







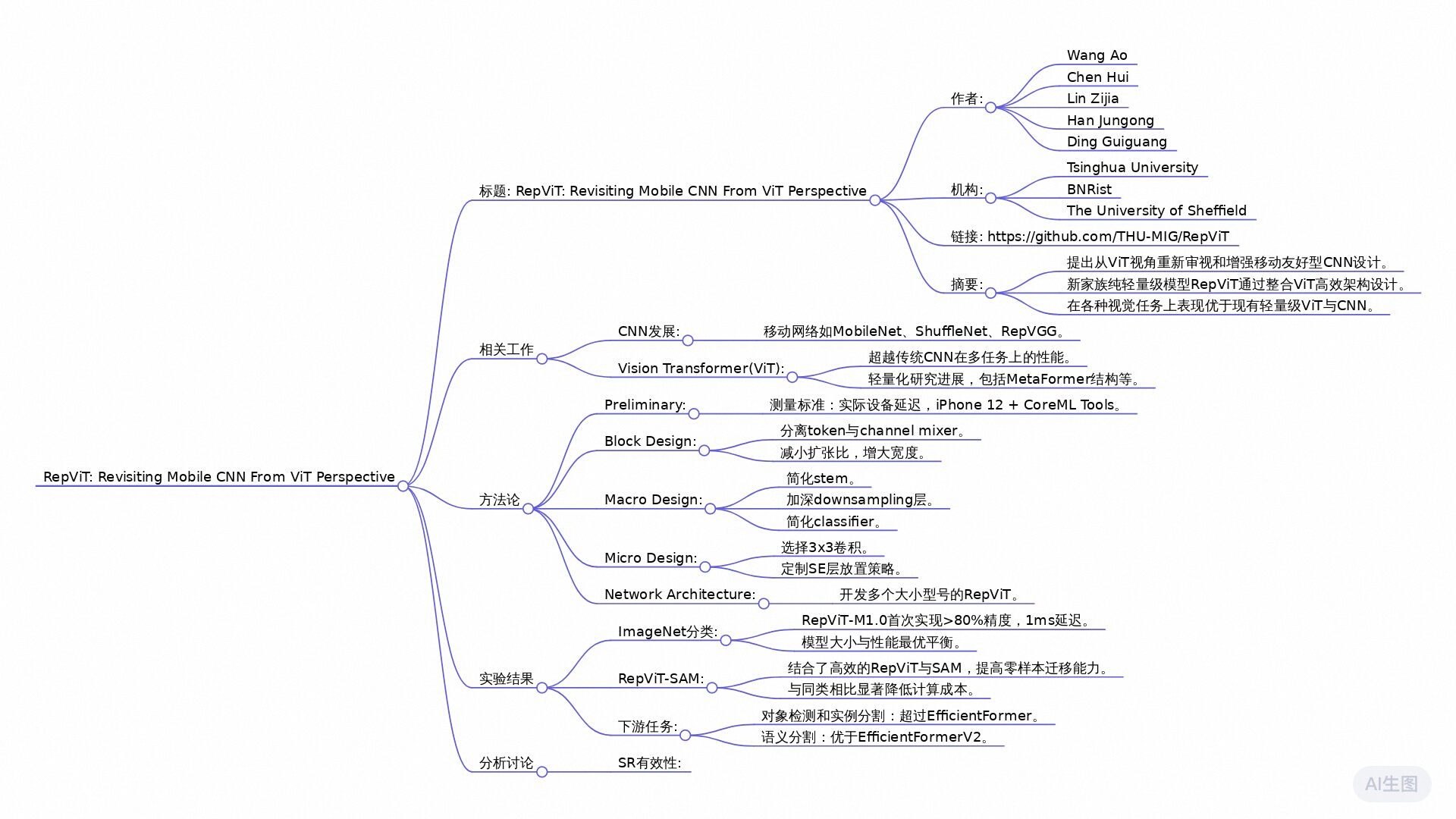
| 论文标题 | RepViT: Revisiting Mobile CNN From ViT Perspective |
|---|---|
| 论文作者 | Ao Wang, Hui Chen, Zijia Lin, Jungong Han, Guiguang Ding |
| 发表日期 | 2024年09月16日 |
| GB引用 | > Wang Ao, Chen Hui, Lin Zijia, et al. RepViT: Revisiting Mobile CNN From ViT Perspective[J]. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2024: 15909-15920. |
| DOI | 10.1109/CVPR52733.2024.01506 |
论文地址:https://arxiv.org/pdf/2307.09283
摘要
本文研究了从视觉Transformer(ViT)的角度重新设计轻量级卷积神经网络(CNN),提出了一种新的纯轻量级CNN模型RepViT。通过整合轻量级ViTs的高效架构设计,RepViT在多个视觉任务中表现出优越的性能和较低的延迟。实验表明,RepViT在ImageNet上达到了超过80%的top-1准确率,仅需1.0毫秒的延迟。此外,RepViT与SAM结合后,其推理速度比先进的MobileSAM快近10倍,同时保持了显著的零样本迁移能力。RepViT展示了纯轻量级CNN在移动设备上的巨大潜力,并有望成为未来研究的基准。
