







 超级会员免费看
超级会员免费看
 CoCoOp解决了CoOp在视觉语言模型中的泛化问题,通过引入一个轻量级的神经网络生成输入条件的提示,增强泛化能力和跨数据集迁移性能。与CoOp相比,CoCoOp在未知类别的泛化上表现更好,同时保持对基类别的识别能力。
CoCoOp解决了CoOp在视觉语言模型中的泛化问题,通过引入一个轻量级的神经网络生成输入条件的提示,增强泛化能力和跨数据集迁移性能。与CoOp相比,CoCoOp在未知类别的泛化上表现更好,同时保持对基类别的识别能力。
目录
Generalization from base to new classes within a dataset
Abstract
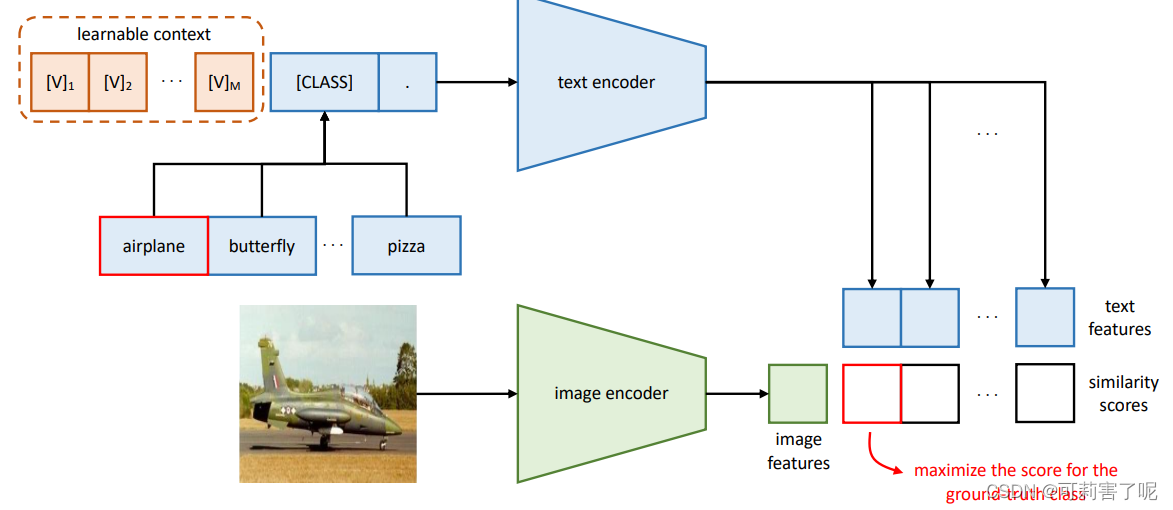
CoOp将prompt中的上下文单词转换为一组可学习的向量,并且只需少数标记的图像用于学习,就可以实现比密集调整的手动prompt更大的改进。
但是研究中发现了CoOp的一个问题:泛化性差,即学习的上下文向量不能推广到同一数据集中的未知类,这表明CoOp在训练时过拟合到了base classes。
为了解决这个问题,作者提出Conditional Context Optimization (CoCoOp)。CoCoOp在CoOp基础之上引入一个轻量级的神经网络为每张图像生成input-conditional tokens (vectors),这些tokens会加到原本CoOp中的learnable vectors上,从而可以学习到更泛化的prompt。
相比CoOp中静态的prompt,CoCoOP这种动态的prompt是能适应每个实例的(instance-adaptive),对于class shift更加鲁棒。实验表明对于未知类,CoCoOp的泛化性比CoOp好,甚至还展示了有潜力的单数据集迁移性。
Motivation
作者展示了一个例子来说明CoOp和CoCoOp对于未知类的结果对比:

CoOp 学习的上下文在区分训练期间见到过的基类时效果很好,但当它迁移到新的(未知)类时,例如“风力发电场”和“火车铁路”,尽管任务的性质(场景识别)保持不变,精度却会严重下降。
