







XRP: In-Kernel Storage Functions with eBPF
XRP: 利用 eBPF 的核内存储函数 [Paper] [Slides] [Code]
OSDI’22
摘要
提出了 XRP, 一个允许应用程序从 NVMe 驱动程序中的 eBPF 钩子(hook)执行用户定义的存储函数(例如索引查找或聚合)的框架, 可以安全地绕过大部分内核的存储栈.
1 介绍
随着新的高性能存储技术的兴起, 新的 NVMe 存储设备现在可以实现很高的性能, 内核存储栈成为延迟和开销的主要来源.
现有的解决方案偏激进, 需要侵入式应用程序级的更改或新的硬件.
本文旨在寻求一种易于部署的机制, 可以提供对新兴快速存储设备的快速访问, 而使用现有内核和文件系统时, 无需专门的硬件或对应用程序进行重大更改.
依靠 BPF (Berkeley Packet Filter): 允许应用程序将简单的函数 offload (卸载) 到 Linux 内核, 可消除内核-用户态跨越和上下文切换的开销; 同时操作系统支持, 可以保证隔离性和利用率.
- Def: I/O 的重提交(resubmission): 需要与其他并发应用程序级操作同步或需要多个函数调用来遍历大型磁盘数据结构的工作负载模式.
使用 BPF 的挑战: 重提交所需的状态在较低层不可用.
本文设计实现了 XRP (eXpress Resubmission Path), 一个使用 Linux eBPF 的高性能存储数据路径.
- XPR 通过在 NVMe 驱动的中断处理程序中使用钩子来绕过内核存储栈, 以最大提高性能.
- XRP 的关键挑战是底层 NVMe 驱动程序缺乏高层提供的上下文.
- 只聚焦 XRP 于一个文件内的操作和在磁盘上具有固定布局的数据结构, 从而 NVMe 驱动程序只需最少量的可由文件系统传递的文件系统映射状态(称为元数据摘要), 使得可以安全执行 I/O 重提交.
本文题提出了 XPR 在 Linux 上的设计和实现, 支持 ext4; 并用 XPR 扩充了 BPF-KV 和 WiredTiger 两个键值存储.
文章贡献:
- 新的数据路径. XRP 是第一个支持使用 BPF 将存储函数 offload 到内核的数据路径.
- 性能. 与普通系统调用相比, XRP 将 B-树查找的吞吐量提高了 2.5 倍.
- 利用率. XRP 提供接近内核旁路的延迟, 但允许内核被相同的线程和进程高效地共享.
- 可扩展性. XRP 支持不同的存储用例, 包括不同的数据结构和存储操作(例如, 索引遍历、范围查询、聚合).
2 背景和动机
2.1 软件现在是存储的瓶颈
访问新的 NVMe 存储设备时, 内核存储栈正成为主要的性能瓶颈.

时间都去哪儿了? 总软件开销占平均延迟的 48.6%.
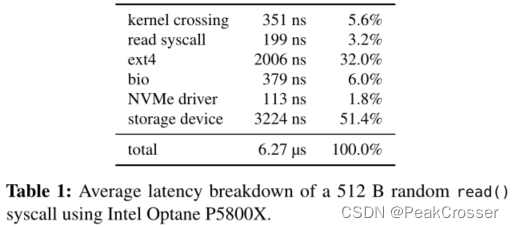
为什么不直接绕过内核? 安全问题(用户有对设备的完全访问权限) 和利用率问题(必须轮询设备完成队列, 内核不能共享, 多个轮询线程带来 CPU 争用).
2.2 BPF 入门
BPF (Berkeley Packet Filter) 是一个接口, 允许用户 offload 一个简单的函数由内核执行. Linux 的 BPF 框架称为 eBPF (extended BPF, 扩展BPF).
eBPF 函数在安装时由内核验证以确保安全, 验证后就可以正常被调用.
2.3 BPF 的潜在效益
BPF 可以避免内核空间和用户空间之间的数据移动,当逻辑查找需要一系列会生成应用程序不直接需要的中间数据的"辅助" I/O 请求时.
在辅助 I/O 工作负载中重提交(分派) I/O 的 BPF 函数可以放置在内核的任何层 (如系统调用层、NVMe 驱动层).
