






Day 1!
小编来发起一轮新的挑战啦,想做的师弟师妹们可以一起操作起来。国庆后最忙的阶段快过去了,最近在科室里终于可以喘口气啦~
最近GBD的发文量剧增,今年到现在的发文量已经超过23年的啦,小编也打算来挑战一篇!
挑战5天完成一篇GBD数据库SCI!大家一起学习,一起冲锋,希望能多增加几篇!
今天的主要任务就是初步检索+确定目标期刊和文献。
关于GBD的介绍已经是老生常谈了,GBD数据库,是一个综合性的统计数据库。该数据库旨在提供全球、国家和地区级别的疾病负担数据,包括死亡率、患病率、伤残调整生命年等多种指标。GBD数据库提供了从1990年至今的健康相关数据,用于分析和比较不同人群、地区和时间段内的健康问题。
使用GBD数据库发表文章的常用方法如下:
1. 数据提取和筛选
2. 描述性分析、比较分析、风险因素分析
3. 预测模型的建立
操作步骤也和之前一样,首先我对“GBD”进行了检索,截至目前已经发文3300多篇了,势头很猛!
且发文的质量还是蛮不错滴,都是一二区的文章
然后我检索了“GBD and目标疾病”,还没有文章发过!赶紧冲~
我打算用更新的数据以及加上预测模型等方法来实现,那就这么决定啦!
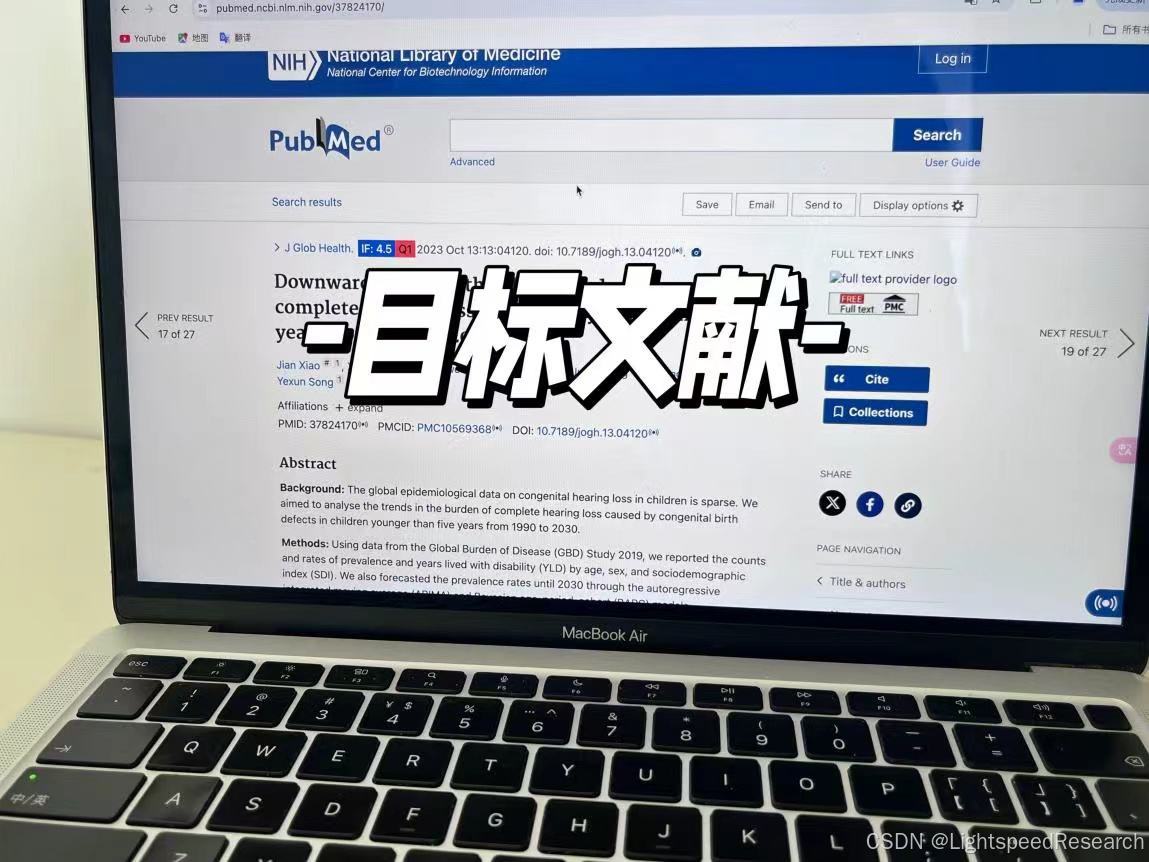
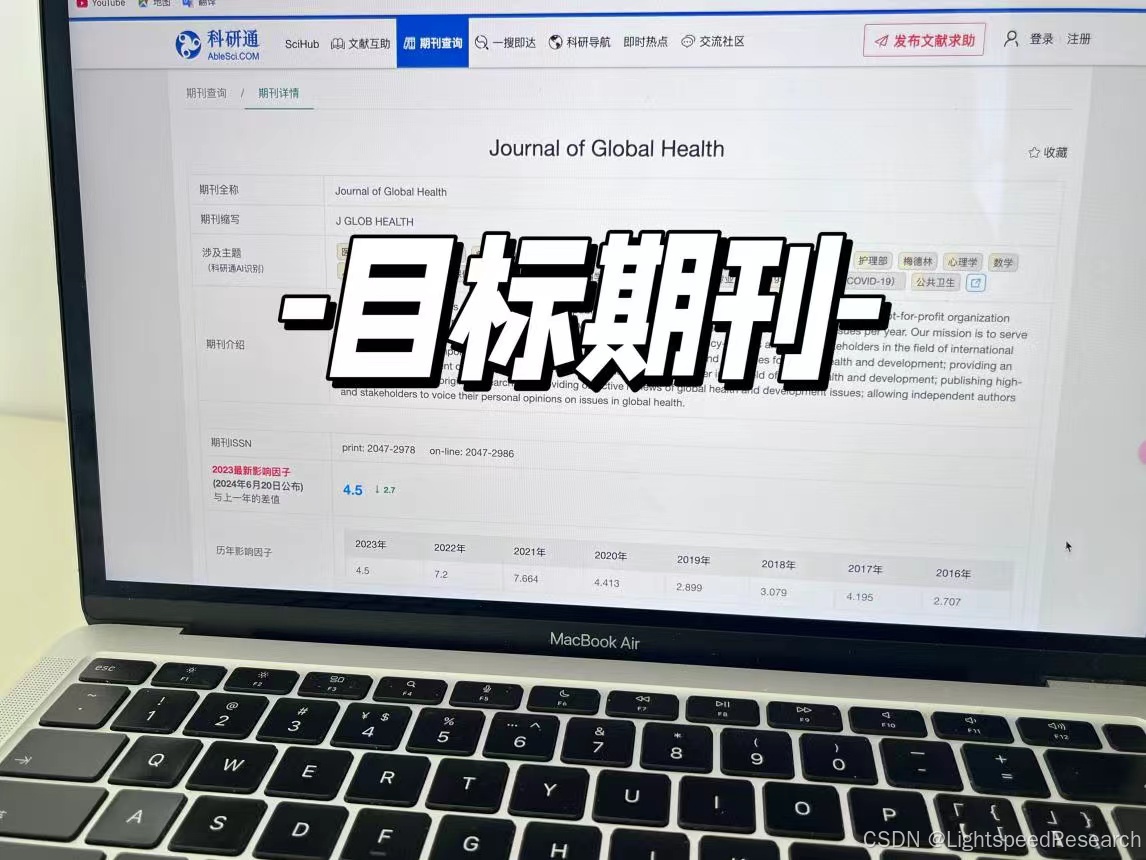
在看文献的过程中发现了一篇用的方法都满足我需求的文章,且这个期刊也是我的目标杂志,影响因子、发文量、首次回复时间都很不错,而且所采用的方法我都已经掌握了,
那就以这个期刊和文献为目标啦!
