








这篇文章是2016年的CVPR,虽然目前来说在性能和计算效率上并不佳,但是在当时来说是一种通过较少模型参数加深网络来提升SR表现力的新方法——Deeply-Recursive Convolutional Network(DRCN)。不同于通过增加卷积层数来加深模型,DRCN通过一个递归子模块在共享模型参数下加深网络(类似于循环神经网络RNN),从而可以提取到更多不同层级的用于重建高分辨率图像的特征。
参考文档:
①文章转载于博主暖风的一篇文章——超分算法DRCN。
Deeply-Recursive Convolutional Network for Image Super-Resolution
Abstract
- 作者采用递归的方式来增加超分网络的深度,该结构不仅带来了深度优势来增加表现力,而且由于共享参数来较少计算复杂度和存储资源。
- 作者指出本文提出的DRCN实现了较深的网络,实现了16个递归块。
- 但是类似于RNN,这种递归结构天然存在梯度消失或者梯度爆炸问题,故作者又引入了递归监督、skip connection来缓解递归结构难以训练的问题。
- DRCN就是一种基于递归结构,使用递归监督和跳跃连接的SISR深度网络模型,其在Set4、Set14、B100、Urban100上较之前的算法拥有更好的表现能力。
1 Introduction
发现问题:
超分就是恢复图像细节的过程,而这些细节的推断很大程度取决于网络的感受野大小,较大的感受野拥有更多的信息,可以被用来重建图像。而感受野的增加往往取决于网络的深度,为了增加深度,一般的做法是堆叠卷积层或者块(residual block、dense block等),但是这种做法会增加网络的模型量,而且在有限的数据集下很难训练出较高表现力的网络参数。
Note:
- 在超分中,一般不使用池化层,因为池化会丢失图像信息,而细节对于图像重建是至关重要的。
解决办法:
DRCN为了增加感受野,也是朝着增加网络深度方向走的。具体而言,为了增加感受野同时避免较大的模型参数,作者提出了一个递归结构,类似于RNN中的细胞,该递归结构重复使用同一套参数来不断提取特征信息,作者指出DRCN的感受野可以达到
41
×
41
41\times 41
41×41,比SRCNN的
13
×
13
13\times 13
13×13要高出3倍还要多!但是递归结构会存在梯度爆炸或梯度消失现象,因此光一个递归结构还不足以实现一个高表现力的超分网络,故作者在递归子网络的基础上,增加了递归监督和跳跃连接来缓解这一现象。
Note:
- Skip connection除了缓解梯度消失爆炸问题以外,还可以进行多特征信息的跨层融合以及迫使网络学习残差结构部分的信息。
小结一下:
DRCN的核心就是通过递归结构来加深网络,提取更多层次的特征信息;用递归监督和跳跃连接缓解梯度爆炸或梯度消失问题。
2 Related Work
略
3 Proposed Method
作者先介绍只基于递归结构的Basic Model;然后引入递归监督和skip connection,即3.2节的Advanced Model。
3.1 Basic Model

整个DRCN网络分为三部分:①Embedding层②前向网络③重建层。
RDCN的pipeline:
我们设
x
,
y
,
y
^
,
f
1
,
f
2
,
f
3
x,y,\hat{y},f_1,f_2,f_3
x,y,y^,f1,f2,f3分别为上采样之后的输入、x对应的高分辨率版本、DRCN预测的结果、Embedding层、前向网络函数、重建层函数,则DRCN可表示为:
f
(
x
)
=
f
3
(
f
2
(
f
1
(
x
)
)
)
f(x) = f_3(f_2(f_1(x)))
f(x)=f3(f2(f1(x)))。
接下来我们具体分析每一部分:
①Embedding层
Embedding层用于提取浅层特征以及作为前向网络的输入。RDCN一共设置了2个卷积层,其表达式为:
H
−
1
=
m
a
x
(
0
,
W
−
1
∗
x
+
b
−
1
)
,
(1)
H_{-1} = max(0, W_{-1}*x +b_{-1})\tag{1},
H−1=max(0,W−1∗x+b−1),(1)
H
0
=
m
a
x
(
0
,
W
0
∗
H
−
1
+
b
0
)
(2)
H_0 = max(0, W_{0}*H_{-1} + b_0)\tag{2}
H0=max(0,W0∗H−1+b0)(2)总结一下就是
H
0
=
f
1
(
x
)
H_0 = f_1(x)
H0=f1(x)。
②前向网络
前向网络用于提取深层特征以及作为重建层的输入。前向网络是RDCN的核心,它是一个递归层,其在加深网络增大感受野的同时,让每一次递归都共享同一套参数。我们设
g
(
⋅
)
g(\cdot)
g(⋅)为前向网络每一次的递归算子,则第
d
∈
{
1
,
⋯
,
D
}
d\in\{1, \cdots, D\}
d∈{1,⋯,D}次递归可表达为:
H
d
=
g
(
H
d
−
1
)
=
m
a
x
(
0
,
W
∗
H
d
−
1
+
b
)
.