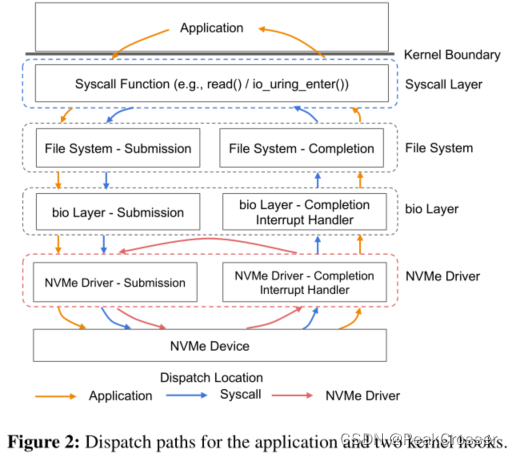
最佳案例加速. XRP 的重提交钩子应驻留在 NVMe 驱动程序中.
io_uring 如何? io_uring 允许进程提交批量异步 I/O 请求, 但每个 I/O 仍会带来完整的存储栈开销. BPF I/O 重提交很大程度上是对 io_uring 的补充: io_uring 提交一批 I/O 触发内核中 BPF 管理的不同 I/O 链.
BPF 可以使传统的读取和 io_uring 系统调用受益.
3 设计挑战和原则
从缺少文件系统层上下文的 NVMe 中断处理程序中执行重提交的两大挑战:
挑战 1: 地址转换和安全. NVMe 驱动程序无法访问文件系统元数据. BPF 函数可以访问设备上的任何块, 即使是属于用户无访问权限的文件.
挑战2: 并发和缓存. 文件系统发出的写入只会反映在页面缓存中, XRP 不可见. 与读取请求同时发出的修改数据结构布局的写入可能导致 XRP 意外获取错误数据. 可以通过加锁解决, 但在 NVMe 中断处理程序中访问锁开销过大.
观察: 大多数磁盘上的数据结构是稳定的. 许多存储引擎的文件保持相对稳定: 有些数据结构不会就地修改磁盘上的存储结构; 文件区段(extent)长时间保持稳定. 使得可以在 NVMe 驱动中缓存文件系统元数据.
设计原则:
- 一次一个文件: XRP 仅在单个文件上发布链式重提交.
- 稳定的数据结构: XRP 以布局 (即指针) 长时间内保持不变的数据结构为目标.
- 用户管理的缓存: XRP 没有页面缓存的接口.
- 慢路径回退: XRP 尽力而为, 失败时重试或回退.
4 XBR 的设计与实现
4.1 重提交逻辑
XRP 的核心: 用重提交逻辑扩充 NVMe 中断处理程序.
重提交逻辑组成: BPF 钩子; 文件系统转换步骤; 在新物理偏移处构造和重提交下一个 NVMe 请求.
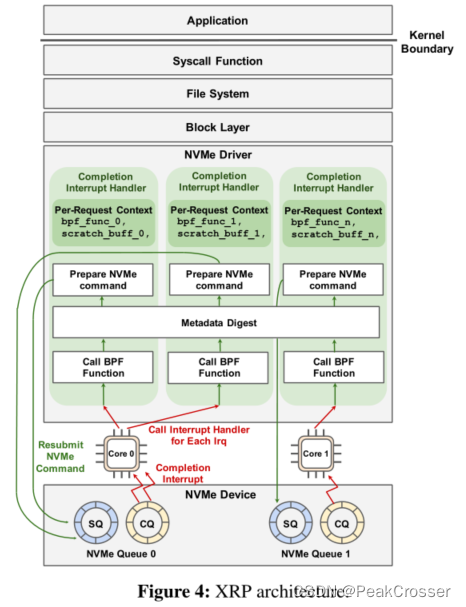
重提交逻辑:
- NVMe 请求完成时, 设备生成中断, 使内核上下文切换到中断处理程序.
- 对于中断上下文中完成的每个 NVMe 请求, XRP 调用其关联的 BPF 函数.
- 调用 BPF 函数后, XRP 调用元数据摘要, 使其能够转换下一次重提交的逻辑地址.
- XRP 通过在 NVMe 请求中设置相应字段来准备下一个 NVMe 命令重提交, 并将请求附加到该核心的 NVMe 提交队列 (SQ) 中.
对于特定的 NVMe 请求, 根据 NVMe 请求中注册的特定 BPF 函数确定的后续完成所需次数, 调用重提交逻辑.
BPF 函数的上下文是每个请求的, 而元数据摘要在所有内核中断处理程序的所有调用之间共享. 对元数据摘要的安全并发访问依赖于读-拷贝-更新(read-copy-update, RCU).
