







最近在看深度学习的东西,激活函数是其中的一个环节,就从网上的一搜寻关于激活函数的介绍
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。
常用激活函数
激活函数的选择是构建神经网络过程中的重要环节,下面简要介绍常用的激活函数。
主要解决传统神经网络对非线性问题的表征弱的问题。
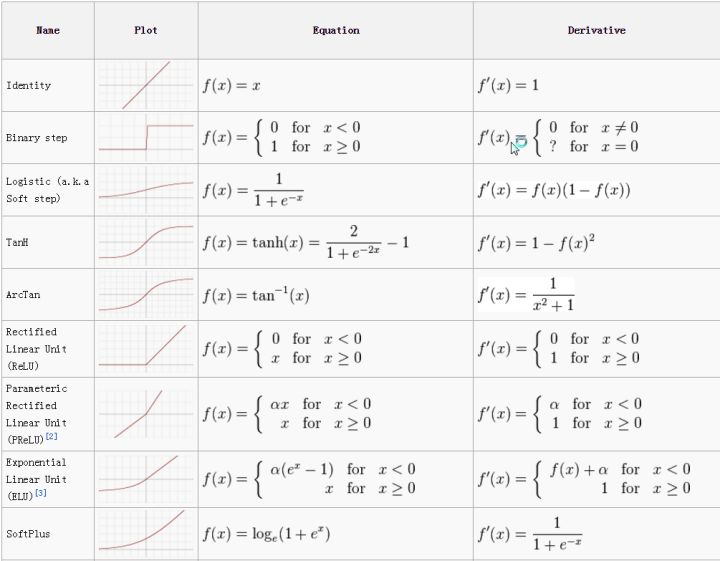

(5) 双曲正切函数
该函数的导函数:
(6)ReLu(Rectified Linear Units)函数
- Noise ReLU max(0, x+N(0, σ(x)).
该函数的导函数:
g(x)'=0或1

(7)maxout 函数


这里的W是3维的,尺寸为d*m*k,其中d表示输入层节点的个数,m表示隐含层节点的个数,k表示每个隐含层节点对应了k个”隐隐含层”节点,这k个”隐隐含层”节点都是线性输出的,而maxout的每个节点就是取这k个”隐隐含层”节点输出值中最大的那个值。因为激发函数中有了max操作,所以整个maxout网络也是一种非线性的变换。

补充:在ImageNet Classification with Deep Convolutional Neural Networks的论文中其解释了
RELU取代sigmoid 和tanh函数的原因是在求解梯度下降时RELU的速度更快,在大数集下会节省训练的时间
在这里指出sigmoid和tanh是饱和非线性函数,而RELU是非饱和非线性函数。
对于这个概念我不是很明白,有兴趣的童鞋可以去google一下,百度上是没有的。。。
20160515补充
PRELU激活函数
PReLU激活
PReLU(Parametric Rectified Linear Unit), 顾名思义:带参数的ReLU。二者的定义和区别如下图:

如果ai=0,那么PReLU退化为ReLU;如果ai是一个很小的固定值(如ai=0.01),则PReLU退化为Leaky ReLU(LReLU)。 有实验证明,与ReLU相比,LReLU对最终的结果几乎没什么影响。
PReLU的几点说明
(1) PReLU只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同channels使用相同的ai时,参数就更少了。
(2) BP更新ai时,采用的是带动量的更新方式,如下图:
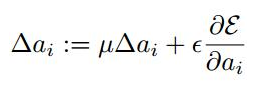
上式的两个系数分别是动量和学习率。
需要特别注意的是:更新ai时不施加权重衰减(L2正则化),因为这会把ai很大程度上push到0。事实上,即使不加正则化,试验中ai也很少有超过1的。
(3) 整个论文,ai被初始化为0.25。
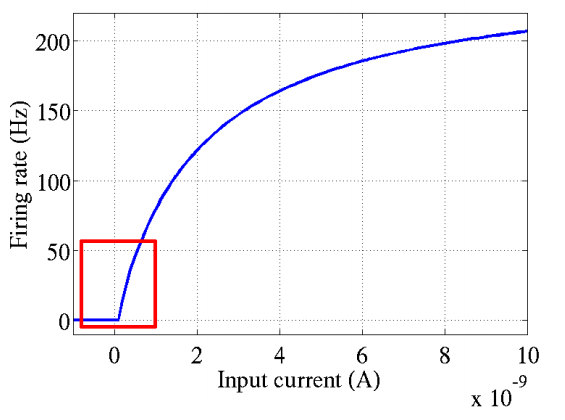
下图是生物学家研究出的人类大脑的信号变化。跟relu的方式相近似。















 2716
2716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