(3)
H_d = g(H_{d-1}) = max(0, W*H_{d-1} + b).\tag{3}
Hd=g(Hd−1)=max(0,W∗Hd−1+b).(3)整个前向网络是
D
D
D次递归的总和,故表达式可以写为:
H
D
=
f
2
(
H
0
)
=
(
g
∘
g
∘
⋯
g
∘
g
)
g
(
H
0
)
=
g
D
(
H
0
)
.
(4)
H_D = f_2(H_0) = (g\circ g\circ\cdots g\circ g ) g(H_0) = g^D(H_0).\tag{4}
HD=f2(H0)=(g∘g∘⋯g∘g)g(H0)=gD(H0).(4)
③重建层
将前向网络的输出进行优化调整或进行校正来进一步提升网络的非线性度,增加表现力。此外通过重建层的最后一层来调整输出通道数为3(RGB通道数)或1(有时只训练灰度通道)。重建层可以看成是Embedding层的反向操作,其表达式为:
H
D
+
1
=
m
a
x
(
0
,
W
D
+
1
∗
H
D
+
b
D
+
1
)
,
(5)
H_{D+1} = max(0, W_{D+1}*H_D + b_{D+1}),\tag{5}
HD+1=max(0,WD+1∗HD+bD+1),(5)
y
^
=
m
a
x
(
0
,
W
D
+
2
∗
H
D
+
1
+
b
D
+
2
)
.
(6)
\hat{y} = max(0, W_{D+2}*H_{D+1} + b_{D+2}).\tag{6}
y^=max(0,WD+2∗HD+1+bD+2).(6)总结一下就是
y
^
=
f
3
(
H
)
\hat{y} = f_3(H)
y^=f3(H)。
Note:
- DRCN没有上采样层,是因为它和SRCNN一样,直接在输入端进行插值(如bicubic上采样),后续的特征提取直接是在HR层级上进行的。
- 除了最后一层卷积层外,其余所有卷积层都是用 3 × 3 × F × F 3\times 3\times F \times F 3×3×F×F的滤波器以及ReLU函数。
- 输入可以是 C = 3 C=3 C=3的RGB图像,也可以是 C = 1 C=1 C=1的灰度图像。
上述的Basic Model虽然结构简单、参数量少,但是其存在3个问题:
- 梯度消失/爆炸。DRCN中的递归层其实是和RNN一样的结构,每一次递归的特征信息 H d , d ∈ { 1 , ⋯ , D } H_d,d\in\{1,\cdots,D\} Hd,d∈{1,⋯,D}可以看成是时间序列,因此递归层的参数梯度会随着递归次数(RNN中的时间 T T T)呈指数式变化,因此最后就会导致梯度呈指数式下降趋于0或者直接出现很大的梯度值。这是不利于网络训练学习的,因为长序列会让网络很难学习到很久之前的信息,举个例子:对于序列"今天小明先去打篮球,然后又。。。一天终于结束了,洗个澡睡觉了",要求网络从这段序列中学习出预测今天小明先做了什么?那么RNN的做法就是不断将“小明打篮球”这一信息传送到RNN的末端,然后网络开始根据Loss回传梯度,但是序列太长,导致传到小明打篮球的时候,梯度比如说消失为0,那么这时候参数就无法更新,那么无论你训练多久,网络前向时候将打篮球的信息都无法传到RNN末端,也就是说训练从头到尾,“打篮球”传到Loss处的值都是几乎无变化的。因此DRCN的梯度消失或爆炸问题会让网络无法学习到长距离的特征信息,加大了训练的难度以及限制了递归的长度。
- 在递归层中损失太多原图信息。在SR中,输入和输出的差别其实很小,两者的差异大部分都是趋于0,少部分是有差别。我们超分的目的就是补齐输入对于输出损失的那部分细节,甚至有一些SR方法仅仅只是去学习回归出一些细节。而递归的长距离卷积池化过程会损失改变原图的一些细节,比如说物体的位置等等。
- 关于递归最优次数的超参数寻优问题。这个次数决定了递归的长度,对于特征信息的学习是至关重要的,如果太长,就会导致梯度消失爆炸问题,并且会损失原图太多细节;如果太短,那么深层特征信息提取不完全,抑制了最后超分的表现力。