4.1.1 BPF 钩子
XRP 引入了一种新的 BPF 类型:BPF_PROG_TYPE_XRP, 与其签名匹配的 BPF 函数均可被钩子调用.

BPF_PROG_TYPE_XRP 程序需要上下文 struct bpf_xrp:
- 被 BPF 调用者检查或修改的字段:
data: 缓存从磁盘读取的数据done: 布尔值, 通知重提交逻辑返回给用户或继续重提交 I/O 请求next_addr: 逻辑地址数组, 指示下个逻辑地址以供重提交 (数组以支持带有扇出的数据结构)size: 逻辑地址对应大小数组
- BFP 函数私有字段:
scratch: 对用户和BPF函数私有的暂存空间.
4.1.2 BPF 校验器
BPF 校验器通过跟踪存储在每个寄存器中的值的语义来确保内存安全.
校验器定义了各种指针类型:
SCALAR_TYPE: 无法解引用的值PTR_TO_CTX: 指向 BPF 上下文的指针, 只能使用常量偏移量解引用PTR_TO_MEM: 指向固定大小内存区域的指针, 支持使用可变偏移量解引用
每个类型定义了回调函数 is_valid_access(): 对上下文访问执行其他检查, 并返回上下文字段的值类型.
4.1.3 元数据摘要
元数据摘要: XRP 公开的在文件系统和中断处理程序之间共享逻辑-到-物理(logic-to-physical)块映射的接口.
元数据摘要组成:
- 更新函数: 当逻辑-到-物理映射更新时, 在文件系统中被调用
- 查找函数: 在中断处理程序中被调用, 返回给定偏移量和长度的映射

4.1.4 重提交 NVMe 请求
查找物理块偏移后, XRP 准备下一个 NVMe 请求, 重用刚完成请求的现有 NVMe 请求结构体 (即 struct nvme_command), 只需将现有 NVMe 请求的物理扇区和块地址更新为从映射查找中导出的新偏移量.
4.2 同步限制
BPF 目前只支持一个有限的自旋锁用于同步.
校验器只允许 BPF 程序一次获取一个锁, 且必须在返回之前释放.
用户空间不能直接访问 BPF 自旋锁, 必须通过 bpf() 系统调用读写锁保护的结构, 在操作期间会持有锁.
用户可以使用 BPF 原子操作实现自定义自旋锁.
4.3 与 Linux 调度器的交互
进程调度器. 当多个进程共享同一内核时, 即使所有 I/O 均从用户空间发出, 微秒级存储设备也会干扰 Linux 的 CFS (Completely Fair Scheduler, 完全公平调度器).
共享同一内核时, I/O 密集型进程会导致计算密集型进程 CPU 饥饿, XRP 通过生成中断链加剧了该问题.
I/O调度器. XRP 绕过了位于块层的 Linux 的 I/O 调度器.
5 案例研究
XRP 应用程序接口:
bpf_prog_load: 加载BPF_PROG_TYPE_XRP类型的 BPF 函数并将其 offload 到驱动程序中read_xrp: 将特定 BPF 函数应用于读取请求

应用程序可以使用 XRP 加载多个 BPF 函数.
本文提出了两个关于如何修改应用程序以使用 XRP 的案例研究.
5.1 BPF-KV
BPF-KV: 简单的键值存储, 与其他基准线对比来评估 XRP.
- 被设计为存储大量小对象
- 使用 B+-树索引来查找对象位置
- 缓存: 为索引块和对象实现了用户空间 DRAM 缓存, 维护最热门键值对的最近最少使用 (least recent use, LRU) 对象缓存
- 范围查询: 支持返回可变数量的对象的范围查询
- 聚合: 支持聚合操作, 如
SUM、MAX和MIN
5.2 WiredTiger
WiredTiger: 流行的键值存储, 作为 MongoDB 的默认后端, 用于实际生产.
- 提供使用 LSM 树的选项, 其中数据被划分为不同的级别; 每个级别包含一个使用 B-树索引的文件
- 缓存: 为其 B-树内部页面和叶子页面维护一个最近最少使用的 (LRU) 缓存
6 评估
回答问题:
- 使用 BPF 进行存储的开销是多少 (§6.1)?
- XRP 如何扩展到多个线程 (§6.2)?
- XRP 可以支持哪些类型的操作 (§6.3)?
- XRP 能否加速真实世界的键值存储 (§6.4)?
