







来源:数学建模清风学习内容整理
文章目录
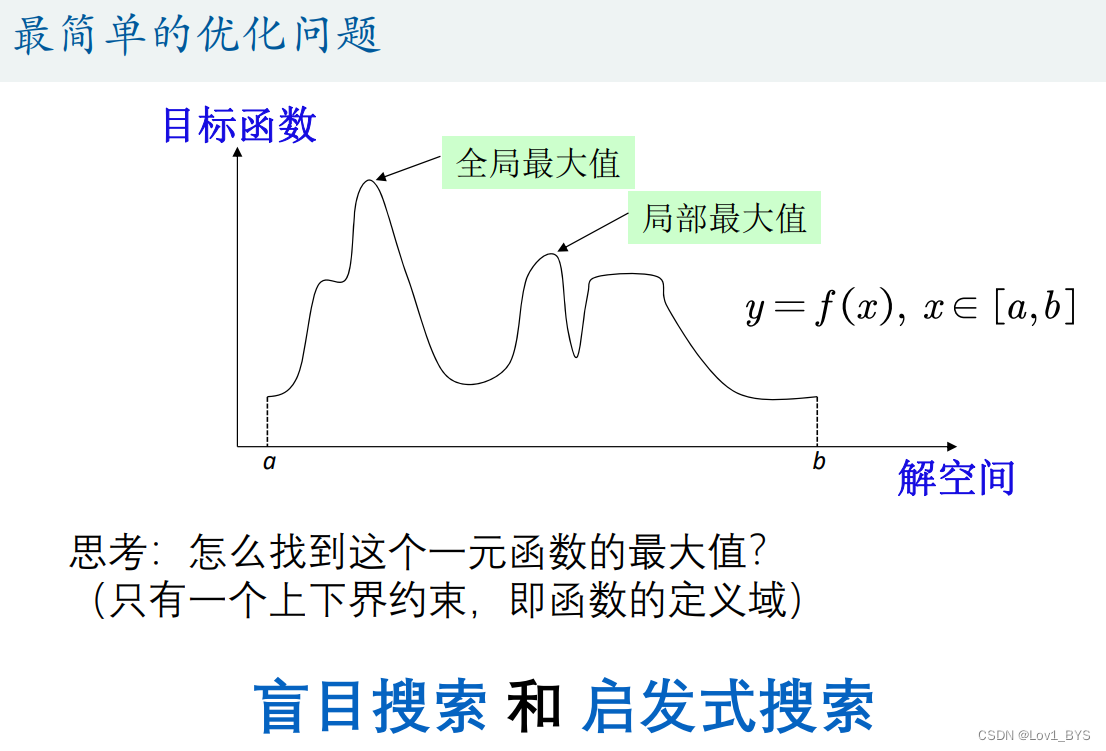
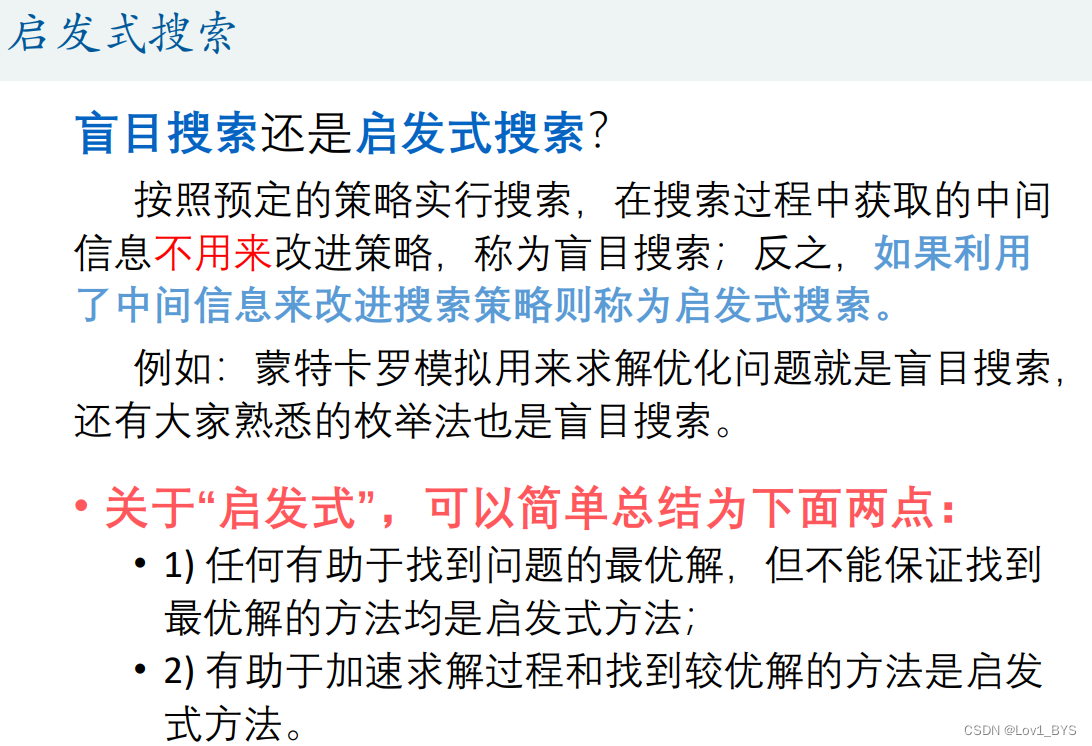
什么是粒子群算法?
启发式算法(智能优化算法)



粒子群算法的基本概念


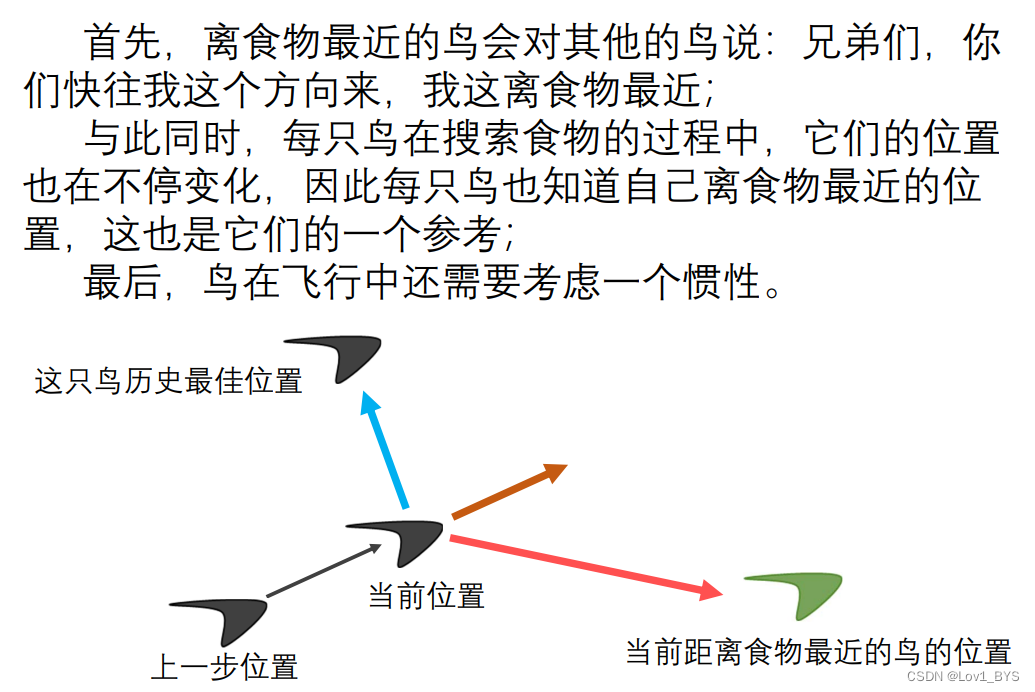
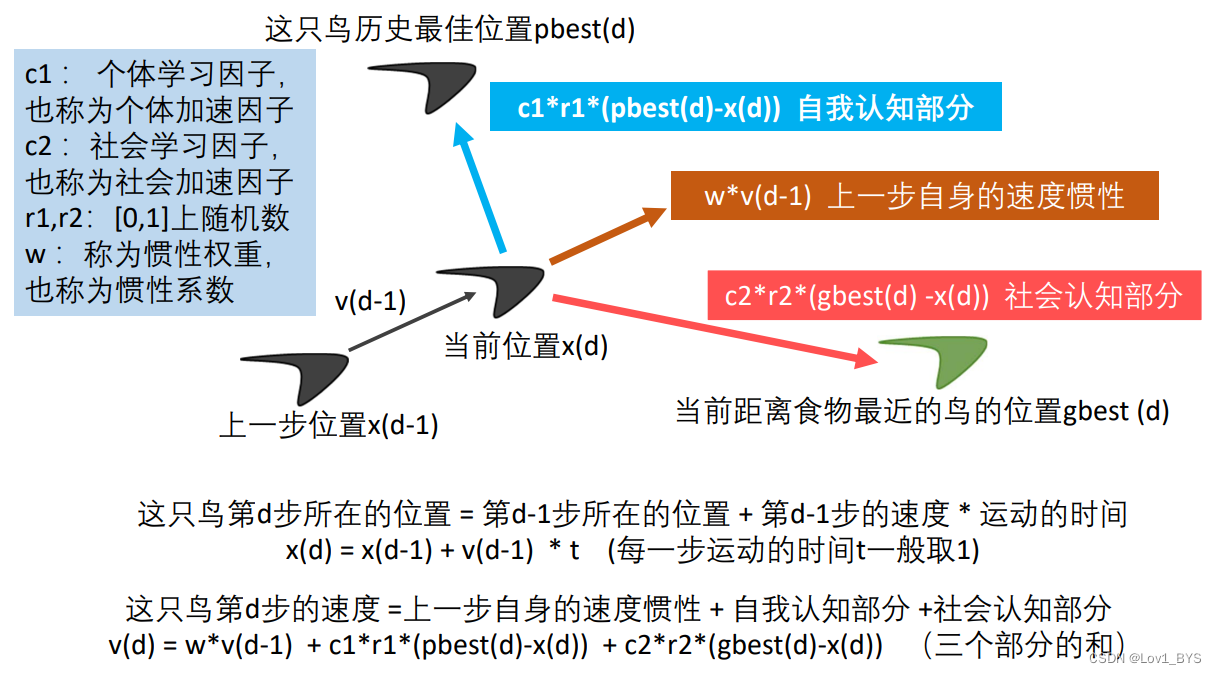

