







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言(Preface)
注意:本文与《Convex Optimization》的Convex/Concave Function定义相同,但与同济大学《高等数学》的定义相反.
凸问题(Convex Problem)
凸问题的一般形式:
min
f
(
x
)
s.t.
h
i
(
x
)
=
0
,
∀
i
=
1
,
.
.
.
,
n
g
i
(
x
)
≤
0
,
∀
j
=
1
,
.
.
.
,
m
\begin{aligned} \min~ &f(x)\\ \text{s.t.~} &h_i(x) = 0, \forall i =1,...,n \\ &g_i(x) \leq 0, \forall j =1,...,m \end{aligned}
min s.t. f(x)hi(x)=0,∀i=1,...,ngi(x)≤0,∀j=1,...,m 其中,目标函数
f
(
x
)
f(x)
f(x)是凸函数,等式约束
h
i
(
x
)
h_i(x)
hi(x)为仿射,不等式约束
g
i
(
x
)
g_i(x)
gi(x)为凸函数。
凸集(Convex Set)
定义
一个集合
C
⊆
R
n
C\subseteq \mathbb{R}^n
C⊆Rn为凸集,如果满足任意
x
,
y
∈
C
x,y \in C
x,y∈C有
t
x
+
(
1
−
t
)
y
∈
C
,
∀
0
≤
t
≤
1.
tx + (1-t)y \in C, \forall 0 \leq t \leq 1.
tx+(1−t)y∈C,∀0≤t≤1.
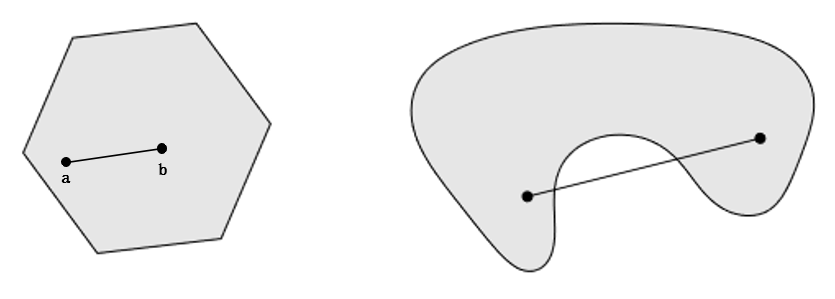
从几何的角度来看,任一两点在凸集内有连续的线段连接。例如下图中,图一成立,而图二不成立。
仿射函数(Affine Function)
定义(Definition)
从 R n \mathbb{R}^n Rn到 R m \mathbb{R}^m Rm的映射: x → A x + b x\rightarrow Ax + b x→Ax+b,称为反射变换(Affine Transform)或仿射映射(Affine Map),其中 A A A是一个 m × n m\times n m×n矩阵, b b b是一个 m m m维向量。当 m = 1 m=1 m=1时,称上述仿射变换称为仿射函数(Affine Function)。
一般形式: f ( x ) = A x + b , f( \mathbf{x} ) = \mathbf{A} \mathbf{x} + \mathbf{b}, f(x)=Ax+b,其中, A \mathbf{A} A是一个 m × k m \times k m×k矩阵, x x x是一个 k k k向量, b b b是一个 m m m向量,实际反映从 k k k维到 m m m维的空间映射关系。
若 f f f是一个矢性(值)函数,若它可以表示为: f ( x 1 , . . . , x n ) = A 1 x 1 + A 2 x 2 + . . . + A n x n b , f( \mathbf{x}_1, ...,\mathbf{x}_n ) = \mathbf{A}_1 \mathbf{x}_1 + \mathbf{A}_2 \mathbf{x}_2 +... + \mathbf{A}_n \mathbf{x}_n \mathbf{b}, f(x1,...,xn)=A1x1+A2x2+...+Anxnb, 其中, A i \mathbf{A}_i Ai可以是一个标量or矩阵,则称 f f f是仿射函数。
充要条件(Necessary and Sufficient Condition)
f [ p x 1 + ( 1 − p ) y 1 , p x 2 + ( 1 − p ) y 2 , … , p x n + ( 1 − p ) y n ] ≡ p f ( x 1 , x 2 , … , x n ) + ( 1 − p ) f ( y 1 , y 2 , … , y n ) f[px_1+(1-p)y_1,px_2+(1-p)y_2,…,px_n+(1-p)y_n] ≡ pf(x_1,x_2,…,x_n)+(1-p) f (y_1,y_2,…,y_n) f[px1+(1−p)y1,px2+(1−p)y2,…,pxn+(1−p)yn]≡pf(x1,x2,…,xn)+(1−p)f(y1,y2,…,yn)
