







 本文详细介绍在 xv6 操作系统中实现 mmap 和 munmap 系统调用的过程,包括参数解析、内存映射结构体定义、内存分配、页故障处理、内存解除映射以及对 exit 和 fork 的修改等内容。
本文详细介绍在 xv6 操作系统中实现 mmap 和 munmap 系统调用的过程,包括参数解析、内存映射结构体定义、内存分配、页故障处理、内存解除映射以及对 exit 和 fork 的修改等内容。
Lab 10: mmap
- Lab Guide: https://pdos.csail.mit.edu/6.828/2020/labs/mmap.html
- Lab Code: https://github.com/peakcrosser7/xv6-labs-2020/tree/mmap
mmap (hard)
要点
- 实现只考虑内存映射文件的
mmap和munmap系统调用. mmap参数addr一直为 0, 由内核决定映射文件的虚拟地址.mmap参数flags只考虑MAP_SHARED和MAP_PRIVATE.mmap使用懒分配进行内存映射.- 定义一个 VMA 结构体来描述一块虚拟内存的信息. 可以用定长数组记录.
步骤
1. Makefile 修改和系统调用定义
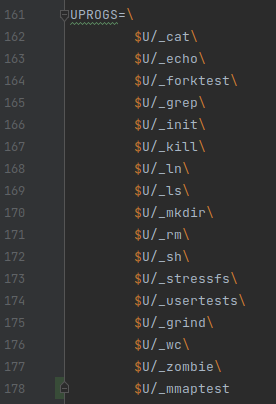
- 在
Makefile中添加$U/_mmaptest
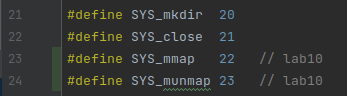
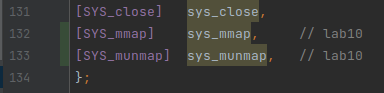
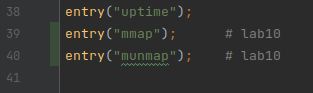
- 添加有关
mmap和munmap系统调用的定义声明. 包括kernel/syscall.h,kernel/syscall.c,user/usys.pl和user/user.h.


2. 定义 vm_area 结构体及其数组
- 在
kernel/proc.h中定义struct vm_area结构体.
vm_area即 Virtual Memory Area, VMA, 此处用于表示使用mmap系统调用文件映射的虚拟内存的区域的位置、大小、权限等(实际上在 Linux 中会用来表示整个虚拟内存区域的相关信息, 包括堆、栈等, 而在此部分实验中出于简单考虑只用于表示文件映射部分内存).
struct vm_area中具体记录的内存信息和mmap系统调用的参数基本对应, 包括映射的起始地址、映射内存长度(大小)、权限、mmap标志位、文件偏移以及指向的文件结构体指针.
// Virtual Memory Area - lab10
struct vm_area {
uint64 addr; // mmap address
int len; // mmap memory length
int prot; // permission
int flags; // the mmap flags
int offset; // the file offset
struct file* f; // pointer to the mapped file
};
- 在
struct proc结构体中定义相关字段.
处于简单, 根据实验指导的提示, 对于每个进程都使用一个 VMA 的数组来记录映射的内存(实际上根据 Linux 的相关实现, 使用链表效果会更好).
此处定义了NVMA表示 VMA 数组的大小. 并在struct proc结构体中定义了vma数组, 且容易知道 VMA 是进程的私有字段, 因此对于 xv6 的进程单用户线程的系统, 访问 VMA 是无需加锁的.
#define NVMA 16 // the number of VMA in a process - lab10
// Per-process state
struct proc {
// ...
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
struct vm_area vma[NVMA]; // VMA array - lab10
};
3. 编写 mmap 系统调用
在 kernel/sysfile.c 中实现系统调用 sys_mmap().