PSO数学模型及符号
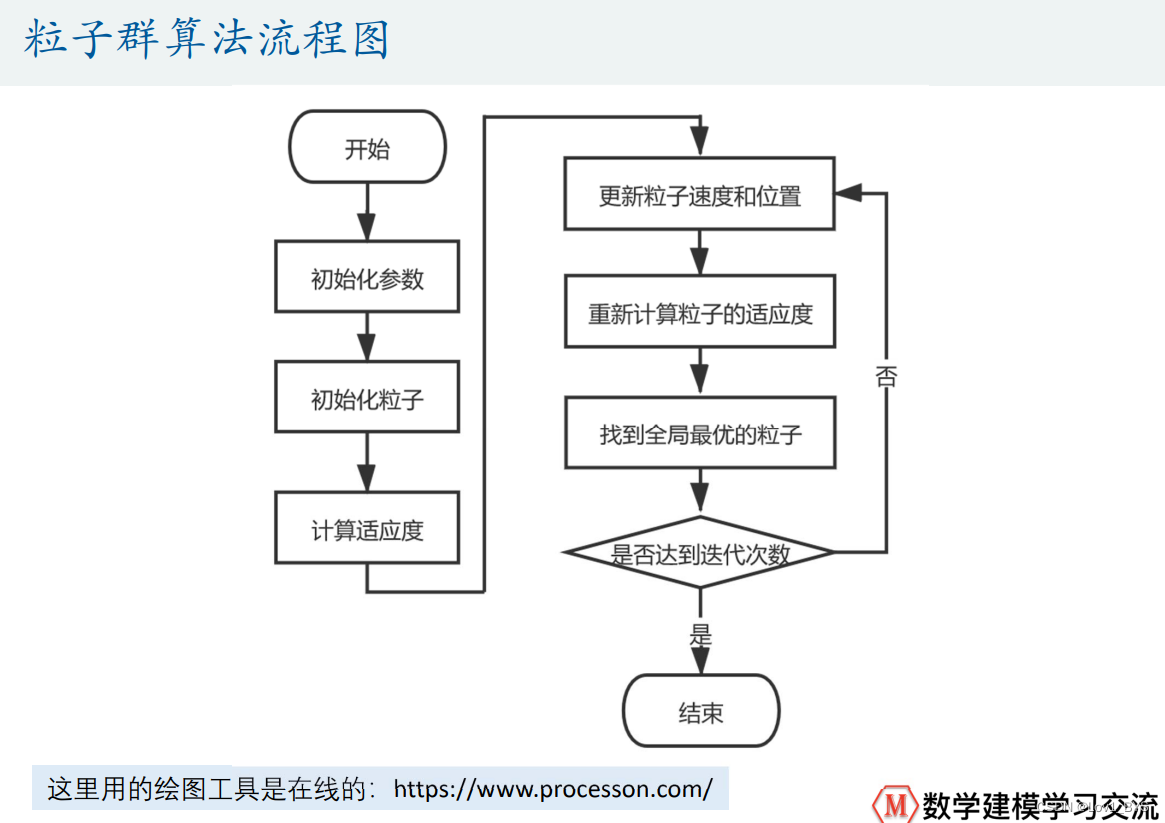




怎么用粒子群算法:
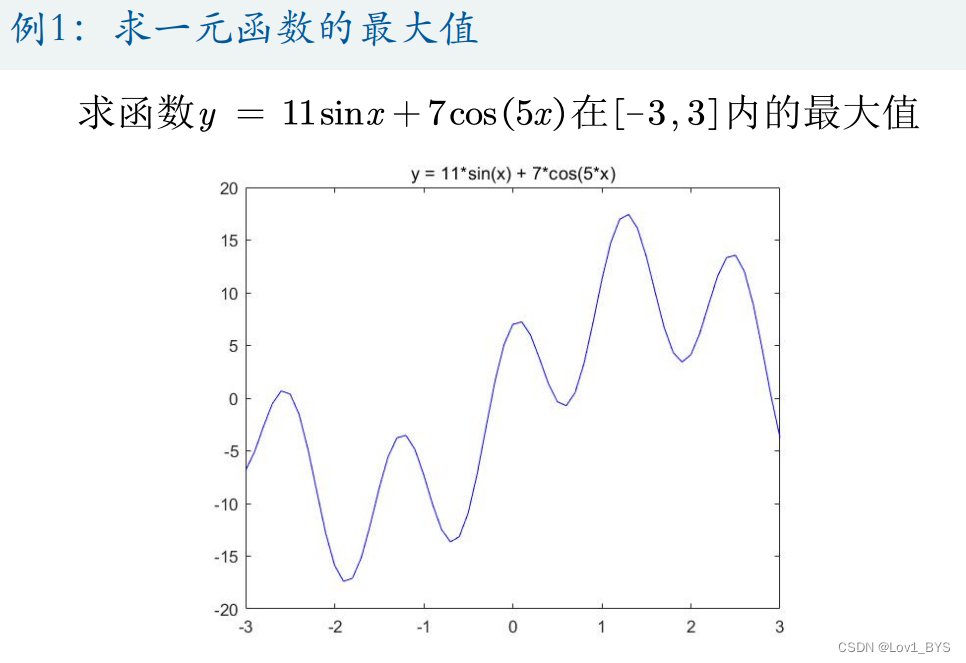
例一:求一元函数的最大值
- 可以用非线性规划求解

%主函数部分:
% 如果调用fmincon函数,则需要把求最大值的目标函数添加负号改为求最小值
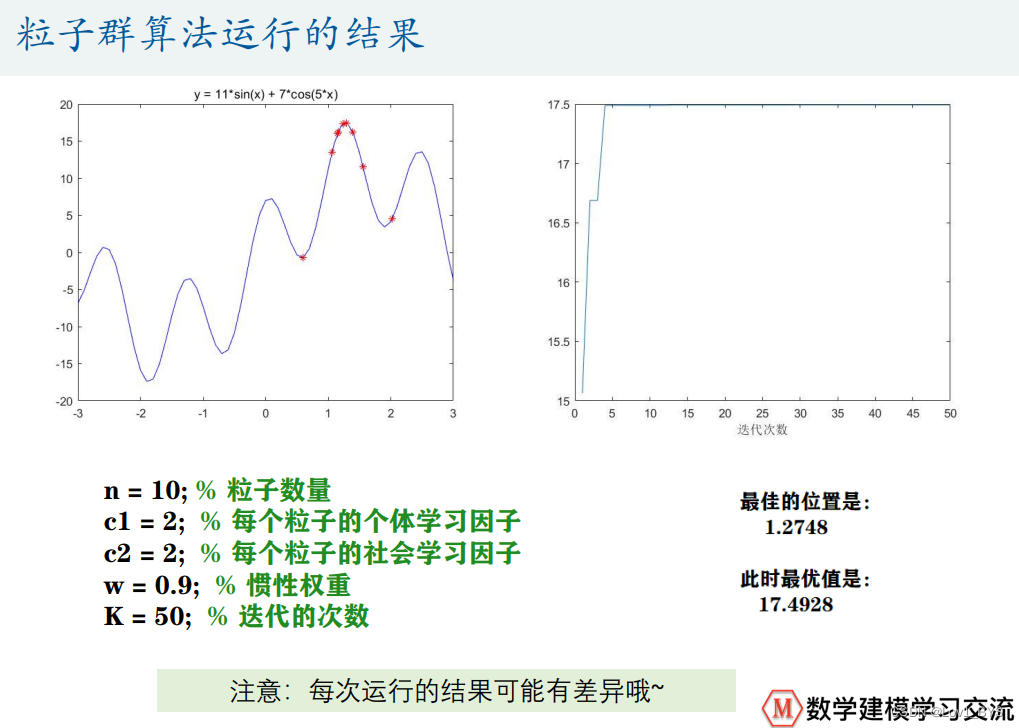
%% 求解函数y = 11*sin(x) + 7*cos(5*x)在[-3,3]内的最大值
x0 = 0;
A=[]; b=[];
Aeq=[];beq=[];
x_lb = -3; % x的下界
x_ub = 3; % x的上界
[x,fval] = fmincon(@Obj_fun1,x0,A,b,Aeq,beq,x_lb,x_ub)
fval = -fval
% x = 1.2750, y = 17.4928
% 如果把初始值改为x0 = 2,结果会是什么?
%调用函数部分:需单独保存为,m文件
function y = Obj_fun1(x)
y = 11*sin(x) + 7*cos(5*x);
% y = -(11*sin(x) + 7*cos(5*x)); % 如果调用fmincon函数,则需要添加负号改为求最小值
end
- 使用非线性规划求解时,给出的初始值很重要,但粒子群不用给出初始值:
% 粒子群算法PSO: 求解函数y = 11*sin(x) + 7*cos(5*x)在[-3,3]内的最大值(动画演示)
clear; clc
%% 绘制函数的图形
x = -3:0.01:3;
y = 11*sin(x) + 7*cos(5*x);
figure(1)
plot(x,y,'b-')
title('y = 11*sin(x) + 7*cos(5*x)')
hold on % 不关闭图形,继续在上面画图
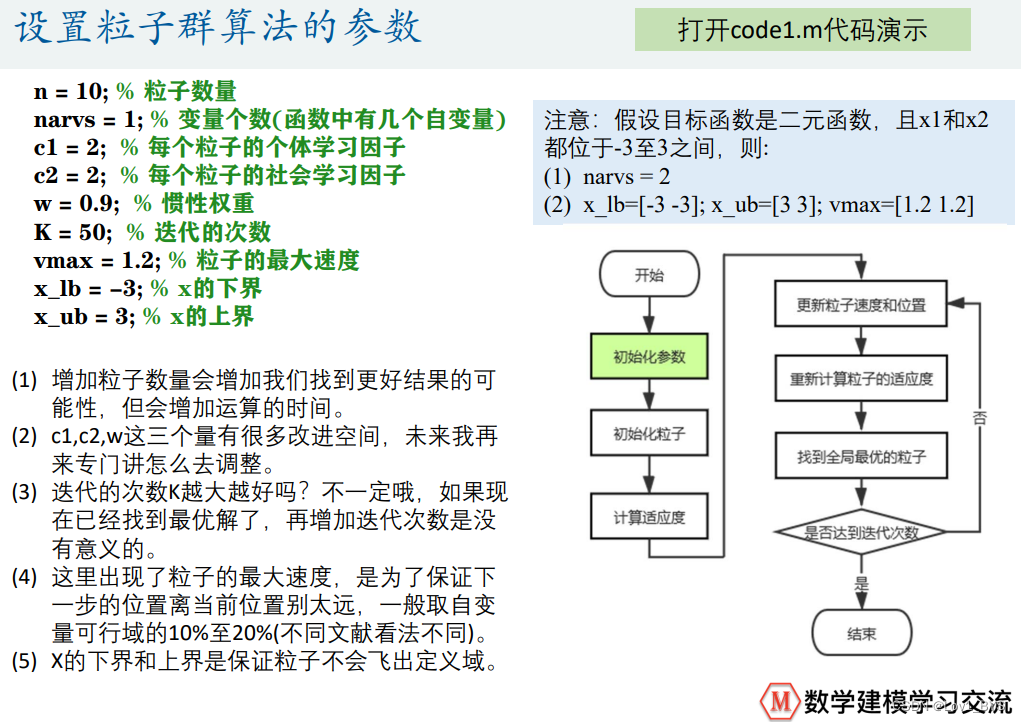
%% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
n = 10; % 粒子数量
narvs = 1; % 变量个数
c1 = 2; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2; % 每个粒子的社会学习因子,也称为社会加速常数
w = 0.9; % 惯性权重
K = 50; % 迭代的次数
vmax = 1.2; % 粒子的最大速度
x_lb = -3; % x的下界
x_ub = 3; % x的上界
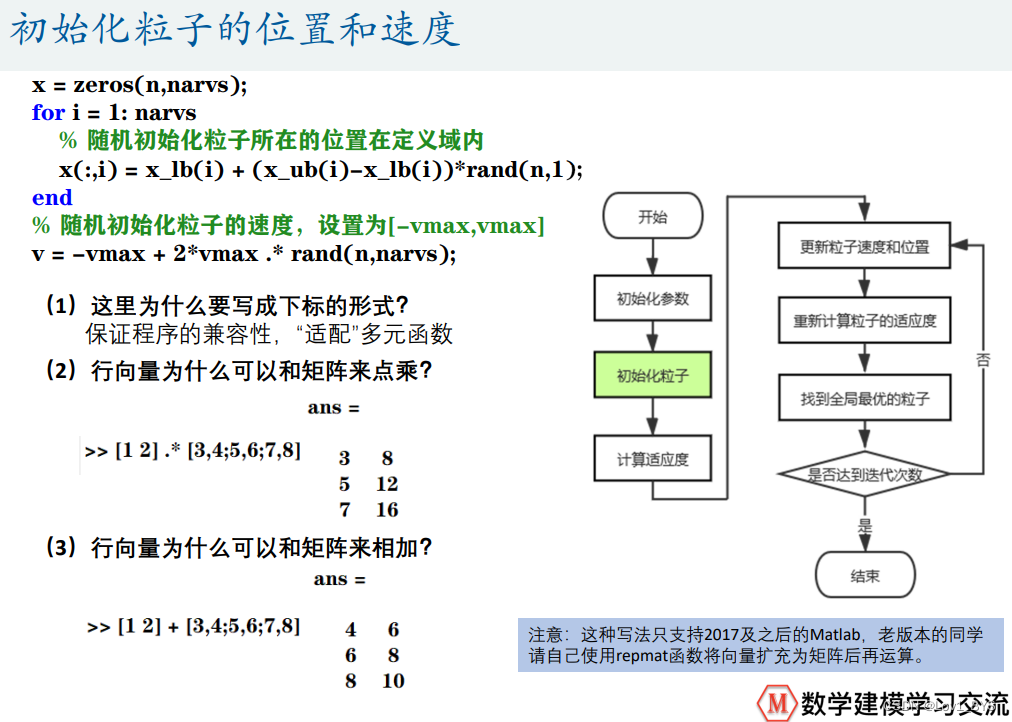
%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvs
x(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])
% 注意:这种写法只支持2017及之后的Matlab,老版本的同学请自己使用repmat函数将向量扩充为矩阵后再运算。
% 即:v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样
% 老版本同学可以用x = repmat(x_lb, n, 1) + repmat((x_ub-x_lb), n, 1).*rand(n,narvs)
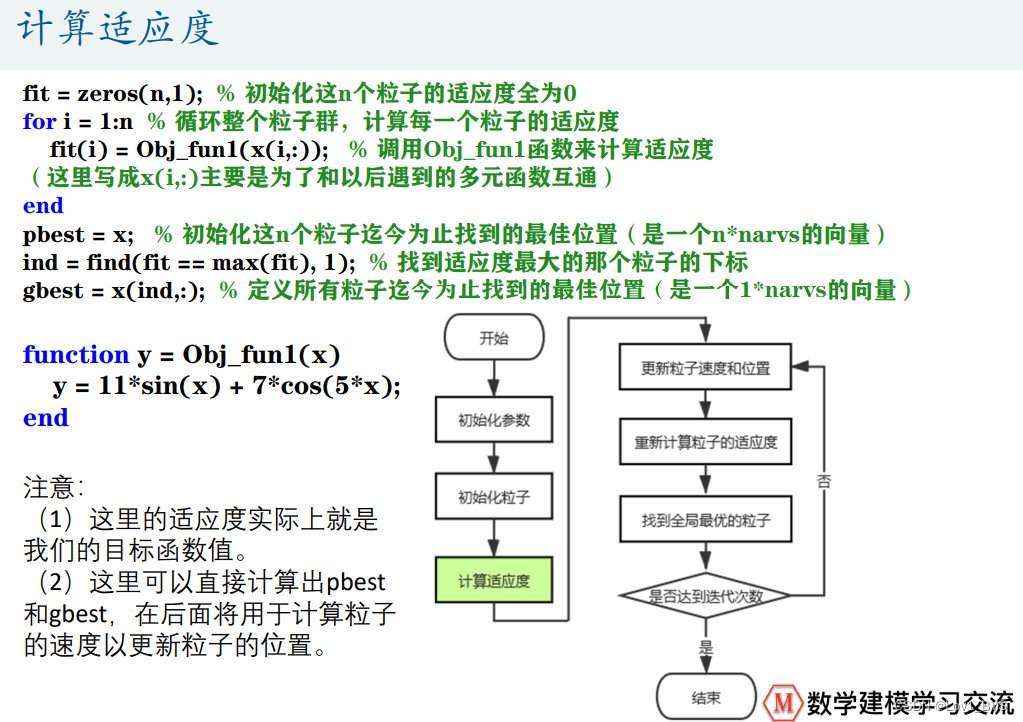
%% 计算适应度
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度
fit(i) = Obj_fun1(x(i,:)); % 调用Obj_fun1函数来计算适应度(这里写成x(i,:)主要是为了和以后遇到的多元函数互通)
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == max(fit), 1); % 找到适应度最大的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)
%% 在图上标上这n个粒子的位置用于演示
h = scatter(x,fit,80,'*r'); % scatter是绘制二维散点图的函数,80是我设置的散点显示的大小(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)
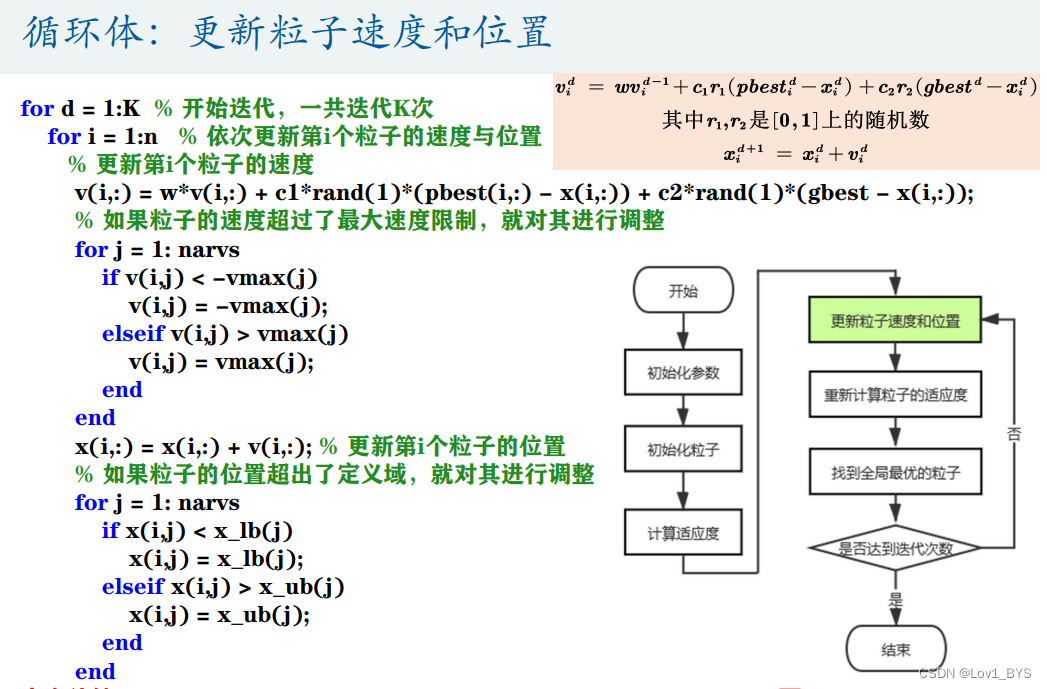
%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次
for i = 1:n % 依次更新第i个粒子的速度与位置
v(i,:) = w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:)); % 更新第i个粒子的速度
% 如果粒子的速度超过了最大速度限制,就对其进行调整
for j = 1: narvs
if v(i,j) < -vmax(j)
v(i,j) = -vmax(j);
elseif v(i,j) > vmax(j)
v(i,j) = vmax(j);
end
end
x(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置
% 如果粒子的位置超出了定义域,就对其进行调整
for j = 1: narvs
if x(i,j) < x_lb(j)
x(i,j) = x_lb(j);
elseif x(i,j) > x_ub(j)
x(i,j) = x_ub(j);
end
end
fit(i) = Obj_fun1(x(i,:)); % 重新计算第i个粒子的适应度
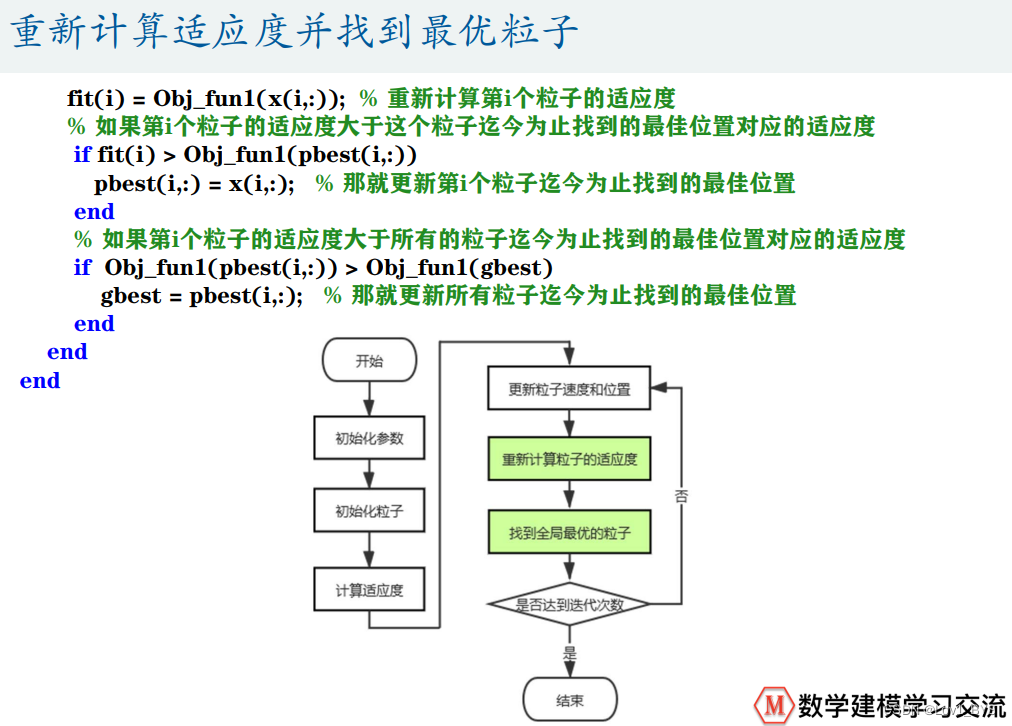
if fit(i) > Obj_fun1(pbest(i,:)) % 如果第i个粒子的适应度大于这个粒子迄今为止找到的最佳位置对应的适应度
pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置
end
if fit(i) > Obj_fun1(gbest) % 如果第i个粒子的适应度大于所有的粒子迄今为止找到的最佳位置对应的适应度
gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置
end
end
fitnessbest(d) = Obj_fun1(gbest); % 更新第d次迭代得到的最佳的适应度
pause(0.1) % 暂停0.1s
h.XData = x; % 更新散点图句柄的x轴的数据(此时粒子的位置在图上发生了变化)
h.YData = fit; % 更新散点图句柄的y轴的数据(此时粒子的位置在图上发生了变化)
end
figure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun1(gbest))
% 调用的Obj_fun1函数:(需要单独保存.m文件中)
function y = Obj_fun1(x)
y = 11*sin(x) + 7*cos(5*x);
% y = -(11*sin(x) + 7*cos(5*x)); % 如果调用fmincon函数,则需要添加负号改为求最小值
end
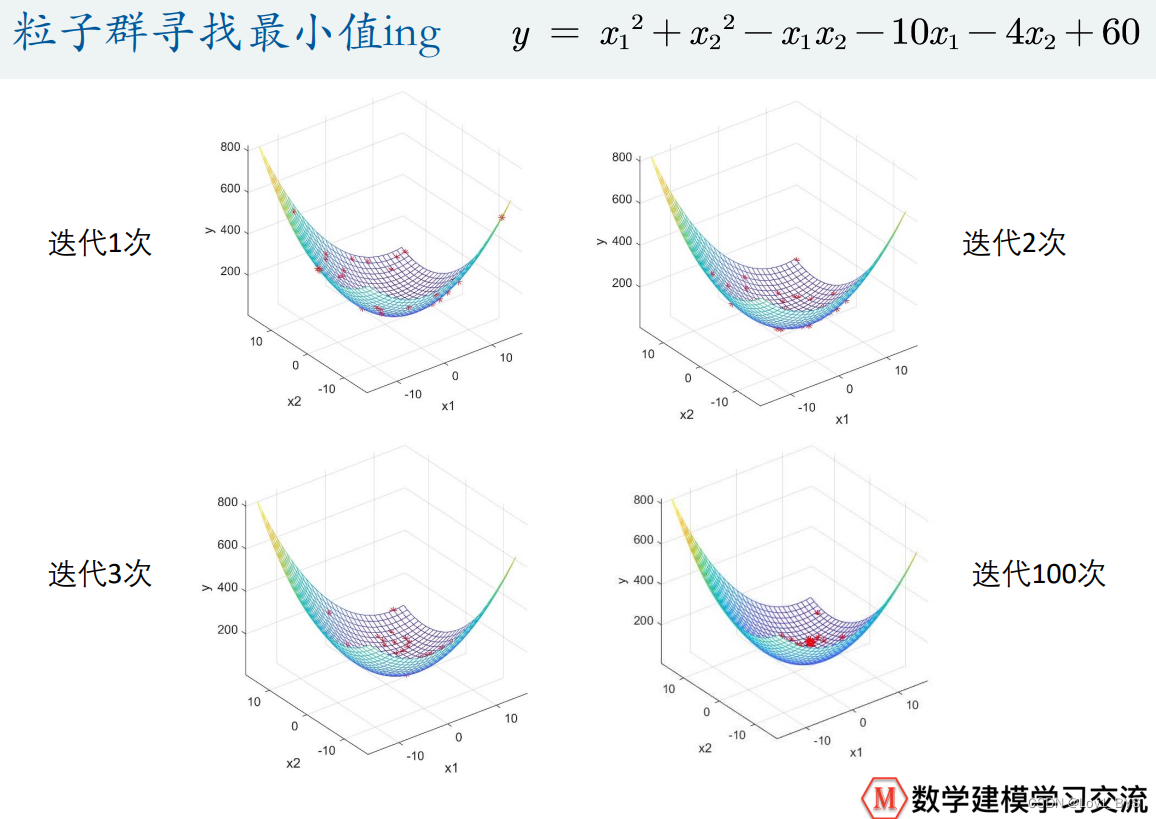
例二:求二元函数的最小值
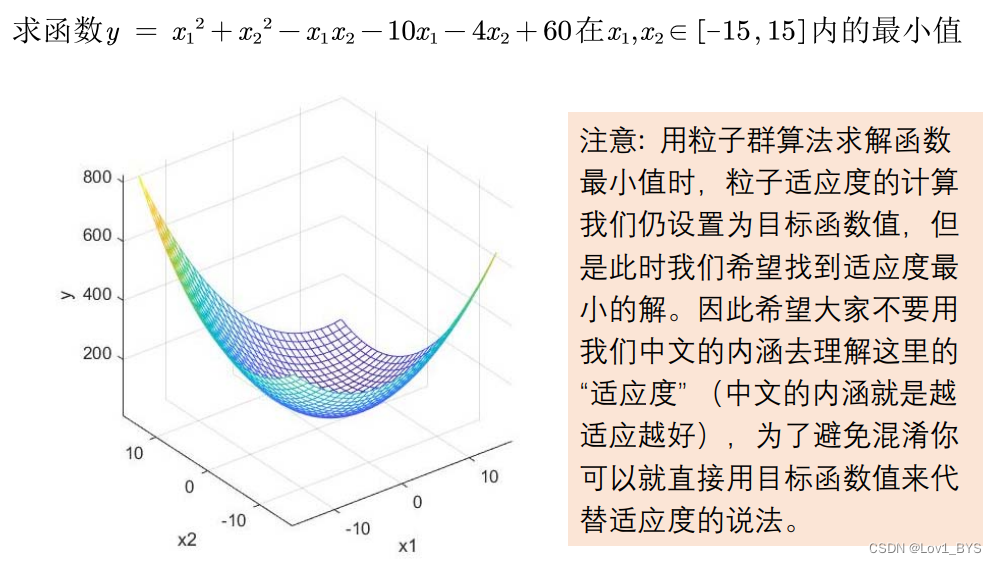
- 求最大值时,适应度越大越好;
- 求最小值时,适应度越小越好;
普通粒子群算法求解
%主函数
% 粒子群算法PSO: 求解函数y = x1^2+x2^2-x1*x2-10*x1-4*x2+60在[-15,15]内的最小值(动画演示)
clear; clc
%% 绘制函数的图形
x1 = -15:1:15;
x2 = -15:1:15;
[x1,x2] = meshgrid(x1,x2);
y = x1.^2 + x2.^2 - x1.*x2 - 10*x1 - 4*x2 + 60;
mesh(x1,x2,y)
xlabel('x1'); ylabel('x2'); zlabel('y'); % 加上坐标轴的标签
axis vis3d % 冻结屏幕高宽比,使得一个三维对象的旋转不会改变坐标轴的刻度显示
hold on % 不关闭图形,继续在上面画图
%% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
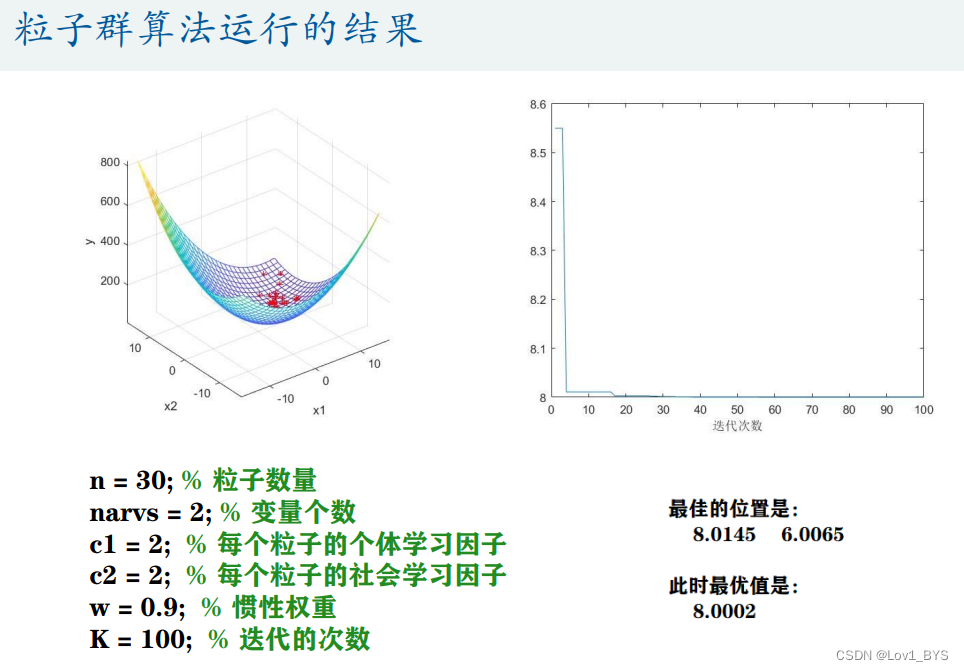
n = 30; % 粒子数量
narvs = 2; % 变量个数
c1 = 2; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2; % 每个粒子的社会学习因子,也称为社会加速常数
w = 0.9; % 惯性权重
K = 100; % 迭代的次数
vmax = [6 6]; % 粒子的最大速度
x_lb = [-15 -15]; % x的下界
x_ub = [15 15]; % x的上界
%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvs
x(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])
% 注意:这种写法只支持2017及之后的Matlab,老版本的同学请自己使用repmat函数将向量扩充为矩阵后再运算。
% 即:v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样
% 老版本同学可以用x = repmat(x_lb, n, 1) + repmat((x_ub-x_lb), n, 1).*rand(n,narvs)
%% 计算适应度(注意,因为是最小化问题,所以适应度越小越好)
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度
fit(i) = Obj_fun2(x(i,:)); % 调用Obj_fun2函数来计算适应度
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == min(fit), 1); % 找到适应度最小的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)
%% 在图上标上这n个粒子的位置用于演示
h = scatter3(x(:,1),x(:,2),fit,'*r'); % scatter3是绘制三维散点图的函数(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)
%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次
for i = 1:n % 依次更新第i个粒子的速度与位置
v(i,:) = w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:)); % 更新第i个粒子的速度
% 如果粒子的速度超过了最大速度限制,就对其进行调整
for j = 1: narvs
if v(i,j) < -vmax(j)
v(i,j) = -vmax(j);
elseif v(i,j) > vmax(j)
v(i,j) = vmax(j);
end
end
x(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置
% 如果粒子的位置超出了定义域,就对其进行调整
for j = 1: narvs
if x(i,j) < x_lb(j)
x(i,j) = x_lb(j);
elseif x(i,j) > x_ub(j)
x(i,j) = x_ub(j);
end
end
fit(i) = Obj_fun2(x(i,:)); % 重新计算第i个粒子的适应度
if fit(i) < Obj_fun2(pbest(i,:)) % 如果第i个粒子的适应度小于这个粒子迄今为止找到的最佳位置对应的适应度
pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置
end
if fit(i) < Obj_fun2(gbest) % 如果第i个粒子的适应度小于所有的粒子迄今为止找到的最佳位置对应的适应度
gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置
end
end
fitnessbest(d) = Obj_fun2(gbest); % 更新第d次迭代得到的最佳的适应度
pause(0.1) % 暂停0.1s
h.XData = x(:,1); % 更新散点图句柄的x轴的数据(此时粒子的位置在图上发生了变化)
h.YData = x(:,2); % 更新散点图句柄的y轴的数据(此时粒子的位置在图上发生了变化)
h.ZData = fit; % 更新散点图句柄的z轴的数据(此时粒子的位置在图上发生了变化)
end
figure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun2(gbest))
%被调用的函数:Obj_fun2
function y = Obj_fun2(x)
% y = x1^2+x2^2-x1*x2-10*x1-4*x2+60
% x是一个向量哦!
y = x(1)^2 + x(2)^2 - x(1)*x(2) - 10*x(1) - 4*x(2) + 60; % 千万别写成了x1
end
改进:线性递减惯性权重