目标文献是:10.7189/jogh.13.04120
目标期刊是:J Glob Health
让我们一起探索GBD数据库吧!冲冲冲~


Day 2-3!
新挑战继续进行~
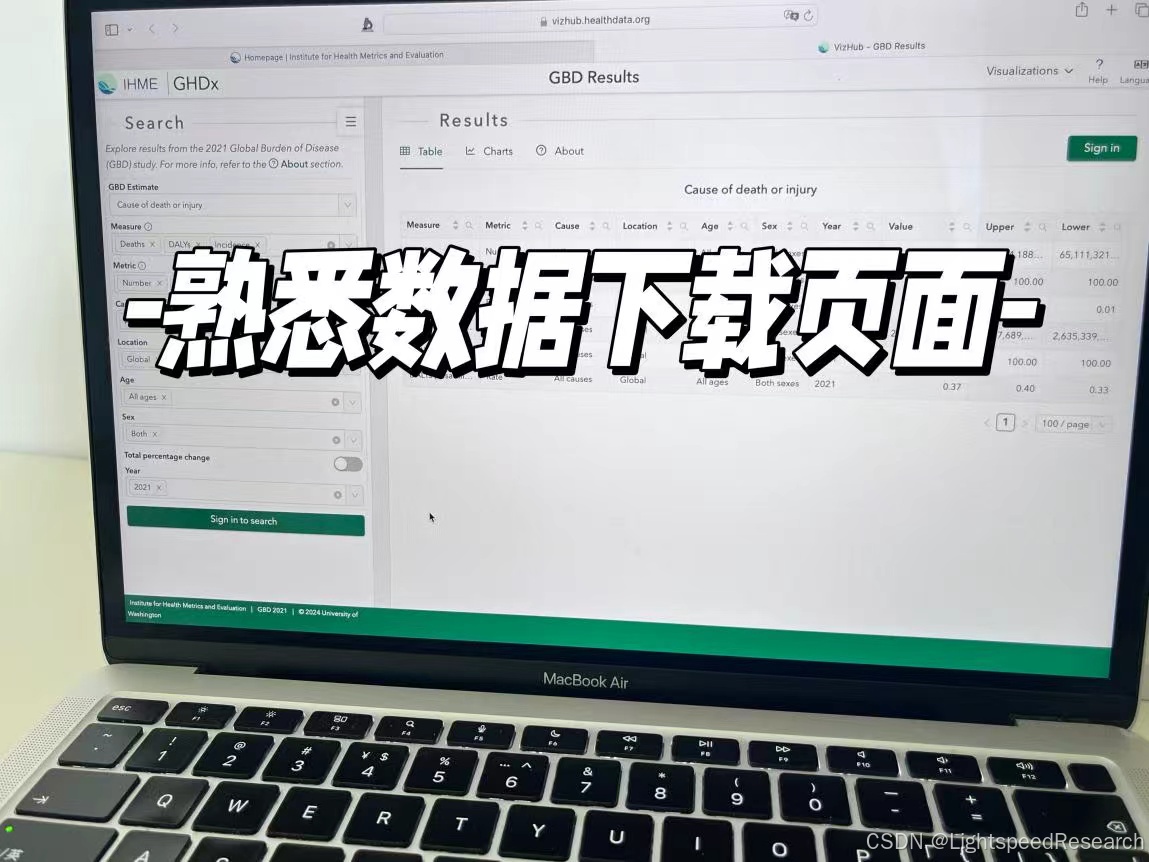
第2天的主要任务:认识数据库+下载数据
这个数据库的优点就在于比较简单、方便,且任何一个可以在官网上下载的疾病,都可以跑出想要的图表,而不是像