






问题:
1、InfoNCE loss和cross entropy loss是否有联系?
2、温度系数τ,其作用是什么?温度系数的设置对效果如何产生影响?
先从softmax说起,下面是softmax公式:
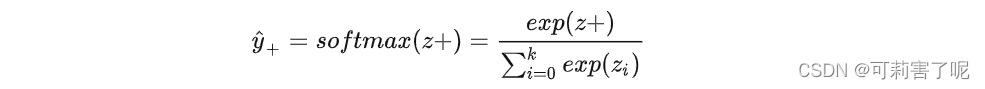
交叉熵损失函数如下:
![]()
在有监督学习下,ground truth是一个one-hot向量,softmax的结果y^+取−log,再与ground truth相乘之后,即得到如下交叉熵损失:
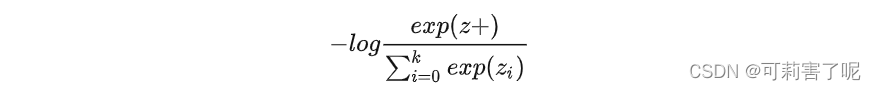
上式中的k在有监督学习里指的是这个数据集一共有多少类别,比如CV的ImageNet数据集有1000类,k就是1000。
InfoNCE对比损失:

InfoNCE, 又称global NCE, 继承了NCE的基本思想,从一个新的分布引入负样例,构造了一个新的多元分类问题,并且证明了减小这个损失函数相当于增大互信息(mutual information)的下界,这也是名字infoNCE的由来。
加入τ后也就是:
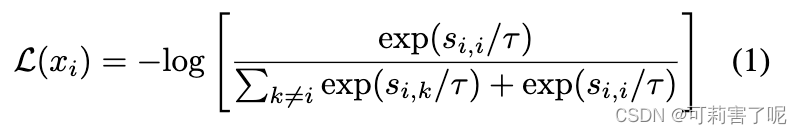
其中τ是温度系数。直观来说,该损失函数要求第i个样本和它的正样本i之间的相似度尽可能大,而与其他的实例(负样本k)之间的相似度尽可能小。
Si*i是模型出来的logits。显而易见,infoNCE最后的形式就是多元分类任务常见的交叉熵(cross entropy)softmax 损失。唯一的区别是,在cross entropy loss里,k指代的是数据集里类别的数量,而在对比学习InfoNCE loss里,这个k指的是负样本的数量。
因为表示已经归一化,据前所述,向量内积等价于向量间的距离度量。故由softmax的性质,上述损失就可以理解为,我们希望在拉近原样例与正样例距离的同时,拉远其与负样例间的距离,这正是对比学习的思想。
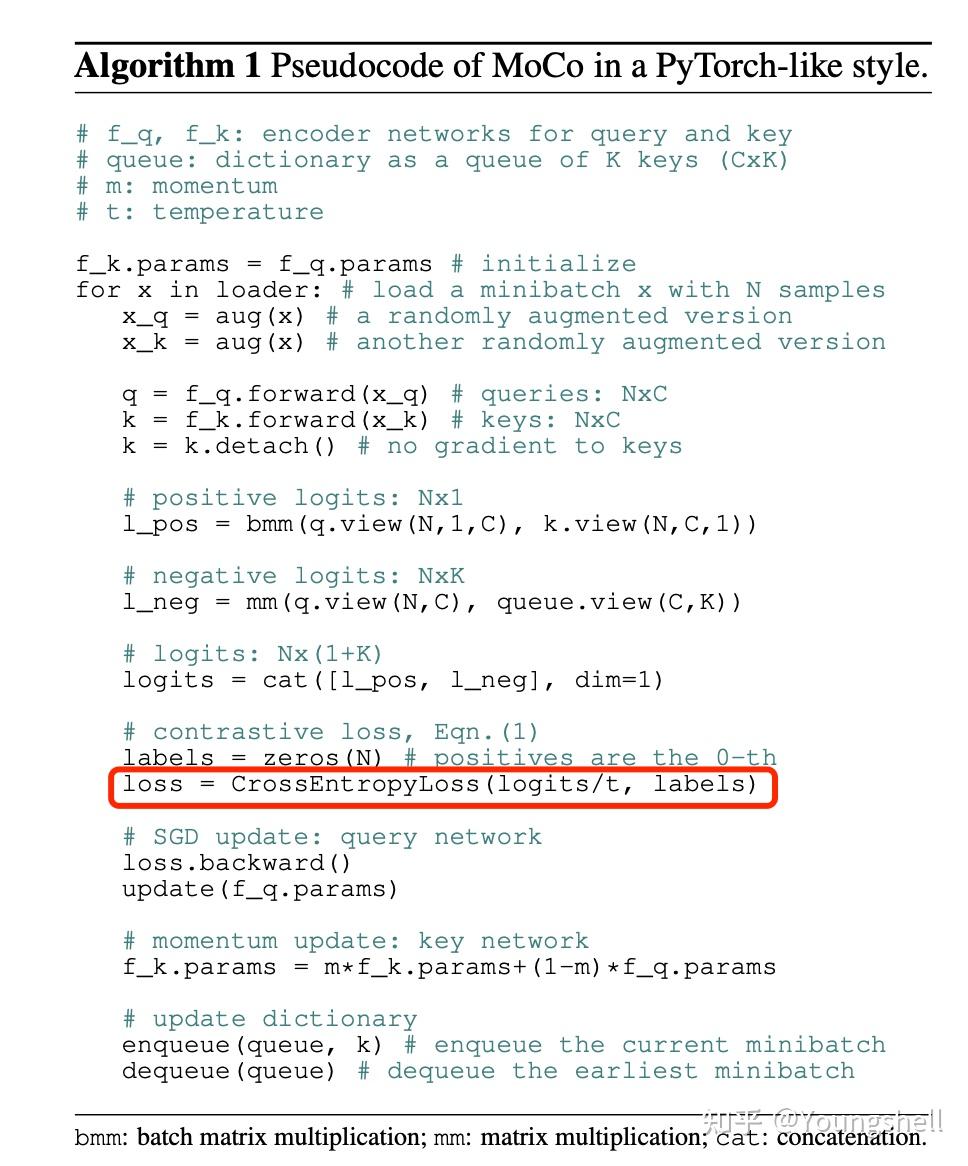
另外,我们看下图中MoCo的伪代码,MoCo这个InfoNCE loss的实现就是基于cross entropy loss。
温度超参τ用什么作用?
τ为softmax的温度超参,并不是原始InfoNCE损失的组成部分,它被引入的一个重要前提假设就是“不完全信任用户的点击标签”,意在控制模型对标签的信任程度,越小(趋向于0),则越信任,反之则越不信任。
τ越小,softmax越接近真实的max函数,越大越接近一个均匀分布。
因此,当τ很小时,只有难区分的负样例才会对损失函数产生影响,同时,对错分的样例(即与原样例距离比正样例与原样例距离更近)有更大的惩罚。
τ趋于无穷大时,对所有负样本的权重都相同,即对比损失失去了关注困难样本的特性。这样不好(关注困难样本的作用就是:对于那些已经远离的样本,不需要继续让其远离,而主要聚焦在如何使没有远离的那些的样本远离,从而使得到的表示空间更均匀uniformity。)
对比损失随着τ的增大而倾向于“一视同仁”,随着τ的减少而只关注最困难的负样本,τ发挥着一种调节负样本关注度的作用。而且实验结果表明,对比学习对 τ 很敏感。















 5813
5813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