- 先大范围搜索,再小范围精确
%% 线性递减惯性权重的粒子群算法PSO: 求解函数y = x1^2+x2^2-x1*x2-10*x1-4*x2+60在[-15,15]内的最小值(动画演示)
%主函数
clear; clc
%% 绘制函数的图形
x1 = -15:1:15;
x2 = -15:1:15;
[x1,x2] = meshgrid(x1,x2);
y = x1.^2 + x2.^2 - x1.*x2 - 10*x1 - 4*x2 + 60;
mesh(x1,x2,y)
xlabel('x1'); ylabel('x2'); zlabel('y'); % 加上坐标轴的标签
axis vis3d % 冻结屏幕高宽比,使得一个三维对象的旋转不会改变坐标轴的刻度显示
hold on % 不关闭图形,继续在上面画图
%% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
n = 30; % 粒子数量
narvs = 2; % 变量个数
c1 = 2; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2; % 每个粒子的社会学习因子,也称为社会加速常数
w_start = 0.9; % 初始惯性权重,通常取0.9
w_end = 0.4; % 粒子群最大迭代次数时的惯性权重,通常取0.4
K = 100; % 迭代的次数
vmax = [6 6]; % 粒子的最大速度
x_lb = [-15 -15]; % x的下界
x_ub = [15 15]; % x的上界
%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvs
x(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])
% 注意:这种写法只支持2017及之后的Matlab,老版本的同学请自己使用repmat函数将向量扩充为矩阵后再运算。
% 即:v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样
% 老版本同学可以用x = repmat(x_lb, n, 1) + repmat((x_ub-x_lb), n, 1).*rand(n,narvs)
%% 计算适应度
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度
fit(i) = Obj_fun2(x(i,:)); % 调用Obj_fun2函数来计算适应度
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == min(fit), 1); % 找到适应度最小的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)
%% 在图上标上这n个粒子的位置用于演示
h = scatter3(x(:,1),x(:,2),fit,'*r'); % scatter3是绘制三维散点图的函数(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)
%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次
for i = 1:n % 依次更新第i个粒子的速度与位置
w = w_start - (w_start - w_end) * d / K; % 可以从以下不同的计算方法替换
v(i,:) = w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:)); % 更新第i个粒子的速度
% 如果粒子的速度超过了最大速度限制,就对其进行调整
for j = 1: narvs
if v(i,j) < -vmax(j)
v(i,j) = -vmax(j);
elseif v(i,j) > vmax(j)
v(i,j) = vmax(j);
end
end
x(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置
% 如果粒子的位置超出了定义域,就对其进行调整
for j = 1: narvs
if x(i,j) < x_lb(j)
x(i,j) = x_lb(j);
elseif x(i,j) > x_ub(j)
x(i,j) = x_ub(j);
end
end
fit(i) = Obj_fun2(x(i,:)); % 重新计算第i个粒子的适应度
if fit(i) < Obj_fun2(pbest(i,:)) % 如果第i个粒子的适应度小于这个粒子迄今为止找到的最佳位置对应的适应度
pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置
end
if fit(i) < Obj_fun2(gbest) % 如果第i个粒子的适应度小于所有的粒子迄今为止找到的最佳位置对应的适应度
gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置
end
end
fitnessbest(d) = Obj_fun2(gbest); % 更新第d次迭代得到的最佳的适应度
pause(0.1) % 暂停0.1s
h.XData = x(:,1); % 更新散点图句柄的x轴的数据(此时粒子的位置在图上发生了变化)
h.YData = x(:,2); % 更新散点图句柄的y轴的数据(此时粒子的位置在图上发生了变化)
h.ZData = fit; % 更新散点图句柄的z轴的数据(此时粒子的位置在图上发生了变化)
end
figure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun2(gbest))
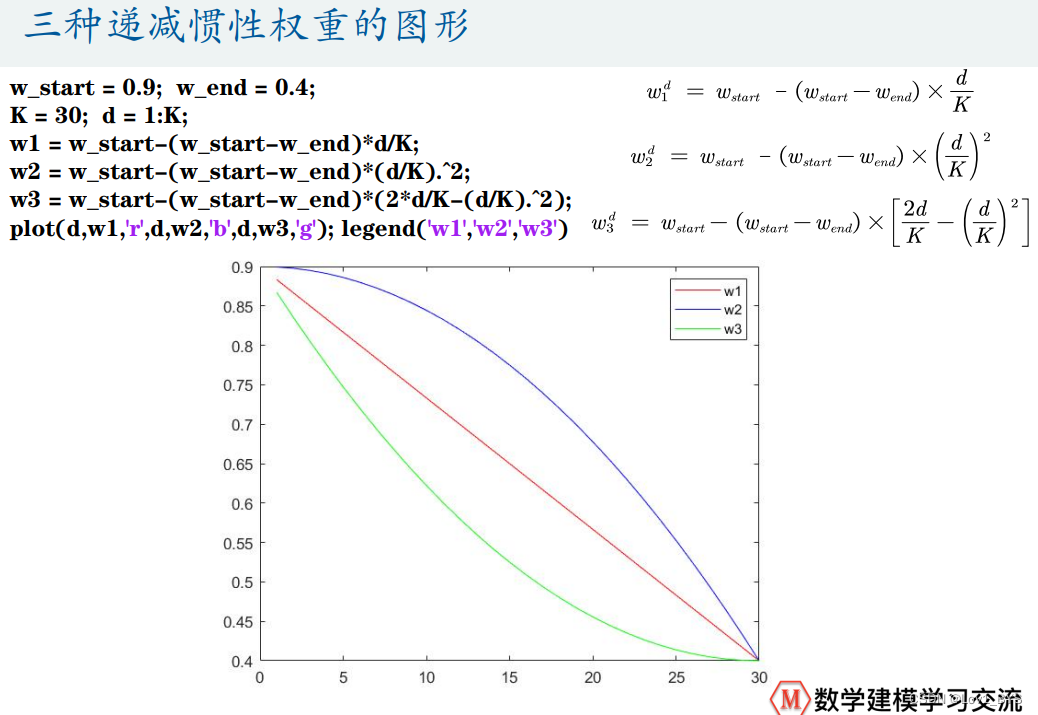
%% 三种递减惯性权重的对比
w_start = 0.9; w_end = 0.4;
K = 30; d = 1:K;
w1 = w_start-(w_start-w_end)*d/K; % 不同的计算权重办法
w2 = w_start-(w_start-w_end)*(d/K).^2; % 有线性的和非线性的,可以自行选择
w3 = w_start-(w_start-w_end)*(2*d/K-(d/K).^2); % 复制粘贴替换上面计算适应度的代码即可
figure(3)
plot(d,w1,'r',d,w2,'b',d,w3,'g');
legend('w1','w2','w3')
%被调用的函数:Obj_fun2
function y = Obj_fun2(x)
% y = x1^2+x2^2-x1*x2-10*x1-4*x2+60
% x是一个向量哦!
y = x(1)^2 + x(2)^2 - x(1)*x(2) - 10*x(1) - 4*x(2) + 60; % 千万别写成了x1
end
- 不同的递减惯性权重计算方法,可以自行选择替换即可
改进:自适应惯性权重




