






本篇主要是介绍vllm的核心引擎逻辑
vllm核心引擎逻辑图
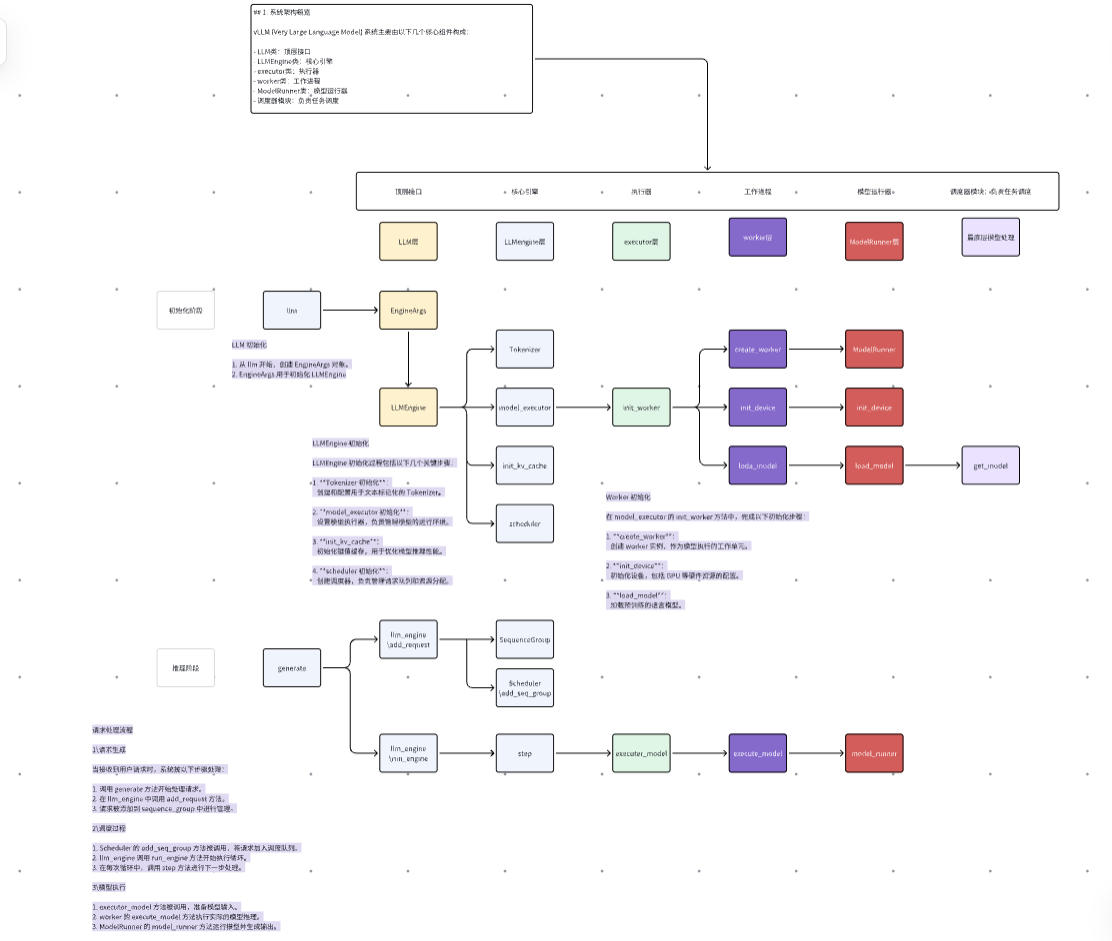
核心流程文字解释(带详细地址)
核心流程文字解释(带详细地址)
# vLLM 工作流程与代码位置详解
## 1. 系统架构概览
vLLM的核心组件及其代码位置:
- LLM类: `vllm/v1/engine/llm_engine.py`
- LLMEngine类: `vllm/v1/engine/core.py`
- Executor类: `vllm/v1/executor/abstract.py`
- Worker相关: `vllm/worker/`
- ModelRunner: `vllm/model_executor/`
- 调度器: `vllm/core/scheduler.py`
## 2. 初始化流程
### 2.1 LLM 初始化
位置:`vllm/v1/engine/llm_engine.py`
```python
class LLMEngine:
def __init__(self, vllm_config: VllmConfig, executor_class: type[Executor], ...):
# 配置初始化
self.vllm_config = vllm_config
self.model_config = vllm_config.model_config
self.cache_config = vllm_config.cache_config
```
### 2.2 Engine初始化流程
1. **Tokenizer 初始化**
位置:`vllm/v1/engine/llm_engine.py`
```python
# Line ~70
self.tokenizer = init_tokenizer_from_configs(
model_config=vllm_config.model_config,
scheduler_config=vllm_config.scheduler_config,
parallel_config=vllm_config.parallel_config,
lora_config=vllm_config.lora_config
)
```
2. **Processor 初始化**
位置:`vllm/v1/engine/llm_engine.py`
```python
# Line ~80
self.processor = Processor(
vllm_config=vllm_config,
tokenizer=self.tokenizer,
mm_registry=mm_registry
)
```
3. **OutputProcessor 初始化**
位置:`vllm/v1/engine/llm_engine.py`
```python
# Line ~85
self.output_processor = OutputProcessor(
self.tokenizer,
log_stats=False
)
```
4. **EngineCore 初始化**
位置:`vllm/v1/engine/core.py`
```python
class EngineCore:
def __init__(self, vllm_config, executor_class, log_stats):
self.model_executor = executor_class(vllm_config)
self._initialize_kv_caches(vllm_config)
self.scheduler = Scheduler(...)
