






好几次笔者和别人说起自己在研究玻璃存储的时候,经常会被问到“为什么不去研究一下DNA存储”?近半年和投资人交流过程中,至少有三位投资人都说他们暂时不考虑玻璃存储方向,但已经投了DNA存储团队。同样是当前三大数据存储发展方向(玻璃存储、全息存储和DNA存储)之一,差距为什么就这么大呢?女怕嫁错郎,男怕入错行,笔者真有一种“悔不该当初选择机电自动化专业,为什么不选择生物专业”的痛心疾首感!
说实话,笔者真心不想写DNA存储方向的文章,因为一边写一边心在滴血,特别是冠以“DNA存储:数据存储的终极解决之道”这样的标题。无奈树欲静而风不止,最近又被《中国档案报》刺激了一下,让笔者意识到,躲是躲不过去的,该来的终究会来。我们必须得承认,DNA存储的想象空间远超玻璃存储和全息存储,但在三大数据存储发展方向中,目前来看成熟度相对最高,最有希望率先商用落地的应该还是玻璃存储,咱也无需妄自菲薄。另外毕竟术业有专攻,DNA存储再好,也肯定不是咱的菜。
DNA存储背景情况
《中国档案报》2022年6月6日第三版刊发了一篇《全球首例:储存在DNA上的数字档案已存入法国国家档案馆》的文章,其中写道:“法国国家档案馆将成为全球首个储存DNA文件的公共机构,法国国家档案馆馆长表示:‘数据存储已成为档案馆面临的关键挑战之一,法国国家档案馆目前存储了超过70TB的数据,几年后应该会超过200TB,对存储容量的需求巨大。’而DNA具有成为理想存储介质的主要特征,包括稳定持久(可保持数十万年)、高度浓缩(数十亿份文件在一个微胶囊中),而且不消耗物质能量。目前的数字存储系统主要是将文本、照片或其他类型的信息编码为二进制数据,同样地,这些信息也可以使用构成遗传密码的4种核苷酸在DNA中实现编码。具体来说,DNA存储主要是使用DNA驱动器算法将二进制数据(0或1)转换为DNA对应的4种核苷酸,然后在DNA片段上合成核苷酸序列,最后以冷冻干燥的方式封装在DNA金属胶囊中,读取时再将其转换回二进制数据。”
事实上,DNA存储已被写入2021年3月发布的《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》:“加快布局量子计算、量子通信、神经芯片、DNA存储等前沿技术,加强信息科学与生命科学、材料等基础学科的交叉创新”,这是玻璃存储和全息存储所无法企及的高度,也难怪投资机构只对DNA存储情有独钟了。
DNA存储介绍
首先我们来具象化地描述一下DNA存储,可以设想这样一个场景:一个1亿年前的琥珀化石最近被发现了,中间封存着一只蚊子,假设这只蚊子的DNA中存储了1亿年前的地球数据,那么现在的人类将这些数据读取出来之后徐徐展开的是否就是1亿年前恐龙时代的壮美图景?

