







池化层也叫下采样层,对输入的特征图进行压缩,1.使特征图变小,简化网络计算复杂度;2.进行特征压缩,提取主要特征;3.降低过拟合,减小输出大小的结果,它同样也减少了后续层中的参数的数量。其具体操作与卷基层的操作基本相同,只不过下采样的卷积核为只取对应位置的最大值、平均值等(最大池化、平均池化),并且不经过反向传播的修改。
pooling的结果是使得特征减少,参数减少,但pooling的目的并不仅在于此,pooling目的是为了保持某种不变性(旋转、平移、伸缩等)
根据相关理论,特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
mean-pooling能减小第一种误差(邻域大小受限造成的估计值方差增大),更多的保留图像的背景信息,
max-pooling能减小第二种误差(卷积层参数误差造成估计均值的偏移),更多的保留纹理信息。
Stochastic-pooling则介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行亚采样,在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
池化层的分类
一般池化(General Pooling)
其中最常见的池化操作有平均池化、最大池化:
平均池化(average pooling):计算图像区域的平均值作为该区域池化后的值。
最大池化(max pooling):选图像区域的最大值作为该区域池化后的值。
重叠池化(OverlappingPooling)
重叠池化就是,相邻池化窗口之间有重叠区域,此时一般sizeX > stride。
空金字塔池化(Spatial Pyramid Pooling)
空间金字塔池化的思想源自 Spatial Pyramid Model,它将一个pooling变成了多个scale的pooling。用不同大小池化窗口作用于上层的卷积特征。也就是说 spatital pyramid pooling layer就是把前一卷积层的feature maps的每一个图片上进行了3个卷积操作,并把结果输出给全连接层。其中每一个pool操作可以看成是一个空间金字塔的一层。(具体的细节可以看下面的参考链接,讲的比较详细)
这样做的好处是,空间金字塔池化可以把任意尺度的图像的卷积特征转化成相同维度,这不仅可以让CNN处理任意尺度的图像,还能避免cropping和warping操作,导致一些信息的丢失,具有非常重要的意义。
池化层的反向传播
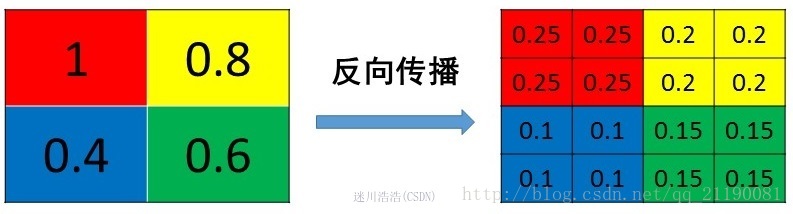
原则:把1个像素的梯度传递给4个像素,但是需要保证传递的loss(或者梯度)总和不变
mean pooling
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下
mean pooling比较容易让人理解错的地方就是会简单的认为直接把梯度复制N遍之后直接反向传播回去,但是这样会造成loss之和变为原来的N倍,网络是会产生梯度爆炸的。
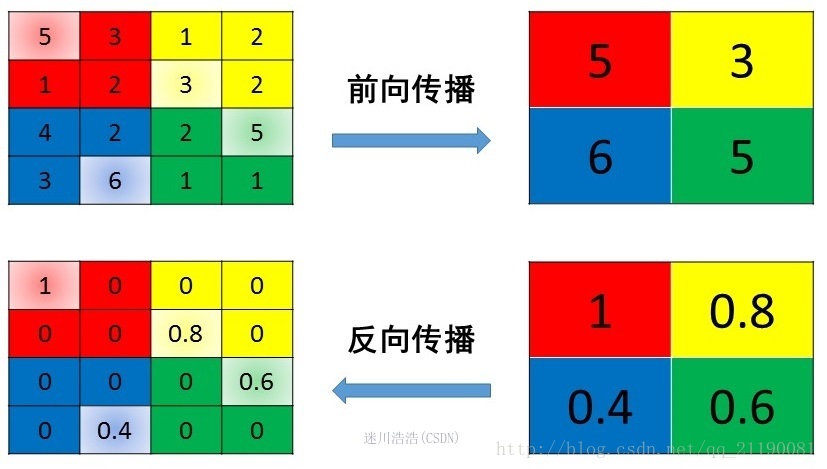
max pooling
max pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大
源码中有一个max_idx_的变量,这个变量就是记录最大值所在位置的,因为在反向传播中要用到,那么假设前向传播和反向传播的过程就如下图所示















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









