






贝叶斯的强大之处就在于可将先验概率与后验概率互相转换。用不精确的语言说,就是待分属性属于哪个目标类别的可能性最大,就将其归到相应的类别。而属于哪个类别的概率判断就根据以往的先验知识,看看以往该类别的情况下出现该待分属性的概率有多大。若以某文档D作为待分类属性,类别C表示不同目标类别,若要判断D文档属于C类的概率,则利用一般贝叶斯分类器的过程是这样的。首先确定要解决的问题是P(C|D)这个条件概率。由于直接计算这个概率不好计算,就利用贝叶斯公式,P(C|D)=P(D|C)P(C)/P(D),通过对于样例的训练,我们可以通过bag of words的假设估计出P(D|C),也可以统计出P(C),分母对于所有类别都一样,因此可以忽略。这样,我们就可以把文档D划分到一个概率最大的类C里,就完成了对文档D的分类。
朴素贝叶斯中,其naive的地方在于,强制认为给定目标值时,属性(大小,格式)之间相互条件独立儿一般情况是(P(ABCD)=P(DIABC)P(ABC)=P(DIABC) P(CIAB)P(BIA)P(A)),然后进行分类。
假设现在我们的待分类属性是有两个变量组成的,文档的大小和格式,现在要来判断某文档该归类于科学类文档、还是艺术类文档。也就是比较
P(科学|大小,格式)和P(艺术|大小, 格式),那个概率大,则判断该文档属于哪个目标类别。根据贝叶斯公式,
P(科学|大小,格式)=P(大小,格式 I 科学)×P(科学)/P(大小,格式)
根据朴素贝叶斯的条件独立假设, P(大小,格式|科学)=P(大小I科学)P(格式I科学)
其中的P(大小I科学)和P(格式I科学)两项都可以通过 training set 直接求得。具体算法流程图如下(摘自http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html)
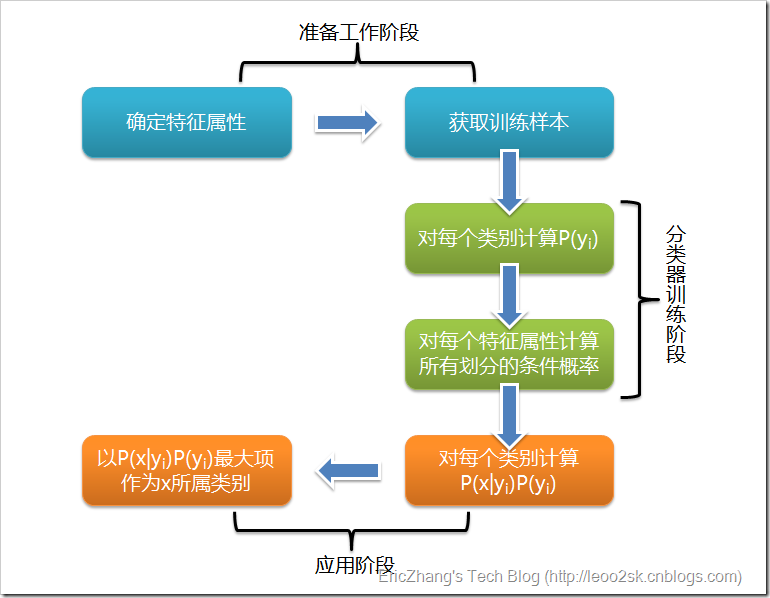
补充以下条件独立的概念:
条件独立是条件概率的独立性,条件概率也是一种概率,只不过是将事件的空间集合改变。
设有事件R和B,当它们在事件Y定义的空间上相互独立时要满足

或者表达成

下图两幅图举例说明了什么是条件独立(Conditional independence)。途中每个单元代表一个可能的结果,途中蓝色、红色和黄色填充的部分分别代表事件R, B,和Y。其中都满足R和B在给定Y的条件下条件独立。都满足
但不满足
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









