






TF-IDF算法概述
TF-IDF(Term Frequency-Inverse Document Frequency)算法主要用于文本特征提取和文档相似度计算,其作用是衡量一个词语在文档中的重要程度。TF-IDF算法的主要原理是结合词频和逆文档频率两个因素,从而对文本数据进行特征提取和特征表示。
具体来说,TF(词频)指的是某个词在文档中出现的频率。词频越高,表示该词在文档中越重要。但是,有些常见词汇在多个文档中均会出现,例如中文中的:“这”,“我”,“是”等等,因此不能单纯以词频来衡量词的重要性。这时引入逆文档频率(IDF)来衡量包含该词的文档数量,逆文档频率的计算方式是总文档数除以包含该词的文档数,然后取对数。根据对数的性质我们知道,逆文档频率越高,表示该词在整个文档集合中的重要性越高。
TF-IDF的计算方法是将TF和IDF相乘,得到一个综合的词语权重。通过计算每个词的TF-IDF值,文本数据就可以表示为词语与其权重组成的稀疏向量,每个元素代表一个词在文档中的重要程度。
数学公式
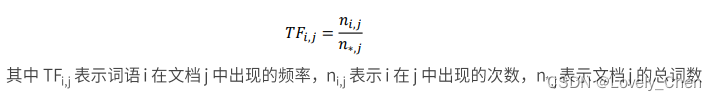
TF的公式

TF-IDF算法的主要用途
1:特征提取:将文本数据转换为特征向量表示,便于机器学习算法进行处理。
2:特征筛选:通过计算词的TF-IDF值,可以找到文本中重要的关键词,帮助理解文本内容。
3:文本分类和聚类:基于TF-IDF特征向量可以进行文本分类和聚类任务。
相似度计算:通过计算文档之间的TF-IDF相似度,可以衡量文档之间的相似程度。
用python模拟实现TF-IDF算法原理
第一步导入需要的包和定义两个简单文档,并进行分割
import numpy as np
import pandas as pd
docA="I love coding with cpp"
docB="I love coding with java"
bowA=docA.split(" ")
bowB=docB.split(" ")
第二步对两个文档进行合并,并进行初始化与统计
wordSet=set(bowA).union(bowB)
wordDirectA=dict.fromkeys(wordSet,0)
wordDirectB=dict.fromkeys(wordSet,0)
for word in bowA:
wordDirectA[word]+=1
for word in bowB:
wordDirectB[word]+=1
wordSet=set(bowA).union(bowB): 首先将文档A和文档B中的所有单词放入一个集合wordSet中,这样可以得到文档A和文档B中出现的所有唯一单词。
wordDirectA=dict.fromkeys(wordSet,0), wordDirectB=dict.fromkeys(wordSet,0): 分别创建两个字典wordDirectA和wordDirectB,其中字典的键为wordSet中的单词,初始值都设置为0。
for word in bowA: wordDirectA[word]+=1: 遍历文档A中的每个单词,对于每个单词,将其在wordDirectA字典中对应的计数值加1。这样就统计了文档A中每个单词的出现次数。
for word in bowB: wordDirectB[word]+=1: 同样地,遍历文档B中的每个单词,对于每个单词,将其在wordDirectB字典中对应的计数值加1。这样就统计了文档B中每个单词的出现次数。
通过这段代码,我们可以得到文档A和文档B中每个单词的出现次数统计,将其表示为字典形式。
第三步计算TF
def computeTF(wordDict,bow):
tfDict={}
nbowCount=len(bow)
for word,count in wordDict.items():
tfDict[word]=count/nbowCount
return tfDict
tfA=computeTF(wordDirectA,bowA)
tfB=computeTF(wordDirectB,bowB)
def computeTF(wordDict,bow):: 定义了一个名为computeTF的函数,该函数接受两个参数:wordDict表示存储单词计数的字典,bow表示文档的单词列表。
tfDict={}: 创建一个空字典tfDict,用于存储计算出的TF值。
nbowCount=len(bow): 计算文档中单词的总数,即文档长度。
for word,count in wordDict.items():: 遍历wordDict字典中的单词和计数项。
tfDict[word]=count/nbowCount: 计算每个单词的TF值,即该单词在文档中出现的次数除以文档的总单词数。
return tfDict: 返回包含每个单词TF值的字典tfDict。
