






Abstract
现有的多源无监督域自适应(UDA)方法大多依赖于一个共同的特征提取器来提取域不变特征。然而,学习这样的提取器涉及更新整个网络的参数,特别是当与min-max目标相结合时,使得优化的计算代价很高。
受prompt learning的最新进展的启发,作者引入了多prompt对齐(Multi-Prompt Alignment),一种简单高效的多源UDA的两阶段框架:
给定源和目标域对,MPA首先训练个人Prompt,通过少量参数,利用对比学习损失将域间差异降至最小。然后,MPA通过最大化多个可学习Prompt的一致性的来获得低维潜在空间,由此促进了对未知域的概括。

Introduction
更具体地说,对于第一阶段,在给定源域和目标域的情况下,我们使用CLIP作为我们的骨干,并为这样的一对儿学习其特定的prompt。然后,我们在低维Di的潜在空间中对齐所有学习到的prompt。这是通过一个简单的具有重建损耗的自动编码网络实现的。
此外,我们加入了L1损失,以便重建的prompt与目标图像的分类一致。这对于提示处理目标数据位于决策边界附近的情况是有益的。
更重要的是,由于潜在空间是通过来自多个源域的提示来优化的,它编码了不同域共享的知识,并可能通过遍历该空间而推广到不可见的域。
主要贡献:
1、针对多源UDA,我们引入了多prompt对齐算法(MPA)。MPA利用prompt learning的优势,因此与其他方法相比,大大减少了训练所需的参数量。
2、MPA通过最大化多个学习的prompt的一致性来学习潜在的embedding空间,由此产生的低维嵌入有助于轻松适应新的未知域。
3、在大规模DomainNet数据集上,MPA达到了SOTA。
Related work
什么是prompt?
通过在输入文本中预先添加指令,预训练好的大规模语言模型可以在只需少量甚至没有样本的情况下处理广泛的下游任务,这样的指令文本被称为prompt。
因此,可以调整prompt而不是整个网络,以便更有效地适应下游任务。最初,prompt本质上是映射到嵌入空间的手动设计的语言tokens。到目前为止,广泛的研究已经证明,训练soft prompt,即通过深度神经网络模型学习的带有自己参数的prompt会更有效。
Method
在我们的工作中,我们不使用手动制作的prompt,而是训练直接由文本编码器嵌入的soft prompt。给定k类∈{1,2,...,K}的图像x和每个类别的文本嵌入wk,CLIP以对比学习的方式将它们对齐:

当输入图像x确实属于类别k时,上式被最大化。这里<··>表示余弦相似性,而T是learnable temperature parameter.。
设N表示域的总数,其中前N−1个域是源域,第N个域是目标域。对于所有N个−1源域,都提供了图像及其标签,而对于目标域,我们只假定可以访问它们的图像,即UDA。我们希望学习一个域不变的潜在空间,以便最小化不同源域之间的域偏移以及所有源域和目标域对之间的差异。
作者利用prompt learning在不同领域之间进行比对。下面首先介绍prompt的设计,然后介绍多prompt对齐。最后,说明如何学习可以推广到不可见域的联合嵌入空间。
Prompt Design
作者设计了两组prompt:
1、class-specific context vectors 其中:i ∈ {1, 2, ..., M1长度}, k ∈ {1, 2, ..., K类别个数} ;
2、domain-specific vectors shared across all classes ,其中:j ∈ {1, 2, ..., M2}, d ∈ {s, t}。
每一个class prompt ∈ R:1×(M1+M2)×512 是一个“源prompt”和一个“目标prompt”的串联(即下面的一行,私以为应该是域无关和域相关的串联)。因此,每一对儿源-目标prompt可以被表示为:
![]()
这些prompt作为可学习的参数,其通过对比损失来帮助弥合源域和目标域之间的域差距。Pi如下图所示:

