






池化层(Pooling layer)
在CNN中负责特征选择,池化层通常也叫做子采样(subsampling)或降采样(Downsampling)。对输入的特征图(Feature Map)进行压缩,一方面使特征图变小,简化网络计算复杂度和所需显存;一方面进行特征压缩,提取主要特征。就是将输入图像进行缩小,减少像素信息,只保留重要信息。
池化层会不断地减小数据的空间大小,往往是用在卷积层之后,通过池化层来降低卷积层输出的特征维度,在有效减少网络参数的同时还可以防止过拟合现象。
池化层的功能
特征不变形:池化操作是模型更加关注是否存在某些特征而不是特征具体的位置。
特征降维:池化相当于在空间范围内做了维度约减,从而使模型可以抽取更加广范围的特征。同时减小了下一层的输入大小,进而减少计算量和参数个数。
在一定程度上防止过拟合,更方便优化。
常用的池化操作有四种:
1、平均池化(mean-pooling)
2、最大池化(max-pooling)
3、随机池化(Stochastic-pooling)
4、全局平均池化(global average pooling)
1、最大池化(max-pooling)
最大池化是采用较多的一种池化过程,优点是能很好的保留纹理特征。通常情况下,池化都是2x2大小。
最大池化过程:对一个 4×4 feature map邻域内的值,用一个 2×2 的filter,步长为2进行扫描,选择最大值输出到下一层。正向传播的最大池化过程如图所示
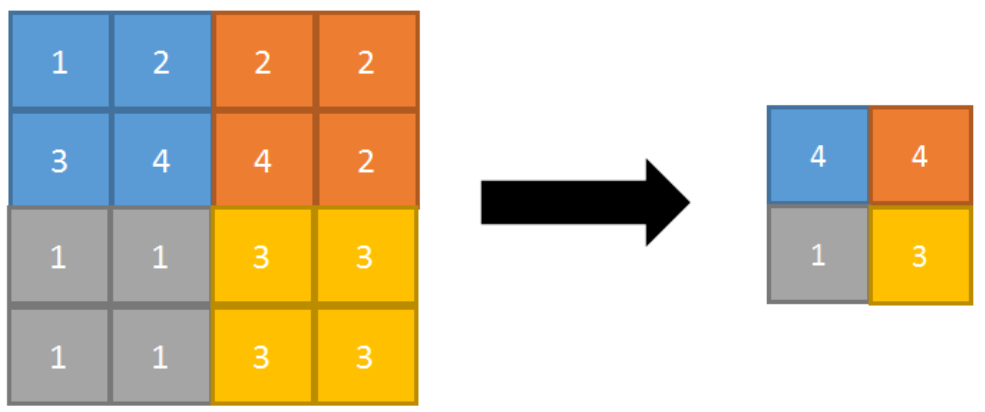
步长为1的正向最大池化如图所示
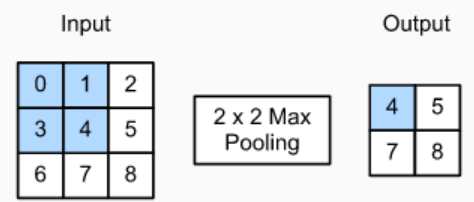
正向传播是取邻域内最大值,并标记最大值的索引位置,以便反向传播。
反向传播:将特征值填充到正向传播中,值最大的索引位置,其他位置补0。如下图所示

2、平均池化(Average Pooling)
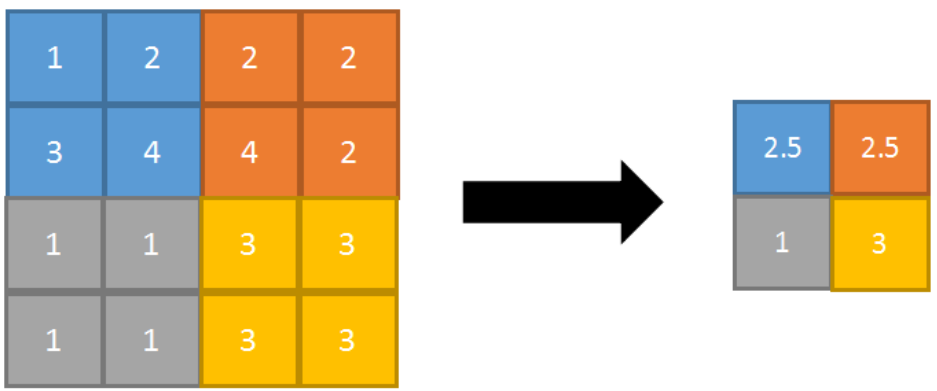
其特点是能很好的保留背景,但容易使得图片变模糊。平均池化过程:对一个 4×4 feature map邻域内的值,用一个 2×2 的filter,步长为2进行扫描,计算平均值输出到下一层。
正向传播的平均池化过程如图所示
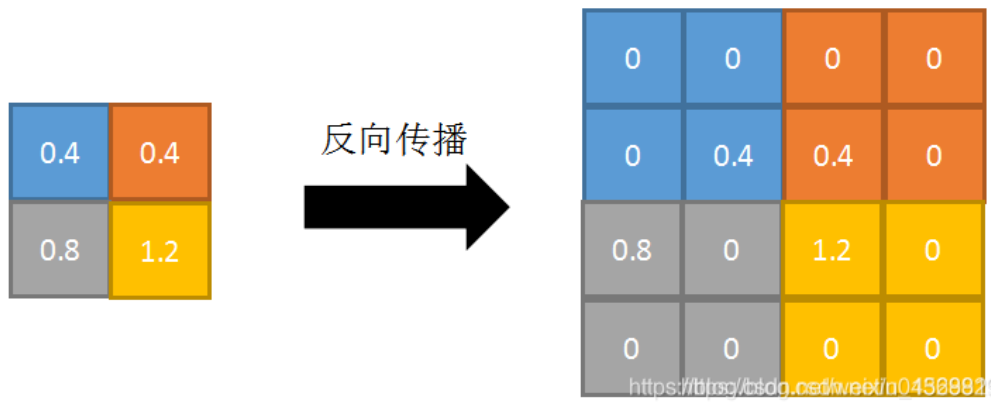
反向传播:特征值根据领域大小被平均,然后传给每个索引位置。如图所示
in the end
将之前所提到的卷积、激活、池化放在一起就形成了一个简单的神经网络,然后我们加大网络的深度,增加更多的层,就得到深度神经网络了。

reference:















 9893
9893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









