







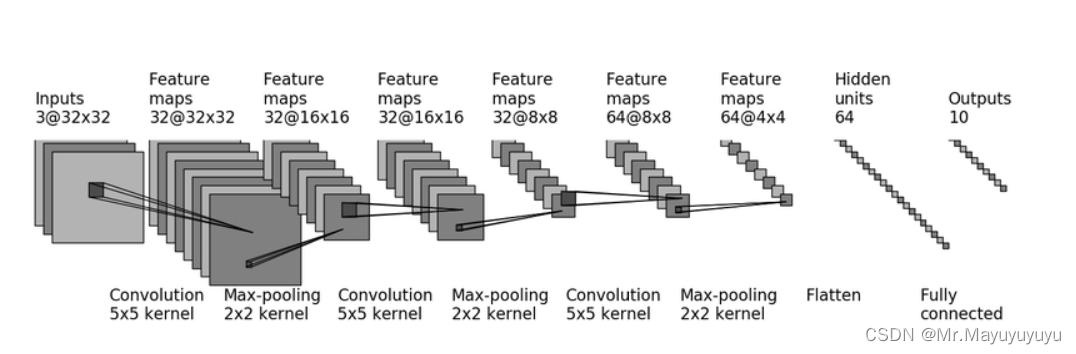
本文针对上图的卷积神经网络搭建一个能够进行10个类别的图像进行识别 如果想观察其测试集的损失度和精度可以通过Tensorboard进行记录。(参考于B站小土堆的Pytorch讲解)
首先实现对上图的神经网络的实现,这部分代码主要实现构建卷积神经网络,也是神经网络的核心代码。
class Mayu(nn.Module):
def __init__(self):
super(Mayu, self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10),
)
def forward(self, input):
output = self.model1(input)
return output
训练数据集部分代码。主要是对训练数据的损失值进行统计
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
#训练开始
mayu.train()#把网络设置为一个训练状态 只对特定的层有作用
for data in train_dataloader:
imgs, targets = data#data是对train_dataloader的数据进行调用,前两个参数表示tensor类型的图片和其位置
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = mayu(imgs)
loss = loss_fu(outputs, targets)
#优化器调优
optimzer.zero_grad()
loss.backward()
optimzer.step()
total_train_step += 1
if total_train_step % 100 == 0:#逢百输出
end_time = time.time()
print(end_time-start_time)
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
测试数据集部分代码。主要计算对测试集数据的损失值和准确值
#测试步骤开始
#测试集主要就是测试训练的结果怎么样,模型的精度、损失度
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():#不需要梯度取消梯度
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = mayu(imgs)
loss = loss_fu(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1)==targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
总体实现对CIFAR10进行训练得到模型
import torch
import torchvision
import time
#1.准备数据集
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#训练数据集
from Project.create_nn import Mayu
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)#路径可以使用绝对路径
#测试数据集
test_train = torchvision.datasets.CIFAR10("./dataset", train = False, transform=torchvision.transforms.ToTensor(),
download=True)
#看下数据集长度
train_data_size = len(train_data)
test_data_size = len(test_train)
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
#利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=32)
test_dataloader = DataLoader(test_train, batch_size=32)
#损失函数
loss_fu = nn.CrossEntropyLoss()#使用交叉熵损失函数
if torch.cuda.is_available():
loss_fn = loss_fu.cuda()#GPU是否可用,可用就用
mayu = Mayu()#实例化,利用上文已经写过的神经网络
if torch.cuda.is_available():
mayu = mayu.cuda()
#优化参数
#1e-2 = 1×(10)^(-2) = 1/100 = 0.01
learning_rate = 1e-2
#优化器使用SGD
optimzer = torch.optim.SGD(mayu.parameters(), learning_rate)
#设置训练网络的参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#设置训练轮数
epoch = 10
#添加tensorboard,记录统计数据,使test_loss、test_accuracy可视化
writer = SummaryWriter("../Projetlog")
#记录下开始时间
start_time = time.time()
#开始训练
for i in range(epoch):
print("第{}轮训练开始".format(i+1))
#训练开始
mayu.train()#把网络设置为一个训练状态 只对特定的层有作用
for data in train_dataloader:
imgs, targets = data#data是对train_dataloader的数据进行调用,前两个参数表示tensor类型的图片和其位置
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = mayu(imgs)
loss = loss_fu(outputs, targets)
#优化器调优
optimzer.zero_grad()
loss.backward()
optimzer.step()
total_train_step += 1
if total_train_step % 100 == 0:#逢百输出
end_time = time.time()
print(end_time-start_time)
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
#测试步骤开始
#测试集主要就是测试训练的结果怎么样,模型的精度、损失度
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():#不需要梯度取消梯度
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = mayu(imgs)
loss = loss_fu(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1)==targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(mayu, "mayu{}.pth".format(i))
print("模型已保存")
writer.close()
得到最后一轮的模型结果

