受限的设备?
研究方法
实验研究: 该论文通过训练和测试多个模型版本(如MobileViTv2-0.5, MobileViTv2-1.0等),在ImageNet-1k和ImageNet-21k数据集上验证了所提出的方法的有效性。此外,还对比了不同模型在不同输入分辨率下的性能,展示了MobileViTv2在高分辨率输入下的优越性能。
混合方法研究: 文章中提到的MobileViTv2模型结合了卷积神经网络(CNN)和视觉变换器(ViT)的优点,通过引入分离自注意力机制来改进MobileViT模型。这种混合方法不仅提高了模型的效率,还保持了良好的性能表现。
比较研究: 文中多次使用比较研究方法,例如比较不同模型(如MobileViTv2与MobileFormer)在不同任务上的表现(如图像分类、目标检测和语义分割)。这些比较展示了MobileViTv2模型在低延迟和高准确性方面的优势。
研究思路
这篇论文的研究思路主要集中在提高移动视觉任务中变换器模型(特别是移动视觉变换器,MobileViT)的计算效率。虽然现有的变换器模型在许多视觉任务上表现优异,但它们在资源受限设备上(如手机)存在高延迟的问题。因此,论文提出了一种新的可分离自注意力机制,以解决这一瓶颈。
理论基础:
- 论文基于自注意力机制和变换器架构,特别是多头自注意力(MHA)机制。MHA的优点在于它能捕捉到全局信息,并允许输入的每个标记(或补丁)相互作用。
- 论文进一步引入了“可分离自注意力”的概念,这种机制的时间复杂度为 O ( k ) O(k) O(k),与传统的 O ( k 2 ) O(k^2) O(k2) 相比大幅降低了计算复杂度。
模型架构:
- MobileViT是一个混合网络,结合了卷积神经网络(CNN)和变换器的优势。作者在此基础上,将MHA替换为可分离自注意力,形成新的模型MobileViTv2。