3.2 Advanced Model

- 上图(a)是DRCN最终的模型。作者通过引入递归监督来消除长距离递归导致梯度消失爆炸问题。对于每一次递归,都输出到重建层,作为总和Loss的一部分,也就是说每一次递归都通过监督学习来学习参数,故称之为递归监督。对于 D D D次的递归,最终的Loss由 D D D个小loss通过加权平均得到,当反向传播的时候,每一次递归都会获取属于自己的那一部分梯度,这样就算来自深层递归的梯度消失了,自己的那份也可以用来训练更新参数,这有点类似于Inception-v2网络中的辅助分类器。作者引入skip connection来跨层连接底层特征信息和高层信息,具体而言,DRCN将输入端( H R HR HR层级)特征信息直接输入到重建网络中和来自前向网络的输出相结合,这样做的好处:①可以保存下来原始特征信息,这样的话递归过程中的特征信息损失也无妨;②原始信息通过跨层可以直接参与重建过程,将不同层级的特征信息进行融合来为重建提供更多信息。数学表达式为: y ^ d = f 3 ( x , g ( d ) ( f 1 ( x ) ) ) , d ∈ { 1 , ⋯ , D } . (7) \hat{y}_d = f_3(x,g^{(d)}(f_1(x))),\\ d\in\{1, \cdots,D\}.\tag{7} y^d=f3(x,g(d)(f1(x))),d∈{1,⋯,D}.(7),其中 f 3 ( ⋅ ) f_3(\cdot) f3(⋅)可以表示为将底层和高层信息concat,或者作者提出的 f 3 ( x , H d ) = x + f 3 ( H d ) f_3(x,H_d) = x + f_3(H_d) f3(x,Hd)=x+f3(Hd)也是一种思路,它相当于先将每一次递归的结构进行重建然后和原始输入相结合。此外,作者还引入了注意力机制,这种机制就是本质就是训练一堆权重,这些权重将和每一次递归的结果进行加权从而形成最后的Loss: y ^ = ∑ d = 1 D w d ⋅ y ^ d . (8) \hat{y} = \sum^D_{d=1}w_d \cdot \hat{y}_d.\tag{8} y^=d=1∑Dwd⋅y^d.(8),这里之所以我引入了注意力的说法,是因为这就好像是通过学习权值 w d w_d wd来选择最优的递归次数一样,比如当递归次数太深了,那么深层递归所获取的权重就会很小,而浅层递归的权值就高,那么就自动过滤掉了高层的递归输出,变向选择最佳递归次数(这种思想就和Robust-LTD中通过注意力机制学习权值map,从而选择最优的时间尺度(时间窗口))。通过学习这些权值我们就可以不怎么去考虑最优递归次数这个超参数的调节问题了!
- 上图(b)是Deeply-Supervised Nets这篇文章提出的一种结构。在递归部分和RDCN是类似的,共享网络参数,但是不同的是对于每一次递归,它都用一个个独立的分类器来做监督,并且重建层需要 D D D个不同的层,这样就会大大增加模型的参数。此外,(b)丢弃了中间递归的结果,要知道中间的递归结构对于后续重建也是很有帮助的。
- 上图©的参数量就更大了,它就不是递归结构了,因为它的将(a)中参数共享的递归结构拆开了,执行 D D D次并行的特征提取,对第 d ∈ { 1 , ⋯ , D } d\in \{1,\cdots, D\} d∈{1,⋯,D}次特征提取,都使用 d d d层来做,这种做法类似于(a),但它将每一次递归的重要性都看成是一样的,但是参数量还是很大的。
3.3 Training
DRCN的Loss部分分为递归Loss(递归监督)和综合Loss两部分,他们都基于MSE损失函数,具体的:
对于递归监督部分:
l
1
(
θ
)
=
∑
d
=
1
D
∑
i
=
1
N
1
2
D
N
∣
∣
y
(
i
)
−
y
^
d
(
i
)
∣
∣
2
.