实验设置:
- 一台 6 核 i5-8500 3GHz 服务器, 16 GB 内存
- 使用 Ubuntu 20.04 和带有 Intel Optane 5800X 原型的 Linux 5.12.0
- 使用 O_DIRECT, 关闭超线程, 禁用处理器低功耗模式(C-states)和睿频加速(Turbo Boost), 使用最大性能调节器, 并启用 KPTI
- 使用 WiredTiger 4.4.0
基准线:
(a) XRP
(b) SPDK (一种流行的内核旁路库)
(c) 标准 read() 系统调用
(d) 标准 io_uring 系统调用
6.1 BPF-KV
延迟:
- 实验: 执行了一百万次读取操作, 键名随机抽取, 概率均匀, 禁用数据对象和索引节点的缓存.
- 结果:
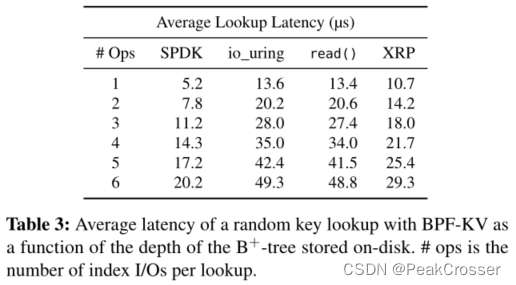
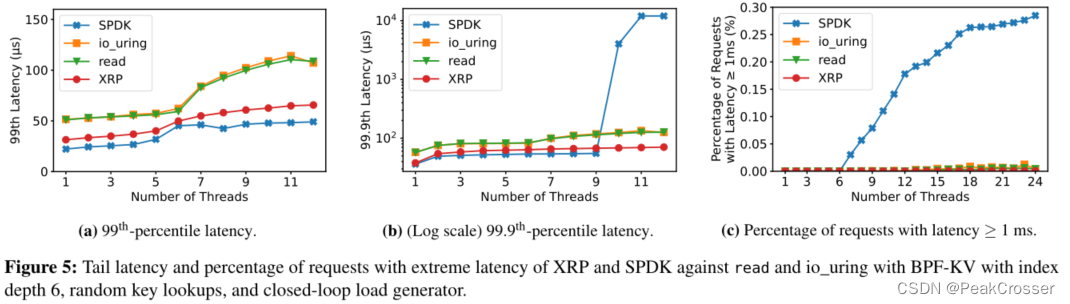
XRP 比read()改善了延迟
每增加一次 I/O 操作就增加约 3.5-3.9 µs, 这与设备的延迟接近, 实现了接近最佳的延迟
在 6 级索引的情况下, XRP 仅比 SPDK 慢 45%, 但 XRP 不重排序轮询.
当使用单个线程运行时, 与read()和 io_uring 相比, XRP 将第 99 百分位延迟和 99.9 百分位等待时间减少了 30%.
吞吐量:
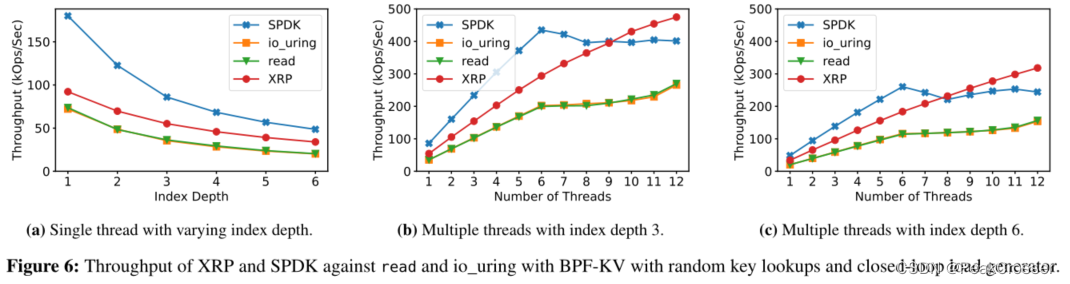
随着索引深度的增加, XRP 的加速比标准系统调用更高.
6.2 线程扩展
XRP 如何作为一些线程的函数进行扩展, 并将其与 SPDK.
- 实验: 运行了一个开环实验, 其中负载量与 Intel 设备的最大带宽相匹配, 使用 6 个磁盘索引级别来比较 XRP (与 io_uring 集成) 与 SPDK (BPF-KV) 的吞吐量.