- MobileViTv2模型在架构上进行了优化,以便在充分保留性能的同时减少计算资源的消耗。
具体方法:
- 论文首先分析了MHA在移动设备上推理时的延迟和计算复杂度问题。
- 提出了可分离自注意力机制,该机制通过以下步骤实现:
- 使用一个线性层将输入投影到标量,计算与潜在标记的内积,以获得上下文分数。
- 通过传播上下文分数来计算上下文向量,借助简单的逐元素运算(如加法和乘法)而非复杂的矩阵运算来完成。
- 在不同的视觉任务(如图像分类、目标检测和语义分割)上进行了实证实验,验证了可分离自注意力在性能和速度上的优越性。
技术路线:
- 实验在ImageNet、MS-COCO等标准数据集上进行,使用了不同的模型复杂度和输入分辨率。
- 为了评估模型的效果,进行了一系列对比实验,包括与传统CNN模型和其它变换器模型的比较。
MobileViT V2
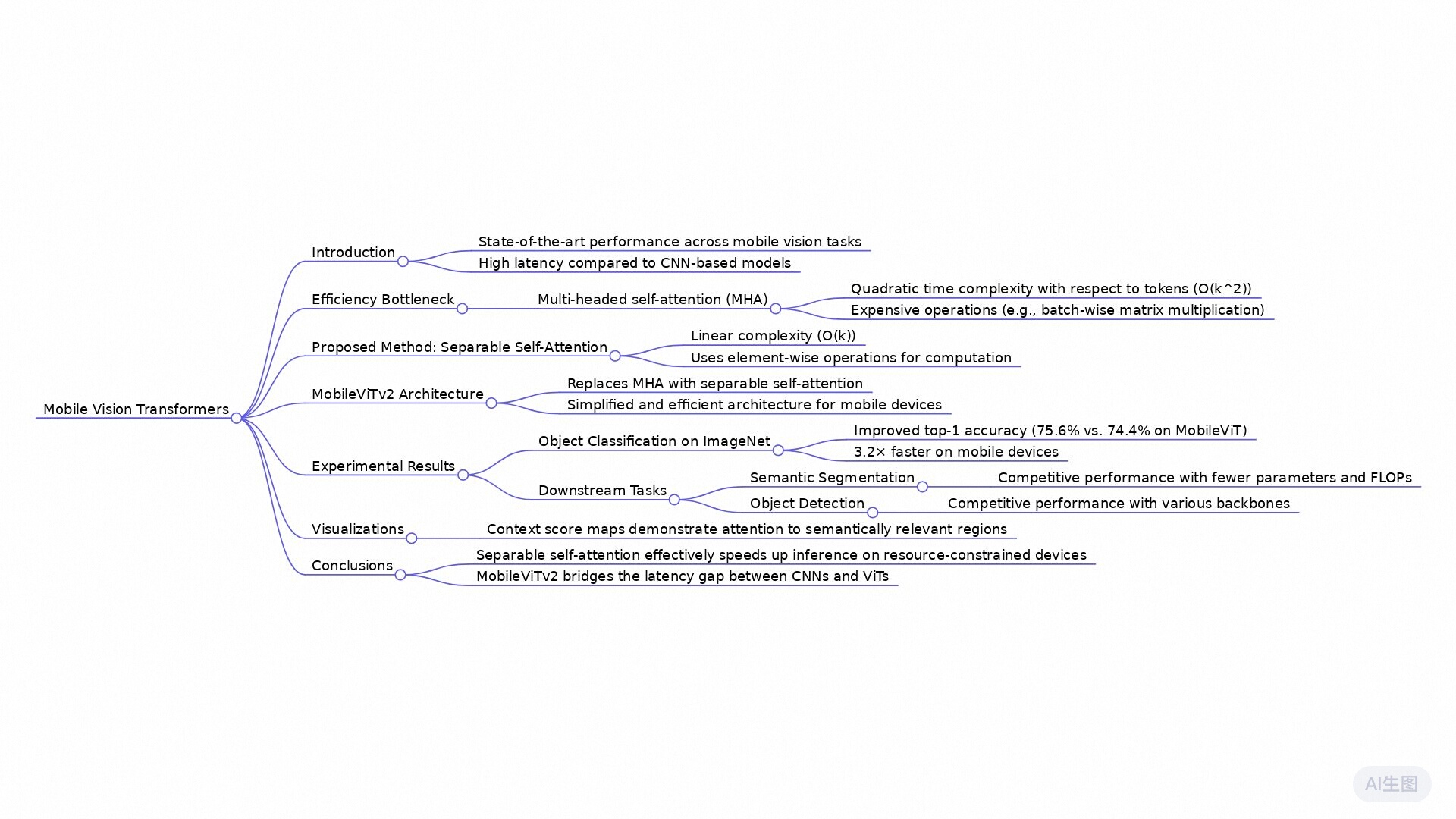
MobileViT [4] 是一种混合网络,结合了卷积神经网络 (CNN) 和视觉注意力模型 (ViT) 的优势。MobileViT 将转换器视为卷积运算,使其能够利用卷积的优点(如归纳偏见)和转换器的优点(如长程依赖关系),从而构建适用于移动设备的轻量级网络。尽管与轻量级 CNN(例如 MobileNets [24,25])相比,MobileViT 网络具有显著更少的参数并且性能更好,但它们有较高的延迟。MobileViT 中的主要效率瓶颈是多头自注意层(MHA;图 3a)。
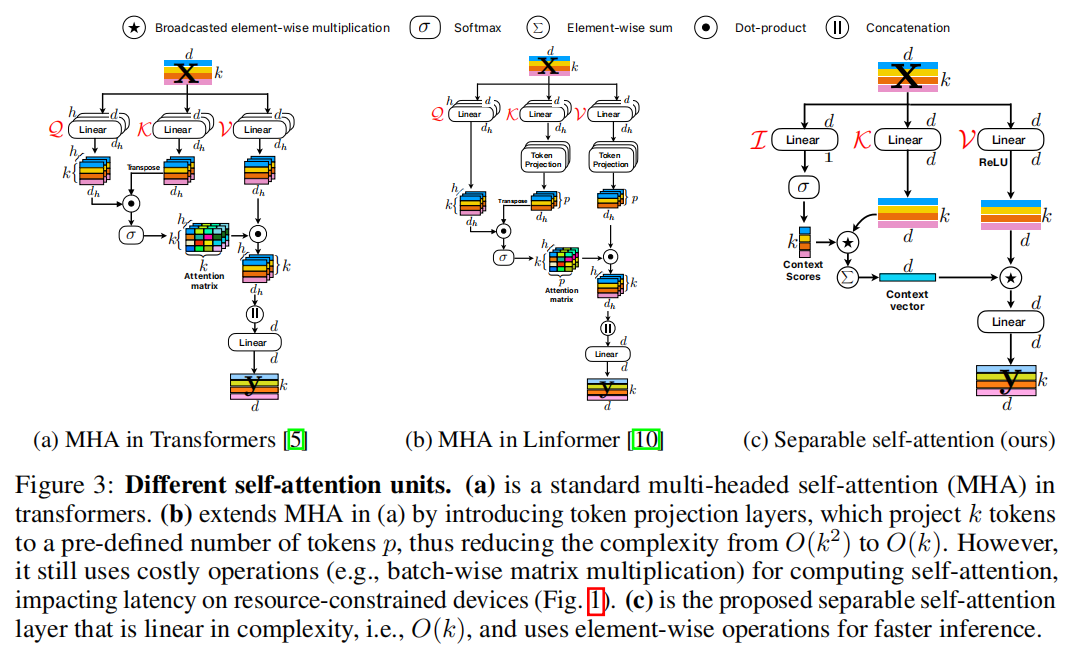