这不仅仅是好莱坞大片《侏罗纪公园》中的场景,DNA存储就是如此地令人心潮澎湃、壮怀激烈,否则怎么配得上“数据存储的终极解决之道”的称谓呢?
当然,DNA存储也不是什么新概念,上世纪80-90年代就已经有人在研究了,但受制于当时的技术条件,并没有取得大的突破和进展。一直到最近几年,研究人员将DNA分子存储领域与DNA合成与测序技术、细胞生物学与分子生物学技术、信息科学与通信技术等领域不断交叉融合,才为这一领域的未来描绘出更多的可能性,不断提高DNA分子的存储潜力,使得DNA数据存储越来越接近于生产和生活实际。
这其中,微软研究院和华盛顿大学合作的自动DNA数据存储技术走在了业界前列:
DNA存储原理
DNA存储的原理也不复杂,就是用人工合成的DNA存储文本、图片、声音、视频文件等数据,随后完整读取的技术。目前计算机存储的数据都是依据电压的高和低代表0和1来表示的,DNA存储则是把原本这些用0和1来表示的内容换成用碱基:A,C,G,T来表示,简而言之就是用遗传代码替代计算机代码,实现从数字信号转换到化学信号的过程。当复制一份计算机文件时,DNA数字存储系统首先把硬盘信息中的二进制数翻译成定制代码,然后借助标准DNA合成机器制造出相应的碱基序列。
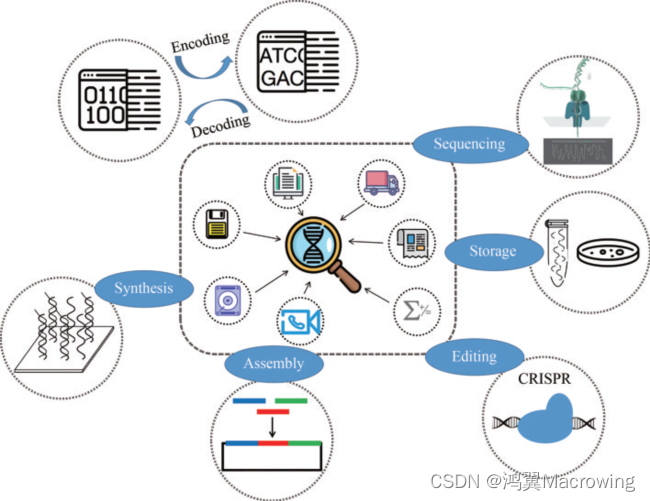
DNA存储优势
利用人工合成的DNA作为存储介质具有以下三方面突出优势,因此被称为“数据存储的终极解决之道”:
信息密度高
据微软研究院此前估计,1立方毫米的DNA就能够存储1个EB(ExaByte,1,024 PB,1,048,576 TB)的数据;更有夸张的说法是号称1克DNA就可以存下全球信息。
存储时间长
在合适的条件下,可以存储上万年;像琥珀这种极端存储条件下甚至可以存储上亿年。
能耗低
不需要维护成本。存储所需要的占地,资源,能耗均远远小于传统存储介质,而且几乎不需要后期维护,尤其适用于存储大规模不需要经常访问的“冷数据”。
DNA存储流程
DNA数据存储过程大致可以分成四个步骤:信息编码、DNA 合成(写入)、DNA 测序(读取)和信息解码。如下图所示:
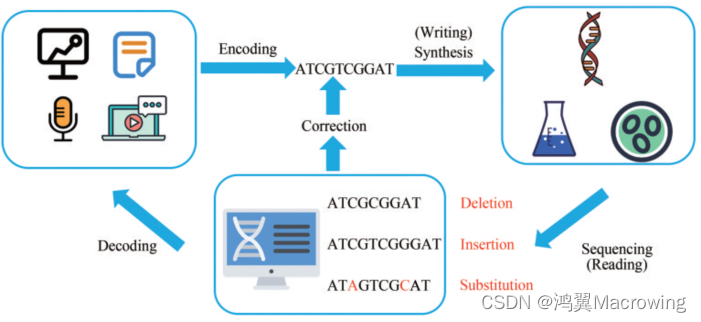
首先必须将数据转换为DNA分子中4种碱基的序列。在信息科学领域,不同的数据类型有不同的编码和压缩算法,常用的算法有霍夫曼编码、算术编码、字典编码等。此外,对于DNA分子而言,在合成、复制、测序的过程中都可能发生错误,物理冗余和逻辑冗余可以帮助在信息失真的情况下恢复原始数据,也就是纠错码。
在编码之后,进行DNA合成,即写入。三代DNA合成技术——化学合成法(固相亚磷酰胺化学法)、微阵列DNA合成法和酶合成法的演化大大减少了DNA 合成的时间和成本。另外,基因组装和编辑技术的发展让我们可以灵活而准确地改变遗传信息,并在活细胞中进行数据处理和储存,为DNA数据存储技术的发展提供了有利的条件。
信息的读取依靠基因测序技术。自1977 年第一代DNA 测序技术(Sanger 法)出现以来,测序技术已获得了巨大的发展,相比于最初,其成本下降了几个数量级。通过测序恢复碱基序列,根据编码规则可以预判数据恢复能力。
在得到DNA序列信息之后,将碱基序列重新转换为二进制序列;此后,再利用编码的纠错原理将序列自动纠错,就可以得到原始的数字信息。
待解决问题
DNA存储无疑有希望成为一项划时代的存储技术,它的很多特性和现有存储技术相比都是颠覆性的。但这项技术目前远未成熟,或许离真正商用还需要20年,甚至更长;或许有可能过程中碰到一个难以突破的技术瓶颈导致中途夭折;或许过程中出现另外一项更具革命性的存储技术,比如量子存储,形成降维打击。

由于信息技术发展太快,谁也无法准确预测10年、20年之后的事情,对于DNA存储而言,要想尽快得到应用,现阶段至少还需要解决以下三方面问题:
读写速度太慢
根据美国佐治亚大学研究团队的实验数据,以目前的技术在合成DNA时,每添加一个碱基大约需要0.1秒钟时间,按照这个速度推算,保存一首高音质的MP3歌曲都需要差不多1个月时间;读取速度虽然没有这么夸张,但需要配备专用设备,既无法实现便携式操作,也无法实时读取。
成本太高
根据美国哥伦比亚大学研究团队的测算,目前合成2MB的DNA数据需要7000美元,读取数据需要2000美元,如果用户需要以DNA形式存储1GB大小的一部电影,编码大约需要花费358万美元,而读取数据还需要102万美元,这还不算设备本身的成本!
合成DNA的稳定性
合成DNA过程中产生的错误率在当前技术条件下还是不低的,尽管有冗余设计和纠错码,但还是会造成部分数据失真,更不用说基因突变之类的不可控因素,这对于要求确保100%真实性和完整性的数据存储指标而言是致命的问题。
DNA存储超出了笔者的知识领域,以上很多数据和说法来自网络,笔者也没有能力鉴别真伪,存在纰漏和错误之处恳请读者见谅。不管怎么说,数字资源长期保存技术是数字罗塞塔计划项目的核心研究内容
















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