然后我们可以下载一张图片喂到所得到的模型中进行测试

再写一个测试代码,使用训练出的模型
import torchvision
from PIL import Image
import torch
img_path = "D:\\PycharmPro\\first_demo\\DataTes\\horse.png"
image = Image.open(img_path)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()])
image = transform(image)
model=torch.load("mayu9.pth", map_location=torch.device('cpu'))
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
classes = ['airplane', 'automobile', 'bird',
'cat', 'deer', 'dog', 'frog', 'horse',
'ship', 'truck']
with torch.no_grad():
output = model(image)
print("predict:{}".format(classes[torch.argmax(output)]))
得到结果
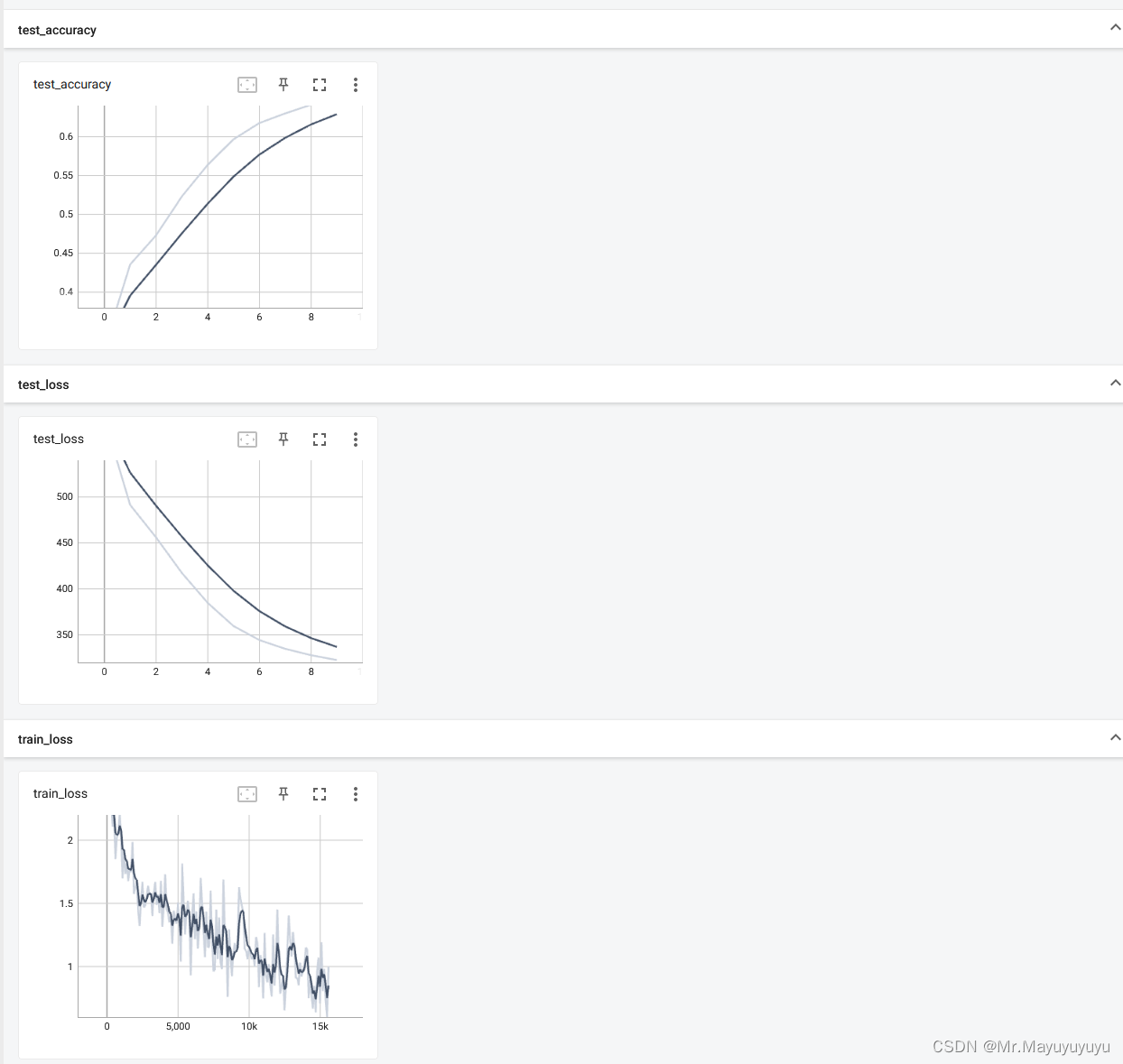
 在Tensorboard中得到的可视化的测试集损失值和准确度
在Tensorboard中得到的可视化的测试集损失值和准确度
总结:
①代码主要体现的是如何对数据进行训练得到自己的模型,对自己的数据集进行处理。
②pytorch基本架构也是如此,AlexNet等论文的代码也可通过相似的架构进行实现并得到测试结果。
















 1205
1205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