Comparison with Linear Function
当仿射函数中的 b \mathbf{b} b中的元素全为零,即,截距为零,则称为线性函数(Linear Function)。
凸函数(Convex Function)
Definition of Convex Functions
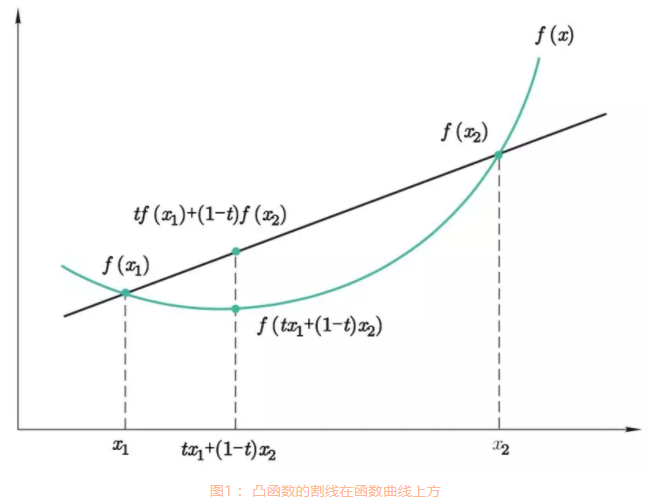
凸函数(一元)(Convex Function):对于一元函数 f ( x ) f(x) f(x),如果对于任意 t ∈ [ 0 , 1 ] t \in [0,1] t∈[0,1],满足 f ( t x 1 + ( 1 − t ) x 2 ) ≤ t f ( x 1 ) + ( 1 − t ) f ( x 2 ) f \left(tx_1+(1-t)x_2 \right) \leq t f(x_1) + (1-t) f(x_2) f(tx1+(1−t)x2)≤tf(x1)+(1−t)f(x2),则称 f ( x ) f(x) f(x)为凸函数(Convex Function)。
严格凸函数(一元)(Strictly Convex Function): ∀ t ∈ ( 0 , 1 ) \forall t\in (0,1) ∀t∈(0,1),满足 f ( t x 1 + ( 1 − t ) x 2 ) < t f ( x 1 ) + ( 1 − t ) f ( x 2 ) f \left(tx_1+(1-t)x_2 \right) < t f(x_1) + (1-t) f(x_2) f(tx1+(1−t)x2)<tf(x1)+(1−t)f(x2),则称 f ( x ) f(x) f(x)为严格凸函数。注意:与凸函数相比,少了等号。
若从几何的角度来看,凸函数的割线在函数曲线的上方,线段上的点 ( t x 1 + ( 1 − t ) x 2 , t f ( x 1 ) + ( 1 − t ) f ( x 2 ) ) (tx_1+(1-t)x_2, t f(x_1) + (1-t) f(x_2)) (tx1+(1−t)x2,tf(x1)+(1−t)f(x2))始终大于下方的点 ( t x 1 + ( 1 − t ) x 2 , f ( t x 1 + ( 1 − t ) x 2 ) ) \left(tx_1+(1-t)x_2, f \left(tx_1+(1-t)x_2 \right) \right) (tx1+(1−t)x2,f(tx1+(1−t)x2))。
在数据科学的模型求解中,如果优化的目标函数是凸函数,则局部极小值就是全局最小值。
Judgement for Convex Functions (凸函数的判断)
A. General Methods for Convex Proof (凸证明的常用方法)
3.1.3 First-order conditions(一阶条件)
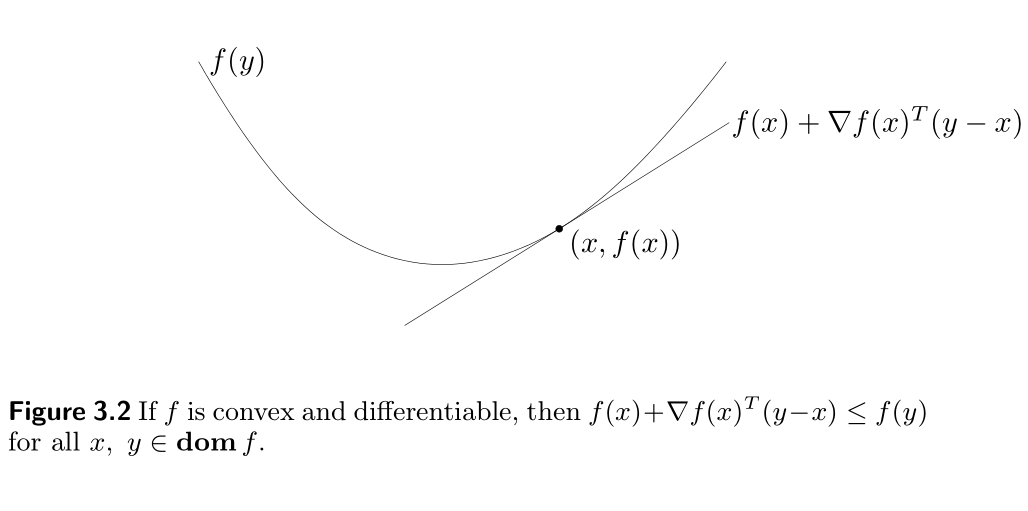
Suppose f f f is differentiable (i.e., its gradient ∇ f \nabla f ∇f exists at each point in d o m f \mathbf{dom} f domf, which is open). Then f f f is convex, if and only if d o m f \mathbf{dom} f domf is convex and f ( y ) ≥ f ( x ) + ∇ f ( x ) T ( y − x ) ( 3.2 ) f(y) \geq f(x) + \nabla f(x)^T (y-x) \qquad (3.2) f(y)≥f(x)+∇f(x)T(y−x)(3.2) holds for all x , y ∈ d o m f x, y \in \mathbf{dom} f x,y∈domf.