别的数据库,整理完数据后分析发现可能无相关性,所以GBD数据库可以使我们可以快速发文,疯狂冲锋冲锋~
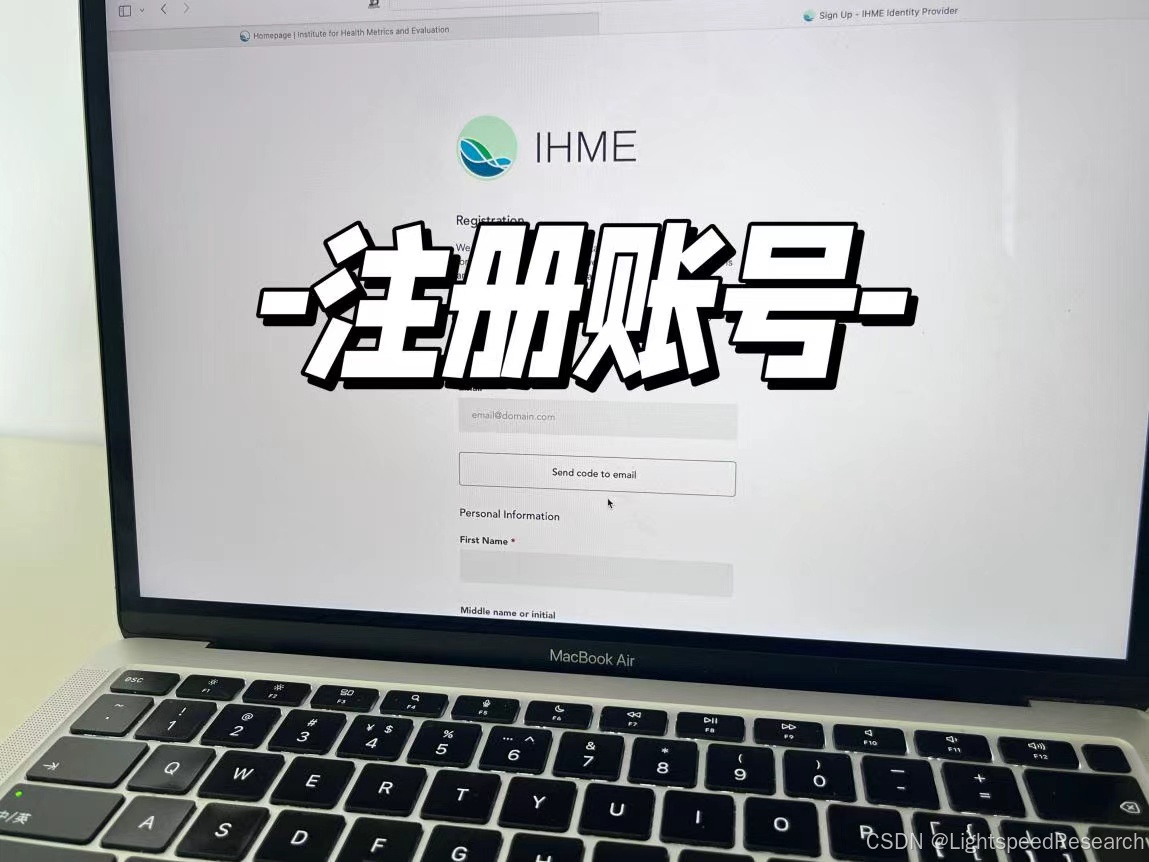
我们在提取数据之前,首先得熟悉一下GBD的官网,注册自己的账号以及了解数据是怎么下载的。
其次我们需要评估所选目标文献的方法,它的table和figure是否换了数据集后仍可以复现。一切准备就绪后就可以开始下载啦!