MHA 使用缩放点积注意力来捕捉 k k k个标记(或补丁)之间的上下文关系。然而,由于 MHA 具有 O ( k 2 ) O(k^2) O(k2)的时间复杂度,因此它代价高昂。这种二次成本对于具有大量标记 k k k的变压器来说是一个瓶颈(图 1)。此外,MHA 使用计算和内存密集型操作(例如批量矩阵乘法和 softmax 来计算注意力矩阵;图 1),这可能成为资源受限设备上的瓶颈。为了解决 MHA 在资源受限设备上有效推理的局限性,本文引入了具有线性复杂度的可分离自注意(图 3c)。

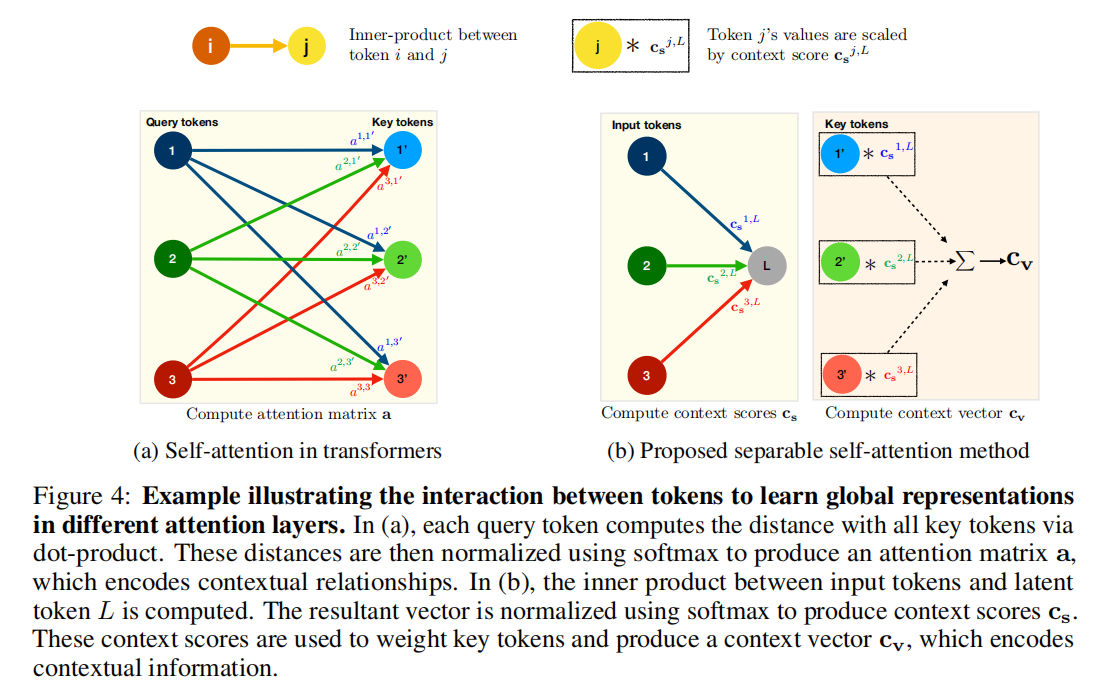
我们分离自注意力方法的主要思想如图 4 (b) 所示,即根据潜在标记 L L L 计算上下文分数。然后使用这些分数对输入标记进行加权以产生一个表示全局信息的上下文向量。由于所使用的自注意计算是基于潜在标记的,因此本方法可以将变压器中的自注意复杂性降低 k k k 倍。本方法的一个简单而有效的特性是它使用标量运算(例如求和和乘法)来实现,使其成为资源受限设备上的一个好的选择。我们称这种注意方法为分离自注意,因为它允许我们通过两个独立的线性计算替换二次 MHA 来编码全局信息。改进后的模型,MobileViTv2,是在MobileViT中用分离自注意力代替MHA得到的。
多头自注意力综述
MHA(图 3a)允许变压器编码令牌之间的关系。具体来说,MHA 接受一个输入 x ∈ R k × d \mathbf{x}\in\mathbb{R}^{k\times d} x∈Rk×d,其中包含 k k k个 d d d维令牌(或补丁)嵌入。然后,将输入 x \mathbf{x} x提供给三个分支,即查询 Q \mathcal{Q} Q、键 K \mathcal{K} K和值 V \mathcal{V} V。