结果表明,CoOp在下游任务上训练时容易过拟合到 base classes上,因此无法捕获到更泛化,且对广泛场景识别重要的元素。CoOp的context 仅针对一组特定的类别上优化,而且在学习之后就固定了,一种简单的解决方法就是将CoOp中unified context,变成instance-adaptive context。这样对于每个样本都有一个特定的prompt,从而会让context 的聚焦从一组特定类别上,转移到每个样本的特征或者属性上,进而就减少了过拟合,对于class shift更加鲁棒。
Method
回顾CoOp:
CoCoOp由两个可学习的组件组成:一组上下文向量和一个轻量级神经网络(Meta-Net),它为每个图像生成一个输入条件token。
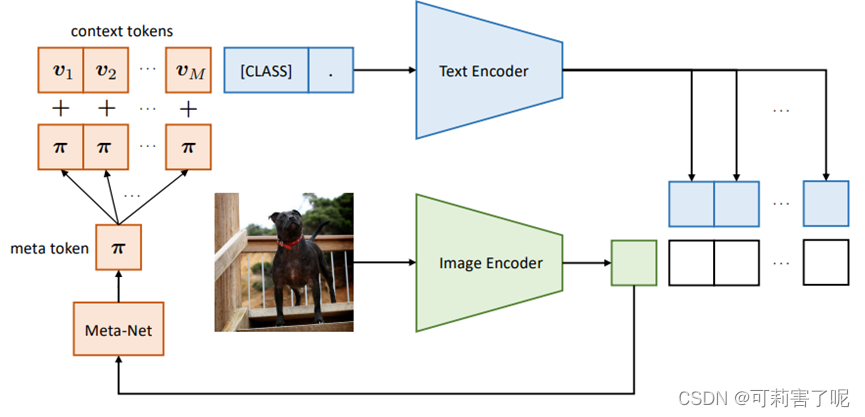
相比于CoOp,CoCoOp增加了一个Meta-Net, 设为ℎ(⋅) ,Meta-Net的输入是image feature x ,输出则是一个instance-conditional token :
![]()
然后与每个context token
相加,得到
:
![]()
因此,第 i 类的prompt以输入为条件,即:
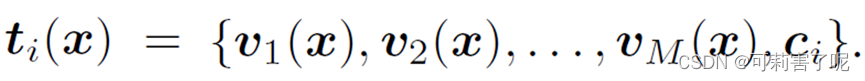
预测概率的计算公式如下:
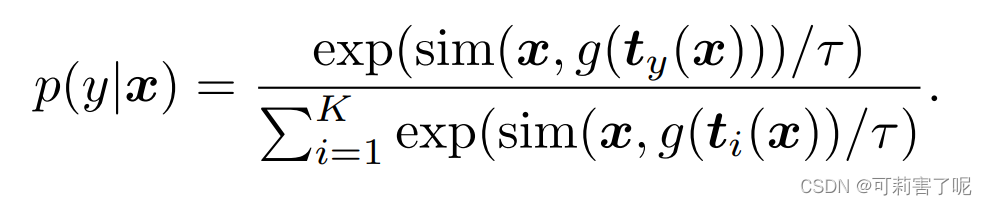
在训练过程中,更新上下文向量{Vm} 以及Meta-Net的参数θ。Meta-Net是一个两层瓶颈结构(Linear-ReLU-Linear),隐层将输入维度降低了16倍。
Experiments
Generalization from base to new classes within a dataset
第一个实验:在一个数据集中从基类到新类的泛化。
- 将每一个数据集的classes平均分成2组,一组base classes,一组new classes;
- 训练时只有base classes的16-shot数据训练;