Remarkable properties of convex functions and convex optimization problems
- The affine function of y y y given by f ( x ) + ∇ f ( x ) T ( y − x ) f(x)+\nabla f(x)^T (y−x) f(x)+∇f(x)T(y−x) is, of course, the first-order Taylor approximation of f f f near x x x.
- The inequality ( 3.2 ) (3.2) (3.2) states that for a convex function, the first-order Taylor approximation is in fact a global underestimator of the function.
- Conversely, if the first-order Taylor approximation of a function is always a global underestimator of the function, then the function is convex.
The inequality ( 3.2 ) (3.2) (3.2) shows that from local information about a convex function (i.e., its value and derivative at a point) we can derive global information (i.e., a global underestimator of it).
This is perhaps the most important propoerty of convex functions, and explains some of the remarkable propoerties of convex functions and convex optimization problems.
As one simple example, the inequality ( 3.2 ) (3.2) (3.2) shows that if ∇ f ( x ) = 0 \nabla f(x) = 0 ∇f(x)=0, then for all y ∈ d o m f , y\in \mathbf{dom} f, y∈domf, f ( y ) ≥ f ( x ) f(y) \geq f(x) f(y)≥f(x), i.e., x x x is a global minimizer of the function f f f.
-
Strict convexity can also be characterized by a first-order condition: f f f is strictly convex if and only if d o m f \mathbf{dom} f domf is convex and for x , y ∈ d o m f x, y \in \mathbf{dom} f x,y∈domf, x ≠ y x \neq y x=y, we have f ( y ) > f ( x ) + ∇ f ( x ) T ( y − x ) . f(y) > f(x) + \nabla f(x)^T (y-x). f(y)>f(x)+∇f(x)T(y−x).
-
For concave functions, we have the corresponding characterization: f f f is concave if and only if d o m f \mathbf{dom} f domf is convex and f ( y ) ≤ f ( x ) + ∇ f ( x ) T ( y − x ) f(y) \leq f(x) + \nabla f(x)^T (y-x) f(y)≤f(x)+∇f(x)T(y−x) for all x , y ∈ d o m f x,y\in \mathbf{dom} f x,y∈domf.
3.1.4 Second-Order Conditions(二阶条件)
f f f is twice differentiable, that is, its Hession or second derivative ∇ 2 f \nabla^2 f ∇2f exists at each point in d o m f \mathbf{dom} f domf, which is open. Then f f f is convex if and only if d o m f \mathbf{dom} f domf is convex and its Hessian is positive semidefinite: for all x ∈ d o m f x\in \mathbf{dom} f x∈domf, ∇ 2 f ( x ) ⪰ 0. \nabla^2 f(x) \succeq 0. ∇2f(x)⪰0.
For a function on R \mathbf{R} R, this reduces to the simple condition f ′ ′ ( x ) ≥ 0 f''(x) \geq 0 f′′(x)≥0 (and d o m f \mathbf{dom} f domf convex, i.e., an interval), which means that the derivative is nondecreasing.
- To be noted, the condition ∇ 2 f ( x ) ⪰ 0 \nabla^2 f(x) \succeq 0 ∇2f(x)⪰0 can be interpreted geometrically as the requirement that the graph of the function have positive (upward) curvature at x x x.
- Similarly, f f f is concave if and only if d o m f \mathbf{dom} f domf is convex and ∇ 2 f ( x ) ⪯ 0 \nabla^2 f(x) \preceq 0 ∇2f(x)⪯0 for all x ∈ d o m f x \in \mathbf{dom} f x∈domf.