每个分支 ( Q \mathcal{Q} Q、 K \mathcal{K} K、 V \mathcal{V} V) 都由 h h h个线性层(或头)组成,这使得变压器能够学习到多个视角的输入。然后,对于所有 h h h个头并行计算查询 Q \mathcal{Q} Q和键 K \mathcal{K} K的输出的内积,并随后应用 softmax 操作 σ σ σ以产生注意力(或上下文映射)矩阵 a ∈ R k × k × h \mathbf{a}\in\mathbb{R}^{k\times k\times h} a∈Rk×k×h。然后在线性层 V \mathcal{V} V的输出与 a 计算另一个内积来产生加权和输出 y w ∈ R k × d h × h \mathbf{y_w}\in\mathbb{R}^{k\times d_h\times h} yw∈Rk×dh×h,其中 d h d_h dh是头的维度。来自 h h h个头的输出被连接起来形成一个具有 k k k个 d d d维令牌的张量,然后馈送给另一个具有权重 W O ∈ R d × d \mathbf{W}_{\mathbf{O}}\in\mathbb{R}^{d\times d} WO∈Rd×d的线性层,以产生 MHA 的输出 y ∈ R k × d \mathbf{y}\in\mathbb{R}^{k\times d} y∈Rk×d。数学上,可以这样描述这个操作:
y = C o n c a t ( ⟨ σ ( ⟨ x W Q 0 , x W K 0 ⟩ ) ⏟ a 0 ∈ R k × k , x W V 0 ⟩ , ⋯ , ⟨ σ ( ⟨ x W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