tfA=computeTF(wordDirectA,bowA), tfB=computeTF(wordDirectB,bowB): 调用computeTF函数分别计算文档A和文档B中每个单词的TF值,得到TF值字典tfA和tfB。
通过这段代码,我们可以计算文档中每个单词的TF值,从而评估单词在文档中的重要性。
第四步计算IDF
def computeIDF(wordDictList):
idDict=dict.fromkeys(wordDictList[0],0)
N=len(wordDictList)
import math
for wordDict in wordDictList:
for word,count in wordDict.items():
if count>0:
idDict[word]+=1
for word,ni in idDict.items():
idDict[word]=math.log10((N+1)/(ni+1))
return idDict
idfs=computeIDF([wordDirectA,wordDirectB])
def computeIDF(wordDictList):: 定义了一个名为computeIDF的函数,该函数接受一个参数wordDictList,该参数是包含文档单词计数字典的列表。
idDict=dict.fromkeys(wordDictList[0],0): 创建一个初始值为0的字典idDict,字典的键为第一个文档的单词,用于存储计算出的IDF值。
N=len(wordDictList): 获取文档集合的总数N。
import math: 导入math库,用于进行数学运算。
遍历wordDictList列表中的每个文档单词计数字典:
for wordDict in wordDictList:
再遍历每个单词及其计数项:
for word,count in wordDict.items():
如果单词在当前文档中出现次数大于0,则将该单词在idDict中的计数加1。
接着计算每个单词的IDF值:
for word,ni in idDict.items():
计算公式是:IDF = log10((N + 1) / (ni + 1)),其中N表示文档集合总数,ni表示包含该单词的文档数量。
这里的加1是为了避免分母为0的情况,同时也避免某个单词在所有文档中都出现的极端情况。
return idDict: 返回包含每个单词IDF值的字典idDict。
idfs=computeIDF([wordDirectA,wordDirectB]): 调用computeIDF函数计算文档集合中每个单词的IDF值,得到一个包含所有单词IDF值的字典idfs。
通过这段代码,我们可以计算文档集合中每个单词的IDF值,判断某个词是否是停用词,进而用于计算TF-IDF值,并衡量单词的重要性。
第五步计算TF-IDF
def computeTFIDF(tf,idfs):
tfidf={}
for word,tfval in tf.items():
tfidf[word]=tfval*idfs[word]
return tfidf
def computeTFIDF(tf,idfs):: 定义了一个名为computeTFIDF的函数,该函数接受两个参数tf和idfs,分别表示某个文档中每个单词的TF值和整个文档集合中每个单词的IDF值。
tfidf={}: 创建一个空字典tfidf,用于存储计算出的TF-IDF值。
for word,tfval in tf.items():: 遍历TF值字典tf中的每个单词和对应的TF值。
tfidf[word]=tfval*idfs[word]: 计算每个单词的TF-IDF值,即将该单词的TF值乘以其对应的IDF值,得到综合的TF-IDF值。
return tfidf: 返回包含每个单词TF-IDF值的字典tfidf。
通过这段代码,我们可以通过TF和IDF值的结合,计算出单词的TF-IDF值,进而衡量单词在文档中和整个文档集合中的重要性。
第六步调用以及结果输出
def computeTFIDF(tf,idfs):
tfidf={}
for word,tfval in tf.items():
tfidf[word]=tfval*idfs[word]
return tfidf
tfidfA=computeTFIDF(tfA,idfs)
tfidB=computeTFIDF(tfB,idfs)
df2=pd.DataFrame([tfidfA,tfidB])
df3=df2[df2>0].dropna(axis=1,how="all")
print(df3)
tfidfA=computeTFIDF(tfA,idfs): 调用computeTFIDF函数计算文档A中每个单词的TF-IDF值,将结果存储在tfidfA字典中。