- If ∇ 2 f ( x ) ≻ 0 \nabla^2 f(x) \succ 0 ∇2f(x)≻0 for all x ∈ d o m f x\in \mathbf{dom} f x∈domf, then f f f is strictly convex. To converse, however, is not true: for example, the function f f f: R → R \mathbf{R} \rightarrow \mathbf{R} R→R given by f ( x ) = x 4 f(x) = x^4 f(x)=x4 is strictly convex but has zero second derivative at x = 0 x=0 x=0.
对于一元函数 f ( x ) f(x) f(x),可以通过二阶导数 f ′ ′ ( x ) f'' (x) f′′(x)的符号来判断。如果 f ′ ′ ( x ) ≤ 0 f''(x) \leq 0 f′′(x)≤0,则 f ( x ) f(x) f(x)是凸函数。
对于多元函数 f ( x ) f(\mathbf{x}) f(x),可以通过Hessian矩阵的正定性来判断,其中Hessian矩阵是由多元函数的二阶导数组成的方阵。如果Hessian矩阵是半正定矩阵,则 f ( x ) f(\mathbf{x}) f(x)是凸函数。
Example 3.2 Quadratic functions. Consider the quadratic function f f f: R n → R \mathbf{R}^n \rightarrow \mathbf{R} Rn→R, with d o m f = R n \mathbf{dom} f = \mathbf{R}^n domf=Rn, given by f ( x ) = 1 2 x T P x + q T x + r , f(x) = \frac{1}{2} x^T P x + q^T x +r , f(x)=21xTPx+qTx+r, with P ∈ S n P \in \mathbf{S}^n P∈Sn, q ∈ R n q \in \mathbf{R}^n q∈Rn, and r ∈ R r \in \mathbf{R} r∈R. Since ∇ 2 f ( x ) = P \nabla^2 f(x) = P ∇2f(x)=P for all x x x, f f f is convex if and only if P ⪰ 0 P\succeq 0 P⪰0 (and concave if and only if P ⪯ 0 P \preceq 0 P⪯0).
3.1.6 Sublevel Sets
The
α
\alpha
α-sublevel set of a function
f
f
f:
R
n
→
R
\mathbf{R}^n \rightarrow \mathbf{R}
Rn→R is defined
C
α
=
{
x
∈
d
o
m
f
∣
f
(
x
)
≤
α
}
.
C_{\alpha} = \{ x \in \mathbf{dom} f ~ |~ f(x) \leq \alpha \}.
Cα={x∈domf ∣ f(x)≤α}.
Sublevel sets of a convex function are convex, for any value of
α
\alpha
α.
proof:
if
x
,
y
∈
C
α
x,y \in C_\alpha
x,y∈Cα, then
f
(
x
)
≤
α
f(x) \leq \alpha
f(x)≤α and
f
(
y
)
≤
α
f(y) \leq \alpha
f(y)≤α.
And, so
f
(
θ
x
+
(
1
−
θ
)
y
)
≤
α
f(\theta x + (1-\theta)y) \leq \alpha
f(θx+(1−θ)y)≤α for
0
≤
θ
≤
1
0\leq \theta \leq 1
0≤θ≤1, and hence
θ
x
+
(
1
−
θ
)
y
∈
C
α
\theta x + (1-\theta) y \in C_\alpha
θx+(1−θ)y∈Cα.
For example,
f
(
x
)
=
−
e
x
f(x) = −e^x
f(x)=−ex is not convex on
R
\mathbf{R}
R (indeed, it is strictly concave) but all its sublevel sets are convex.
To be noted, the converse is not true: a function can have all its sublevel sets convex, but not be a convex function.
