







首先,需要明确一点:
多分类时,目前我们使用交叉熵。
原因:想要预测分类结果正确,不需要预测概率完全等于标签概率。但使用均方差时,预测过于严格。因此需要使用更适合衡量两个概率分布差异的测量函数,其中交叉熵是常用的方法。
我制作了部分对比的图片,看这个视频应该对理解有帮助。
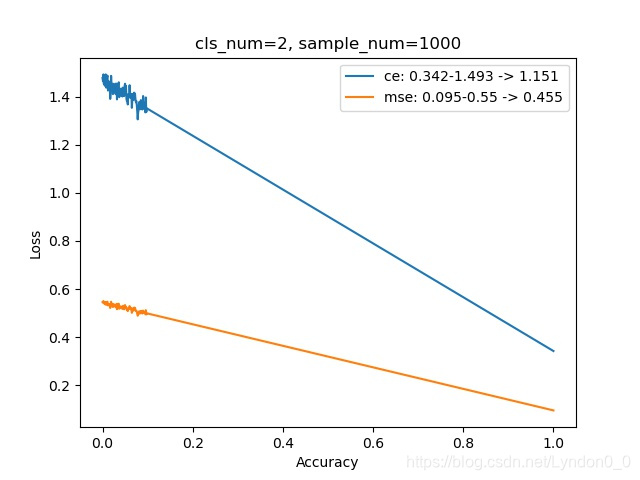
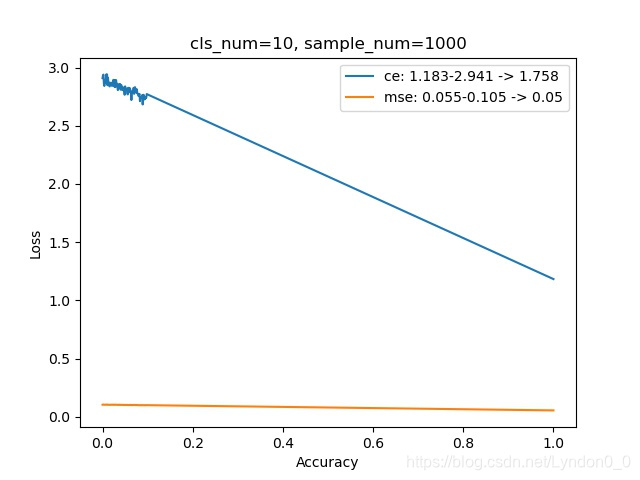
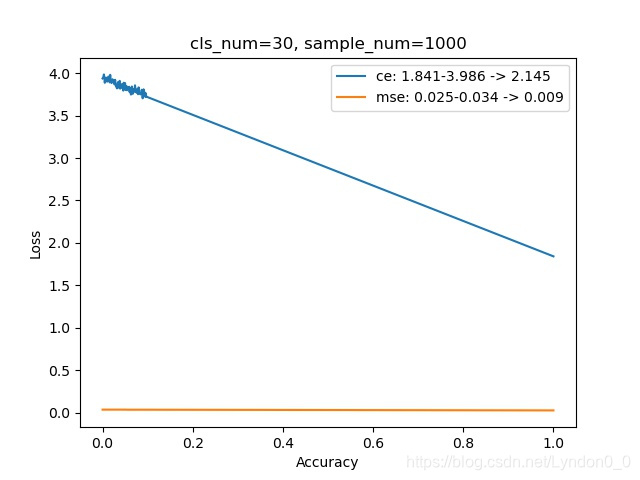
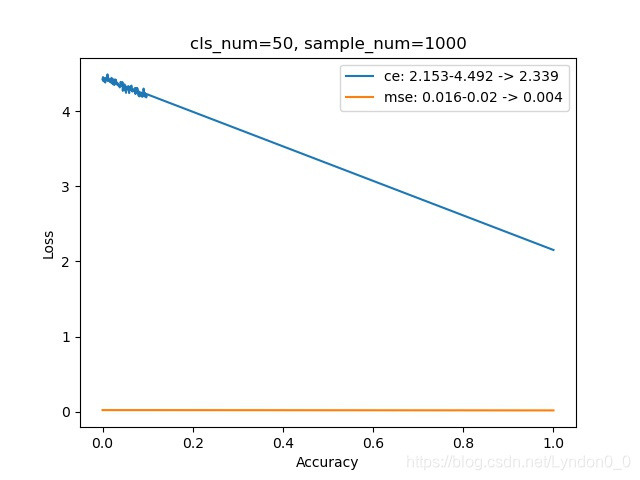
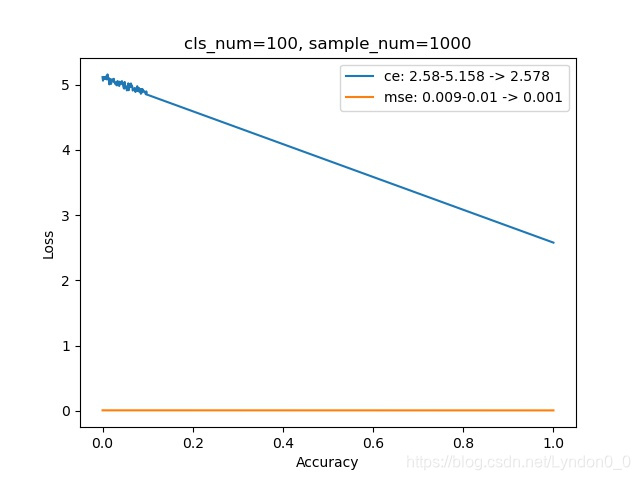
每幅图上的曲线,显示了随着预测准确率的提高,交叉熵损失和均方差损失的变化情况。
其中横坐标为准确率,范围在0到1之间,纵坐标为损失。
对比的类别数范围在[2, 100],每个类别使用的样本量是1000组。
可以发现,随着预测的类别增多,完全预测正确和完全预测错误时两者损失之差,交叉熵损失在增大,均方差损失在减小。
即:预测多个类别时,交叉熵比均方差更容易将不同类别区分开。
代码见github:https://github.com/helindemeng/Compare-CrossEntrop-MSE.git
视频地址:
多分类时交叉熵损失函数为什么比均方差损失函数好
部分类别:















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









