










文章目录
生成对抗网络 GAN —— Generative Adversarial Network
一, Why GAN
常有这样的需求:图像生成,语音生成,状态预测等,这要求我们要有一个很好的生成器,而近年来出现了许多的生成器模型,但是在生成出来的结果都不尽如人意,容易预测,或者是缺乏变化,或者是缺乏实用性。而GAN就很好的克服了这些缺点。
二,GAN的思想 Thought of GAN
GAN有两个重要的角色:一个生成器(Generator),还有一个判别器(Discriminator)。
GAN的思想简单来说就是这两个角色之间的博弈:生成器生成图片,并试图尽自己最大的努力去欺骗判别器——这是一张自然的图片!而判别器则是尽可能的去辨别——不,这是一张生成的图片!
你可能很快会想到Minimax Theorem——最小化最大值原理,事实上这也是为什么我们称之为对抗(Adversarial),这就是两个互相对弈的象棋大师:双方都努力做出最佳的应招,而显然,在双方都做出最佳的选择的情况下,结果就必然是确定的。这保证了我们的训练最终将会收敛,也就是说,最终生成器将会作出最好的采样,得到最为接近真实的图片,而判别器将束手无策!
三,GAN网络架构
生成对抗网络由两个网络组成:
- 生成器(Generator)网络
- 判别器(Discriminator)网络
下面是一个基本的GAN网络架构:
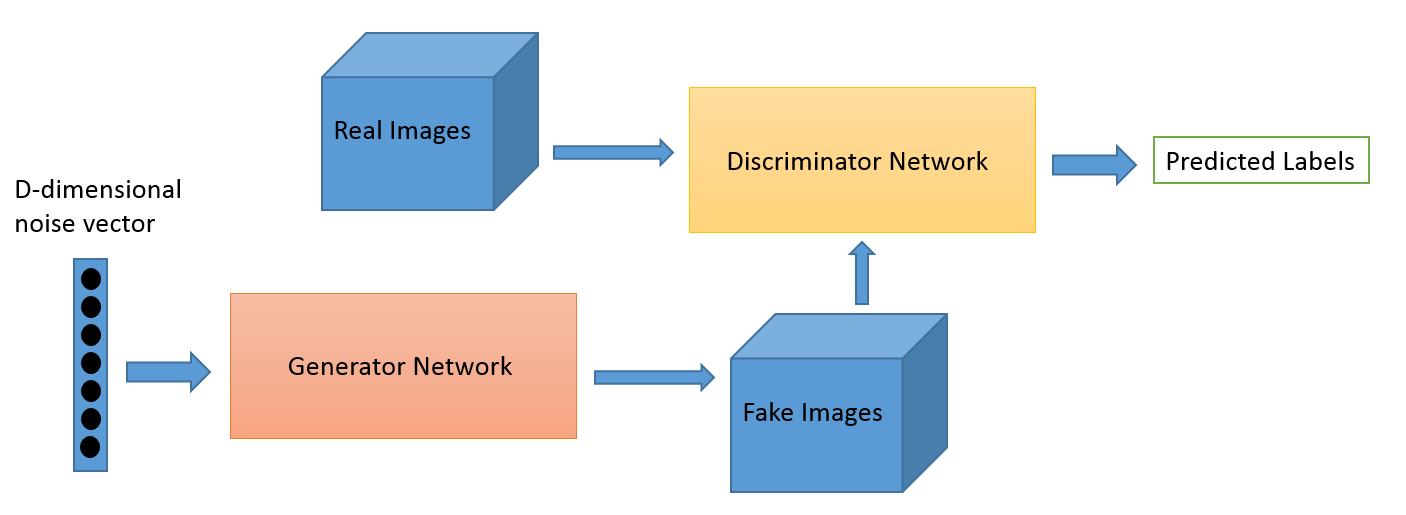
GAN架构 from O’Reilly
输入D维的噪声向量,通过生成器网络产生假图像,然后输入到判别器中,判别器根据数据集中的真是图像做出判断,给出判断结果,即,这是否是一张真实的图片。
1,生成器 Generator
生成器具体是怎样来生成图片的呢?GAN的生成器的架构是类似下面这样,可以看到这实际上可以看成一个反卷积(reverse convolutional neural network)的过程:输入是一个随机的噪声向量,最终通过多层的反卷积生成一张
64
×
64
64 \times 64
64×64 的图片。