%% 自适应权重的粒子群算法PSO: 求解函数y = x1^2+x2^2-x1*x2-10*x1-4*x2+60在[-15,15]内的最小值(动画演示)
clear; clc
%% 绘制函数的图形
x1 = -15:1:15;
x2 = -15:1:15;
[x1,x2] = meshgrid(x1,x2);
y = x1.^2 + x2.^2 - x1.*x2 - 10*x1 - 4*x2 + 60;
mesh(x1,x2,y)
xlabel('x1'); ylabel('x2'); zlabel('y'); % 加上坐标轴的标签
axis vis3d % 冻结屏幕高宽比,使得一个三维对象的旋转不会改变坐标轴的刻度显示
hold on % 不关闭图形,继续在上面画图
%% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
n = 30; % 粒子数量
narvs = 2; % 变量个数
c1 = 2; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2; % 每个粒子的社会学习因子,也称为社会加速常数
w_max = 0.9; % 最大惯性权重,通常取0.9
w_min = 0.4; % 最小惯性权重,通常取0.4
K = 100; % 迭代的次数
vmax = [6 6]; % 粒子的最大速度
x_lb = [-15 -15]; % x的下界
x_ub = [15 15]; % x的上界
%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvs
x(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])
% 注意:这种写法只支持2017及之后的Matlab,老版本的同学请自己使用repmat函数将向量扩充为矩阵后再运算。
% 即:v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样
% 老版本同学可以用x = repmat(x_lb, n, 1) + repmat((x_ub-x_lb), n, 1).*rand(n,narvs)
%% 计算适应度
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度
fit(i) = Obj_fun2(x(i,:)); % 调用Obj_fun2函数来计算适应度
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == min(fit), 1); % 找到适应度最小的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)
%% 在图上标上这n个粒子的位置用于演示
h = scatter3(x(:,1),x(:,2),fit,'*r'); % scatter3是绘制三维散点图的函数(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)
%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次
for i = 1:n % 依次更新第i个粒子的速度与位置
f_i = fit(i); % 取出第i个粒子的适应度
f_avg = sum(fit)/n; % 计算此时适应度的平均值
f_min = min(fit); % 计算此时适应度的最小值
if f_i <= f_avg
if f_avg ~= f_min % 如果分母为0,我们就干脆令w=w_min
w = w_min + (w_max - w_min)*(f_i - f_min)/(f_avg - f_min);
else
w = w_min;
end
else
w = w_max;
end
v(i,:) = w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:)); % 更新第i个粒子的速度
% 如果粒子的速度超过了最大速度限制,就对其进行调整
for j = 1: narvs
if v(i,j) < -vmax(j)
v(i,j) = -vmax(j);
elseif v(i,j) > vmax(j)
v(i,j) = vmax(j);
end
end
x(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置
% 如果粒子的位置超出了定义域,就对其进行调整
for j = 1: narvs
if x(i,j) < x_lb(j)
x(i,j) = x_lb(j);
elseif x(i,j) > x_ub(j)
x(i,j) = x_ub(j);
end
end
fit(i) = Obj_fun2(x(i,:)); % 重新计算第i个粒子的适应度
if fit(i) < Obj_fun2(pbest(i,:)) % 如果第i个粒子的适应度小于这个粒子迄今为止找到的最佳位置对应的适应度
pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置
end
if fit(i) < Obj_fun2(gbest) % 如果第i个粒子的适应度小于所有的粒子迄今为止找到的最佳位置对应的适应度
gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置
end
end
fitnessbest(d) = Obj_fun2(gbest); % 更新第d次迭代得到的最佳的适应度
pause(0.1) % 暂停0.1s
h.XData = x(:,1); % 更新散点图句柄的x轴的数据(此时粒子的位置在图上发生了变化)
h.YData = x(:,2); % 更新散点图句柄的y轴的数据(此时粒子的位置在图上发生了变化)
h.ZData = fit; % 更新散点图句柄的z轴的数据(此时粒子的位置在图上发生了变化)
end
figure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun2(gbest))
%被调用的函数:Obj_fun2
function y = Obj_fun2(x)
% y = x1^2+x2^2-x1*x2-10*x1-4*x2+60
% x是一个向量哦!
y = x(1)^2 + x(2)^2 - x(1)*x(2) - 10*x(1) - 4*x(2) + 60; % 千万别写成了x1
end
改进:随机惯性权重


%% 随机权重的粒子群算法PSO: 求解函数y = x1^2+x2^2-x1*x2-10*x1-4*x2+60在[-15,15]内的最小值(动画演示)
clear; clc
%% 绘制函数的图形
x1 = -15:1:15;
x2 = -15:1:15;
[x1,x2] = meshgrid(x1,x2);
y = x1.^2 + x2.^2 - x1.*x2 - 10*x1 - 4*x2 + 60;
mesh(x1,x2,y)
xlabel('x1'); ylabel('x2'); zlabel('y'); % 加上坐标轴的标签
axis vis3d % 冻结屏幕高宽比,使得一个三维对象的旋转不会改变坐标轴的刻度显示
hold on % 不关闭图形,继续在上面画图
%% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
n = 30; % 粒子数量
narvs = 2; % 变量个数
c1 = 2; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2; % 每个粒子的社会学习因子,也称为社会加速常数
w_max = 0.9; % 最大惯性权重,通常取0.9
w_min = 0.4; % 最小惯性权重,通常取0.4
sigma = 0.3; % 正态分布的随机扰动项的标准差(一般取0.2-0.5之间)
K = 100; % 迭代的次数
vmax = [6 6]; % 粒子的最大速度
x_lb = [-15 -15]; % x的下界
x_ub = [15 15]; % x的上界
%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvs
x(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])
% 注意:这种写法只支持2017及之后的Matlab,老版本的同学请自己使用repmat函数将向量扩充为矩阵后再运算。
% 即:v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样
% 老版本同学可以用x = repmat(x_lb, n, 1) + repmat((x_ub-x_lb), n, 1).*rand(n,narvs)
%% 计算适应度
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度
fit(i) = Obj_fun2(x(i,:)); % 调用Obj_fun2函数来计算适应度
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == min(fit), 1); % 找到适应度最小的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)
%% 在图上标上这n个粒子的位置用于演示
h = scatter3(x(:,1),x(:,2),fit,'*r'); % scatter3是绘制三维散点图的函数(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)
%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次
for i = 1:n % 依次更新第i个粒子的速度与位置
w = w_min + (w_max - w_min)*rand(1) + sigma*randn(1);
v(i,:) = w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:)); % 更新第i个粒子的速度
% 如果粒子的速度超过了最大速度限制,就对其进行调整
for j = 1: narvs
if v(i,j) < -vmax(j)
v(i,j) = -vmax(j);
elseif v(i,j) > vmax(j)
v(i,j) = vmax(j);
end
end
x(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置
% 如果粒子的位置超出了定义域,就对其进行调整
for j = 1: narvs
if x(i,j) < x_lb(j)
x(i,j) = x_lb(j);
elseif x(i,j) > x_ub(j)
x(i,j) = x_ub(j);
end
end
fit(i) = Obj_fun2(x(i,:)); % 重新计算第i个粒子的适应度
if fit(i) < Obj_fun2(pbest(i,:)) % 如果第i个粒子的适应度小于这个粒子迄今为止找到的最佳位置对应的适应度
pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置
end
if fit(i) < Obj_fun2(gbest) % 如果第i个粒子的适应度小于所有的粒子迄今为止找到的最佳位置对应的适应度
gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置
end
end
fitnessbest(d) = Obj_fun2(gbest); % 更新第d次迭代得到的最佳的适应度
pause(0.1) % 暂停0.1s
h.XData = x(:,1); % 更新散点图句柄的x轴的数据(此时粒子的位置在图上发生了变化)
h.YData = x(:,2); % 更新散点图句柄的y轴的数据(此时粒子的位置在图上发生了变化)
h.ZData = fit; % 更新散点图句柄的z轴的数据(此时粒子的位置在图上发生了变化)
end
figure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun2(gbest))
%被调用的函数:Obj_fun2
function y = Obj_fun2(x)
% y = x1^2+x2^2-x1*x2-10*x1-4*x2+60
% x是一个向量哦!
y = x(1)^2 + x(2)^2 - x(1)*x(2) - 10*x(1) - 4*x(2) + 60; % 千万别写成了x1
end
改进:压缩(收缩)因子法


%% 带有压缩因子(收缩因子)的粒子群算法PSO: 求解函数y = x1^2+x2^2-x1*x2-10*x1-4*x2+60在[-15,15]内的最小值(动画演示)
clear; clc
%% 绘制函数的图形
x1 = -15:1:15;
x2 = -15:1:15;
[x1,x2] = meshgrid(x1,x2);
y = x1.^2 + x2.^2 - x1.*x2 - 10*x1 - 4*x2 + 60;
mesh(x1,x2,y)
xlabel('x1'); ylabel('x2'); zlabel('y'); % 加上坐标轴的标签
axis vis3d % 冻结屏幕高宽比,使得一个三维对象的旋转不会改变坐标轴的刻度显示
hold on % 不关闭图形,继续在上面画图
%% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
n = 30; % 粒子数量
narvs = 2; % 变量个数
c1 = 2.05; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2.05; % 每个粒子的社会学习因子,也称为社会加速常数
C = c1+c2;
fai = 2/abs((2-C-sqrt(C^2-4*C))); % 收缩因子
w = 0.9; % 惯性权重
K = 100; % 迭代的次数
vmax = [6 6]; % 粒子的最大速度
x_lb = [-15 -15]; % x的下界
x_ub = [15 15]; % x的上界
%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvs
x(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])
% 注意:这种写法只支持2017及之后的Matlab,老版本的同学请自己使用repmat函数将向量扩充为矩阵后再运算。
% 即:v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样
% 老版本同学可以用x = repmat(x_lb, n, 1) + repmat((x_ub-x_lb), n, 1).*rand(n,narvs)
%% 计算适应度
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度
fit(i) = Obj_fun2(x(i,:)); % 调用Obj_fun2函数来计算适应度
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == min(fit), 1); % 找到适应度最小的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)
%% 在图上标上这n个粒子的位置用于演示
h = scatter3(x(:,1),x(:,2),fit,'*r'); % scatter3是绘制三维散点图的函数(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)
%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次
for i = 1:n % 依次更新第i个粒子的速度与位置
v(i,:) = fai * (w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:))); % 更新第i个粒子的速度
% 有时候会看到直接写成:0.657*v(i,:) + 1.496*rand(1)*(pbest(i,:) - x(i,:)) + 1.496*rand(1)*(gbest - x(i,:)));
x(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置
% 如果粒子的位置超出了定义域,就对其进行调整
for j = 1: narvs
if x(i,j) < x_lb(j)
x(i,j) = x_lb(j);
elseif x(i,j) > x_ub(j)
x(i,j) = x_ub(j);
end
end
fit(i) = Obj_fun2(x(i,:)); % 重新计算第i个粒子的适应度
if fit(i) < Obj_fun2(pbest(i,:)) % 如果第i个粒子的适应度小于这个粒子迄今为止找到的最佳位置对应的适应度
pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置
end
if fit(i) < Obj_fun2(gbest) % 如果第i个粒子的适应度小于所有的粒子迄今为止找到的最佳位置对应的适应度
gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置
end
end
fitnessbest(d) = Obj_fun2(gbest); % 更新第d次迭代得到的最佳的适应度
pause(0.1) % 暂停0.1s
h.XData = x(:,1); % 更新散点图句柄的x轴的数据(此时粒子的位置在图上发生了变化)
h.YData = x(:,2); % 更新散点图句柄的y轴的数据(此时粒子的位置在图上发生了变化)
h.ZData = fit; % 更新散点图句柄的z轴的数据(此时粒子的位置在图上发生了变化)
end
figure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun2(gbest))
%被调用的函数:Obj_fun2
function y = Obj_fun2(x)
% y = x1^2+x2^2-x1*x2-10*x1-4*x2+60
% x是一个向量哦!
y = x(1)^2 + x(2)^2 - x(1)*x(2) - 10*x(1) - 4*x(2) + 60; % 千万别写成了x1
end
改进:非对称学习因子