```
## 3. 请求处理流程
### 3.1 请求生成
位置:`vllm/v1/engine/llm_engine.py`
```python
def add_request(self, request_id: str, prompt: PromptType, params: Union[SamplingParams, PoolingParams], ...):
# 处理输入
request = self.processor.process_inputs(
request_id, prompt, params,
arrival_time, lora_request,
trace_headers,
prompt_adapter_request,
priority
)
```
### 3.2 调度过程
位置:`vllm/core/scheduler.py`
```python
class Scheduler:
def schedule(self):
# 选择要处理的序列
scheduled_seq_groups = self._schedule()
# 创建批处理
return self._prepare_batch(scheduled_seq_groups)
```
### 3.3 执行过程
位置:`vllm/v1/executor/abstract.py`
```python
class Executor:
def execute_model(self, batch_group):
# 执行模型推理
return self._execute_model_with_cache(batch_group)
```
## 4. 关键组件实现位置
### 4.1 LLMEngine
位置:`vllm/v1/engine/llm_engine.py`
核心方法:
- `__init__`: 初始化引擎 (~Line 40)
- `add_request`: 添加新请求 (~Line 150)
- `step`: 执行一步推理 (~Line 200)
### 4.2 Executor
位置:`vllm/v1/executor/abstract.py`
主要实现:
- `UniProcExecutor`: 单进程执行器
- `MultiprocExecutor`: 多进程执行器
- `RayDistributedExecutor`: 分布式执行器
### 4.3 Worker
位置:`vllm/worker/worker.py`
关键方法:
- `create_worker`: 创建worker实例
- `init_device`: 初始化设备
- `load_model`: 加载模型
### 4.4 ModelRunner
位置:`vllm/model_executor/model_runner.py`
核心功能:
- 模型加载和初始化
- 批处理执行
- 缓存管理
## 5. 性能优化实现
### 5.1 KV Cache实现
位置:`vllm/core/block_manager.py`
```python
class BlockManager:
def __init__(self, block_size, num_blocks):
self.block_size = block_size
self.num_blocks = num_blocks
```
### 5.2 批处理优化
位置:`vllm/core/scheduler.py`
```python
class Scheduler:
def _prepare_batch(self, scheduled_seq_groups):
# 根据资源和请求动态调整批大小
batch_size = self._calculate_batch_size(...)
```
## 6. 调用链路示例
以处理一个新请求为例,完整的调用链路:
1. 入口点:`vllm/v1/engine/llm_engine.py:add_request()`
2. 请求处理:`vllm/v1/engine/processor.py:process_inputs()`
3. 调度安排:`vllm/core/scheduler.py:schedule()`
4. 执行准备:`vllm/v1/executor/abstract.py:prepare_batch()`
5. 模型执行:`vllm/model_executor/model_runner.py:execute_batch()`
6. 输出处理:`vllm/v1/engine/output_processor.py:process_outputs()`
## 7. 错误处理实现
### 7.1 请求错误处理
位置:`vllm/v1/engine/llm_engine.py`
```python
def abort_request(self, request_ids: list[str]) -> None:
request_ids = self.output_processor.abort_requests(request_ids)
self.engine_core.abort_requests(request_ids)
```
### 7.2 执行错误处理
位置:`vllm/v1/executor/abstract.py`
```python
def execute_model(self, *args, **kwargs):
try:
return self._execute_model_with_cache(*args, **kwargs)
except Exception as e:
self._handle_execution_error(e)
```
## 8. 总结
1. `vllm/v1/engine/` 目录包含核心引擎实现
2. `vllm/v1/executor/` 目录包含执行器实现
3. `vllm/core/` 目录包含基础组件
4. `vllm/worker/` 目录包含工作进程实现
5. `vllm/model_executor/` 目录包含模型执行相关代码
kvcache和lmcache详细后续文章解释
KVCache
作用:在 Transformer 模型(如 GPT)中缓存注意力层的 Key 和 Value 矩阵。
原理:生成文本时,每次解码只计算当前 token 的 Key/Value,避免重复计算历史 token 的数据。
优势:大幅提升长文本生成效率(例如对话或长文章),减少内存和计算开销。
LMCache
作用:缓存语言模型(LM)生成过程中的中间结果(如历史 token 或上下文)。
原理:在生成重复内容(如常见短语)时,直接复用缓存结果,跳过重复计算。
优势:加速高频重复内容的生成(例如代码、公式),降低响应延迟。

















 3516
3516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