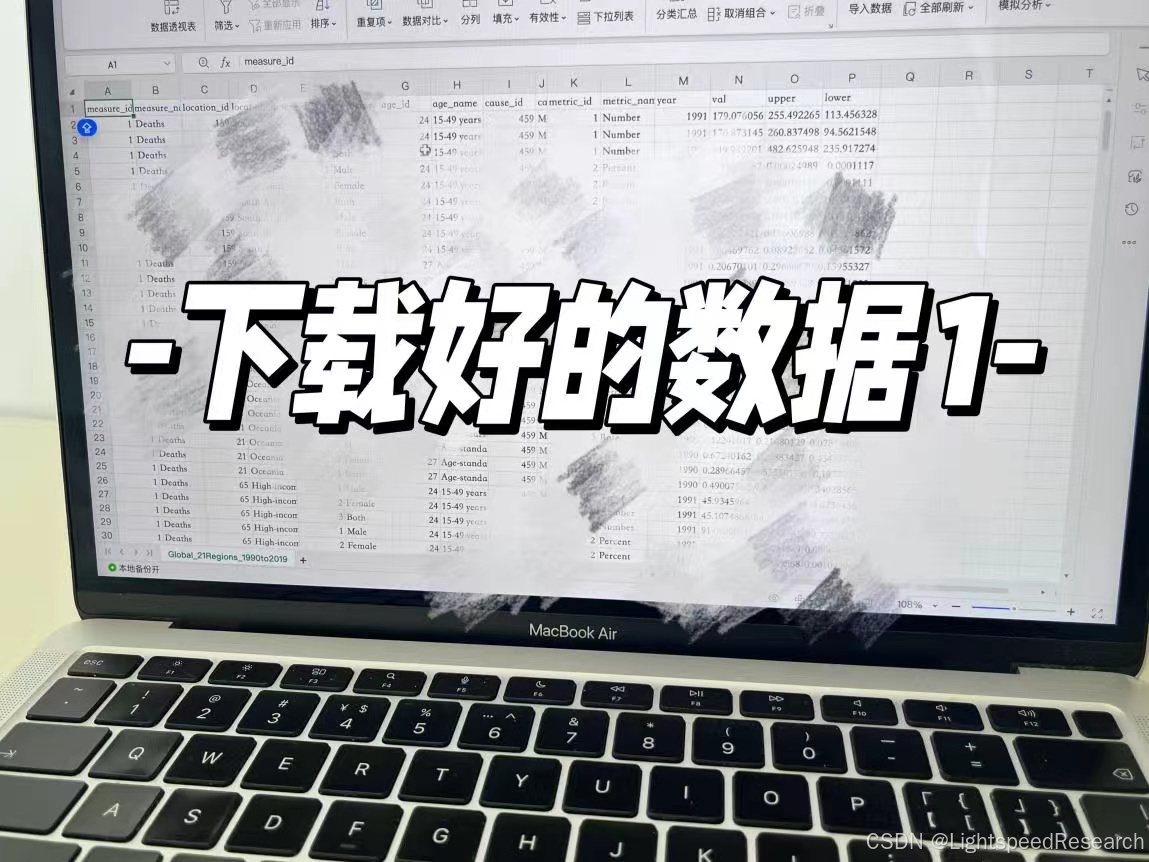
不过最近的GBD数据下载并不顺利,如果将所有数据一起下载往往会失败,但我用了分割提取再合并的方法,还是可以在2天内完成的!库库一顿提取就完事~
GBD的优点就是下载的数据都是标准化的,不需要像NHANES一样还需要特别处理,所以下载得到的数据可以直接用来分析。
只要数据清晰了,后面的一切都好说,没什么复杂和困难的,重点就是选题和明确分析方法,这就是我花了很多的时间进行初步检索确定目标期刊、选题的意义。千万不要一来就闷头下载数据,很可能白费时间!