tfidfB=computeTFIDF(tfB,idfs): 类似地,计算文档B中每个单词的TF-IDF值,将结果存储在tfidfB字典中。
df2=pd.DataFrame([tfidfA,tfidfB]): 创建一个数据框df2,该数据框包含了两个文档的TF-IDF值,其中每行代表一个文档,每列代表一个单词的TF-IDF值。
df3=df2[df2>0].dropna(axis=1,how=“all”): 对数据框df2进行处理,将值大于0的单元格保留,然后删除全为NaN的列,得到一个新的数据框df3。这一步通常用于过滤出重要的单词,并去除控制单词。
print(df3): 最后打印输出经过处理后的数据框df3,展示了两个文档中重要单词的TF-IDF值。
结果展示
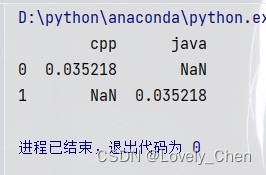
我们可以看到它分析出两个关键词,cpp和java,值都是0.035218
结合我们一开始文本我们可以发现:两个文本中都有的I love coding with这几个词都被屏蔽掉了
实战中应用
这个算法在许多计算框架中都有现成的方法可以调用
例如在sparkmllib中就有这样的方法
from pyspark import SparkContext
from pyspark.mllib.feature import HashingTF, IDF
from pyspark.mllib.linalg import Vectors
# 创建SparkContext
sc = SparkContext("local", "TF-IDF Example")
# 假设我们有一个包含文本内容的RDD
documents = sc.parallelize(["hello world", "world foo", "hello foo"])
# 通过HashingTF计算TF
tf = HashingTF(numFeatures=10000)
tf_vectors = tf.transform(documents.map(lambda x: x.split()))
# 计算IDF
idf = IDF().fit(tf_vectors)
tfidf_vectors = idf.transform(tf_vectors)
# 打印TF-IDF结果
for i, vector in enumerate(tfidf_vectors.collect()):
print("Document %d: %s" % (i + 1, vector))
from pyspark import SparkContext: 导入SparkContext,用于创建和管理Spark应用程序的主要入口点。
from pyspark.mllib.feature import HashingTF, IDF: 导入HashingTF和IDF类,用于计算TF(词频)和IDF(逆文档频率)。
from pyspark.mllib.linalg import Vectors: 导入Vectors类,用于处理向量数据。
sc = SparkContext(“local”, “TF-IDF Example”): 创建一个本地SparkContext,"local"表示在本地模式下运行Spark应用程序,"TF-IDF Example"是应用程序的名称。
documents = sc.parallelize([“hello world”, “world foo”, “hello foo”]): 假设我们有一个包含文本内容的RDD,将文本内容分布在几个分区中。
tf = HashingTF(numFeatures=10000): 创建一个HashingTF对象,指定特征数量为10000用于计算TF。
tf_vectors = tf.transform(documents.map(lambda x: x.split())): 使用HashingTF计算TF值,将每个文档拆分成单词后传递给transform方法。
idf = IDF().fit(tf_vectors): 创建一个IDF对象,并使用fit方法适应TF向量以计算IDF。
tfidf_vectors = idf.transform(tf_vectors): 计算TF-IDF向量,将TF向量传递给IDF对象的transform方法。
for i, vector in enumerate(tfidf_vectors.collect()):: 遍历计算得到的TF-IDF向量并打印。
print(“Document %d: %s” % (i + 1, vector)): 打印每个文档的序号和对应的TF-IDF向量值。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