(9)
l_1(\theta) = \sum^D_{d=1}\sum^N_{i=1}\frac{1}{2DN} ||y^{(i)} - \hat{y}_d^{(i)}||^2.\tag{9}
l1(θ)=d=1∑Di=1∑N2DN1∣∣y(i)−y^d(i)∣∣2.(9)其中
D
D
D为递归次数(深度),
N
N
N为样本个数。
D
D
D次递归中,每一次递归的输出都被同一个标签
y
(
i
)
y^{(i)}
y(i)指导训练。
那么对于综合的总Loss:
l
2
(
θ
)
=
∑
i
=
1
N
1
2
N
∣
∣
y
(
i
)
−
∑
d
=
1
D
w
d
⋅
y
^
d
(
i
)
∣
∣
2
.
(10)
l_2(\theta) = \sum^N_{i=1}\frac{1}{2N} ||y^{(i)} - \sum^D_{d=1}w_d\cdot \hat{y}_d^{(i)}||^2.\tag{10}
l2(θ)=i=1∑N2N1∣∣y(i)−d=1∑Dwd⋅y^d(i)∣∣2.(10),我们最终训练的时候要将这两种Loss进行结合,具体表达为:
L
(
θ
)
=
α
l
1
(
θ
)
+
(
1
−
α
)
l
2
(
θ
)
+
β
∣
∣
θ
∣
∣
2
.
(11)
L(\theta) = \alpha l_1(\theta) + (1-\alpha)l_2(\theta) + \beta||\theta||^2.\tag{11}
L(θ)=αl1(θ)+(1−α)l2(θ)+β∣∣θ∣∣2.(11)其中
α
、
β
=
1
0
−
4
\alpha、\beta=10^{-4}
α、β=10−4都是超参数,
∣
∣
θ
∣
∣
2
||\theta||^2
∣∣θ∣∣2是正则化项,抑制过拟合。
4 Experiments
4.1 Datasets
- 训练集:91张图片,来自于这篇文章。
- 测试集:Set4、Set14、B100、Urban100。
4.2 Training Setup
- 递归次数为16,故DRCN一共有 ( 2 + 16 + 2 ) = 20 (2+16+2)=20 (2+16+2)=20层,产生 21 × 21 21\times 21 21×21的感受野。
- 所有卷积层都使用256个 3 × 3 3\times 3 3×3的格式。
- Batch=64,一般来说,SISR的Batch包括 n n n张随机图片;VSR的Batch包括 n n n张连续 m m m帧的图片。
- 非递归层的参数初始化参考这篇文章;递归层(除了self-connection神经元之外)的参数全部归零。
- 学习率初始化为0.01,之后在验证集上如果连续5个epochs都无法让loss下降,那么就衰减10倍,当学习率小于 1 0 − 6 10^{-6} 10−6,那么训练终止。