- 首先是参数的提取, 此处
mmap的参数与 Linux 手册中的基本一致, 由于 xv6 中对于系统调用的数字参数只有整数int类型的提取, 因此len,offset参数此处都定义为了int类型. - 接下来是对参数的简单检查. 由于实验中只是实现了
mmap系统调用文件映射部分, 因此prot和flags的参数比较少.flags参数必须为MAP_SHARED和MAP_PRIVATE二选一. 而对于MAP_SHARED由于会写入文件中, 因此若映射的文件是不可写的且使用了PROT_WRITE写映射权限便会报错, 因为不能向不可写的文件写入内容. 最后会检查len和offset的非负性, 以及要求offset是PGSISZE的整数倍(参照 Linux 手册中的限制, 在本实验中offset实际上都是 0). - 然后是从当前进程的 VMA 数组中为该映射分配一个 VMA 结构, 分配的规则也比较简单, 即根据 VMA 中记录的地址, 若为 0 则表示该 VMA 未被使用即可用于本次映射.
- 接下来就是将本次
mmap的参数记录到分配的 VMA 中, 而首先需要考虑的就是用于映射的地址. 根据实验指导, 可以假设addr参数都为 0, 即需要内核自行选择映射的地址.
在此处, 笔者参照 Linux 的内存布局, 在kernel/memlayout.h中定义了MMAPMINADDR宏定义, 用于表示mmap可以用于映射的最低地址. 若本进程有多个文件映射, 因此在实际确定映射的地址时, 会先遍历 VMA 数组, 找到已被映射内存的最高地址, 然后对该地址向上取页面对齐, 进而确定本次mmap的映射地址. 当然, 若映射的地址空间会覆盖TRAPFRAME则会报错. (此处实际上是一个相对简单的实现, 没有考虑映射内存可能从低地址率先释放的问题, 但这样实现则更复杂, 需要计算未分配空间是否满足本次分配, 实现类似内存分区的算法. 此外这里并未对堆空间可能覆盖到映射内存进行检查, 实际上 xv6 也未对堆空间可能覆盖TRAPFRAME进行检查, 可能是考虑到不会分配这么多的内存, 这样可能引起物理内存耗尽.)
根据实验要求,mmap的映射内存采用的也是 Lazy allocation, 因此在此处只需要在 VMA 中记录映射的地址即长度即可, 而后续通过在 trap 中对 page fault 处理进行实际的内存页面分配.
// the minimum address the mmap can ues - lab10
#define MMAPMINADDR (TRAPFRAME - 10 * PGSIZE)
- 对于其他参数则可以直接记录到分配的 VMA 结构中. 对于引用的文件指针, 需要使用
filedup()增加其引用数, 避免其文件结构被释放. - 最后将分配的地址进行返回. 过程中任何失败返回
0xffffffffffffffff即-1.
// lab10
uint64 sys_mmap(void) {
uint64 addr;
int len, prot, flags, offset;
struct file *f;
struct vm_area *vma = 0;
struct proc *p = myproc();
int i;
if (argaddr(0, &addr) < 0 || argint(1, &len) < 0
|| argint(2, &prot) < 0 || argint(3, &flags) < 0
|| argfd(4, 0, &f) < 0 || argint(5, &offset) < 0) {
return -1;
}
if (flags != MAP_SHARED && flags != MAP_PRIVATE) {
return -1;
}
// the file must be written when flag is MAP_SHARED
if (flags == MAP_SHARED && f->writable == 0 && (prot & PROT_WRITE)) {
return -1;
}
// offset must be a multiple of the page size
if (len < 0 || offset < 0 || offset % PGSIZE) {
return -1;
}
// allocate a VMA for the mapped memory
for (i = 0; i < NVMA; ++i) {
if (!p->vma[i].addr) {
vma = &p->vma[i];
break;
}
}
if (!vma) {
return -1;
}
// assume that addr will always be 0, the kernel
//choose the page-aligned address at which to create
//the mapping
addr = MMAPMINADDR;
for (i = 0; i < NVMA; ++i) {
if (p->vma[i].addr) {
// get the max address of the mapped memory
addr = max(addr, p->vma[i].addr + p->vma[i].len);
}
}
addr = PGROUNDUP(addr);
if (addr + len > TRAPFRAME) {
return -1;
}
vma->addr = addr;
vma->len = len;
vma->prot = prot;
vma->flags = flags;
vma->offset = offset;
vma->f = f;
filedup(f); // increase the file's reference count
return addr;
}
4. 编写 page fault 处理代码
由于在 sys_mmap() 中对文件映射的内存采用的是 Lazy allocation, 因此需要对访问文件映射内存产生的 page fault 进行处理. 和之前 Lazy allocation 和 COW 的实验相同, 即修改 kernel/trap.c 中 usertrap() 的代码.
