







一、前言
arXiv作为全球最大的开放获取预印本平台,涵盖物理、计算机科学、数学等多个领域的前沿论文,成为科研人员获取最新学术动态的重要渠道。但是,海量信息的存在也带来了查找与筛选的挑战。如何让AI助手不仅理解用户的需求,还能主动搜索、筛选并准确返回arXiv上的相关论文?
MCP作为一种新兴的模型上下文协议,能够有效整合多源信息,为AI模型提供结构化、动态的上下文支持,使其在面对复杂查询时表现更为智能和灵活。
ArXiv MCP Server 是一个基于模型上下文协议(MCP)的专用服务器,旨在为 AI 助手提供强大的 arXiv 论文搜索与分析功能。通过该服务器,AI 模型能够以编程接口的形式,便捷地执行论文的检索、下载、浏览和内容解析等操作,极大地提升了与学术资源交互的智能化水平。
该服务器不仅支持实时调用 arXiv 的数据接口,还具备本地缓存和存储机制,使得已下载的论文能够被快速访问和反复利用,显著提升响应速度和系统稳定性。而且,ArXiv MCP Server 还内置了智能研究提示功能,能够根据用户查询自动生成相关的分析建议,帮助用户更高效地理解论文内容、发现研究热点和拓展思路。
凭借其灵活的 MCP 协议设计,ArXiv MCP Server 可无缝集成到各类 AI 助手和学术辅助工具中,支持多样化的应用场景,如科研文献管理、自动化文献综述、智能问答系统等。它不仅降低了 AI 模型访问复杂学术资源的门槛,也为科研人员提供了便捷、高效的知识获取和分析手段,推动学术研究的智能化进程。
腾讯云重磅上线了MCP广场:https://cloud.tencent.com/developer/mcp?channel=ugc,里面恰好上线了【ArXiv AI搜索服务】。本文将就进行MCP实践,将ArXiv MCP server 接入CodeBuddy腾讯云代码助手,赋予精确的 AI 搜索论文能力。
二、ArXiv MCP Server 核心功能
ArXiv MCP 服务器通过模型上下文协议(MCP)搭建了AI助手与arXiv学术资源之间的高效桥梁,赋能AI模型以编程方式实现对arXiv论文的精准搜索和内容访问。该服务器不仅简化了复杂的学术数据调用流程,还通过结构化的协议接口,增强了AI助手在科研场景中的智能交互能力。
核心功能亮点:
- 论文搜索:支持基于时间范围、学科类别等多维度条件的精细筛选,帮助AI模型快速定位目标论文,提升检索效率和准确性。
- 论文访问:实现论文全文的下载与解析,AI助手可直接读取论文内容,辅助生成摘要、提取关键信息或进行深入分析。
- 论文列表管理:提供已下载论文的统一列表查看功能,方便用户随时浏览和管理本地存储的文献资源。
- 本地存储机制:将论文缓存于本地存储,显著缩短访问延迟,支持离线阅读和多次调用,提升系统响应速度和稳定性。