每个源-目标prompt对 Pi 是由域不变特征和域特定特征组成的"源prompt”片段和“目标prompt”片段的拼接。因此,PI的大小为R:2K×(M1+M2)×512(相当于2K个类别用于训练)。
Learning Individual Prompts
首先使用CLIP的图像-文本编码器为每个源和目标对训练单独的prompt。对于带标签的源域,训练其prompt使之对齐。对于没有标签的目标域,用CLIP生成伪标签(仅大于阈值t的图像生成伪标签),然后使用交叉熵损失函数来训练prompt。对于Pi,目标函数如下:
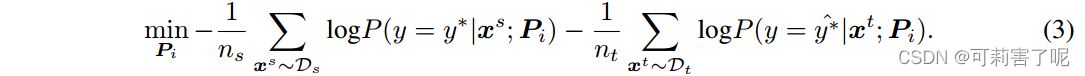
属于第k类的图像样本的概率P(·|xd;Pi)是从如下的对比损失产生的:
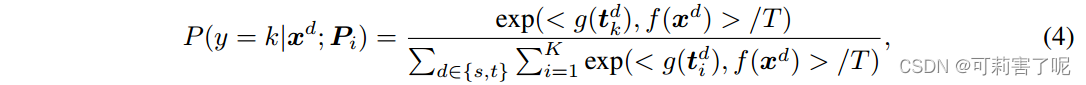
其中,d∈{s,t}是指示图像来自哪个域的标识符,T是可学习的temperature parameter,,并且 f 和 g 分别表示CLIP中的图像和文本编码器,它们在训练期间保持冻结。这种特定的设计可以推动prompts学习类不变和类特定语义信息的分离表示,以提高域适应方法的性能。
一旦学习到目标域的prompt,目标域图像 x 的预测标签可以被计算:

Multi-Prompt Alignment
到目前为止,我们已经获得了每个源-目标域对的prompts。然而,每个源域中的图像数量以及噪声水平各不相同,因此即使对于相同的图像,这些学习的提示也可能产生不一致的结果。
在第二阶段,我们的目标是对齐来自不同prompts的预测,更重要的是,我们希望找到一个域不变的潜在空间,使学习到的prompt中的噪声最小化,并有可能推广到未知域。为此,我们利用经过训练的自动编码器来重建学习到的prompts:
我们使用两个独立的自动编码器,每个由投影函数Proj(·)和反投影函数Projb(·)组成。首先通过投影函数Proj(·)将学习到的提示Pi投影到低维Di的潜在子空间中,然后通过反投影函数Projb(·)将向量投影回 soft prompts ˆPi。我们没有投影整个prompt,而是将Pi调整为只包含目标token的部分,并将其域特定和域无关的片段分别提供给两个自动编码器。我们假设,由于这两个特征向量用于不同的目的,使用两个独立的自动编码器将有助于对齐过程。
Proj(·)函数由一层前馈网络实现,而Projb(·)由两层非线性感知器实现:
![]()
我们优化以下重建损失:
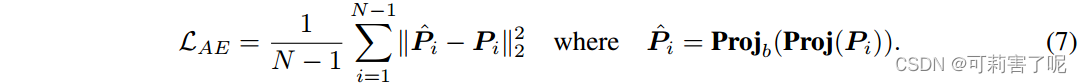
直观来说,人们会期望某个确定的目标域图像对于所有重建的提示ˆPi被归类为相同的类别。受此启发,我们通过在目标函数中引入额外的L1损失来对齐重建的prompt:
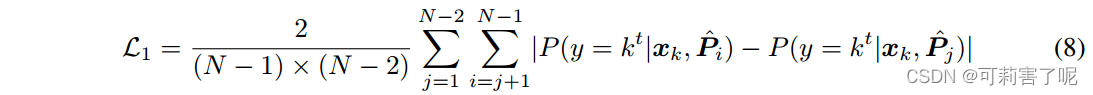
综上,损失函数现在变成:
![]()
Lcls是使用重构的提示ˆPI和静态伪标签计算的交叉熵损失,训练过程如下图,最后,为了预测目标样本的标签,我们使用每个ˆPI来计算输出Logit的平均值。

(A)首先将所有prompts切片为仅包含目标token段的大小R:K×(M1+M2)×512。然后,它们被进一步划分为域无关和域特定的片段,这些片段被投影到相同的潜在空间中,并由自动编码器结构对齐。
(B)自动编码器学习到的潜在子空间可用于推广到新的域。
















 1995
1995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