%% 非对称学习因子的粒子群算法PSO: 求解函数y = x1^2+x2^2-x1*x2-10*x1-4*x2+60在[-15,15]内的最小值(动画演示)
clear; clc
% 毛开富, 包广清, 徐驰. 基于非对称学习因子调节的粒子群优化算法[J]. 计算机工程, 2010(19):188-190.(公式10中的减号应该改为加号)
%% 绘制函数的图形
x1 = -15:1:15;
x2 = -15:1:15;
[x1,x2] = meshgrid(x1,x2);
y = x1.^2 + x2.^2 - x1.*x2 - 10*x1 - 4*x2 + 60;
mesh(x1,x2,y)
xlabel('x1'); ylabel('x2'); zlabel('y'); % 加上坐标轴的标签
axis vis3d % 冻结屏幕高宽比,使得一个三维对象的旋转不会改变坐标轴的刻度显示
hold on % 不关闭图形,继续在上面画图
%% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
n = 30; % 粒子数量
narvs = 2; % 变量个数
c1_ini = 2.5; % 个体学习因子的初始值
c1_fin = 0.5; % 个体学习因子的最终值
c2_ini = 1; % 社会学习因子的初始值
c2_fin = 2.25; % 社会学习因子的最终值
w = 0.9; % 惯性权重
K = 100; % 迭代的次数
vmax = [6 6]; % 粒子的最大速度
x_lb = [-15 -15]; % x的下界
x_ub = [15 15]; % x的上界
%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvs
x(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])
% 注意:这种写法只支持2017及之后的Matlab,老版本的同学请自己使用repmat函数将向量扩充为矩阵后再运算。
%即:v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样
% 老版本同学可以用x = repmat(x_lb, n, 1) + repmat((x_ub-x_lb), n, 1).*rand(n,narvs)
%% 计算适应度
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度
fit(i) = Obj_fun2(x(i,:)); % 调用Obj_fun2函数来计算适应度
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == min(fit), 1); % 找到适应度最小的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)
%% 在图上标上这n个粒子的位置用于演示
h = scatter3(x(:,1),x(:,2),fit,'*r'); % scatter3是绘制三维散点图的函数(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)
%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次
% w = 0.9 - 0.5*d/K; % 效果不是很好的话可以同时考虑线性递减权重
c1 = c1_ini + (c1_fin - c1_ini)*d/K;
c2 = c2_ini + (c2_fin - c2_ini)*d/K;
for i = 1:n % 依次更新第i个粒子的速度与位置
v(i,:) = w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:)); % 更新第i个粒子的速度
% 如果粒子的速度超过了最大速度限制,就对其进行调整
for j = 1: narvs
if v(i,j) < -vmax(j)
v(i,j) = -vmax(j);
elseif v(i,j) > vmax(j)
v(i,j) = vmax(j);
end
end
x(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置
% 如果粒子的位置超出了定义域,就对其进行调整
for j = 1: narvs
if x(i,j) < x_lb(j)
x(i,j) = x_lb(j);
elseif x(i,j) > x_ub(j)
x(i,j) = x_ub(j);
end
end
fit(i) = Obj_fun2(x(i,:)); % 重新计算第i个粒子的适应度
if fit(i) < Obj_fun2(pbest(i,:)) % 如果第i个粒子的适应度小于这个粒子迄今为止找到的最佳位置对应的适应度
pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置
end
if fit(i) < Obj_fun2(gbest) % 如果第i个粒子的适应度小于所有的粒子迄今为止找到的最佳位置对应的适应度
gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置
end
end
fitnessbest(d) = Obj_fun2(gbest); % 更新第d次迭代得到的最佳的适应度
pause(0.1) % 暂停0.1s
h.XData = x(:,1); % 更新散点图句柄的x轴的数据(此时粒子的位置在图上发生了变化)
h.YData = x(:,2); % 更新散点图句柄的y轴的数据(此时粒子的位置在图上发生了变化)
h.ZData = fit; % 更新散点图句柄的z轴的数据(此时粒子的位置在图上发生了变化)
end
figure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun2(gbest))
%被调用的函数:Obj_fun2
function y = Obj_fun2(x)
% y = x1^2+x2^2-x1*x2-10*x1-4*x2+60
% x是一个向量哦!
y = x(1)^2 + x(2)^2 - x(1)*x(2) - 10*x(1) - 4*x(2) + 60; % 千万别写成了x1
end
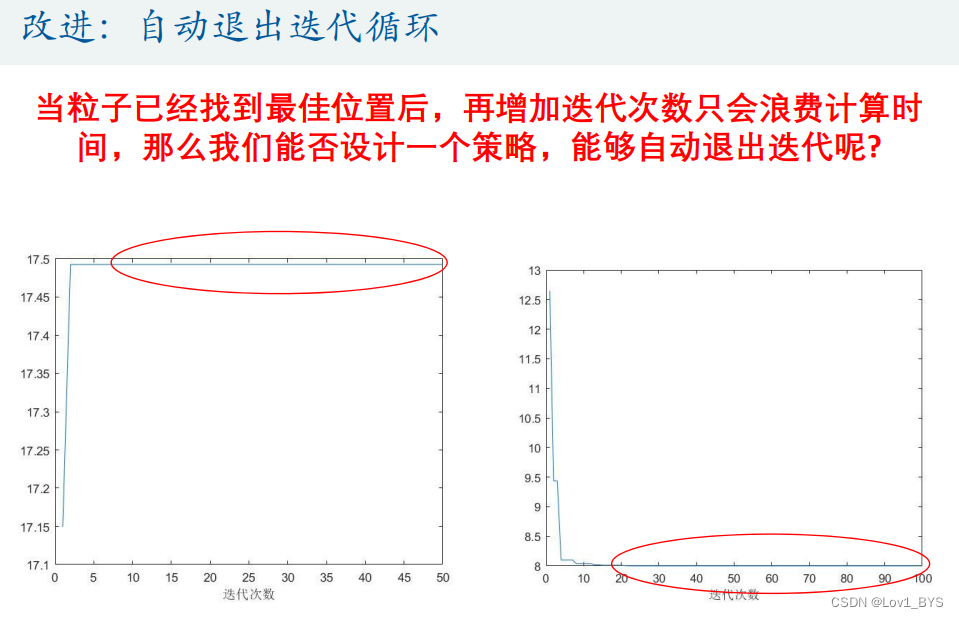
改进:自动退出迭代循环

%% 自适应权重且带有收缩因子的粒子群算法PSO: 求解四种不同测试函数的最小值(动画演示)
clear; clc
%% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
tic % 开始计时
n = 1000; % 粒子数量
narvs = 30; % 变量个数
c1 = 2.05; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2.05; % 每个粒子的社会学习因子,也称为社会加速常数
C = c1+c2;
fai = 2/abs((2-C-sqrt(C^2-4*C))); % 收缩因子
w_max = 0.9; % 最大惯性权重,通常取0.9
w_min = 0.4; % 最小惯性权重,通常取0.4
K = 1000; % 迭代的次数
% Sphere函数
% vmax = 30*ones(1,30); % 粒子的最大速度
% x_lb = -100*ones(1,30); % x的下界
% x_ub = 100*ones(1,30); % x的上界
% Rosenbrock函数
vmax = 10*ones(1,30); % 粒子的最大速度
x_lb = -30*ones(1,30); % x的下界
x_ub = 30*ones(1,30); % x的上界
% Rastrigin函数
% vmax = 1.5*ones(1,30); % 粒子的最大速度
% x_lb = -5.12*ones(1,30); % x的下界
% x_ub = 5.12*ones(1,30); % x的上界
% Griewank函数
% vmax = 150*ones(1,30); % 粒子的最大速度
% x_lb = -600*ones(1,30); % x的下界
% x_ub = 600*ones(1,30); % x的上界
%% 改进:自动退出迭代循环
Count = 0; % 计数器初始化为0
max_Count = 30; % 最大计数值初始化为30
tolerance = 1e-6; % 函数变化量容忍度,取10^(-6)
%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvs
x(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
% v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])
% 注意:这种写法只支持2017及之后的Matlab,老版本的同学请自己使用repmat函数将向量扩充为矩阵后再运算。
v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样
% 老版本同学可以用x = repmat(x_lb, n, 1) + repmat((x_ub-x_lb), n, 1).*rand(n,narvs)
%% 计算适应度
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度
fit(i) = Obj_fun3(x(i,:)); % 调用Obj_fun3函数来计算适应度
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == min(fit), 1); % 找到适应度最小的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)
%% 迭代K次来更新速度与位置
% fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
% 注意我把上面这行注释掉了,因为我们不知道最后一共要迭代多少次,可能后面会自动跳出循环
% 初始化的目的一般是节省运行的时间,在这里这个初始化的步骤我们可以跳过
for d = 1:K % 开始迭代,一共迭代K次
tem = gbest; % 将上一步找到的最佳位置保存为临时变量
for i = 1:n % 依次更新第i个粒子的速度与位置
f_i = fit(i); % 取出第i个粒子的适应度
f_avg = sum(fit)/n; % 计算此时适应度的平均值
f_min = min(fit); % 计算此时适应度的最小值
if f_i <= f_avg
w = w_min + (w_max - w_min)*(f_i - f_min)/(f_avg - f_min);
else
w = w_max;
end
v(i,:) = fai * (w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:))); % 更新第i个粒子的速度
x(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置
% 如果粒子的位置超出了定义域,就对其进行调整
for j = 1: narvs
if x(i,j) < x_lb(j)
x(i,j) = x_lb(j);
elseif x(i,j) > x_ub(j)
x(i,j) = x_ub(j);
end
end
fit(i) = Obj_fun3(x(i,:)); % 重新计算第i个粒子的适应度
if fit(i) < Obj_fun3(pbest(i,:)) % 如果第i个粒子的适应度小于这个粒子迄今为止找到的最佳位置对应的适应度
pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置
end
if fit(i) < Obj_fun3(gbest) % 如果第i个粒子的适应度小于所有的粒子迄今为止找到的最佳位置对应的适应度
gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置
end
end
fitnessbest(d) = Obj_fun3(gbest); % 更新第d次迭代得到的最佳的适应度
delta_fit = abs(Obj_fun3(gbest) - Obj_fun3(tem)); % 计算相邻两次迭代适应度的变化量
if delta_fit < tolerance % 判断这个变化量和“函数变化量容忍度”的相对大小,如果前者小,则计数器加1
Count = Count + 1;
else
Count = 0; % 否则计数器清0
end
if Count > max_Count % 如果计数器的值达到了最大计数值
break; % 跳出循环
end
end
figure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun3(gbest))
toc % 结束计时
%被调用的函数:Obj_fun3
function y = Obj_fun3(x)
% 注意,x是一个向量
% Sphere函数
% y = sum(x.^2); % x.^2 表示x中每一个元素分别计算平方
% Rosenbrock函数
tem1 = x(1:end-1);
tem2 = x(2:end);
y = sum(100 * (tem2-tem1.^2).^2 + (tem1-1).^2);
% Rastrigin函数
% y = sum(x.^2-10*cos(2*pi*x)+10);
% Griewank函数
% y = 1/4000*sum(x.*x)-prod(cos(x./sqrt(1:30)))+1;
end
优化问题的测试函数

- 就是把公式带入粒子群算法中求最优解,再比较最优解,越接近理论极值(误差目标越小)越好
%代码和未改进自动退出迭代循环的代码一样
%% 自适应权重且带有收缩因子的粒子群算法PSO: 求解四种不同测试函数的最小值(动画演示)
clear; clc
%% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
tic % 开始计时
n = 1000; % 粒子数量
narvs = 30; % 变量个数
c1 = 2.05; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2.05; % 每个粒子的社会学习因子,也称为社会加速常数
C = c1+c2;
fai = 2/abs((2-C-sqrt(C^2-4*C))); % 收缩因子
w_max = 0.9; % 最大惯性权重,通常取0.9
w_min = 0.4; % 最小惯性权重,通常取0.4
K = 1000; % 迭代的次数
% Sphere函数
vmax = 30*ones(1,30); % 粒子的最大速度
x_lb = -100*ones(1,30); % x的下界
x_ub = 100*ones(1,30); % x的上界
% Rosenbrock函数
% vmax = 10*ones(1,30); % 粒子的最大速度
% x_lb = -30*ones(1,30); % x的下界
% x_ub = 30*ones(1,30); % x的上界
% Rastrigin函数
% vmax = 1.5*ones(1,30); % 粒子的最大速度
% x_lb = -5.12*ones(1,30); % x的下界
% x_ub = 5.12*ones(1,30); % x的上界
% Griewank函数
% vmax = 150*ones(1,30); % 粒子的最大速度
% x_lb = -600*ones(1,30); % x的下界
% x_ub = 600*ones(1,30); % x的上界
%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvs
x(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
% v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])
% 注意:这种写法只支持2017及之后的Matlab,老版本的同学请自己使用repmat函数将向量扩充为矩阵后再运算。
v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样
% 老版本同学可以用x = repmat(x_lb, n, 1) + repmat((x_ub-x_lb), n, 1).*rand(n,narvs)
%% 计算适应度
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度
fit(i) = Obj_fun3(x(i,:)); % 调用Obj_fun3函数来计算适应度
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == min(fit), 1); % 找到适应度最小的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)
%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次
for i = 1:n % 依次更新第i个粒子的速度与位置
f_i = fit(i); % 取出第i个粒子的适应度
f_avg = sum(fit)/n; % 计算此时适应度的平均值
f_min = min(fit); % 计算此时适应度的最小值
if f_i <= f_avg
w = w_min + (w_max - w_min)*(f_i - f_min)/(f_avg - f_min);
else
w = w_max;
end
v(i,:) = fai * (w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:))); % 更新第i个粒子的速度
x(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置
% 如果粒子的位置超出了定义域,就对其进行调整
for j = 1: narvs
if x(i,j) < x_lb(j)
x(i,j) = x_lb(j);
elseif x(i,j) > x_ub(j)
x(i,j) = x_ub(j);
end
end
fit(i) = Obj_fun3(x(i,:)); % 重新计算第i个粒子的适应度
if fit(i) < Obj_fun3(pbest(i,:)) % 如果第i个粒子的适应度小于这个粒子迄今为止找到的最佳位置对应的适应度
pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置
end
if fit(i) < Obj_fun3(gbest) % 如果第i个粒子的适应度小于所有的粒子迄今为止找到的最佳位置对应的适应度
gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置
end
end
fitnessbest(d) = Obj_fun3(gbest); % 更新第d次迭代得到的最佳的适应度
end
figure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun3(gbest))
toc % 结束计时
%被调用的函数:Obj_fun3
function y = Obj_fun3(x)
% 注意,x是一个向量
% Sphere函数
% y = sum(x.^2); % x.^2 表示x中每一个元素分别计算平方
% Rosenbrock函数
tem1 = x(1:end-1);
tem2 = x(2:end);
y = sum(100 * (tem2-tem1.^2).^2 + (tem1-1).^2);
% Rastrigin函数
% y = sum(x.^2-10*cos(2*pi*x)+10);
% Griewank函数
% y = 1/4000*sum(x.*x)-prod(cos(x./sqrt(1:30)))+1;
end
※ matlab自带的粒子群函数