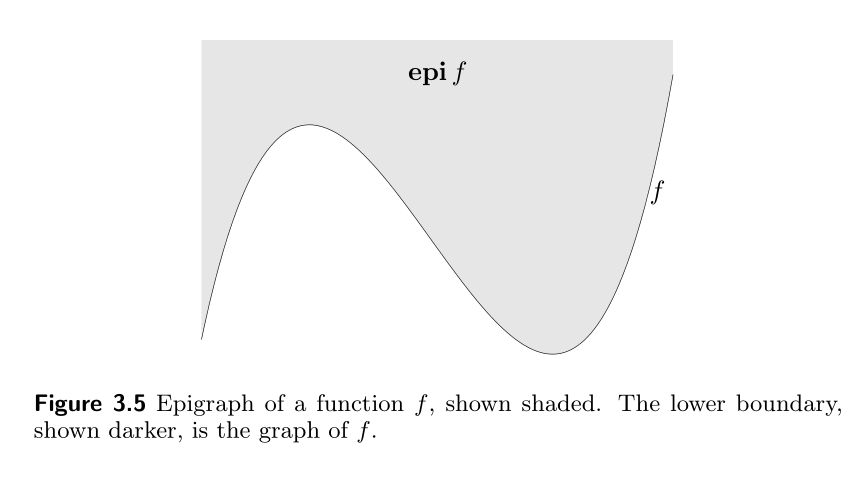
3.1.7 Epigraph
The graph of a function
f
f
f:
R
n
→
R
\mathbf{R}^n \rightarrow \mathbf{R}
Rn→R is defined as
{
(
x
,
f
(
x
)
)
∣
x
∈
d
o
m
f
}
\{ (x,f(x)) ~|~ x \in \mathbf{dom} f \}
{(x,f(x)) ∣ x∈domf} which is a subset of
R
n
+
1
\mathbf{R}^{n+1}
Rn+1.
The epigraph of a function
f
f
f:
R
n
→
R
\mathbf{R}^n \rightarrow \mathbf{R}
Rn→R is defined as
e
p
i
f
=
{
(
x
,
t
)
∣
x
∈
d
o
m
f
,
f
(
x
)
≤
t
}
,
\mathbf{epi} ~f =\{ (x,t) | x \in \mathbf{dom} f, f(x) \leq t \},
epi f={(x,t)∣x∈domf,f(x)≤t}, which is a subset of
R
n
+
1
\mathbf{R}^{n+1}
Rn+1, as shown in the following Fig. 3.5.
Note that ‘Epi’ means ‘above’ so epigraph means ‘above the graph’.
The link between convex sets and convex functions is via the epigraph:
- A function is convex if and only its epigraph is convex set.
- A function is concave if and only if its hypograph, defined as, h y p o f = { ( x , t ) ∣ t ≤ f ( x ) } , \mathbf{hypo} f = \{ (x,t) | t \leq f(x) \}, hypof={(x,t)∣t≤f(x)}, is a convex set.
Eaxmple 3.4. Matrix fractional function. The function f f f: R n × S n → R \mathbf{R}^n \times \mathbf{S}^n \rightarrow \mathbf{R} Rn×Sn→R, defined as, f ( x , Y ) = x T Y − 1 x f(x,Y) = x^T Y^{-1} x f(x,Y)=xTY−1x is convex on d o m f = R n × S + + n \mathbf{dom} f = \mathbf{R}^n \times \mathbf{S}^n_{++} domf=Rn×S++n.
One easy way to establish convexity of f f f is via its epigraph: e p i = { ( x , Y , t ) ∣ Y ≻ 0 , x T Y − 1 x ≤ t } = { ( x , Y , t ) ∣ [ Y x x T t ] ⪰ 0 , Y ≻ 0 } \begin{array}{ll}\mathbf{epi} &= \left\{ (x,Y,t) | Y \succ 0, x^TY^{-1}x \leq t \right\} \\ &=\left\{ (x,Y,t) | \left[ \begin{array}{cc} Y ~~ x \\ x^T ~~ t \end{array} \right] \succeq 0, Y \succ 0 \right\} \end{array} epi={(x,Y,t)∣Y≻0,xTY−1x≤t}={(x,Y,t)∣[Y xxT t]⪰0,Y≻0} using the Schur complement condition for positive semidefiniteness of a block matrix.
The last condition is a linear matrix inequality in ( x , Y , t ) (x,Y,t) (x,Y,t), and therefore e p i f \mathbf{epi} f epif is convex.
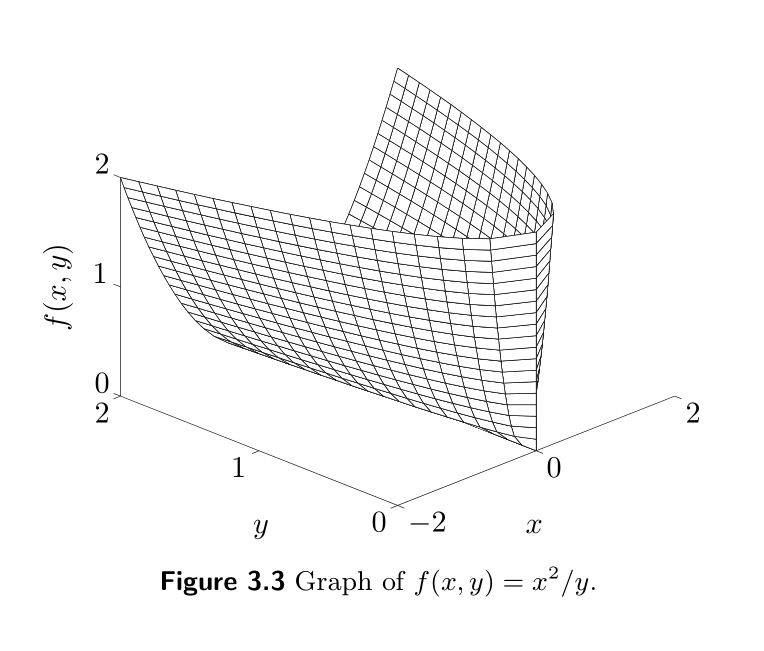
For the special case n = 1 n=1 n=1, the matrix fractional function reduces to the quadratic-over-linear function x 2 / y x^2/y x2/y, and the associated LMI representation is [ y x x t ] ⪰ 0 , y > 0 \left[ \begin{array}{ll} y \quad x \\ x \quad t \end{array} \right] \succeq 0, ~ y>0 [yxxt]⪰0, y>0 (the graph of which is shown in the following figure 3.3 3.3 3.3).