- 结果:
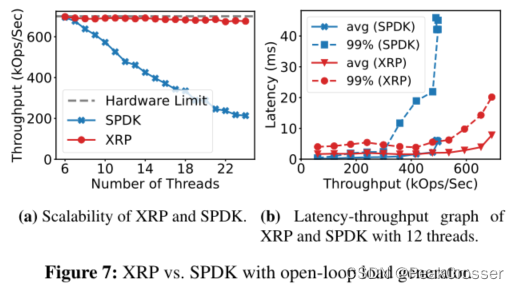
- 当使用 6 个工作线程 (机器上的 CPU 核数) 时, SPDK 和 XRP 都可实现接近硬件极限的吞吐量
- 一旦线程数超过 CPU 内核数, SPDK 的吞吐量就会稳步下降, 而 XRP 仍提供稳定吞吐量
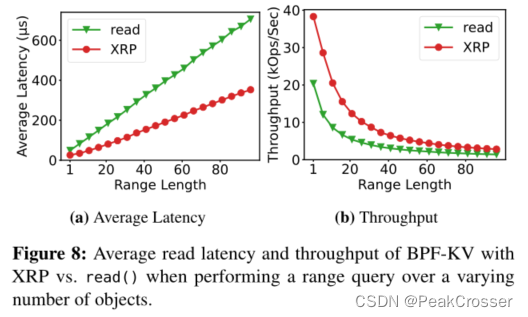
6.3 范围查询
- 实验: 比较使用 XRP 运行范围查询与使用
read()系统调用执行查询的平均延迟和吞吐量. 索引深度为 6. - 结果: XRP 范围查询只增加了微不足道的开销, 性能加速保持相对恒定.
6.4 WiredTiger
评估了 YCSB 上使用和不使用 XRP 的 WiredTiger 的性能
- 实验: 运行不同的 YCSB 工作负载:
YCSB A、B、C 和 E 使用 10M 操作, D 使用 50M 操作, E 使用 3M 操作.
基准线 WiredTiger 使用pread()读取 B-数页面, 而带有 XRP 的 WiredTiger 使用read_xrp().
用 10 亿个键值对填充数据库, 并将键值的大小设置为 16 B. 数据库的总大小为 46 GB.
WiredTiger 驱逐线程的数量设置为 2.
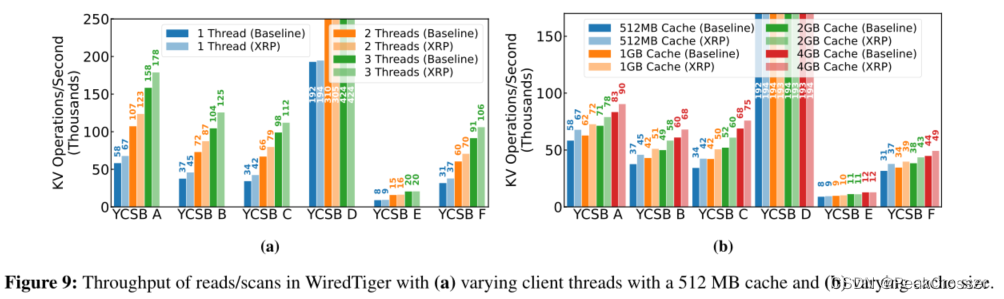
吞吐量:
XRP 可以将大多数工作负载的速度提高 1.25 倍.
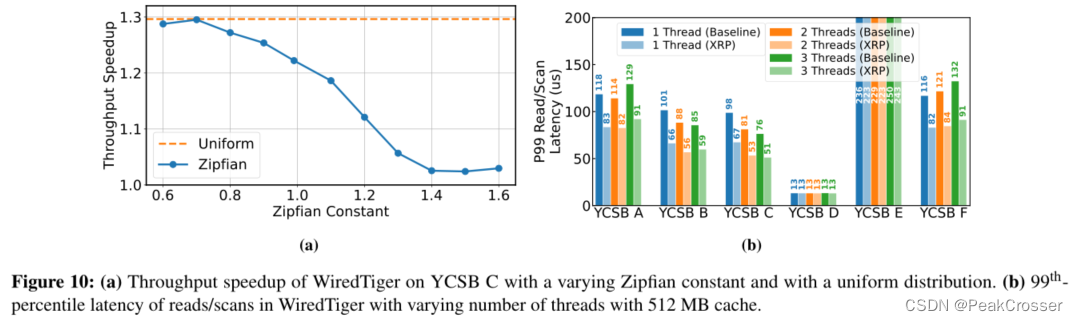
当 Zipfian 常数变大时, XRP 的效益会降低.
尾端延迟:
XRP 可以将第 99 百分位延迟降低 40%.

















 7322
7322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