- 首先就是添加对 page fault 情况的 trap 的检查, 由于映射的内存未分配, 而且该内存读写执行都是有可能的, 因此所有类型的 page fault 都可能发生, 因此
r_scause()的值包括12,13和15三种情况. - 接下来则是根据发生 page fault 的地址去当前进程的 VMA 数组中找对应的 VMA 结构体.
这里需要额外说明的是, 根据mmap的 Linux 手册, 文件映射时参数length实际上可以超过文件(从offset起)的大小, 而且文件映射是以页面为单位的, 因此对应超过文件实际大小的部分, 内容都会是 0, 可以访问修改, 但最后都不会写回文件中. 但是这里寻找 VMA 时对于内存上限是通过va < p->vma[i].addr + p->vma[i].len进行比较的(没有增加PGROUNDUP()是因为va事先进行了PGROUNDDOWN()向下取整).
找到对应的 VMA 则表明本次 page fault 是由于访问文件映射的内存产生的, 进而继续后面的工作. - 然后会对 Store Page fault 进行单独的判断, 此处先略过, 这部分是用于脏页标志位(
PTE_D)设置的, 在后续进行统一阐述. - 然后就是进行 Lazy allocation, 使用
kalloc()先分配一个物理页, 并使用memset()进行清空(该步骤是有必要的,kalloc()分配的页面初始充满0x5脏数据). - 紧接着使用
readi()根据发生 page fault 的地址从文件的相应部分读取内容到分配的物理页. 这里读取的大小即为PGSIZE, 若超过文件大小在readi()内部会被截取, 并不影响. 在这个过程前后需要对文件的 inode 进行加锁. - 在读取完文件数据后, 很重要的就是设置该部分的访问权限, 访问权限根据 VMA 中记录的
mmap的prot参数转换为 PTE 的权限标志位. 对于读和执行权限比较简单, 对于写权限此处只有本次是 Store Page fault 时才会设置, 具体原因见后续脏页标志位的说明. - 最后即可使用
mappages()将物理页映射到用户进程的页面值.
void
usertrap(void)
{
// ...
if(r_scause() == 8){
// ...
} else if (r_scause() == 12 || r_scause() == 13
|| r_scause() == 15) { // mmap page fault - lab10
char *pa;
uint64 va = PGROUNDDOWN(r_stval());
struct vm_area *vma = 0;
int flags = PTE_U;
int i;
// find the VMA
for (i = 0; i < NVMA; ++i) {
// like the Linux mmap, it can modify the remaining bytes in
//the end of mapped page
if (p->vma[i].addr && va >= p->vma[i].addr
&& va < p->vma[i].addr + p->vma[i].len) {
vma = &p->vma[i];
break;
}
}
if (!vma) {
goto err;
}
// set write flag and dirty flag to the mapped page's PTE
if (r_scause() == 15 && (vma->prot & PROT_WRITE)
&& walkaddr(p->pagetable, va)) {
if (uvmsetdirtywrite(p->pagetable, va)) {
goto err;
}
} else {
if ((pa = kalloc()) == 0) {
goto err;
}
memset(pa, 0, PGSIZE);
ilock(vma->f->ip);
if (readi(vma->f->ip, 0, (uint64) pa, va - vma->addr + vma->offset, PGSIZE) < 0) {
iunlock(vma->f->ip);
goto err;
}
iunlock(vma->f->ip);
if ((vma->prot & PROT_READ)) {
flags |= PTE_R;
}
// only store page fault and the mapped page can be written
//set the PTE write flag and dirty flag otherwise don't set
//these two flag until next store page falut
if (r_scause() == 15 && (vma->prot & PROT_WRITE)) {
flags |= PTE_W | PTE_D;
}
if ((vma->prot & PROT_EXEC)) {
flags |= PTE_X;
}
if (mappages(p->pagetable, va, PGSIZE, (uint64) pa, flags) != 0) {
kfree(pa);
goto err;
}
}
}else if((which_dev = devintr()) != 0){
// ok
} else {
err:
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
// ...