全文摘要
论文标题《RepViT: Revisiting Mobile CNN From ViT Perspective》探讨了在资源有限的移动设备上设计高效轻量化模型的重要性。近年来,轻量化的视觉变换器(ViT)在各种视觉任务中表现出了优越性能,但由于参数数量大和高延迟,这使得它们不适合移动设备。相对而言,轻量化卷积神经网络(CNN)在计算速度和设备优化方面具有优势。因此,作者提出了一种融合ViT架构设计的新轻量化CNN系列模型,命名为RepViT。
主要结论包括:
- 改进架构设计:RepViT在传统轻量化CNN(如MobileNetV3)的基础上,逐步引入了ViT的高效架构设计元素,从而提升了性能和效率。这种改进使RepViT在多项视觉任务中超越了现有的轻量级ViT和CNN。
- 性能优势:在ImageNet数据集上,RepViT实现了超过80%的顶级准确率,并在iPhone12上仅需1.0毫秒的延迟。这是轻量化模型首次达成此类性能指标。此外,RepViT-SAM模型在处理速度上比当前先进的MobileSAM快近10倍。
- 结合多项视野任务:研究表明,RepViT不止在图像分类上表现优越,还在目标检测、实例分割和语义分割等多种计算机视觉任务中展现了良好的性能。
论文的独特之处在于它通过将轻量化CNN与ViT设计原理结合,重新审视了CNN的架构设计,展示了轻量化CNN在移动设备部署中的光明前景,为后续轻量化模型的研究提供了强有力的基线。整体而言,RepViT不仅提升了轻量化CNN的表现,还推动了低功耗视觉模型的实际应用潜力。
研究问题
轻量级 ViT 的架构设计能否增强移动设备轻量级 CNN 的性能?