Many results for convex functions can be proved (or interpreted) geometrically using epigraphs, and applying results for convex sets.
As an example, consider first-order condition for the convexity:
f
(
y
)
≥
f
(
x
)
+
∇
f
(
x
)
(
y
−
x
)
,
f(y) \geq f(x) + \nabla f(x) (y-x),
f(y)≥f(x)+∇f(x)(y−x), where
f
f
f is convex and
x
,
y
∈
d
o
m
f
x, y \in \mathbf{dom} f
x,y∈domf.
We can interpret this basic inequality geometrically in terms of
e
p
i
f
\mathbf{epi} f
epif.
If
(
y
.
t
)
∈
e
p
i
f
,
(y.t)\in \mathbf{epi} f,
(y.t)∈epif, then
t
≥
f
(
y
)
≥
f
(
x
)
+
∇
f
(
x
)
(
y
−
x
)
.
t \geq f(y) \geq f(x) + \nabla f(x) (y-x).
t≥f(y)≥f(x)+∇f(x)(y−x).
We can express this as:
(
y
,
t
)
∈
e
p
i
f
→
[
∇
f
(
x
)
−
1
]
T
(
[
y
t
]
−
[
x
f
(
x
)
]
)
≤
0
(y,t) \in \mathbf{epi} f \rightarrow \left[\begin{array}{c} \nabla f(x) \\ -1 \end{array}\right]^{T}\left(\left[\begin{array}{l} y \\ t \end{array}\right]-\left[\begin{array}{c} x \\ f(x) \end{array}\right]\right) \leq 0
(y,t)∈epif→[∇f(x)−1]T([yt]−[xf(x)])≤0
This means that the hyperplane defined by
(
∇
f
(
x
)
,
−
1
)
(\nabla f(x),−1)
(∇f(x),−1) supports epif at the boundary point
(
x
,
f
(
x
)
)
(x,f(x))
(x,f(x)); see figure 3.6.

3.1.8 Jensen’s Inequality and Extensions(延森不等式)
The basic inequality ( 3.1 ) (3.1) (3.1), i.e., f ( θ x + ( 1 − θ ) y ) ≤ θ f ( x ) + ( 1 − θ ) f ( y ) , f(\theta x + (1-\theta)y) \leq \theta f(x) + (1-\theta) f(y), f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y), is sometimes called Jensen’s inequality.
It’s easily extended to convex combinations of more than two points: If f f f is convex, x 1 , . . . , x k ∈ d o m f , x_1,...,x_k \in \mathbf{dom} f, x1,...,xk∈domf, and θ 1 , . . . , θ k ≥ 0 \theta_1,...,\theta_k \geq 0 θ1,...,θk≥0 with θ 1 , . . . , θ k = 1 , \theta_1,...,\theta_k = 1, θ1,...,θk=1, then f ( θ 1 x 1 + . . . . + θ k x k ) ≤ θ 1 f ( x 1 ) + . . . + θ k f ( x k ) . f(\theta_1 x_1 + .... + \theta_k x_k) \leq \theta_1f( x_1) + ... + \theta_k f( x_k). f(θ1x1+....+θkxk)≤θ1f(x1)+...+θkf(xk).
As in the case of convex sets, the inequality extends to infinite sums, integrals, and expected values. For example, if p ( x ) ≥ 0 p(x) \geq 0 p(x)≥0 on S ⊆ d o m f S \subseteq \mathbf{dom} f S⊆domf, ∫ S p ( x ) d x = 1 \int_S p(x) \text{d} x = 1 ∫Sp(x)dx=1, then f ( ∫ S p ( x ) x d x ) ≤ ∫ S p ( x ) f ( x ) d x f \left( \int_S p(x) x \text{d} x \right) \leq \int_S p(x) f(x) \text{d} x f(∫Sp(x)xdx)≤∫Sp(x)f(x)dx provided the integrals exist.