}
5. 编写 munmap 系统调用
在 kernel/sysfile.c 中实现系统调用 sys_munmap(). 根据实验要求, 该系统调用即将映射的部分内存进行取消映射, 同时若为 MAP_SHARED 则需要将对文件映射内存的修改会写到文件中(在 Linux 中, 会写文件是有 mmap 自动完成的, 与本实验不同).
- 首先也是对参数的提取,
munmap只有addr和length两个参数. - 然后对参数进行简单的检查.
len需要非负; 此外根据 Linux 手册,addr需要是PGSIZE的整数倍. - 接下来同
usertrap()中类似, 根据addr和length找到对于的 VMA 结构体. 未找到则返回失败. - 然后主要就是判断当前取消映射的部分是否有
MAP_SHARED标志位, 有的话则需要将该部分写回文件. 当然在此之前先判断len是否为 0, 若是的话则直接返回成功, 无需后续的工作.
该部分为该系统调用的最为复杂的部分, 需要考虑的有两点: 一是哪些页面需要写入, 另一方面是每次写回文件的写入大小. 对于前者, 根据实验指导, 选择使用脏页标志位(PTE_D)进行记录, 拥有该标志位则表明改部分被修改过, 则需要将该页面写回文件中, 具体脏页标志位的设置见后续. 对于后者, 由于是根据脏页会写文件的, 因此能够想到写入大小为PGSIZE, 但由于len可能不为PGSIZE的整倍数, 此处还需要进行判断. 此外, 根据实验指导, 参考filewrite()函数, 一次写入文件的大小还受日志 block 的影响, 因此可能会再分批次写入文件(实际上PGSIZE大于maxsz, 整页需要写会文件时会被分为两次). - 在将修改内容写回文件后, 便可以使用
uvmunmap()将改部分页面在用户页表中取消映射.
这里采用的是向上页面取整的取消页表映射方法, 实际上感觉有些不合理, 因为可能有一部分页面仍未取消文件映射, 但考虑到addr需要页面对齐, 因此不会在页面中间取消文件映射, 否则后半部分将无法取消文件映射.
此外, 此处修改了uvmunmap()函数的PTE_V标志位的检查部分, 和之前 Lazy allocation 的实验相同, 取消映射的页面可能并未实际分配, 此时跳过即可.
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
// ...
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0)
panic("uvmunmap: walk");
if((*pte & PTE_V) == 0) {
continue; // lab10
// panic("uvmunmap: not mapped"); // lab10
}
if(PTE_FLAGS(*pte) == PTE_V) {
continue; // lab10
// panic("uvmunmap: not a leaf");
}
// ...
}
}
- 最后还要更新一下 VMA 结构体. 因为取消文件映射的部分可能只是 VMA 结构体中文件映射内存的一部分, 但根据实验指导, 取消映射的部分不会在文件映射内存的中间, 即不会由于取消文件映射产生新的一块内存, 因此只需要更新原本 VMA 结构体的相关参数即可. 在整个 VMA 结构体中记录的内存都取消映射时, 则将该 VMA 结构体清空.