- H:Base和New的准确率的调和平均数。
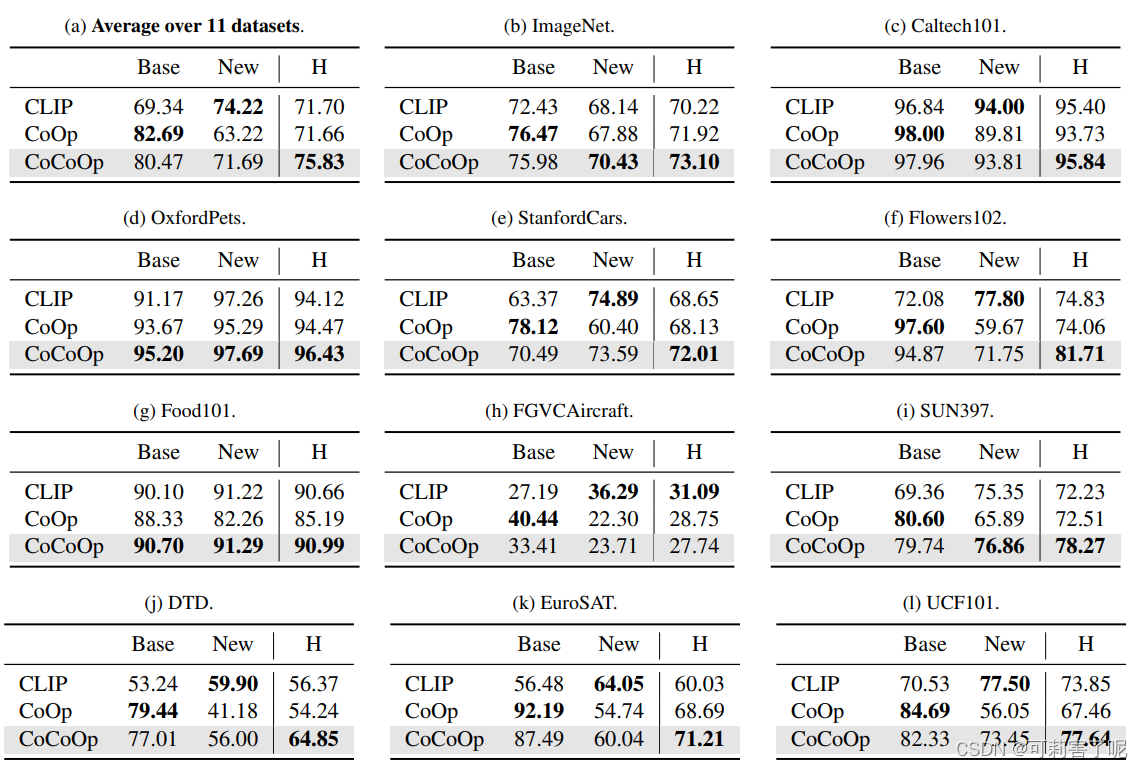
总体来看,CoCoOp在这里更像是介于CoOp和CLIP的中间效果:对于基类不如CoOp,但是超过CLIP;对于未知类不如CLIP(4/11),但是超过了CoOp。
但是我觉得,实际上还是CLIP更好,因为实验test时候对 CLIP 的 manual prompt 是用所有类别调整过的, 实际应用中对多个数据集的泛化直接用CLIP的zero-shot就好。
对于CoCoOp和CoOp在从基类到新类别的泛化综合比较:
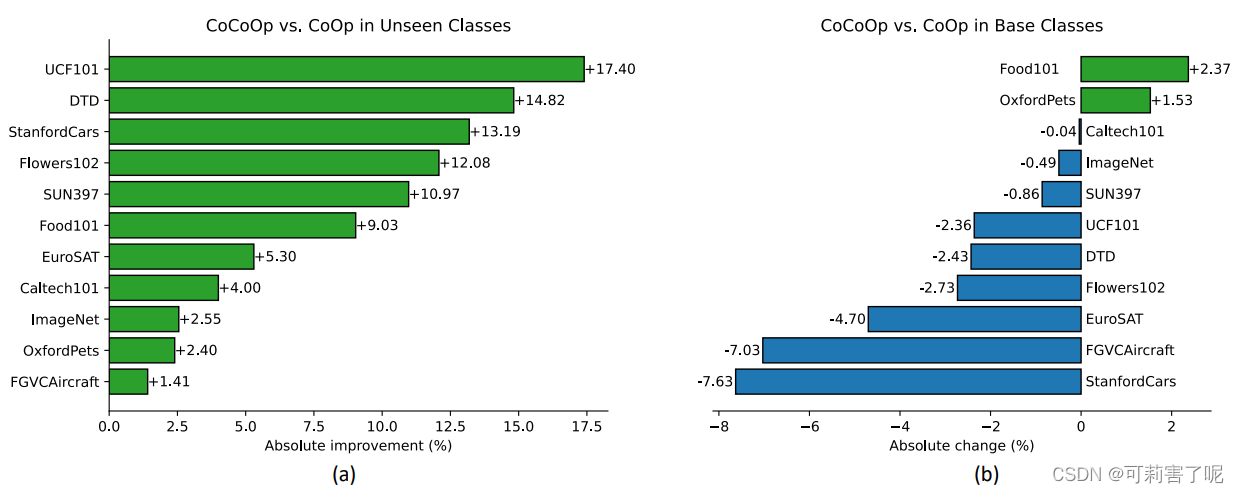
CoCoOp对于未知类的泛化性高于CoOp,但是对于基类的准确率不如CoOp,这是因为:CoOp专门针对基类进行优化,而CoCoOp针对每个实例进行优化,以便获得对整个任务的更多泛化。
Cross-dataset transfer
第二个实验:跨数据集迁移。
在这里只考虑 prompt learning方法,作者将在ImageNet里的1000个类学习到的context,迁移到另外10个数据集上比较,也就是说,把ImageNet作为源域,另外10个数据集作为目标域进行测试:
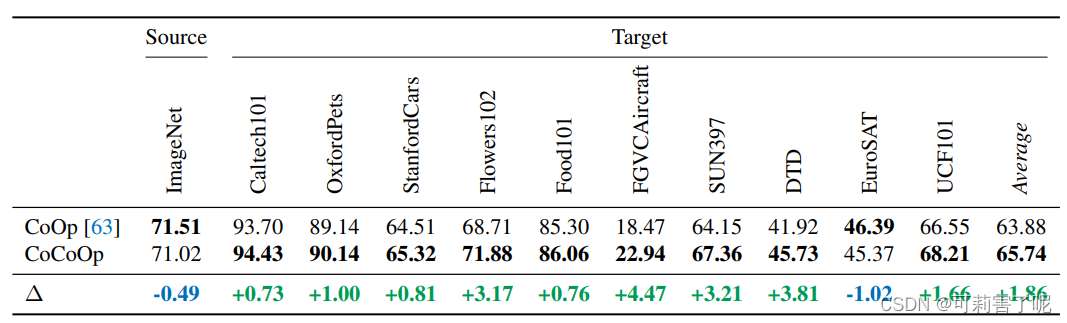
在10/11数据集下,CoCoOp的性能都要超过CoOp。
Domain generalization
第三个实验:域泛化。
对于OOD的泛化研究近年来做的比较多,CoOp的可学习prompt方法对于domain shift表现较好,本节就验证CoCoOp是否还能保持CoOp的优势。

从ImageNet学习到的context 迁移到四个专门设计的基准测试中来评估CoCoOp的域泛化性能。结果表明,这两种prompt learning方法在所有目标数据集上都明显优于CLIP。与Coop相比,CoCoOp在ImageNetV2上的性能略差,但在其他三个版本上的性能要好一些。
