






文章目录
YOLOv5代码本地训练模型
本文记录自己本地使用YOLOv5算法训练识别安全帽和人脸的过程,以供以后学习参考。
一、学习资源
1、B站炮哥保姆级YOLOv5本地训练模型讲解
强推:
https://www.bilibili.com/video/BV1f44y187Xg/?p=6&spm_id_from=pageDriver&vd_source=2fa09a0655d11f6cfae7287ba7e9df31
2、YOLOv5源码
https://github.com/ultralytics/yolov5/tree/v5.0
YOLOv5源码下载,本次所有实验都是使用YOLOv5-5.0这个版本
3、数据集的下载
YOLOv5算法采用的是VOC数据集,所以要对原始数据集进行标注处理,然后划分数据集为训练集与测试集。其中会使用labelImg工具对图像进行打标签的操作以及格式转换。
这里是已经划分好的数据集,具体的图像处理与数据集划分炮哥的博客中都有详细介绍。
炮哥 YOLOv5教程博客:https://blog.csdn.net/didiaopao/category_11321656.html?spm=1001.2014.3001.5482
数据集:
夸克网盘:https://pan.quark.cn/s/af9d304b2a00 提取码:QZUC
百度网盘:https://pan.baidu.com/s/1SKkv19bk6xwDME0KgfVGhQ 提取码:pVG2
二、算法训练流程
1、利用Anaconda安装pytorch+pycharm,安装CUDA和CUDNN
Anaconda可以便捷获取包且对包能够进行管理,包括了python和很多常见的软件库和一个包管理器conda。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易,同时对环境可以统一管理的发行版本。

pytorch是一个开源的由Facebook人工智能研究院出品的Python机器学习库,基于Torch,用于自然语言处理等应用程序,基于python的一个科学计算工具。
NVIDIA驱动:臭打游戏的驱动,提供显示功能,是驱动程序。
CUDA:英伟达出的一个【平台】。
cuDNN:也是英伟达出的,它是专门用于神经网络的加速包,CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。
2、利用labeling工具标注VOC格式的数据集以及数据集的划分
使用labeling工具可以对自己的数据集进行标注处理,然后再使用相应python脚本将比标注的xml文件转换为txt格式文件,具体流程细节炮哥博客有详细介绍这里就不多做赘述。
上述所提供的数据集已经包含了划分好的数据集,包含安全帽和人脸两种标注可以直接使用。
3、使用YOLOv5代码本地训练模型
(1)项目克隆
首先,要从github官网上克隆YOLOv5的源码,使用的是YOLOv5-5.0这个版本的源码。然后使用一款IDE打开这个项目。
(2)环境与依赖的安装
在项目中有一个requirements.txt文件,打开requirements.txt这个文件,可以看到里面有很多的依赖库和其对应的版本要求。我们打开pycharm的命令终端,在中输入如下的命令,就可以安装了。
pip install -r requirements.txt

等其全部安装完毕,所以环境与依赖即可配置完成。
(3)数据集和预训练权重的准备
炮哥博客:https://blog.csdn.net/didiaopao/article/details/120022845
这篇博客完整的讲述了如何使用labeling标注数据集以及数据集的划分。
本地YOLOv5的在本地训练如果使用随机值开始训练的话,必须花费好多轮迭代才能使得测试集的mAP值达到一个比较好的效果。 一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。YOLOv5-5.0提供了好几个版本的预训练权重文件,可以在这个网址进行下载:https://github.com/ultralytics/yolov5/releases,这里我们所以使用的是yolov5s.pt这个预权重文件。
(4)使用准备好的数据集本地训练模型
1)首先将数据集文件VOC2007放在YOLOv5-5.0这个项目的文件夹中,将与预训练权重文件yolov5s.pt放在该项目文件夹下的weights文件夹下。

2)修改数据配置文件与模型配置文件
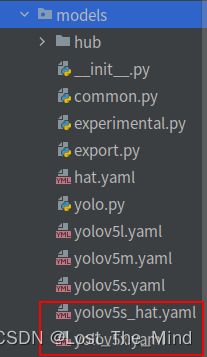
将数据文件夹data目录下的voc.yaml文件重新复制一份并重命名为hat.yaml

然后打开这个文件夹修改其中的参数,首先将箭头1中的那一行代码注释掉(我已经注释掉了),如果不注释这行代码训练的时候会报错;箭头2中需要将训练和测试的数据集的路径填上(最好要填绝对路径,有时候由目录结构的问题会莫名奇妙的报错);箭头3中需要检测的类别数,我这里是识别安全帽和人,所以这里填写2;最后箭头4中填写需要识别的类别的名字(必须是英文,否则会乱码识别不出来)。