// lab10
uint64 sys_munmap(void) {
uint64 addr, va;
int len;
struct proc *p = myproc();
struct vm_area *vma = 0;
uint maxsz, n, n1;
int i;
if (argaddr(0, &addr) < 0 || argint(1, &len) < 0) {
return -1;
}
if (addr % PGSIZE || len < 0) {
return -1;
}
// find the VMA
for (i = 0; i < NVMA; ++i) {
if (p->vma[i].addr && addr >= p->vma[i].addr
&& addr + len <= p->vma[i].addr + p->vma[i].len) {
vma = &p->vma[i];
break;
}
}
if (!vma) {
return -1;
}
if (len == 0) {
return 0;
}
if ((vma->flags & MAP_SHARED)) {
// the max size once can write to the disk
maxsz = ((MAXOPBLOCKS - 1 - 1 - 2) / 2) * BSIZE;
for (va = addr; va < addr + len; va += PGSIZE) {
if (uvmgetdirty(p->pagetable, va) == 0) {
continue;
}
// only write the dirty page back to the mapped file
n = min(PGSIZE, addr + len - va);
for (i = 0; i < n; i += n1) {
n1 = min(maxsz, n - i);
begin_op();
ilock(vma->f->ip);
if (writei(vma->f->ip, 1, va + i, va - vma->addr + vma->offset + i, n1) != n1) {
iunlock(vma->f->ip);
end_op();
return -1;
}
iunlock(vma->f->ip);
end_op();
}
}
}
uvmunmap(p->pagetable, addr, (len - 1) / PGSIZE + 1, 1);
// update the vma
if (addr == vma->addr && len == vma->len) {
vma->addr = 0;
vma->len = 0;
vma->offset = 0;
vma->flags = 0;
vma->prot = 0;
fileclose(vma->f);
vma->f = 0;
} else if (addr == vma->addr) {
vma->addr += len;
vma->offset += len;
vma->len -= len;
} else if (addr + len == vma->addr + vma->len) {
vma->len -= len;
} else {
panic("unexpected munmap");
}
return 0;
}
6. 脏页标志位设置
正如前文所述, 在 munmap 系统调用将映射内存中修改的内容写回文件时, 只考虑将已经修改的部分, 也就是脏页写回文件. 这样实现有两个好处, 一方面可以减少写回的数据, 对于 MAP_SHARED 以及可写的文件, 并不将所有内容都回写, 而是只将修改的部分回写; 另一方面, 由于文件映射内存是 Lazy allocation, 脏页因为进行了修改因此一定分配了内存, 因而在取消映射时无需考虑当前页面是否真正被分配.
在 xv6 中, 脏页可以通过 PTE 的脏页标志位 PTE_D 进行标识, 但是 xv6 本身并未对该部分进行实现. 因此此处笔者对该部分进行了简单的实现, 只考虑了文件映射内存页面的脏页标志位设置.
- 首先是在
kernel/riscv.h中定义了脏页标志位PTE_D
#define PTE_D (1L << 7) // dirty flag - lab10
- 接下来再
kernel/vm.c中定义了uvmgetdirty()以及uvmsetdirtywrite()两个函数. 前者用于读取脏页标志位, 后者用于写入脏页标志位和写标志位(因为两个标志位是同时更新的). 因为返回 PTE 的walk()是内部函数, 所有此处选择了定义这两个函数专门用于脏页标志位的相关读写.
