







 本文详细介绍了Kafka_2.11的安装配置过程,包括解压、配置环境变量、发送到集群节点、配置server.properties文件(如修改监听端口、Zookeeper连接、broker ID及日志目录),以及启动和关闭Kafka server的方法。
本文详细介绍了Kafka_2.11的安装配置过程,包括解压、配置环境变量、发送到集群节点、配置server.properties文件(如修改监听端口、Zookeeper连接、broker ID及日志目录),以及启动和关闭Kafka server的方法。
准备工作
先从官网上下载好该版本的安装包,并上传到集群中任意一台主机(我上传到了master上)
1 安装配置
1.1 解压
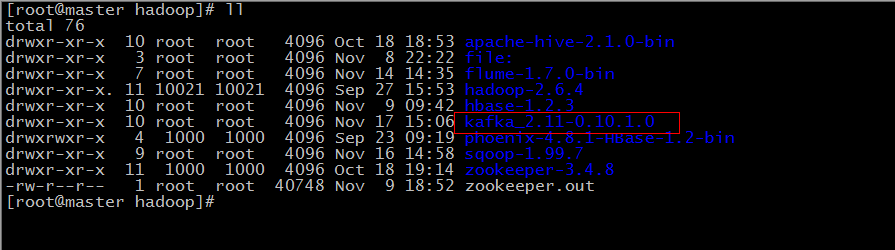
我是放到 /usr/hadoop 目录下的,解压之后会多出来一个 kafka_2.11-0.10.1.0 的目录
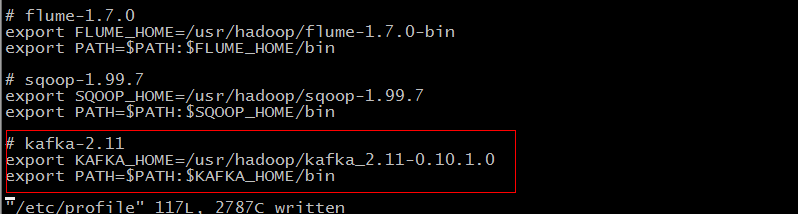
1.2 配置环境变量
在 /etc/profile 中添加如下配置
使环境变量生效
[root@master hadoop]# source /etc/profile
[root@master hadoop]#1.3 发送到集群中其他节点
这时候把我们的 /etc/profile 发送到 slave1、slave2 节点上:
[root@master hadoop]# scp /etc/profile root@slave1:/etc/
...
[root@master hadoop]# scp /etc/profile root@slave2:/etc/
...
发送 kafka 整个文件夹到 slave1、slave2 节点上:
[root@master hadoop]# scp -r kafka_2.11-0.10.1.0 root@slave1:/usr/hadoop
...
[root@master hadoop]# scp -r kafka_2.11-0.10.1.0 root@slave2:/usr/hadoop
...
1.4 配置 server.properties
其实单节点的 kafka 是不用修改这个文件的,直接仿照官网的介绍就可以了,但是我们搭建的是一个集群。这里的配置文件需要修改,有三四处吧。
1.4.1 打开监听端口
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = security_protocol://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092 # 取消这一行的注释1.4.2 修改 zookeeper.connect
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=master:2181,slave1:2181,slave2:2181 # 修改成为我们搭建的zookeeper集群
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