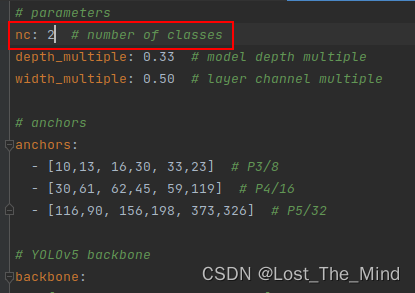
打开模型配置文件models,由于该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。同上修改data目录下的yaml文件一样,我们最好将yolov5s.yaml文件复制一份,然后将其重命名,我将其重命名为yolov5_hat.yaml。打开yolov5_hat.yaml文件只需要修改如图中的数字就好了,这里是识别两个类别。
3)训练自己的模型
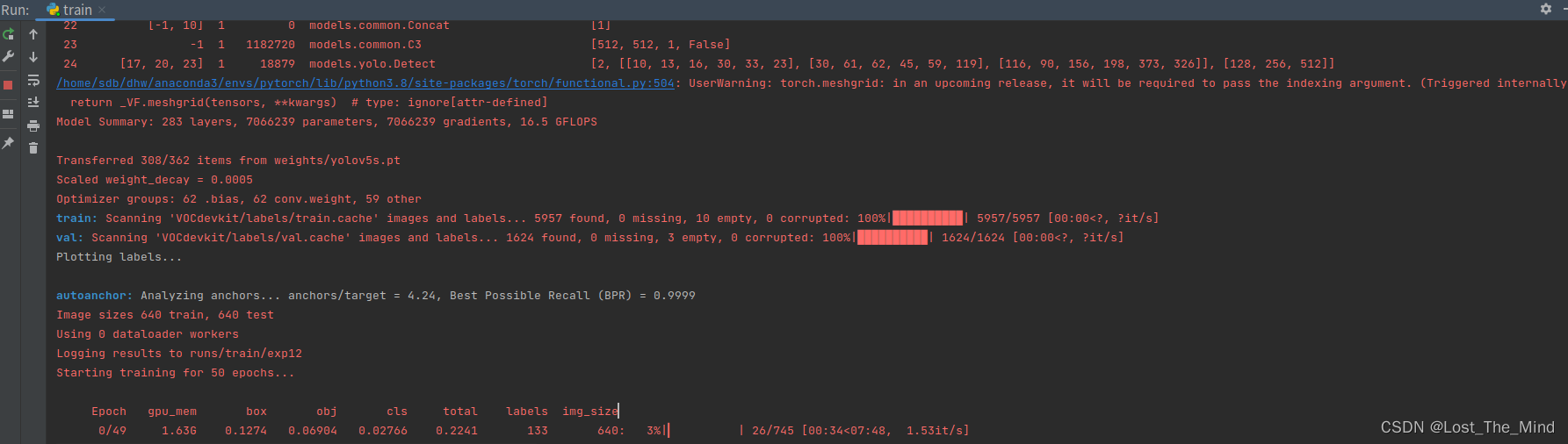
完成上述修改后我们即可开始训练模型,打开train.py文件。训练自己的模型需要修改如下几个参数就可以训练了。首先将weights权重的路径填写到对应的参数里面,然后将修好好的models模型的yolov5s.yaml文件路径填写到相应的参数里面,最后将data数据的hat.yaml文件路径填写到相对于的参数里面。这几个参数就必须要修改的参数。

下面其他参数比如:训练论次、输入图片数量、输入图片尺寸等,可以依据自身情况自行修改。然后运行train.py这个文件即可开始训练,最后训练结果保存在run这个文件夹中,best.pt为训练结果最好的权重文件,last.py为最后一轮训练的权重文件。

4)启用tensorbord查看参数
yolov5里面有写好的tensorbord函数,可以运行命令就可以调用tensorbord,然后查看tensorbord了。首先打开pycharm的命令控制终端,输入如下命令,就会出现一个网址地址,将那行网址复制下来到浏览器打开就可以看到训练的过程了。
tensorboard --logdir=runs/train