%% Matlab自带的粒子群函数 particleswarm
% particleswarm函数是求最小值的
% 如果目标函数是求最大值则需要添加负号从而转换为求最小值。
clear;clc
% Matlab中粒子群算法函数的参考文献
% Mezura-Montes, E., and C. A. Coello Coello. "Constraint-handling in nature-inspired numerical optimization: Past, present and future." Swarm and Evolutionary Computation. 2011, pp. 173–194.
% Pedersen, M. E. "Good Parameters for Particle Swarm Optimization." Luxembourg: Hvass Laboratories, 2010.
% Iadevaia, S., Lu, Y., Morales, F. C., Mills, G. B. & Ram, P. T. Identification of optimal drug combinations targeting cellular networks: integrating phospho-proteomics and computational network analysis. Cancer Res. 70, 6704-6714 (2010).
% Liu, Mingshou , D. Shin , and H. I. Kang . "Parameter estimation in dynamic biochemical systems based on adaptive Particle Swarm Optimization." Information, Communications and Signal Processing, 2009. ICICS 2009. 7th International Conference on IEEE Press, 2010.
%% 求解函数y = x1^2+x2^2-x1*x2-10*x1-4*x2+60在[-15,15]内的最小值(最小值为8)
narvs = 2; % 变量个数
x_lb = [-15 -15]; % x的下界(长度等于变量的个数,每个变量对应一个下界约束)
x_ub = [15 15]; % x的上界
[x,fval,exitflag,output] = particleswarm(@Obj_fun2, narvs, x_lb, x_ub)
%% 直接调用particleswarm函数进行求解测试函数
narvs = 30; % 变量个数
% Sphere函数
% x_lb = -100*ones(1,30); % x的下界
% x_ub = 100*ones(1,30); % x的上界
% Rosenbrock函数
x_lb = -30*ones(1,30); % x的下界
x_ub = 30*ones(1,30); % x的上界
% Rastrigin函数
% x_lb = -5.12*ones(1,30); % x的下界
% x_ub = 5.12*ones(1,30); % x的上界
% Griewank函数
% x_lb = -600*ones(1,30); % x的下界
% x_ub = 600*ones(1,30); % x的上界
[x,fval,exitflag,output] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub)
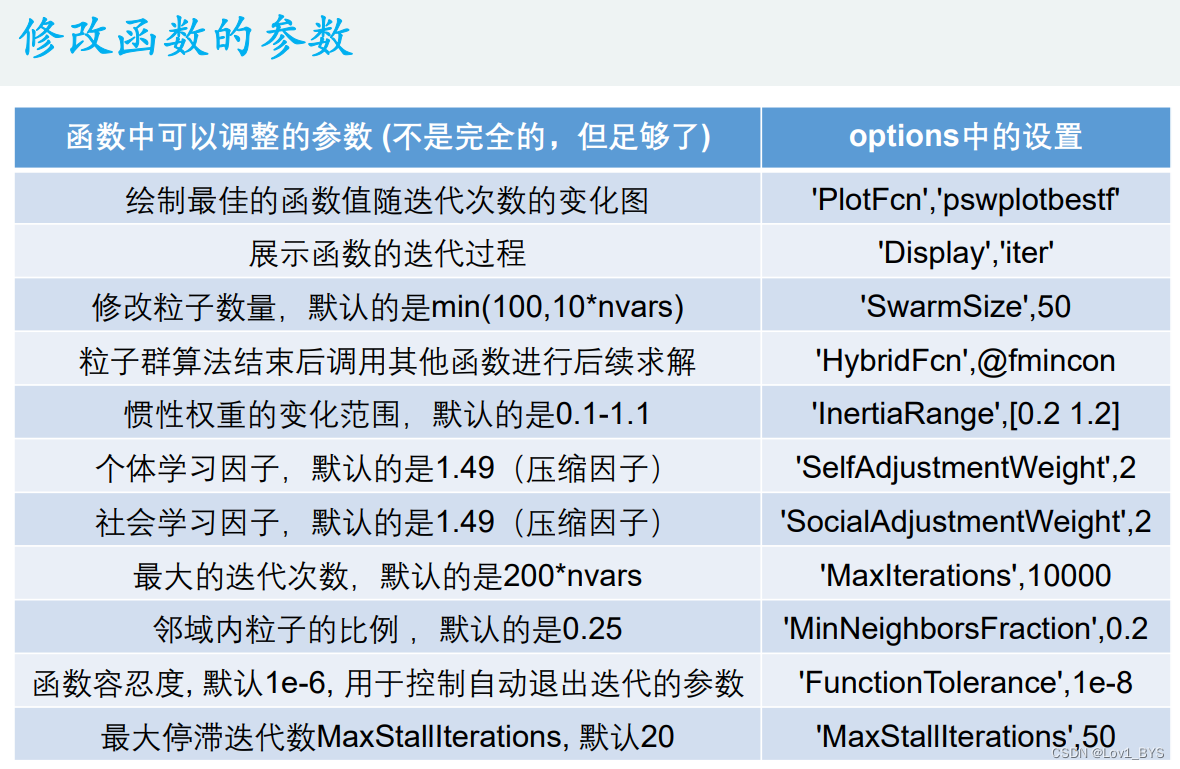
%% 绘制最佳的函数值随迭代次数的变化图
options = optimoptions('particleswarm','PlotFcn','pswplotbestf')
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 展示函数的迭代过程
options = optimoptions('particleswarm','Display','iter');
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 修改粒子数量,默认的是:min(100,10*nvars)
options = optimoptions('particleswarm','SwarmSize',50);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 在粒子群算法结束后继续调用其他函数进行混合求解(hybrid n.混合物合成物; adj.混合的; 杂种的;)
options = optimoptions('particleswarm','HybridFcn',@fmincon);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 惯性权重的变化范围,默认的是0.1-1.1
options = optimoptions('particleswarm','InertiaRange',[0.2 1.2]);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 个体学习因子,默认的是1.49(压缩因子)
options = optimoptions('particleswarm','SelfAdjustmentWeight',2);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 社会学习因子,默认的是1.49(压缩因子)
options = optimoptions('particleswarm','SocialAdjustmentWeight',2);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 最大的迭代次数,默认的是200*nvars
options = optimoptions('particleswarm','MaxIterations',10000);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 领域内粒子的比例 MinNeighborsFraction,默认是0.25
options = optimoptions('particleswarm','MinNeighborsFraction',0.2);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 函数容忍度FunctionTolerance, 默认1e-6, 用于控制自动退出迭代的参数
options = optimoptions('particleswarm','FunctionTolerance',1e-8);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 最大停滞迭代数MaxStallIterations, 默认20, 用于控制自动退出迭代的参数
options = optimoptions('particleswarm','MaxStallIterations',50);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
%% 不考虑计算时间,同时修改三个控制迭代退出的参数
tic
options = optimoptions('particleswarm','FunctionTolerance',1e-12,'MaxStallIterations',100,'MaxIterations',100000);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
toc
%% 在粒子群结束后调用其他函数进行混合求解
tic
options = optimoptions('particleswarm','FunctionTolerance',1e-12,'MaxStallIterations',50,'MaxIterations',20000,'HybridFcn',@fmincon);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
toc
%被调用的函数:Obj_fun2
function y = Obj_fun2(x)
% y = x1^2+x2^2-x1*x2-10*x1-4*x2+60
% x是一个向量哦!
y = x(1)^2 + x(2)^2 - x(1)*x(2) - 10*x(1) - 4*x(2) + 60; % 千万别写成了x1
end
%被调用的函数:Obj_fun3
function y = Obj_fun3(x)
% 注意,x是一个向量
% Sphere函数
% y = sum(x.^2); % x.^2 表示x中每一个元素分别计算平方
% Rosenbrock函数
tem1 = x(1:end-1);
tem2 = x(2:end);
y = sum(100 * (tem2-tem1.^2).^2 + (tem1-1).^2);
% Rastrigin函数
% y = sum(x.^2-10*cos(2*pi*x)+10);
% Griewank函数
% y = 1/4000*sum(x.*x)-prod(cos(x./sqrt(1:30)))+1;
end


粒子群算法进阶应用
求解方程组


- 例题:

三种求解方法 :
- vpasolve 函数
- fsolve 函数
- 粒子群算法
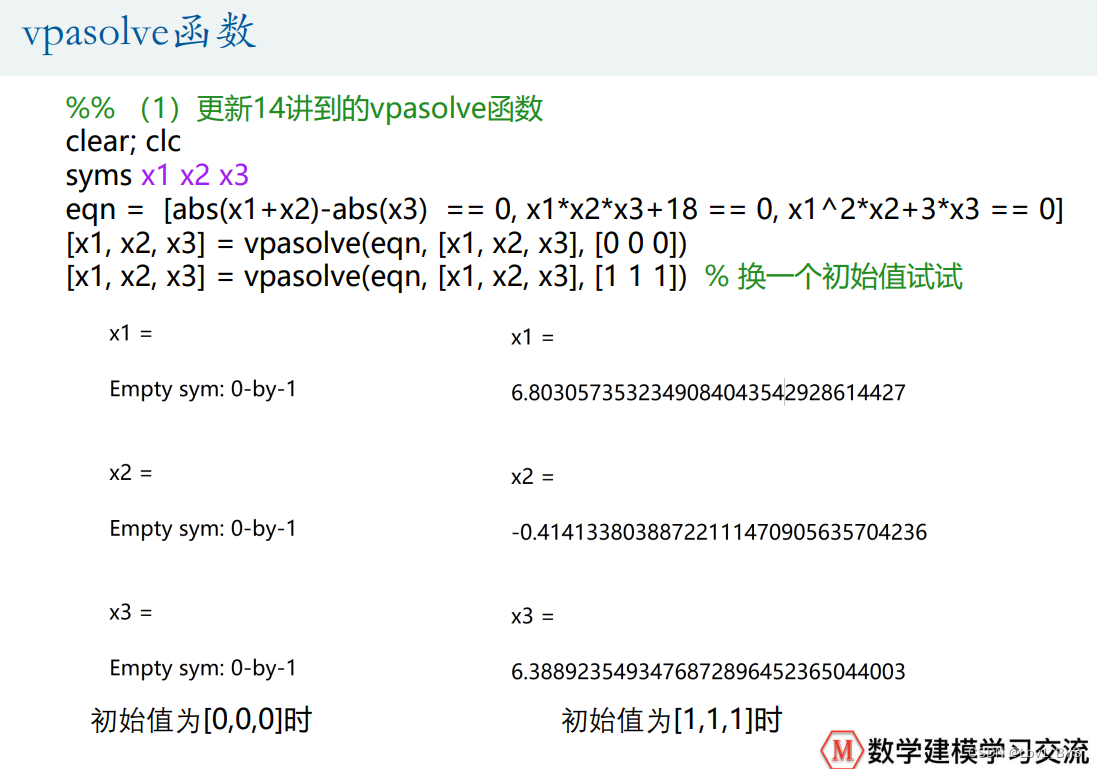


%% (1)vpasolve函数
clear; clc
syms x1 x2 x3
eqn = [abs(x1+x2)-abs(x3) == 0, x1*x2*x3+18 == 0, x1^2*x2+3*x3 == 0]
[x1, x2, x3] = vpasolve(eqn, [x1, x2, x3], [0 0 0])
[x1, x2, x3] = vpasolve(eqn, [x1, x2, x3], [1 1 1]) % 换一个初始值试试
%% (2)fsolve函数
x0 = [0,0,0]; % 初始值
x = fsolve(@my_fun,x0)
% 换一个初始值试试
x0 = [1,1,1]; % 初始值
format long g % 显示更多的小数位数
x = fsolve(@my_fun,x0)
%% (3) 粒子群算法(可以尝试多次,有可能找到多个解)
clear; clc
narvs = 3;
% 使用粒子群算法,不需要指定初始值,只需要给定一个搜索的范围
lb = -10*ones(1,3); ub = 10*ones(1,3); % 搜索范围 [-10,10]
options = optimoptions('particleswarm','FunctionTolerance',1e-12,'MaxStallIterations',100,'MaxIterations',20000,'SwarmSize',100); %搜索精度更高
[x, fval] = particleswarm(@Obj_fun,narvs,lb,ub,options)
% 被调用的函数:my_fun
function F = my_fun(x)
F(1) = abs(x(1)+x(2))-abs(x(3));
F(2) = x(1) * x(2) * x(3) + 18;
F(3) = x(1)^2*x(2)+3*x(3);
end
% 被调用的函数:Obk_fun
function f = Obj_fun(x)
f1= abs(x(1)+x(2))-abs(x(3)) ;
f2 = x(1) * x(2) * x(3) + 18;
f3= x(1)^2 * x(2) + 3*x(3);
f = abs(f1) + abs(f2) + abs(f3);
end

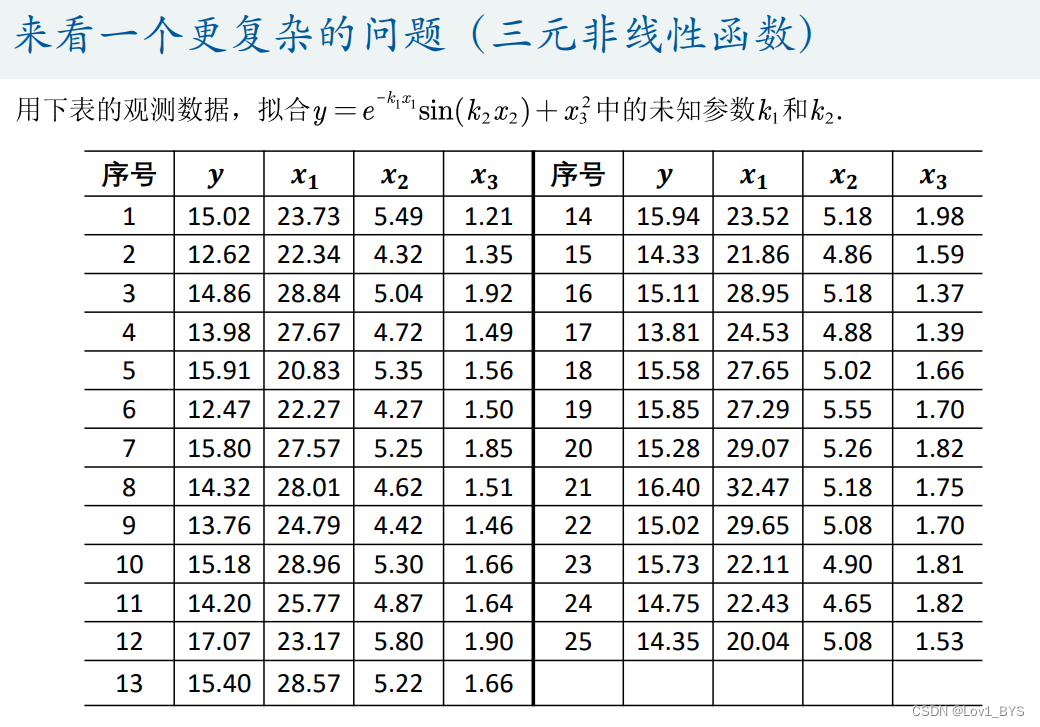
多元函数拟合
- 拟合工具箱只能对一元函数和二元函数进行拟合,所以多个变量可以用粒子群算法拟合