反卷积
相比于卷积的下采样(subsample,将一张图片最终变成一个向量),这是一个上采样的过程(upsample,将一个向量转为图片):
- 首先对图像进行上采样,如下图,原本的图像是一张 3 × 3 3\times3 3×3 的图像,可以看到上采样之后变成了 7 × 7 7 \times 7 7×7 的图片中蓝色的9个像素点,并且出现了很多空白部分
- 然后,我们必须对空白部分进行填充(fill),填充就是采用一个反卷积的过程
下图中深绿色的
5
×
5
5 \times 5
5×5 的部分其实就是我们的反卷积的模板,反卷积不同于卷积的地方就是:我们是用反卷积模板中的每个像素拿来和我们所要进行反卷积的图片进行卷积,也就是说,这是
5
×
5
=
25
5\times5=25
5×5=25 个
1
×
1
1 \times 1
1×1的模板和一张
3
×
3
3 \times 3
3×3 进行卷积的过程的进行卷积的过程!
从下面的动态图片可以看到,下面投射出来的阴影部分就是上面
5
×
5
5 \times 5
5×5 绿色模板中的每个像素和
3
×
3
3 \times 3
3×3 蓝色图片卷积的结果:

我们也可以发现,之所以采用的是
5
×
5
5\times5
5×5 的反卷积模板,是为了能够将一张
3
×
3
3\times3
3×3 的图片对
7
×
7
7\times7
7×7 的上采样结果进行插值:
(0)
3
+
5
−
1
=
7
3 + 5 - 1 = 7 \tag{0}
3+5−1=7(0)
2,判别器 Discriminator
相比较于生成器,你可能更熟悉的是一个简单的判别器的架构:

这是一个非常接近于CNN(Convolutional Neural Network 卷积神经网络)的过程,前面两维是特征图像的大小,第三维是特征图像的数量(例如,经过第一层的卷积层之后得到了 64张
32
×
32
32 \times 32
32×32 的特征图像)。
这里的判别器架构没有给出池化(Pooling)的过程,但是我们可以看到,在每次卷积之后图像的两个维度都变成了原来的
1
/
2
1/2
1/2,事实上是经过了一个池化的操作,我们有时也会把卷积和池化合并在一个卷积层的操作当中,而不是单独作为一个池化层。
关于CNN的架构以及卷积和池化方面的介绍可以点击上面给出的文章链接,通过一个MNIST手写字识别的例子进一步了解整个过程。
最后的完整架构是这样的:

三,GAN的训练过程
这个过程看起来是对生成器的训练,这是一个很自然的想法,因为事实上我们的目的就是想要训练出一个技术高超的伪造大师——一个可以瞒天过海的生成器。但是,其实这是一个相互训练的过程,这也是为什么我们的生成器能够不断进化的原因:因为他的对手也在不断成长!
而你也可以想到,在一开始,双方都是水平有限的菜鸟,当然某种意义上也是旗鼓相当的对手,不过,通过彼此之间的对抗,他们不断升级,将变得越来越聪明:
- 通过真实的图片和生成器产生图片对判别器进行训练,判别器会逐渐明白,一张真实的图片应该具备什么样的特点(比如,一只猫应该有尾巴,甚至是某个特定品种的猫具有什么样的特点)
- 判别器可以对生成器产生的图片做出反馈,告诉生成器怎么样才能做的更好(这会是涉及到像素层级的建议,比如某个灰度值应该做出怎样的调整)
你会发现,他们并不是一味的对抗,而是在对抗之后(一次迭代),双方选手进行赛后复盘,最终得出应该怎样才能做的更好,然后开始下一场比赛。通过这样的共同训练,可以保证某一方不会过于强大,双方同时进步,这样就不会出现这样的画面:略胜一筹的一方会自以为自己非常的完美,然而它并不知道自己在和一个低级的对手进行竞争。。。这样很容易导致对低级网络的过拟合。
在机器之心公众号上的这篇推文非常生动的为我们讲解了GAN的训练过程,以及一些相关的视频,还有本篇的一些图片来源,有兴趣的话可以更多了解一些GAN相关的知识!
如果你对具体的代码实现感兴趣的话,O’Reilly GAN for beginners上给出了基于TensorFlow的一个简单的GAN实现,并且对代码的每个部分都进行了详细的解释,并且提供了在线运行的功能,可以帮助你很好的理解代码每个步骤实现原理和方法















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