- 智能提示词库:内置一套丰富的研究提示词,辅助AI助手在论文内容理解和知识拓展方面提供更具针对性和深度的辅助建议。
三、ArXiv MCP Server使用教程
如果希望快速将 ArXiv MCP Server 集成到 Claude Desktop 中,可以使用 Smithery 工具自动完成安装。只需在命令行执行以下命令:
npx -y @smithery/cli install arxiv-mcp-server --client claude
该命令会自动下载并配置 ArXiv MCP Server,使其无缝对接 Claude Desktop,极大简化安装流程。
如果使用 VSCode 等IDE,推荐手动管理或在其他环境中部署,可以使用 uv 命令行工具直接安装:
uv tool install arxiv-mcp-server
此命令会从官方源获取最新版本并安装,适用于多种运行环境。
若计划参与开发、调试或自定义 ArXiv MCP Server,按照以下步骤搭建完整的开发环境:
-
克隆代码库
git clone https://github.com/blazickjp/arxiv-mcp-server.git cd arxiv-mcp-server -
创建并激活虚拟环境
uv venv source .venv/bin/activate -
安装依赖及测试工具
uv pip install -e ".[test]"
这里演示如何集成ArXiv MCP server 到CodeBuddy腾讯云代码助手。
首先,VS从的中安装CodeBuddy插件。
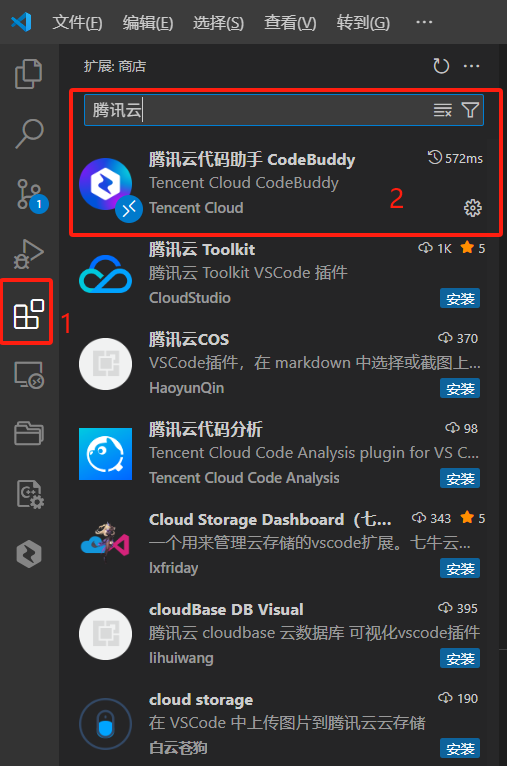
然后在 CodeBuddy 对话框找到 MCP 选项:
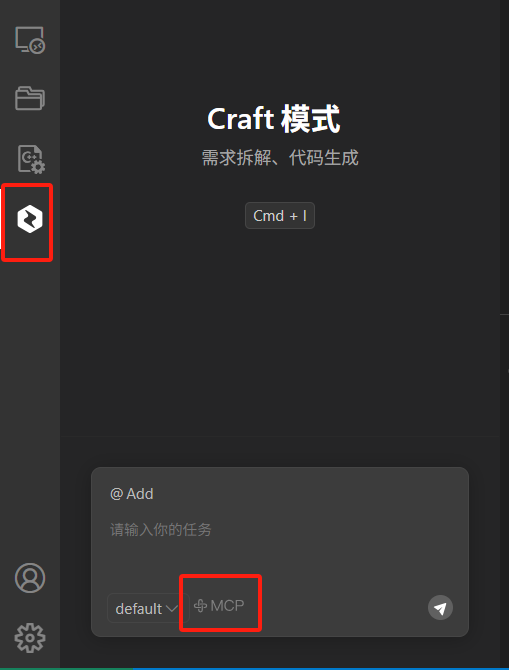
添加MCP服务器:
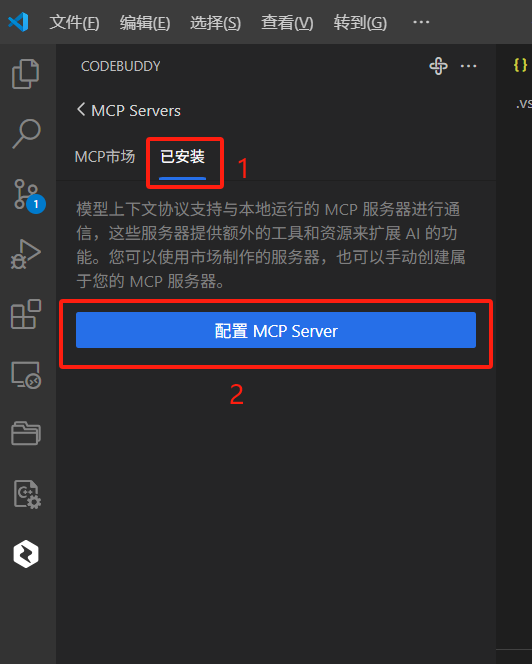
在弹出来的Craft_mcp_settings.json 文件中输入如下内容:
{
"mcpServers": {
"arxiv-mcp-server": {
"command": "uv",
"args": [
"--directory",
"/home/fly/workspace/arxiv-mcp-server",
"run",
"arxiv-mcp-server",
"--storage-path",
"/home/fly/workspace/arxiv-mcp-server/storage"
],
"timeout": 300,
"autoApprove": [
"read_paper"
]
}
}
}
然后点击运行按钮运行:
此时你就可以在AI中搜索和访问arXiv论文啦!