- 方法一:利用fmincon函数求解
- 方法二: 利用fminunc函数求解
- 方法三:利用 lsqcurvefit 函数 非线性最小二乘法拟合

- 方法四:粒子群算法

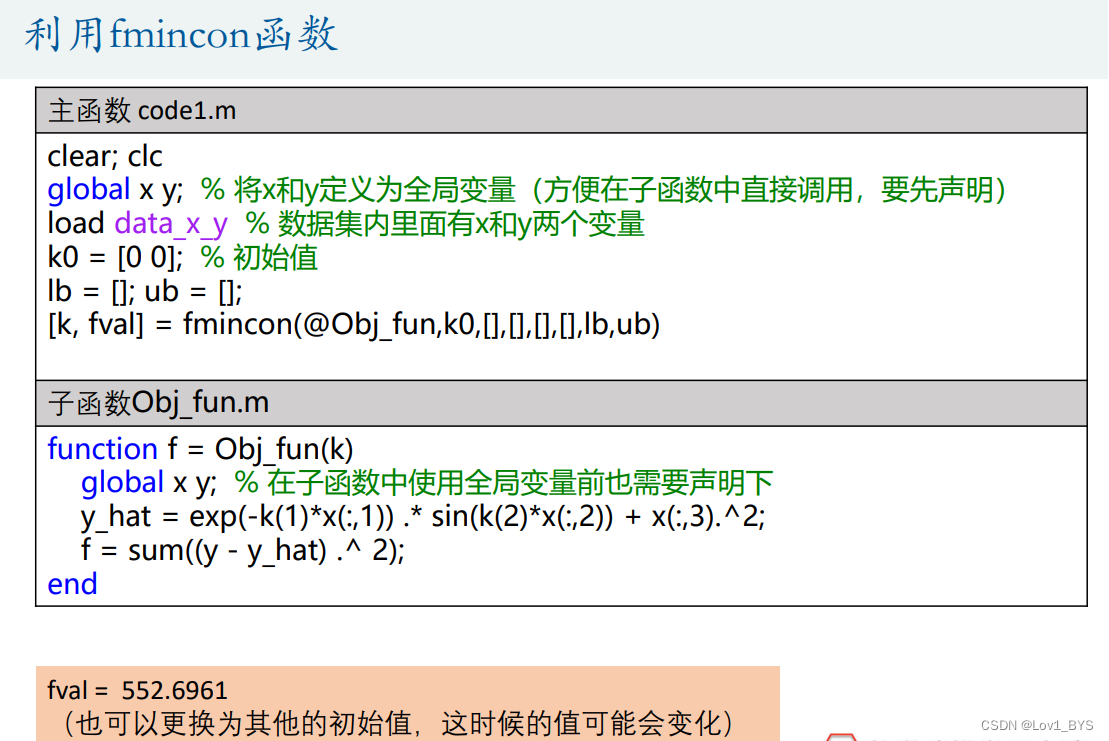
%%%%%%%%%%%%%%%%%%%% 方法一、二: fmincon 函数求解 %%%%%%%%%%%%%%%%%%%%
clear; clc
global x y; % 将x和y定义为全局变量(方便在子函数中直接调用,要先声明)
load data_x_y % 数据集内里面有x和y两个变量
k0 = [0 0]; %初始值,注意哦,这个初始值的选取确实挺难,需要尝试。。。
lb = []; ub = [];
% lb = [-1 -1]; ub = [2 2];
[k, fval] = fmincon(@Obj_fun,k0,[],[],[],[],lb,ub)
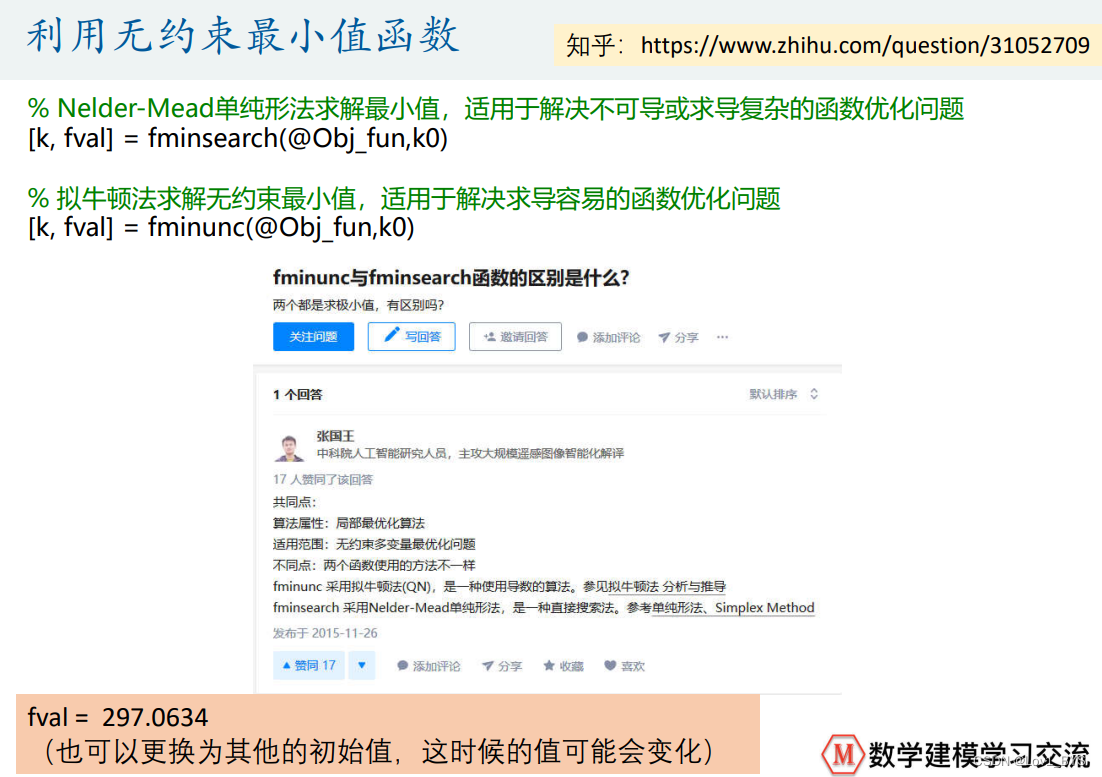
%% 求解无约束非线性函数的最小值的两个函数
[k, fval] = fminsearch(@Obj_fun,k0) % Nelder-Mead单纯形法求解最小值,适用于解决不可导或求导复杂的函数优化问题
[k, fval] = fminunc(@Obj_fun,k0) % 拟牛顿法求解无约束最小值,适用于解决求导容易的函数优化问题
%% 计算拟合值和实际值的相对误差
y_hat = exp(-k(1)*x(:,1)) .* sin(k(2)*x(:,2)) + x(:,3).^2; % 计算拟合值
res_rate = abs(y - y_hat) ./ y; % 相对误差
plot(res_rate) % 每个样本对应的相对误差
mean(res_rate) % 平均相对误差 (小于0.1最好,超过0.3说明拟合效果不好)
% 被调用的函数:Obj_fun
function f = Obj_fun(k)
global x y; % 在子函数中使用全局变量前也需要声明下
y_hat = exp(-k(1)*x(:,1)) .* sin(k(2)*x(:,2)) + x(:,3).^2; % 拟合值
f = sum((y - y_hat) .^ 2);
end
%%%%%%%%%%%%%%%%%%%% 方法三: lsqcurvefit 函数 非线性最小二乘法拟合 %%%%%%%%%%%%%%%%%%%%
%% 非线性最小二乘拟合函数lsqcurvefit
clear; clc
load data_x_y
k0 = [0 0];
lb = []; ub = [];
[k, fval] = lsqcurvefit(@fit_fun,k0,x,y,lb,ub)
% Choose between 'trust-region-reflective' (default) and 'levenberg-marquardt'. (切换算法,默认的是信赖域反射算法)
options= optimoptions('lsqcurvefit','Algorithm','levenberg-marquardt');
[k, fval] = lsqcurvefit(@fit_fun,k0,x,y,lb,ub,options)
% 被调用的函数:fit_fun
function y_hat = fit_fun(k,x)
y_hat = exp(-k(1)*x(:,1)) .* sin(k(2)*x(:,2)) + x(:,3).^2; % 返回的函数就是我们的拟合值
end
%%%%%%%%%%%%%%%%%%%% 方法四: 粒子群算法 %%%%%%%%%%%%%%%%%%%%
clear; clc
global x y; % 将x和y定义为全局变量(方便在子函数中直接调用,要先声明)
load data_x_y % 数据集内里面有x和y两个变量
narvs = 2;
% 使用粒子群算法,不需要指定初始值,只需要给定一个搜索的范围
lb = [-10 -10]; ub = [10 10];
[k, fval] = particleswarm(@Obj_fun,narvs,lb,ub)
% 使用粒子群算法后再利用fmincon函数 混合求解
options = optimoptions('particleswarm','HybridFcn',@fmincon);
[k,fval] = particleswarm(@Obj_fun,narvs,lb,ub,options)
% 被调用函数:Obj_fun
function f = Obj_fun(k)
global x y; % 在子函数中使用全局变量前也需要声明下
y_hat = exp(-k(1)*x(:,1)) .* sin(k(2)*x(:,2)) + x(:,3).^2;
f = sum((y - y_hat) .^ 2);
end
拟合微分方程
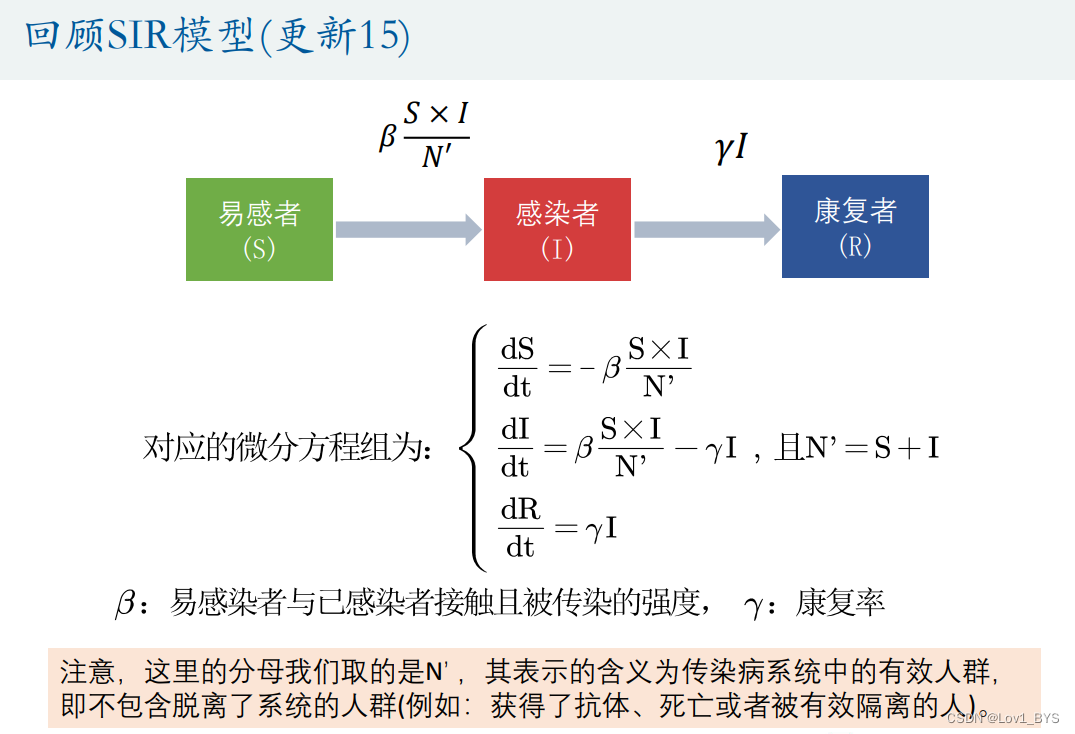
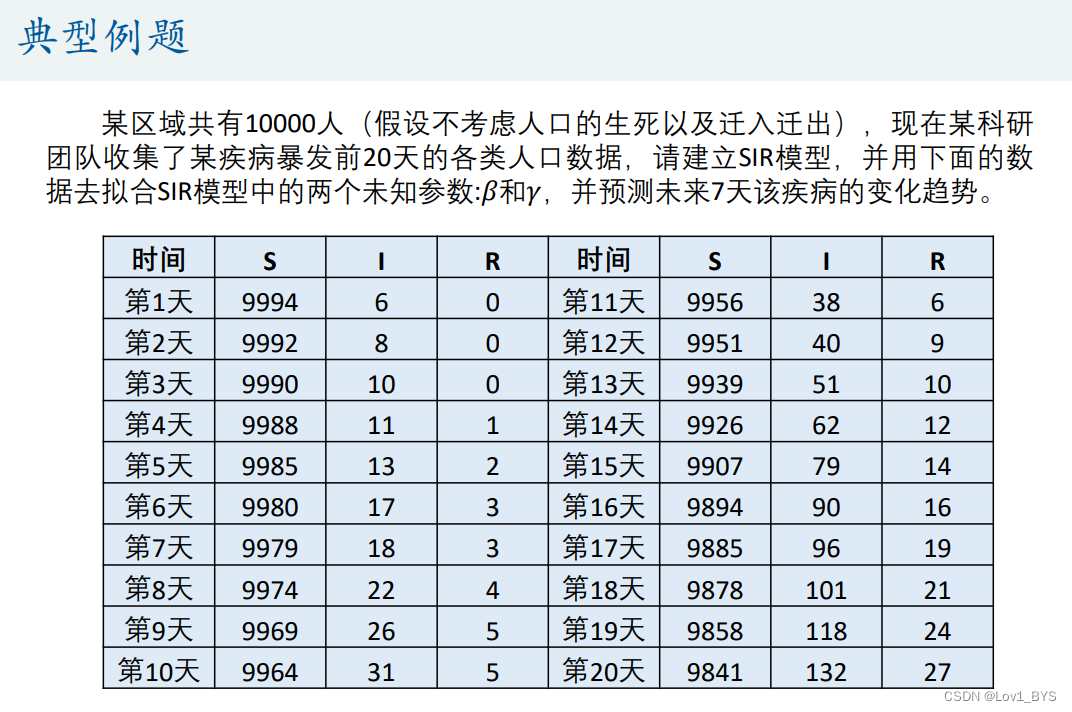
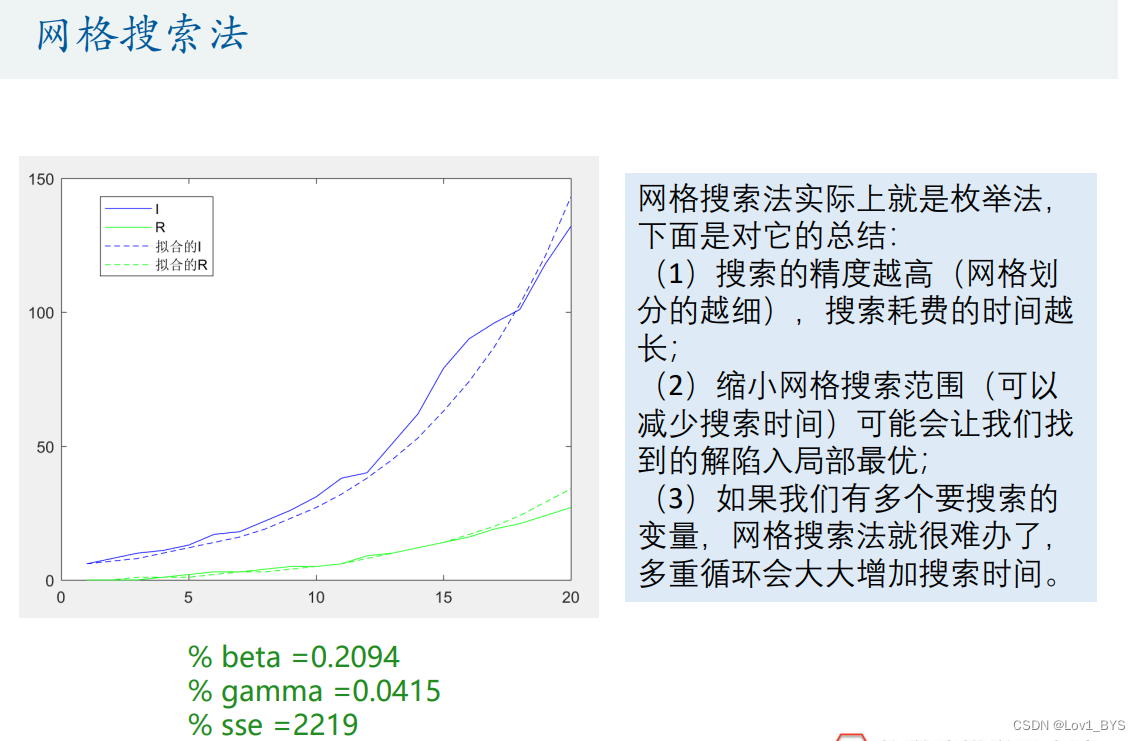
- 网格搜索法(枚举法)
% SIR模型
clear;clc
load mydata.mat % 导入数据(共三列,分别是S,I,R的数量)
n = size(mydata,1); % 一共有多少行数据
true_s = mydata(:,1);
true_i = mydata(:,2);
true_r = mydata(:,3);
figure(1)
plot(1:n,true_s,'r-',1:n,true_i,'b-',1:n,true_r,'g-') % S的数量太大了
legend('S','I','R')
plot(1:n,true_i,'b-',1:n,true_r,'g-') % 单独画出真实的I和R的数量
hold on % 等会接着在这个图形上面画图
% 随便先给一组参数来计算微分方程的数值解
beta = 0.1; % 易感染者与已感染者接触且被传染的强度
gamma = 0.01; % 康复率
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]);
% p就是计算的数值解,它有三列,分别是S I R的数量
p = round(p); % 对p进行四舍五入(人数为整数)
% 注意,四舍五入后有可能出现总人数之和不为10000的情况,例如为9999或10001,但是这种误差可以忽略不计。
plot(1:n,p(:,2),'b--',1:n,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')
hold off % 和hold on对应
% 计算残差平方和
sse = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2)
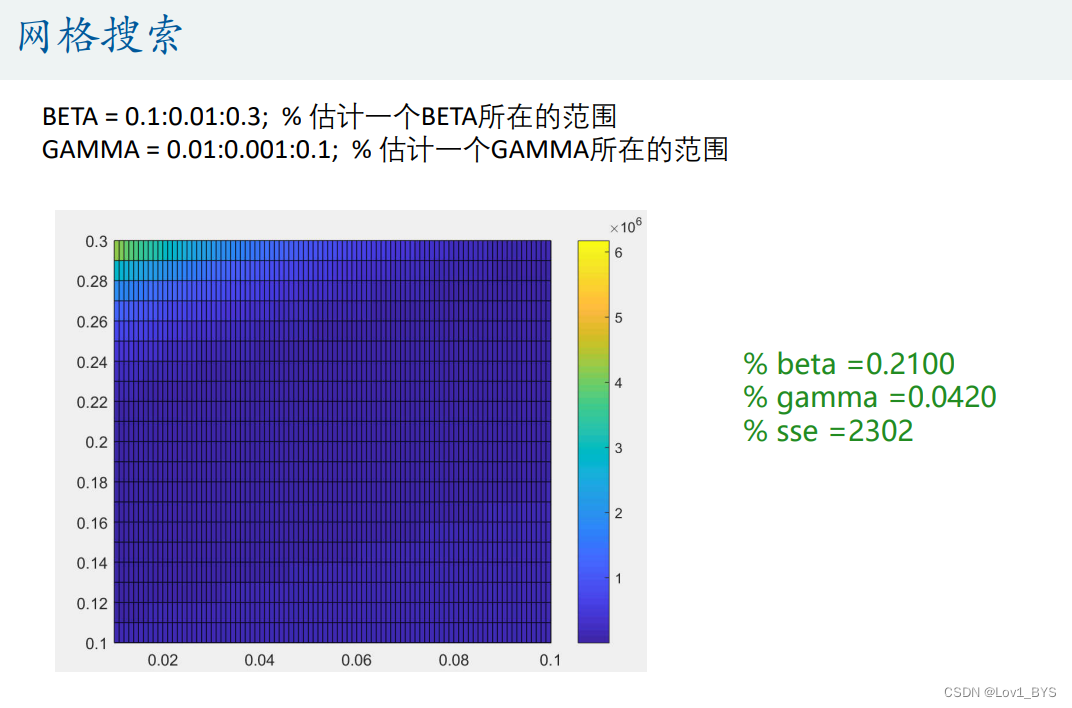
%% 网格法搜索(枚举法) 地毯式搜索
BETA = 0.1:0.01:0.3; % 估计一个BETA所在的范围
GAMMA = 0.01:0.001:0.1; % 估计一个GAMMA所在的范围
n1 = length(BETA);
n2 = length(GAMMA);
SSE = zeros(n1,n2); % 初始化残差平方和矩阵
for i = 1:n1
for j = 1:n2
beta = BETA(i);
gamma = GAMMA(j);
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]);
% p就是计算的数值解,它有三列,分别是S I R的数量
p = round(p); % 对p进行四舍五入(人数为整数)
% 计算残差平方和
sse = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2);
SSE(i,j) = sse;
end
end
% 画出SSE这个矩阵的热力图,放到论文中显得高大上
figure(2)
pcolor(GAMMA,BETA,SSE) % 注意,这里GAMMA和BETA的顺序不能反了(类似于更新13里面的mesh函数的用法)
colorbar % 加上颜色条
% 找到sse最小的那组参数
min_sse = min(min(SSE)); % 注意,min(SSE)是找出每一列的最小值,因此我们还需要再使用一次min函数才能找到整个矩阵里面的最小值
[r,c] = find(SSE == min_sse,1); % find后面加了一个1,表示返回第一个最小值所在的行和列的序号
beta = BETA(r)
gamma = GAMMA(c)
figure(3)
plot(1:n,true_i,'b-',1:n,true_r,'g-') % 单独画出真实的I和R的数量
hold on
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]);
% p就是计算的数值解,它有三列,分别是S I R的数量
p = round(p); % 对p进行四舍五入(人数为整数)
plot(1:n,p(:,2),'b--',1:n,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')
hold off
% 计算残差平方和
sse = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2)
% beta =0.2100
% gamma =0.0420
% sse =2302
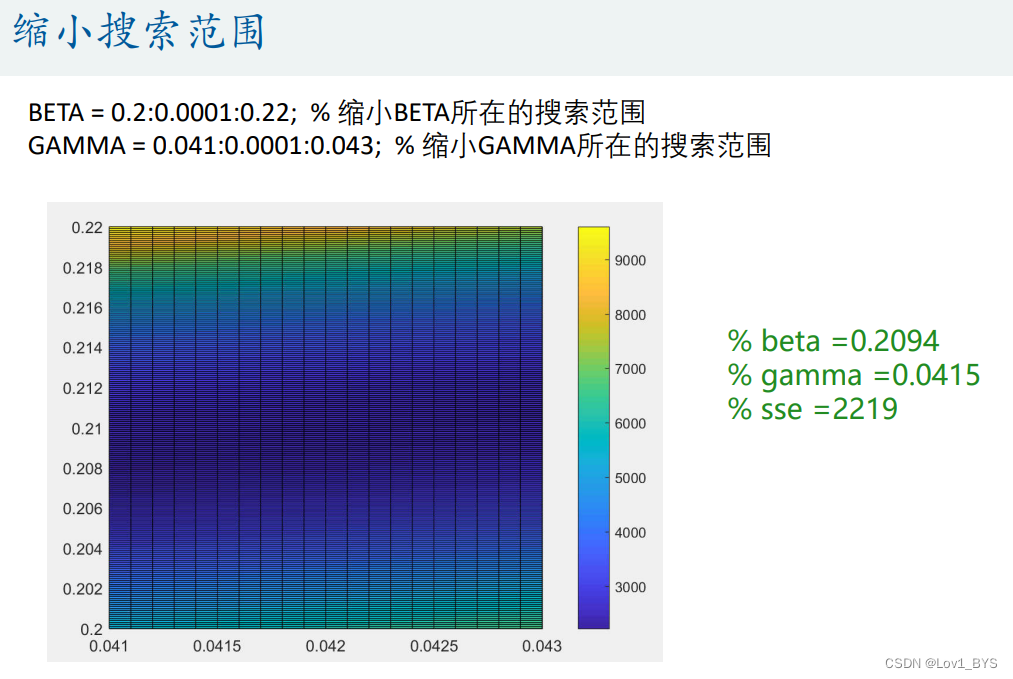
%% 思考:能不能再让这个找到的结果更好点?
BETA = 0.2:0.0001:0.22; % 缩小BETA所在的搜索范围
GAMMA = 0.041:0.0001:0.043; % 缩小GAMMA所在的搜索范围
% 这样可能会陷入局部最优解!
% beta =0.2094
% gamma =0.0415
% sse =2219
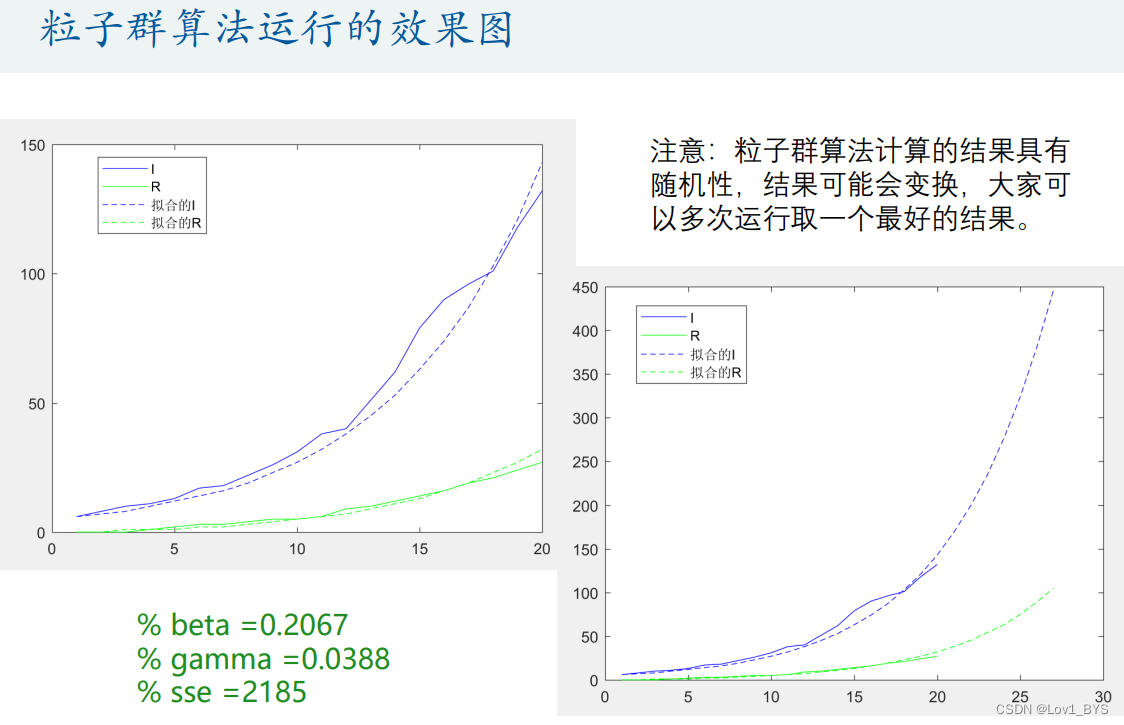
% 粒子群算法,得到的结果为:
% beta =0.2067
% gamma =0.0388
% sse =2185
% 总结:
% 搜索的精度越高(网格划分的越细),搜索耗费的时间越长
% 如果缩小网格搜索范围(可以减少搜索时间)可能会让我们找到的解陷入局部最优
% 另外,如果我们有多个要搜索的变量,网格搜索法就很难办了,多重循环会大大增加搜索时间!
% 被调用的函数:SIR_fun
function dx=SIR_fun(t,x,beta,gamma)
% beta: 易感染者与已感染者接触且被传染的强度
% gamma: 康复率
dx = zeros(3,1); % x(1)表示S x(2)表示I x(3)表示R
C = x(1)+x(2); % 传染病系统中的有效人群,也就是课件中的N' = S+I
dx(1) = - beta*x(1)*x(2)/C;
dx(2) = beta*x(1)*x(2)/C - gamma*x(2);
dx(3) = gamma*x(2);
end
- 粒子群算法
% 粒子群算法求解参数
clear;clc
load mydata.mat % 导入数据(共三列,分别是S,I,R的数量)
global true_s true_i true_r n % 定义全局变量
n = size(mydata,1); % 一共有多少行数据
true_s = mydata(:,1);
true_i = mydata(:,2);
true_r = mydata(:,3);
figure(1)
% plot(1:n,true_s,'r-',1:n,true_i,'b-',1:n,true_r,'g-') % S的数量太大了
% legend('S','I','R')
plot(1:n,true_i,'b-',1:n,true_r,'g-') % 单独画出I和R的数量
legend('I','R')
% 粒子群算法来求解
lb = [0 0];
ub = [1 1]; % Display展示迭代过程 % SwarmSize 100 粒子群个数 越大准确度越高 % PlotFcn 绘制出 最优适应度的变化图
options = optimoptions('particleswarm','Display','iter','SwarmSize',100,'PlotFcn','pswplotbestf');
[h, fval] = particleswarm(@Obj_fun,2,lb,ub,options) % h就是要优化的参数,fval是目标函数值 (数字2代表两个参数)
% options = optimoptions('particleswarm','SwarmSize',100,'FunctionTolerance',1e-12,'MaxStallIterations',100,'MaxIterations',100000);
% [h, fval] = particleswarm(@Obj_fun,2,lb,ub,options) % h就是要优化的参数,fval是目标函数值
beta = h(1); % 易感染者与已感染者接触且被传染的强度
gamma = h(2); % 康复率
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)
sse = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2) % 计算残差平方和
figure(3) % 真实的人数和拟合的人数放到一起看看
plot(1:n,true_i,'b-',1:n,true_r,'g-')
hold on
plot(1:n,p(:,2),'b--',1:n,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')
%% 预测未来的趋势
N = 27; % 计算N天
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:N],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)
figure(4)
plot(1:n,true_i,'b-',1:n,true_r,'g-')
hold on
plot(1:N,p(:,2),'b--',1:N,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')
%被调用的函数 SIR_fun
function dx=SIR_fun(t,x,beta,gamma)
% beta: 易感染者与已感染者接触且被传染的强度
% gamma: 康复率
dx = zeros(3,1); % x(1)表示S x(2)表示I x(3)表示R
C = x(1)+x(2); % 传染病系统中的有效人群,也就是课件中的N' = S+I
dx(1) = - beta*x(1)*x(2)/C;
dx(2) = beta*x(1)*x(2)/C - gamma*x(2);
dx(3) = gamma*x(2);
end
%被调用的函数 Obj_fun
function f = Obj_fun(h)
% 注意,h就是我们要估计的目标函数里面的参数
% h的长度就是我们待估参数的个数
global true_s true_i true_r n % 在子函数中使用全局变量前也需要声明下
beta = h(1); % 易感染者与已感染者接触且被传染的强度
gamma = h(2); % 康复率
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)
% p的第一列是易感染者S的数量,p的第二列是患者I的数量,p的第三列是康复者R的数量
f = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2);
end