研究方法
实验研究: 通过逐步“现代化”MobileNetV3-L的架构,并结合轻量级ViTs的高效设计,最终形成了一种新的纯轻量级CNN,即RepViT。
混合方法研究: 在RepViT的设计过程中,结合了轻量级ViTs的结构设计,如MetaFormer块结构,以及轻量级CNN的传统模块,如深度可分离卷积。
定量研究: 通过对各种模型参数、延迟、准确率等指标进行对比分析,展示了RepViT在不同视觉任务上的优越性能和低延迟。
系统分析: 研究了从块设计到宏观设计再到微观设计的不同层次,系统地优化了MobileNetV3-L的架构,最终形成了RepViT模型。
比较研究: 通过将RepViT与其他现有模型(如MobileViT、EfficientFormer等)进行对比,展示了RepViT在准确率和延迟方面的优势。
研究思路
该研究旨在利用轻量级ViTs中的高效架构设计来“现代化”标准轻量级CNN(如MobileNetV3),并探讨其在移动设备上的表现。考虑到CNN在移动设备上具有更好的硬件优化和更低的延迟,研究者们重新审视了传统CNN的设计,从ViTs的视角出发,通过整合轻量级ViTs的设计理念来提升轻量级CNN的性能。
理论框架
模型理论基础:论文的理论框架主要基于轻量级ViTs的设计原则,包括分离的通道混合器和令牌混合器结构、结构重参数化(Structural Re-parameterization)、以及不同的块结构(MetaFormer)。这些理论基础为设计新的RepViT模型提供了支持,使之能够显著减少模型的延迟并提高准确性。
具体方法和技术路线:
- 延迟测量:论文采用真实设备(例如iPhone12)进行模型延迟的测量,而不仅仅依赖于浮点运算(FLOPs)等理论指标。
- 训练食谱对齐:Aligning的训练公式与轻量级ViTs一致,使用了AdamW优化器和余弦学习率调度器,以确保比较的公正性。
- 块设计优化:将MobileNetV3中的块结构进行分离式重组,特别是移除与ViT中不同的混合器结构,通过改进后的RepViT块实现了更低的延迟,并在某些情况下牺牲了一定的准确性。
- 宏观架构优化:在整体架构设计上,引入了早期卷积(Early Convolutions)以减少输入图像的复杂预处理,采用深度下采样层以保持信息,从而缓解模型的调优敏感性。
- 微观设计调整:通过优化卷积核尺寸和SE层的放置,确保在保证性能的同时降低延迟。
方法
在本节中,我们从标准轻量级卷积神经网络 (CNN) 即 MobileNetV3-L 开始,并通过融合轻量级视觉 Transformer 的架构设计来逐渐对其进行现代化。首先,在第 3.1 节介绍用于衡量移动设备上延迟的度量方法,然后针对现有轻量级视觉 Transformer 对训练过程进行调整。基于一致的训练设置,我们在第 3.2 节探索最佳块的设计。我们在第 3.3 节进一步优化 MobileNetV3-L 在移动设备上的性能,即主干、下采样层、分类器以及总体阶段比率等宏观架构元素。然后我们在第 3.4 节对轻量级 CNN 进行逐层微调设计。图 2 展示了每个步骤中的完整流程及所实现的结果。最后,在第 3.5 节获得一个专门针对移动设备设计的新纯轻量级 CNN 家族,名为 RepViT。所有模型都在 ImageNet-1K 上进行了训练和评估。
延迟度量。先前的工作[5,57]根据浮点运算(FLOPS)或模型大小等指标优化了模型的推理速度。然而,这些指标与移动应用程序中的真实世界延迟的相关性并不好[36]。因此,如[35,36,46,60]所述,我们使用实际设备上的延迟作为基准度量。这种策略可以提供更准确的性能评估,并在现实世界的移动设备上对不同模型进行公平比较。实践中,我们使用iPhone 12作为测试设备,并使用Core ML工具包[1]作为编译器,如[35,36,60]所示。此外,为了避免不受支持的功能,我们在MobileNetV3-L模型中使用GeLU激活,如[36,60]所述。
我们测量MobileNetV3-L 的延迟为1.01毫秒。
对齐训练方案。最近轻量级ViTs [35、36、46、49]通常采用DeiT[58]的训练方案。具体来说,它们使用AdamW优化器[42] 和余弦学习率调度程序来训练模型,从头开始训练了 300 个 epoch,使用了 RegNetY-16GF[51]作为教师来进行蒸馏。此外,他们还采用了 Mixup[72]、auto-augmentation[8] 和随机擦除[77] 进行数据增强。同时还采用了标签平滑(Label Smoothing)[56] 作为正则化方案。为了公平比较,我们调整了 MobileNetV3-L 的训练配方,使其与现有的轻量级 ViT 相匹配,但目前不包括知识蒸馏。因此,MobileNetV3-L 获得了 71.5% 的 top-1 准确率。
Block 设计
Separate token mixer and channel mixer(可分离的token混合器和通道混合器)。轻量级 ViT [35、36、47] 的块结构包含一个重要的设计特征,即分离令牌混合器和通道混合器 [70]。根据最近的研究 [69],
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5144
5144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