好啦,今天的分享就到这里啦,一起加油呀~

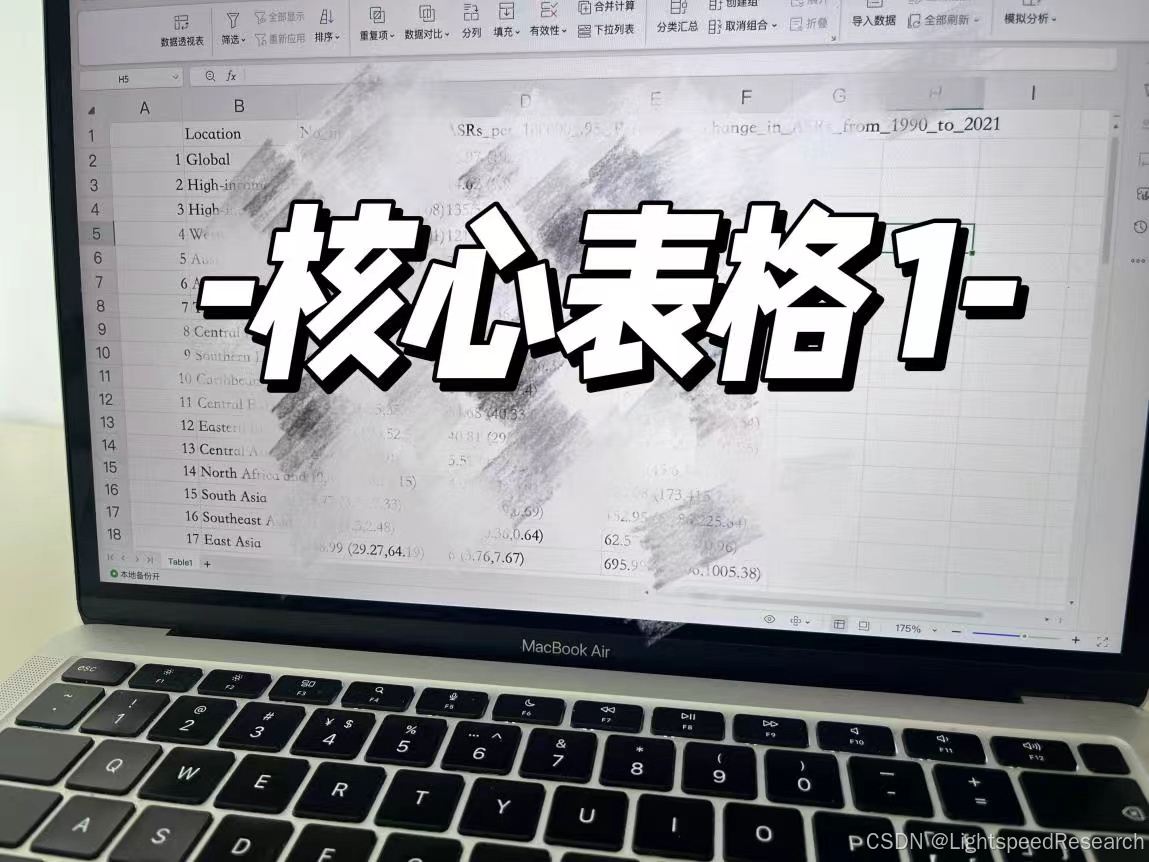

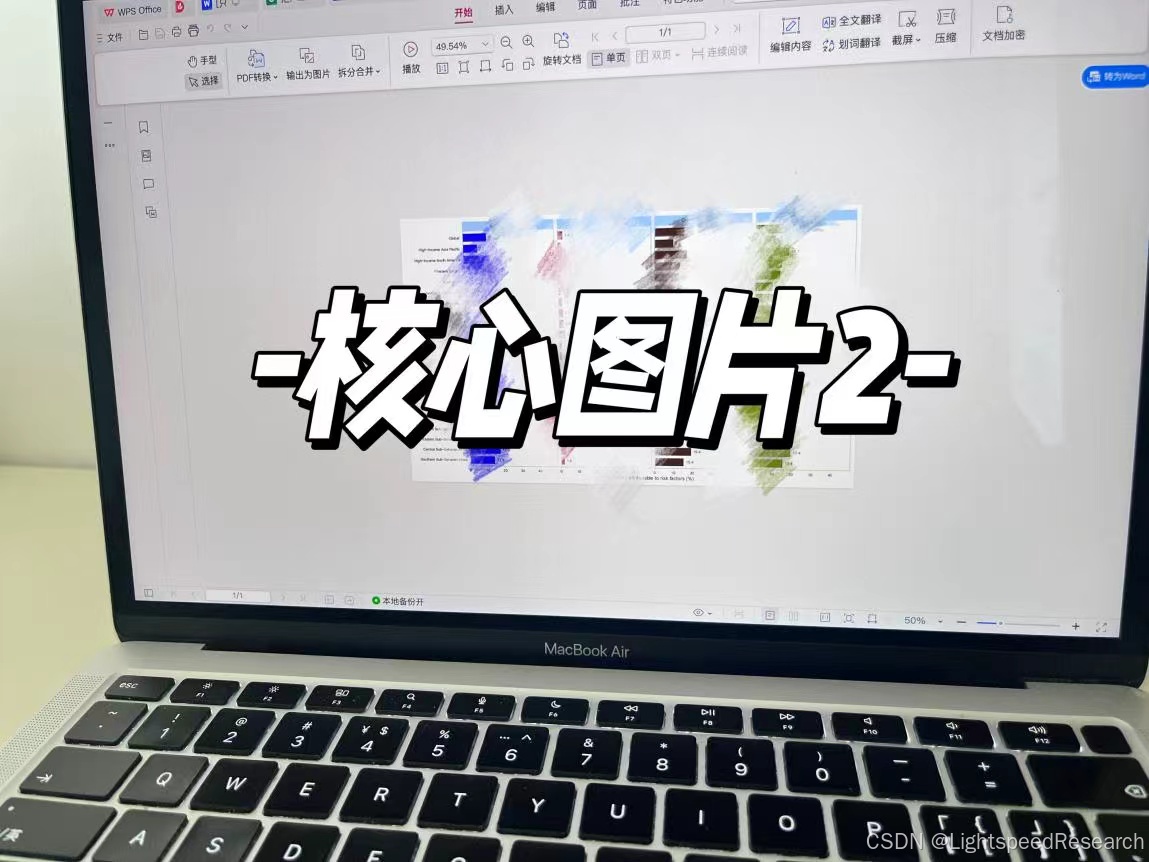
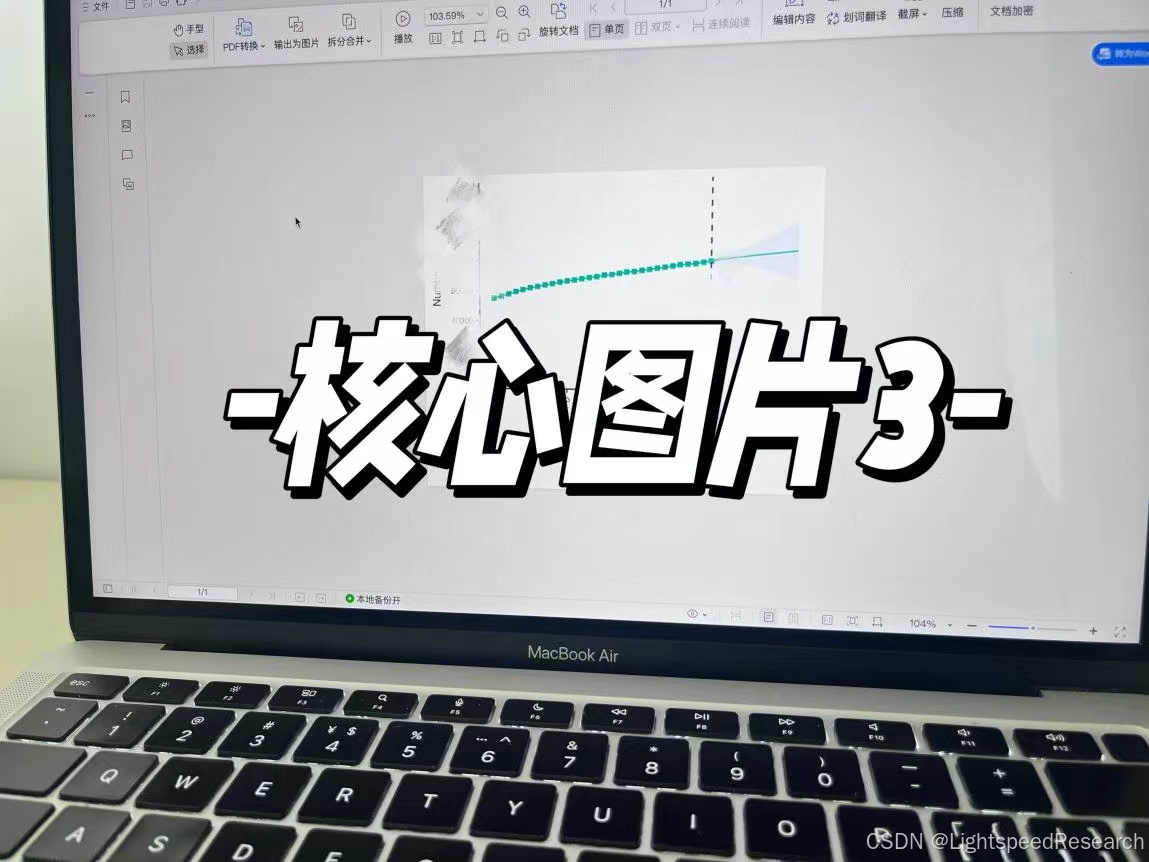
Day 4!
进度汇报:跑出目标图片和表格
数据已经下载完啦,现在要做的就是数据的可视化,根据目标文献跑出核心图片和表格。
GBD的代码比MR和NHANES都要复杂的多,往往一个小细节错误,就会造成不停的报错报错!
不过掌握我们的方法,可以万能的处理一切代码报错问题~