结果证实,instance-conditional prompts具有更强的领域概括性。
Further Analysis
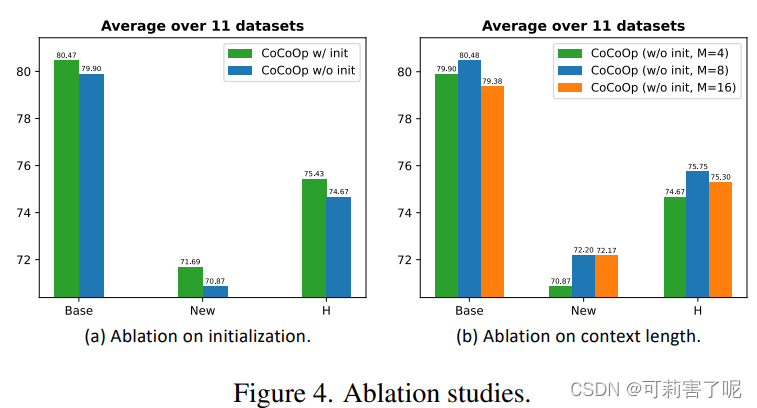
对初始化和context的长度分别做消融实验,结果如下:
Limitations
1、因为CoCoOp是基于实例条件设计的,对于每个图像,都需要通过文本编码器对特定于实例的prompt 进行独立的前向传递。这比CoOp的效率低得多,CoOp只需要通过文本编码器对任何大小的 mini-batch 的prompt进行一次前向传递。
因此,和CoOp相比,CoCoOp需要消耗更大的GPU内存,因此实验部分:we train CoCoOp with batch size of 1 for 10 epochs.
2、在11个数据集的结果中,CoCoOp在未知类上的表现仍然落后于CLIP,这表明基于学习的prompt和人工设计的prompt之间还存在着差距。
One more thing
对于未来的工作,作者也提出了一些可探究的点,比较有趣的一点是扩充 元网络meta-net ,甚至是混合不同数据集的不同训练数据等。
通过实验部分也能看到,CoCoOp其实介于CoOp和CLIP之间的一个方法。CoOp的设计初衷用于将CLIP先验知识快速adapt到下游任务上,其提升了accuracy的同时也牺牲了generalization,所以CoOp更加“专”而“精”;而CLIP从头到尾都是在追求generalization,所以CLIP在所有数据集上的效果都还不错,但不够“精”,却更加“广泛”而“粗糙”。
而CoCoOp则介于它们之间,从研究上来看是没问题的,但是从工程角度,实际应用来看就有点疑惑了:我们什么时候才需要CoCoOp呢?它的应用场景真的广吗?就很值得考虑了。举个例子,如果说想完成某个具体的下游任务我就直接用CoOp,如果我想同时完成很多下游任务 追求泛化性,那么我就选CLIP。这样看,CoCoOp的motivation并不是很强。

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









