







第二章 Spark基础
2.5 启动Spark-Shell
Spark-Shell是一个强大的交互式数据分析工具, 初学者可以很好的使用它来学习相关API,用户可以在命令行下使用Scala编写Spark程序,并且每当输入一条语句, Spark-Shell就会立 即执行语句并返回结果,Spark-Shell支持Scala和Python,如果需要进入Python语言的交互式执行环境,只需要执行"pyspark 命令即可。
2.5.1 运行Spark-Shell命令
在spark/bin目录中,执行"Spark-Shell"命令就可以进 入Spark-Shell交互式环境,具体执行命令如下。
bin/spark-shell --master <master-url>
上述命令中,“–master”表示指定 当前连接的Master节点,用于指定Spark的运行模式, 可取的详细值如表所示。
表2-1 master-url参数列表
| 参数名称 | 功能描述 |
|---|---|
| local | 使用一个Worker线程本地化运行Spark |
| local[*] | 本地运行Spark,其工作线程数量与本机CPU逻辑核心数量相同 |
| local[N] | 使用N个Worker线程本地化运行Spark (根据运行机器的CPU核数设定) |
| spark://host:port | 在Standalone模式下,连接到指定的Spark集群,默认端口是7077 |
| yarn-client | 以客户端模式连接Yarn集群,集群的位置可以在HADOOP_ CONF DIR 环境变量中配置 |
| yarn-cluster | 以集群模式连接Yarn集群,集群的位置可以在HADOOP_ CONF_ DIR 环境变量中配置 |
| mesos://host:port | 连接到指定的Mesos集群。默认接口是5050 |
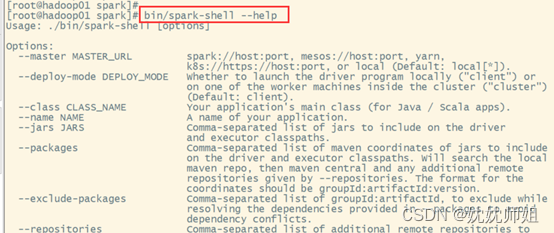
如需查询Spark-Shell的更多使用方式可以执行“–help命令“获取帮助选项列表,如图所示。
2.5.2 运行Spark Shell读取HDFS文件
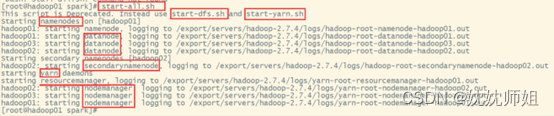
2.5.2.1 先启动Hadoop
下面通过启动Spark-Shell,并组使用Scala语言开发单词计数的Spark程序,现有文本文件words.txt (读者需要在本地创建文件并上传至指定目录)在HDFS中的/spark/test路径下, 且文本内容如下。
hello hadoop
hello spark
hellp itcast
如果使用Spark Shell来读取HDFS中的/spark/test/ words.txt文件,具体步骤如下:
2.5.2.2 整合Spark与HDFS
Spark加载HDFS上的文件,需要修改spark-env.sh配置文件,添加HADOOP_CONF_ DIR配置参数,指定Hadoop配置文件的目录,添加配置参数如下。
#指定HDFS配置文件目录
export HADOOP_CONF_DIR=/export/servers/hadoop-2.7.4/etc/hadoop
在Hadoop01上修改后,将该spark-env.sh配置文件分发给hadoop02和hadoop03。

2.5.2.3 启动Hadoop Spark服务
配置完毕后,启动Hadoop集群服务,并重新启动Spark集群服务,使配置文件生效。
(1) 要重启Hadoop,先要停掉Hadoop。

(2) 重启Hadoop。
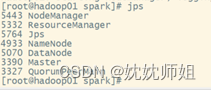
(3) 查看jps
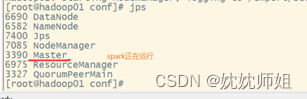
要先将它停了。

(4) 重启spark。
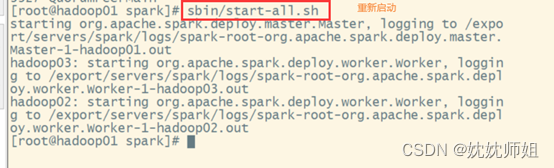
2.5.2.4 启动Spark-Shell编写程序
启动Spark-Shell交互式界面,执行命令如下。
bin/spark-shell --master local[2]
执行上述命令, Spark-Shell启动成功后, 就会进入如图所示的程序交互界面。
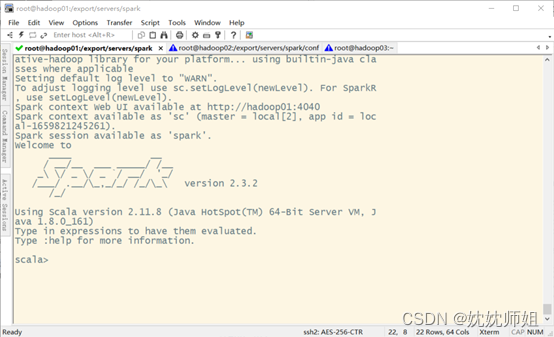
SparkShell本身就是一个Driver, 它会初始化-个SparkContext对象为“sc”,用户可以直接调用。下面编写Scala代码实现单词计数,具体代码如下。
scala > sc.textFile("/spark/test/words.txt").
flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((itcast,1), (hello,3), (spark,1), (hadoop,1))
上述代码中,res0表示返回的结果对象, 该对象中是一个Array[ ](String, Int)]类型的集合, (itcast, 1)则表示"itcast"单词总计为1个。
2.5.2.5 退出Spark-Shell客户端
可以使用命令“:quit”退出Spark-Shell,如下所示。
scala > :quit
也可以使用快捷键“Ctrl+D",退出Spark Shell。

2.6 本地数据文件的统计与分析
2.6.1 准备数据文件
1.在/usr/data目录下创建数据文件

文件内容如下:
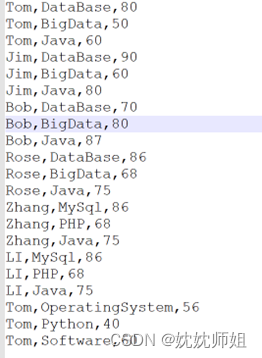
2.启动Spark-Shell

2.6.2 任务1-统计学生人数
- 读取数据获取数据lines
- val lines = sc.textFile(“url”)
- 通过分隔符将各列数据取出并生成map
- val par=lines.map(row=>row.split(“,”)(0))
- “,”为分隔符
- 0代表第一列
- 去重
- var distinct_par=par.distinct()
- 查看结果
- distinct_par.count
示例:

- distinct_par.count
2.6.3 任务2-统计课程数
- 读取数据获取数据lines
- val lines = sc.textFile(“url”)
- 通过分隔符将各列数据取出并生成map
- val par=lines.map(row=>row.split(“,”)(1))
- “,”为分隔符
- 0代表第一列
- 去重
- var distinct_par=par.distinct()
- 查看结果
- distinct_par.count

- distinct_par.count
2.6.4 任务3-统计Tom 同学的总成绩平均分是多少
- 读取数据获取数据lines
- val lines = sc.textFile(“url”)
- 通过分隔符将取得条件满足的行生成数组
- var pare=lines.filter(row=>row.split(“,”)(0)==“Tom”)
- 查看筛选后的数据结果
- pare.foreach(println)
- 平均分的计算与统计
- pare.map(row=>(row.s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