四、可用工具说明
ArXiv MCP 服务器为用户和AI助手提供了四个核心工具,支持从论文检索到深入阅读的完整流程。
(1)论文搜索:该工具支持基于关键词的论文检索,同时允许通过多种过滤条件精准筛选目标文献。用户可以指定搜索关键词、最大返回结果数、起始日期以及论文学科分类,从而获得符合需求的最新或特定领域的论文列表。
示例调用:
result = await call_tool("search_papers", {
"query": "transformer architecture",
"max_results": 10,
"date_from": "2023-01-01",
"categories": ["cs.AI", "cs.LG"]
})
功能说明:
query: 检索关键词或短语max_results: 返回的最大论文数量限制date_from: 论文发表或提交的起始日期categories: arXiv 分类代码列表,如人工智能(cs.AI)、机器学习(cs.LG)
(2)论文下载:通过论文的唯一arXiv标识号(arXiv ID)直接下载所需论文全文。这一功能支持本地缓存,方便后续快速访问和离线阅读。
示例调用:
result = await call_tool("download_paper", {
"paper_id": "2401.12345"
})
(3)列出论文:查看当前本地存储库中所有已下载的论文列表。该工具方便用户管理和检索已保存的文献资源,支持快速定位目标论文。
示例调用:
result = await call_tool("list_papers", {})
(4)阅读论文:访问并读取本地已下载论文的具体内容,支持AI模型进行文本分析、摘要生成和深入解读。
示例调用:
result = await call_tool("read_paper", {
"paper_id": "2401.12345"
})
通过这四大工具,ArXiv MCP 服务器实现了从论文搜索、下载到管理和内容访问的全流程支持,极大提升了科研信息的自动化处理能力。
此外,ArXiv MCP 服务器内置了一套专门设计的提示词(Prompts),旨在辅助用户和AI模型高效且系统地分析学术论文,极大提升研究效率和理解深度。
该提示词通过只需提供一个论文的arXiv ID,即可启动一整套结构化的学术论文分析流程,帮助用户全面把握论文的核心内容与价值。
示例调用:
result = await call_prompt("deep-paper-analysis", {
"paper_id": "2401.12345"
})
功能与优势:
-
集成多工具操作: 该提示词内置了对服务器核心工具的调用指导,包括:
list_papers:列出本地已下载论文download_paper:下载目标论文read_paper:读取论文全文内容search_papers:辅助查找相关文献
-
系统化分析流程: 通过预设的工作步骤,提示词引导AI模型逐步展开论文解读,确保分析覆盖全面且条理清晰。
-
多维度全面解析: 分析内容涵盖以下关键方面,帮助用户深入理解论文价值与应用潜力:
- 执行摘要:简明扼要地总结论文核心内容
- 研究背景:解析研究所处的学术环境和动机
- 方法论分析:详细解读采用的研究方法和技术路径
- 结果评估:评估实验结果及其可靠性和创新点
- 实践和理论影响:探讨论文对实际应用和理论发展的贡献
- 未来研究方向:预测和建议基于论文的新研究可能性
- 更广泛的影响:讨论论文在社会、伦理、产业等方面的潜在影响
应用场景:
- 学术研究人员:快速获取论文精髓,辅助文献综述与研究设计。
- AI辅助写作:为自动生成学术摘要、批判性分析等提供坚实基础。
- 教育培训:帮助学生和初学者系统理解复杂论文内容。
- 科研管理:支持科研项目评估和趋势分析。
通过利用这一高效的研究提示词,用户不仅能节省大量阅读和分析时间,还能获得结构化、深入且多角度的论文洞察。
五、总结
ArXiv MCP Server作为基于模型上下文协议(MCP)的创新型学术资源访问工具,成功搭建了AI助手与arXiv海量科研论文之间的高效桥梁。它不仅极大简化了论文检索、下载、管理和阅读的流程,还通过智能提示词等功能提升了AI模型对学术内容的理解与分析能力。
通过本服务器,科研人员和开发者能够以编程接口形式,灵活调用arXiv论文数据,快速定位目标文献并深入挖掘论文潜力。这种高效、自动化的文献处理方式,极大节省了时间成本,优化了科研流程。



















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