In the most general case, we can take any probability measure with support in d o m f \mathbf{dom} f domf. If x x x is a random variable such that x ∈ d o m f x \in \mathbf{dom} f x∈domf with probability one, and f f f is convex, then we have f ( E { x } ) ≤ E { f ( x ) } f(\mathbb{E}\{x\})\leq \mathbb{E}\{ f(x) \} f(E{x})≤E{f(x)} provided the expectations exist.
Thus, the inequality ( 3.5 ) (3.5) (3.5) characterizes the convexity: If f f f is not convex, there is a random variable x x x, with x ∈ d o m f x \in \mathbf{dom} f x∈domf with probability one, such that f ( E { x } ) > E ( f ( x ) ) . f(\mathbb{E} \{x\}) > \mathbb{E}(f(x)). f(E{x})>E(f(x)).
All of these inequalities are now called Jensen’s inequality, even though the inequality studied by Jensen was the very simple one f ( x + y 2 ) ≤ 1 2 f ( x ) + 1 2 f ( y ) . f\left( \frac{x+y}{2} \right) \leq \frac{1}{2} f(x) + \frac{1}{2} f(y). f(2x+y)≤21f(x)+21f(y).
Jensen不等式的一般形式:如果 f f f是凸函数, x x x是随机变量,那么 f ( E ( x ) ) ≤ E ( f ( x ) ) f\left( E(x) \right) \leq E(f(x)) f(E(x))≤E(f(x))。
另一种描述:假设
n
n
n个样本
{
x
1
,
x
2
,
.
.
.
,
x
n
}
\{x_1,x_2,...,x_n\}
{x1,x2,...,xn}和对应的权重
{
α
1
,
α
2
,
.
.
.
,
α
n
}
\{\alpha_1,\alpha_2,...,\alpha_n\}
{α1,α2,...,αn},权重满足
∑
α
i
=
1
\sum \alpha_i = 1
∑αi=1,对于凸函数
f
f
f,以下不等式成立:
f
(
∑
i
=
1
n
α
i
x
i
)
≤
∑
i
=
1
n
α
i
f
(
x
i
)
.
f(\sum_{i=1}^n \alpha_i x_i) \leq \sum_{i=1}^n \alpha_i f(x_i).
f(i=1∑nαixi)≤i=1∑nαif(xi).
3.1.9 Inequalities
Many famous inequalities can be derived by applying Jensen’s inequality to some appropriate convex functions.
Indeed, convexity and Jensen’s inequality can be made the foundation of a theory of inequalities.
As a simple example, consider the arithmetic-geometric mean inequality: a b = a 1 2 b 1 2 ≤ 1 2 a + 1 2 b \sqrt{ab} = a^{\frac{1}{2}} b^{\frac{1}{2}} \leq \frac{1}{2} a + \frac{1}{2} b ab=a21b21≤21a+21b for a , b > 0 a, b>0 a,b>0.
The function − log x - \log x −logx is convex; Jensen’s inequality with θ = 1 / 2 \theta = 1/2 θ=1/2 yields − log ( a + b 2 ) ≤ − log a + log b 2 - \log (\frac{a+b}{2}) \leq - \frac{\log a + \log b }{2} −log(2a+b)≤−2loga+logb
3.2 Operations that preserve convexity(保凸操作)
3.2.1 Nonnegative weighted sums(非负的加权和)
- Evidently, if f f f is a convex function and α > 0 \alpha>0 α>0, then the function α f \alpha f αf is convex.
- If f 1 f_1 f1 and f 2 f_2 f2 are both convex functions, then so is their sum f 1 + f 2 f_1 + f_2 f1+f2.
- Combining nonnegative scaling and addition, we see that the set of convex functions is itself a convex cone: a nonnegative weighted sum of convex functions, i.e., f = w 1 f 1 + . . . + w m f m f = w_1 f_1 +...+ w_m f_m f=w1f1+...+wmfm is convex.
- Similarly, a nonnegative weighted sum of concave functions is concave.
- A nonnegative, nonzero weighted sum of strictly convex (concave) functions is strictly convex (concave).
These properties extend to infinite sums and integrals. For example if f ( x , y ) f(x,y) f(x,y) is convex in x x x for each y ∈ A y \in A y∈A, and w ( y ) ≥ 0 w(y) \geq 0 w(y)≥0 for each y ∈ A y \in A y∈A, then the function g g g defined as g ( x ) = ∫ A w ( y ) f ( x , y ) d y g(x) = \int_{\mathcal{A}} w(y) f(x,y) \text{d} y g(x)=∫Aw(y)f(x,y)dy is convex in x x x (provided the integral exists).