// get the dirty flag of the va's PTE - lab10
int uvmgetdirty(pagetable_t pagetable, uint64 va) {
pte_t *pte = walk(pagetable, va, 0);
if(pte == 0) {
return 0;
}
return (*pte & PTE_D);
}
// set the dirty flag and write flag of the va's PTE - lab10
int uvmsetdirtywrite(pagetable_t pagetable, uint64 va) {
pte_t *pte = walk(pagetable, va, 0);
if(pte == 0) {
return -1;
}
*pte |= PTE_D | PTE_W;
return 0;
}
- 接下来就是关于如何设置脏页标志位. 思路也比较简单, 和 COW 机制有些类似, 即利用 page fault 进行脏页标志位的设置. 对于脏页, 即有修改的页面, 其页面权限一定是可写的, 因此考虑在第一次写页面时通过 trap 处理对页面的 PTE 增加脏页标志位. 主要有两种情景:
一种是对未映射的可写页面进行写操作, 根据前文内容, 此时会通过 trap 进行物理页的分配, 即 Lazy allocation. 而由于触发本次 page fault 的是写操作, 因此后续指令一定会对该页面的内容进行修改, 因此即可添加PTE_D脏页标志位.
另一种则是对未映射的可写页面进行读操作或执行操作, 此时同样会进行物理页的分配, 但虽然该页面可写, 但是此时是读操作, 并未修改页面的内容, 因此此时不能添加PTE_D标志位, 需要后续写操作时再进行添加. 于是在此时, 并不设置 PTE 的写标志位PTE_W, 这样页面当前是不可写的, 若后续对页面写操作便会再次触发 page fault, 此时再添加写标志位和脏页标志位.
具体的代码在上述步骤 #4 的kernel/trap.c的usertrap()中. 上文提到的读写执行操作, 可以通过r_scause()的返回值进行区分; 而步骤 #4 中找到对应 VMA 结构体后的代码if (r_scause() == 15 && (vma->prot & PROT_WRITE) && walkaddr(p->pagetable, va))即用于区分上述两种情况,r_scause()为 15 即 Store Page fault, 写操作, 此时 VMA 中记录的映射内存需要同样可写, 且walkaddr()返回非 0 值表明已经对该页面分配了内存. 这便是用于上述的第二种情况再次触发 page fault 时进行判断.else子句中则是步骤 #4 描述的页面分配过程, 而其中通过代码if (r_scause() == 15 && (vma->prot & PROT_WRITE))进行脏页标志位和写标志位的设置, 对应上述的第一种情况. - 在
usertrap()中完成了脏页标志位的设置, 在后续munmap()便可以通过调用uvmgetdirty()来确定页面是否被修改.
7. 修改 exit 和 fork 系统调用
上述内容完成了基本的 mmap 和 munmap 系统调用的部分. 最后需要对 exit 和 fork 两个系统调用进行修改, 添加对进程文件映射内存及 VMA 数组的处理.
- 修改
kernel/proc.c中的exit()函数.
在进程退出时, 需要像munmap()一样对文件映射部分内存进行取消映射. 因此添加的代码与munmap()中部分基本系统, 区别在于需要遍历 VMA 数组对所有文件映射内存进行取消映射, 而且是整个部分取消.
void
exit(int status)
{
// ...
if(p == initproc)
panic("init exiting");
// unmap the mapped memory - lab10
for (i = 0; i < NVMA; ++i) {
if (p->vma[i].addr == 0) {
continue;
}
vma = &p->vma[i];
if ((vma->flags & MAP_SHARED)) {
for (va = vma->addr; va < vma->addr + vma->len; va += PGSIZE) {
if (uvmgetdirty(p->pagetable, va) == 0) {
continue;
}
n = min(PGSIZE, vma->addr + vma->len - va);
for (r = 0; r < n; r += n1) {
n1 = min(maxsz, n - i);
begin_op();
ilock(vma->f->ip);
if (writei(vma->f->ip, 1, va + i, va - vma->addr + vma->offset + i, n1) != n1) {
iunlock(vma->f->ip);
end_op();
panic("exit: writei failed");
}
iunlock(vma->f->ip);
end_op();
}
}
}
uvmunmap(p->pagetable, vma->addr, (vma->len - 1) / PGSIZE + 1, 1);
vma->addr = 0;
vma->len = 0;
vma->offset = 0;
vma->flags = 0;
vma->offset = 0;
fileclose(vma->f);
vma->f = 0;
}
// Close all open files.
for(int fd = 0; fd < NOFILE; fd++){
if(p->ofile[fd]){
struct file *f = p->ofile[fd];
fileclose(f);
p->ofile[fd] = 0;
}
}
// ...