这里我们是一共训练了50轮的结果

(5)推理测试
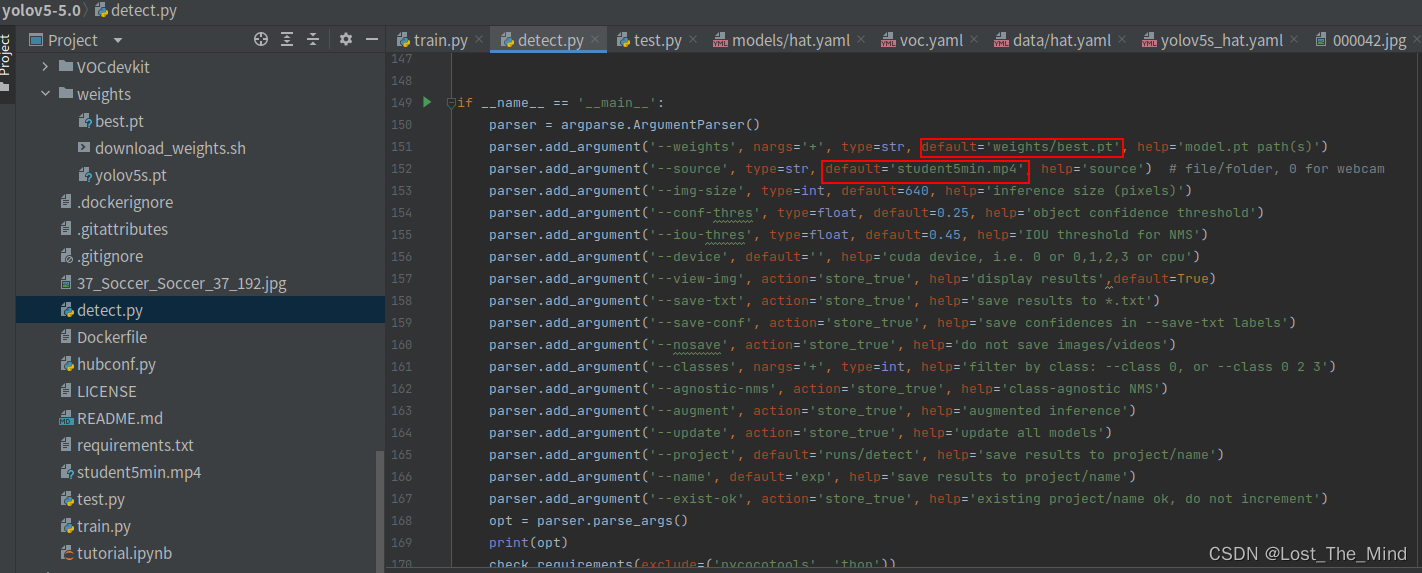
找到主目录下的detect.py文件,这里需要将刚刚训练好的最好的权重传入到推理函数中去,然后填人图像或者视频的路径就可以对图像视频进行推理了。
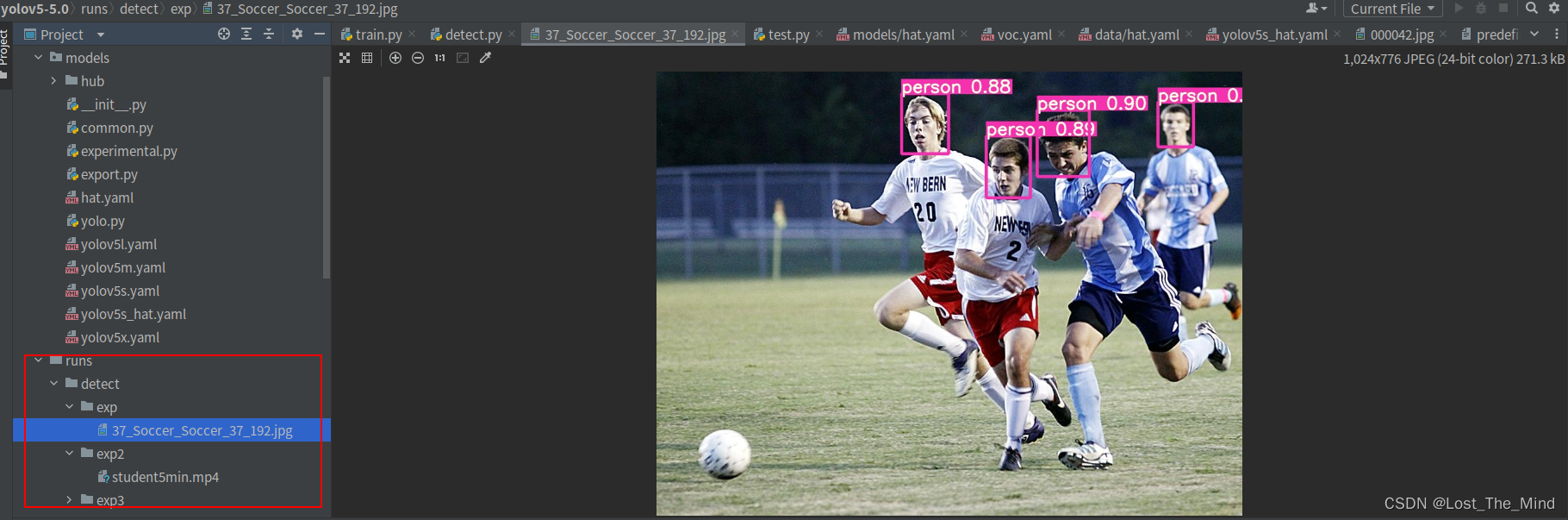
结果保存在主目录下的run文件夹下的detect文件夹中,可以看到效果还是不错的。
如果想修改保存路径,修改下图所是代码中的保存文件路径即可。

4、使用YOLOv5代码运行常见错误解决方法
这篇YOLOv5算法源码已经很广泛的使用,很多小伙伴都已经自己亲手运行过源码或者自己本地修改的代码,这里我就放了一部分关于常见代码运行问题解决办法的总结博客。
YOLOv5配置问题总结:https://blog.csdn.net/weixin_53111016/article/details/124555253
YOLOv5报错解决方法:
https://blog.csdn.net/weixin_62275996/article/details/129122554















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