许多师弟师妹会问:GBD里就这几种疾病,我想做的都被别人做过了怎么办?这个问题其实很好解决,比如这篇文章用的是到2019年的数据,那么你完全可以用更新到2021年的数据来分析,并且加入一些新的方法,如预测模型等,还可以限制地区和国家,比如只关注亚洲人群或者中国。或者只关注青年人?中年人或者老年人?
根据我们提供的代码,稍作修改就跑完图片和表格啦!
这就是GBD文章的主要结果啦,下载好数据以后,后面的分析实际上是非常简单的,选题才是最重要、最费时间的,也是最容易浮躁滴,静下来,方向对了,就一定能出成果。
今日份挑战成功~大家的进展怎么样呀!



Day5!
进度汇报:完成文章写作+投稿
结果部分的核心表格和图片完成后,后面就是写作啦!根据我们的“框架写作法”,写作其实是坠简单的,前期挑战的NHANES、孟德尔以及Meta等,我们都能在1天之内挑战成功,GBD也不例外!掌握了以后,任何类型的文章都不在话下!
在正式写作前,我会先阅读几篇同类型同方法的文章,然后去仔细解读目标文献,对这个期刊的行文逻辑以及格式有了大致的了解后,便开始动手啦~
趁着周末,留可以留出一天完整的时间给写作,准备好零食和奶茶后就开始动手啦!意料之内,这次也在1天之内写完了初稿~
最后跟着目标期刊的投稿要求,
调整文章格式、加引用,
以及把图片和结果放进去就好啦!
准备投稿咯!
光速完成一篇GBD,挑战成功!!!

















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