}
- 修改
kernel/proc.c中的fork()函数.
在使用fork()创建子进程时, 需要将父进程的 VMA 结构体进行拷贝, 从而获得相同的文件映射内存. 由于文件映射内存使用了 Lazy allocation, 所以此时的处理可以比较简单, 直接对父进程的 VMA 数组进行拷贝即可, 当子进程使用文件映射内存时则会通过 page fault 进行页面分配.
当然, 此处可以进行优化, 采用 COW 机制让父子进程指向相同文件映射物理页面, 对于不可写的文件映射内存会十分方便, 且可写的内存则通过 COW 机制重新进行更新. 此处笔者并未进行优化.
int
fork(void)
{
// ...
// increment reference counts on open file descriptors.
for(i = 0; i < NOFILE; i++)
if(p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
// copy all of VMA - lab10
for (i = 0; i < NVMA; ++i) {
if (p->vma[i].addr) {
np->vma[i] = p->vma[i];
filedup(np->vma[i].f);
}
}
safestrcpy(np->name, p->name, sizeof(p->name));
// ...
}
遇到问题
- 在 xv6 中执行
mmaptest, 其中 fork_test 出现如下图所示错误:
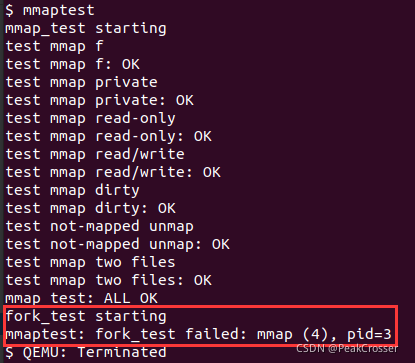
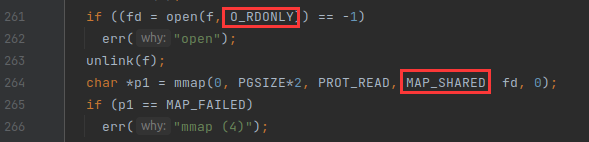
解决: 根据 mmap(4) 可以定位到user/mmaptest.c中错误发生的位置, 原因是mmap()返回失败. 通过分析发现此处是对一个只读的文件采用MAP_SHARED形式进行映射. 笔者最初仅判断MAP_SHARED标志位以及文件的读写情况来进行决定mmap是否能继续执行, 但对于没有PROT_WRITE权限的文件映射, 虽然有MAP_SHARED标志位, 但并不会写入文件中, 因此应该同样可以继续执行, 因此正确的做法应再添加对映射权限prot & PROT_WRITE的检查, 具体代码见上文sys_mmap()实现.

测试
- 在 xv6 中执行
mmaptest测试:

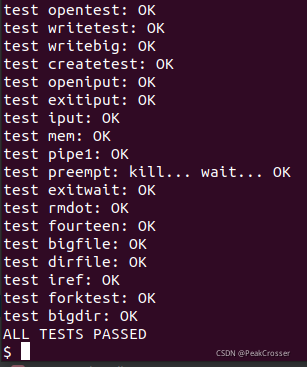
- 在 xv6 中执行
usertests测试:
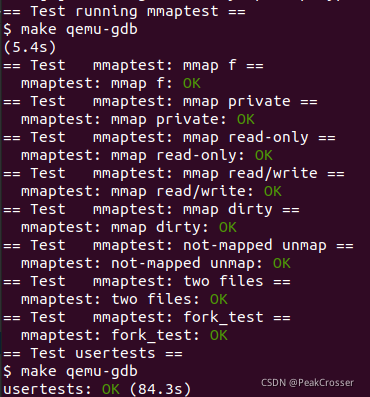
- 执行
make grade测试:

















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