The fact that convexity is preserved under nonnegative scaling and addition is easily verified directly, or can be seen in terms of the associated epigraphs. For example, if
w
≥
0
w \geq 0
w≥0 and
f
f
f is convex, we have
e
p
i
(
w
f
)
=
[
I
0
0
w
]
e
p
i
(
f
)
\operatorname{\mathbf{epi}}(w f)=\left[\begin{array}{cc} I & 0 \\ 0 & w \end{array}\right] \mathbf{epi} (f)
epi(wf)=[I00w]epi(f) which is convex because the image of a convex set under a linear mapping is convex.
3.2.2 Composition with an affine mapping (仿射映射的组合)
Suppose f f f: R n → R \mathbf{R}^n \rightarrow \mathbf{R} Rn→R, A ∈ R n × m A \in \mathbf{R}^{n\times m} A∈Rn×m, and b ∈ R n b \in \mathbf{R}^n b∈Rn. Define g g g: R m → R \mathbf{R}^m \rightarrow \mathbf{R} Rm→R by g ( x ) = f ( A x + b ) , g(x)=f(Ax+b), g(x)=f(Ax+b), with d o m g = { x ∣ A x + b ∈ d o m f } . \mathbf{dom} g=\{ x | Ax + b \in \mathbf{dom } f\}. domg={x∣Ax+b∈domf}. Then, if f f f is convex/concave, so is g g g.
3.2.3 Pointwise Maximum and Supremum (点态最大值与上界)
If
f
1
f_1
f1 and
f
2
f_2
f2 are convex functions, then their pointwise maximum
f
f
f, defined by
f
(
x
)
+
max
{
f
1
(
x
)
,
f
2
(
x
)
}
,
f(x) + \max \{ f_1(x), f_2(x)\},
f(x)+max{f1(x),f2(x)}, with
d
o
m
f
1
∩
d
o
m
f
2
\mathbf{dom} f_1 \cap \mathbf{dom} f_2
domf1∩domf2, is also convex. This property is easily verified: if
0
≤
θ
≤
1
0\leq \theta \leq 1
0≤θ≤1 and
x
x
x,
y
∈
d
o
m
f
y\in \mathbf{dom} f
y∈domf, then
f
(
θ
x
+
(
1
−
θ
)
y
)
=
max
{
f
1
(
θ
x
+
(
1
−
θ
)
y
)
,
f
2
(
θ
x
+
(
1
−
θ
)
y
)
}
≤
max
{
θ
f
1
(
x
)
+
(
1
−
θ
)
f
1
(
y
)
,
θ
f
2
(
x
)
+
(
1
−
θ
)
f
2
(
y
)
}
≤
θ
max
{
f
1
(
x
)
,
f
2
(
x
)
}
+
(
1
−
θ
)
max
{
f
1
(
y
)
,
f
2
(
y
)
}
=
θ
f
(
x
)
+
(
1
−
θ
)
f
(
y
)
,
\begin{aligned} f(\theta x+(1-\theta) y) &=\max \left\{f_{1}(\theta x+(1-\theta) y), f_{2}(\theta x+(1-\theta) y)\right\} \\ & \leq \max \left\{\theta f_{1}(x)+(1-\theta) f_{1}(y), \theta f_{2}(x)+(1-\theta) f_{2}(y)\right\} \\ & \leq \theta \max \left\{f_{1}(x), f_{2}(x)\right\}+(1-\theta) \max \left\{f_{1}(y), f_{2}(y)\right\} \\ &=\theta f(x)+(1-\theta) f(y), \end{aligned}
f(θx+(1−θ)y)=max{f1(θx+(1−θ)y),f2(θx+(1−θ)y)}≤max{θf1(x)+(1−θ)f1(y),θf2(x)+(1−θ)f2(y)}≤θmax{f1(x),f2(x)}+(1−θ)max{f1(y),f2(y)}=θf(x)+(1−θ)f(y), which establishes convexity of
f
f
f. It is easily shown that if
f
1
,
f
2
,
.
.
.
,
f
m
f_1,f_2,...,f_m
f1,f2,...,fm are convex, then their pointwise maximum
f
(
x
)
=
max
{
f
1
(
x
)
,
.
.
.
.
,
f
m
(
x
)
}
f(x) = \max \{ f_1(x), ....,f_m(x) \}
f(x)=max{f1(x),....,fm(x)} is also convex.















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