- RDCN的输入可以是RGB,也可以是灰度图像。
4.3 Study of Deep Recursions
①第一项研究是最佳的递归深度,作者设置了
D
=
1
,
6
,
11
,
16
D=1,6,11,16
D=1,6,11,16,实验结果如下:

实验结论:
- 递归深度越深,对表现力的提升越好,但是到了较大深度的时候,表现力提升不大,这可能是因为当前数据集的数量和质量限制了模型复杂度;此外递归监督只能是缓解而不是消除递归导致的梯度消失爆炸,故个人认为太深也会影响到表现力。
②第二项研究递归监督的作用,在
×
2
、
×
3
、
×
4
\times 2、\times 3、\times4
×2、×3、×4三种SR缩放倍率下,比较单次递归和将多次递归结果集成(Ensemble)的效果,实验结果如下:
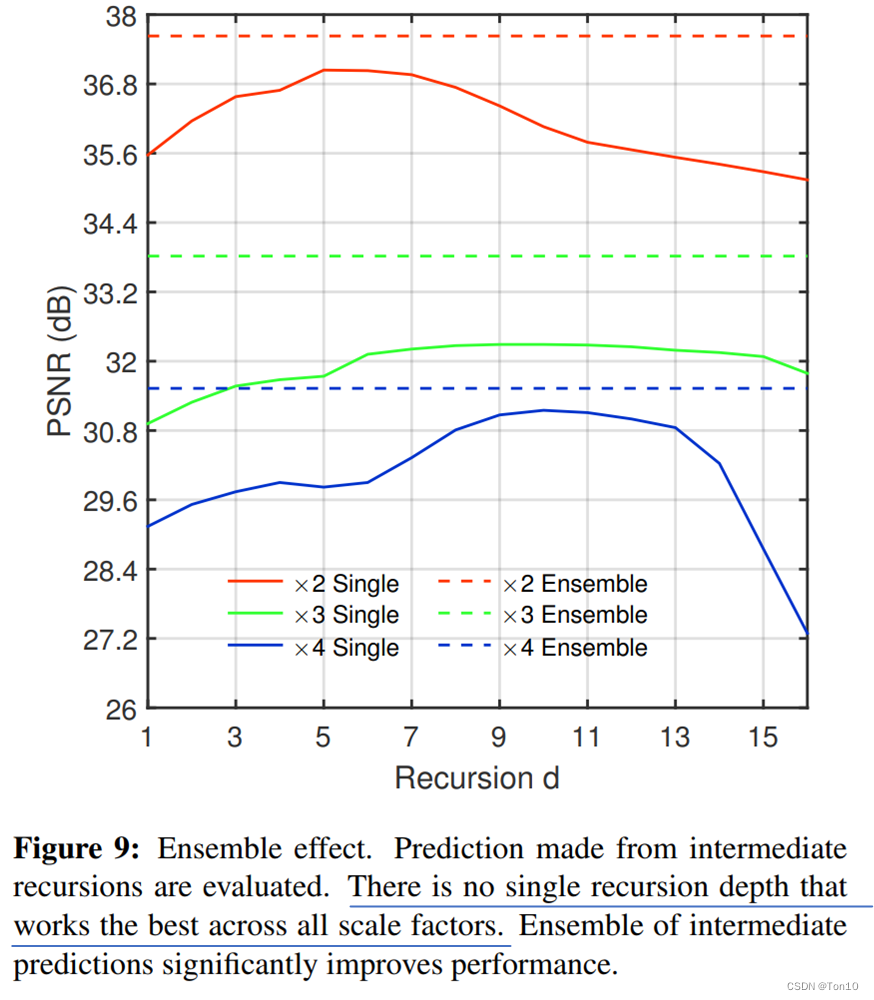
实验结论:
- 不管是哪种尺度下,多次递归的集合都比单次要好,证明了递归监督的重要性。
- 此外,越高尺度的PSNR越低,这是因为高尺度要恢复的细节信息越多,对SR网络性能的要求越严。
4.4 Comparisons with SOTA Methods
本节是DRCN和其他SISR的对比,实验结果如下:


实验结论如下:
- DRCN在四个测试集上相对其余几种超分方法取得了SOTA表现。
- DRCN除了在评价指标上的优势,在图片视觉上,尤其是边缘的超分也做得不错。
5 Conclusion
- 本文提出了一种利用递归结构加深网络的超分方法——
DRCN。DRCN通过 D D D次递归提取网络多个层级的特征信息来提升图像重建的表现力。DRCN递归结构共享模型参数以及共享重建层,从而控制住了网络总体参数量。 - 为了解决递归带来的梯度消失爆炸问题,作者添加递归监督,通过对每一次递归都直接参与到Loss部分来辅助监督;为了解决递归损失太多图像原始信息,作者引入skip connection来将底层信息和高层信息融合且同时保存下来了原始输入的信息,从而避免卷积过程造成的原始信息损失;此外,作者通过在末端对不同递归深度学习相应的权重,作为一种注意力机制来控制一定的递归深度。
- DRCN一大缺陷就是它的特征提取都是基于 H R HR HR层级,而计算复杂度是和输入图像成正比的,故DRCN直接对输入图像先做上采样的做法会大大降低模型训练效率,此外当缩放倍率大于3之后,对 H R HR HR提取的特征是冗余的,就是说对 H R HR HR提取的特征和直接对 L R LR LR提取的特征其实差别不大。因此DRCN这种处理就显得既没必要还低效。















 4756
4756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