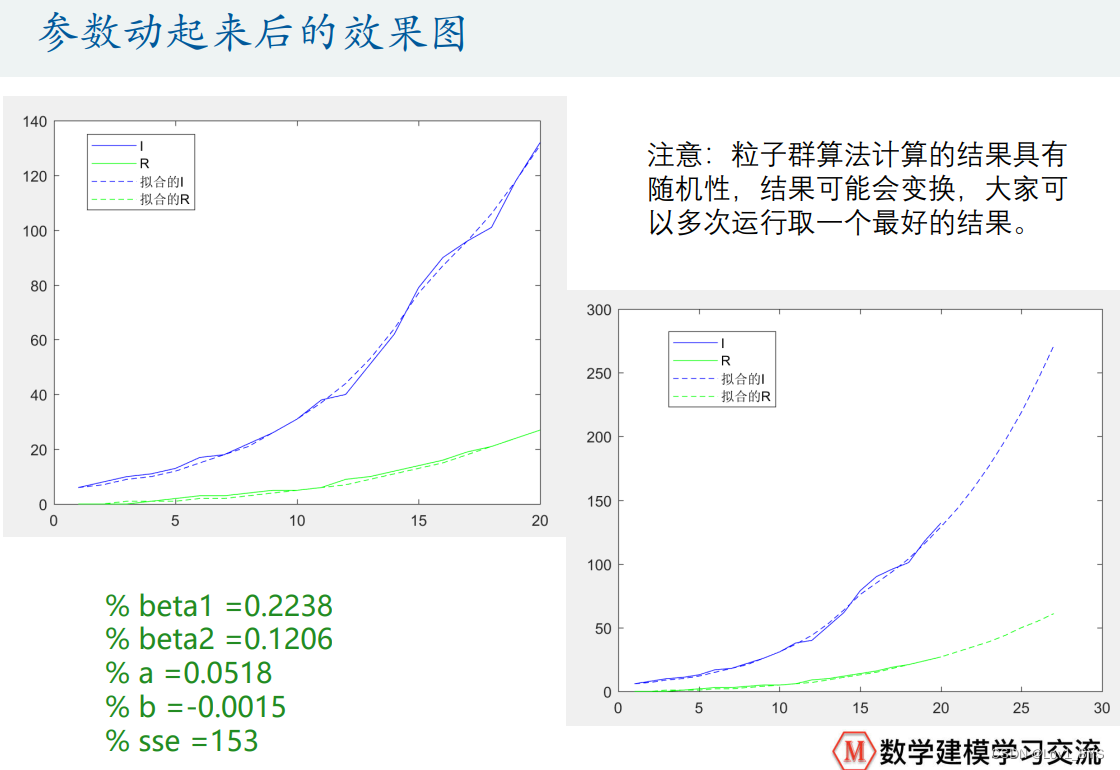
- 参数的定义式不要太复杂,容易过拟合
% 动态参数的粒子群算法
clear;clc
load mydata.mat % 导入数据(共三列,分别是S,I,R的数量)
global true_s true_i true_r n % 定义全局变量
n = size(mydata,1); % 一共有多少行数据
true_s = mydata(:,1);
true_i = mydata(:,2);
true_r = mydata(:,3);
figure(1)
plot(1:n,true_i,'b-',1:n,true_r,'g-') % 单独画出I和R的数量
legend('I','R')
% 粒子群算法来求解
% beta1,beta2,a,b
% 给定参数的搜索范围(根据题目来给),后期可缩小范围
lb = [0 0 -1 -1];
ub = [1 1 1 1];
% lb = [0 0 -0.2 -0.2];
% ub = [0.3 0.3 0.2 0.2];
options = optimoptions('particleswarm','Display','iter','SwarmSize',200);
[h, fval] = particleswarm(@Obj_fun, 4, lb, ub, options) % h就是要优化的参数,fval是目标函数值, 第二个输入参数4代表我们有4个变量需要搜索
beta1 = h(1); % t<=15时,易感染者与已感染者接触且被传染的强度
beta2 = h(2); % t>15时,易感染者与已感染者接触且被传染的强度
a = h(3); % 康复率gamma = a+bt
b = h(4); % 康复率gamma = a+bt
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta1,beta2,a,b), [1:n],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)
figure(3) % 真实的人数和拟合的人数放到一起看看
plot(1:n,true_i,'b-',1:n,true_r,'g-')
hold on
plot(1:n,p(:,2),'b--',1:n,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')
% 预测未来的趋势
N = 27; % 计算N天
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta1,beta2,a,b), [1:N],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)
figure(4)
plot(1:n,true_i,'b-',1:n,true_r,'g-')
hold on
plot(1:N,p(:,2),'b--',1:N,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')
% 被调用的函数 SIR_fun
function dx=SIR_fun(t,x,beta1,beta2,a,b)
% beta1 : t<=15时,易感染者与已感染者接触且被传染的强度
% beta2 : t>15时,易感染者与已感染者接触且被传染的强度
% a : 康复率gamma = a+bt
% b : 康复率gamma = a+bt
if t <=15
beta = beta1;
else
beta = beta2;
end
gamma = a + b * t;
dx = zeros(3,1); % x(1)表示S x(2)表示I x(3)表示R
C = x(1)+x(2); % 传染病系统中的有效人群,也就是课件中的N' = S+I
dx(1) = - beta*x(1)*x(2)/C;
dx(2) = beta*x(1)*x(2)/C - gamma*x(2);
dx(3) = gamma*x(2);
end
% 被调用的函数 Obj_fun
function f = Obj_fun(h)
% 注意,h就是我们要估计的目标函数里面的参数
% h的长度就是我们待估参数的个数
global true_s true_i true_r n % 在子函数中使用全局变量前也需要声明下
beta1 = h(1); % t<=15时,易感染者与已感染者接触且被传染的强度
beta2 = h(2); % t>15时,易感染者与已感染者接触且被传染的强度
a = h(3); % 康复率gamma = a+bt
b = h(4); % 康复率gamma = a+bt
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta1,beta2,a,b) , [1:n],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)
% p的第一列是易感染者S的数量,p的第二列是患者I的数量,p的第三列是康复者R的数量
f = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2);
end
















 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











