







A Google Congestion Control Algorithm for Real-Time Communication draft-alvestrand-rmcat-congestion-03论文理解
看中文的GCC算法一脸懵。看一看英文版的,找一找感觉。
目录
Abstract
本文档介绍了适用于webRTC两种拥塞控制算法。一种是 基于时延(delay-based) 一种是基于损失(loss-based)。
1. Introduction
带宽变化很大,但是呢,媒体的编码方法不能改了。不能依靠编码来解决带宽变化拥塞问题。
拥塞的时候,其他程序也不会减小带宽,来让网络不拥塞,所以只能改自己不能依靠别人了。不能依靠别的程序解决拥塞的问题。
编码输出对丢包是很敏感的,然而,要有实时性,丢的包也不会去重传了。网络拥塞的时候会丢包,因为实时性,不让重传。
1.1 Mathematical notation conventions
X_hat 变量X的真实值的估计值 - 通常在变量名的顶部用符号标记。
X(i) 数组X的第i个值-通常用下标i标记。
E{X} 随机变量X的期望值
2. System model
-
RTP数据包 - 包含流媒体数据的RTP数据包。
-
数据包组Packet group -连续RTP包的集合,由组出发时间和组到达时间(absolute send time)【abs-send-time】唯一标识。这些包可以是视频包、音频包或音频和视频包的混合
-
传入媒体流 - 由RTP数据包组成的帧流。

-
RTP发送方 - 发送RTP流。RTP发送方负责生成RTP时间戳以及abs-send-time头扩展
-
RTP接收方 - 接收RTP流,并记录RTP报文的到达时间。
-
【接收端】RTCP sender at RTP receiver–发送RR(接收方报告receiver report)、REMB消息、传输层RTCP反馈报文(transport wide feedback packet)。
-
【发送端】RTCP receiver at RTP sender - 负责接收RR报文、REMB报文、传输层RTCP反馈报文(transport wide feedback packet)。并将接收信息通知到本方控制器。
-
【发送端】RTCP receiver at RTP receiver - 接收SR报文 sender reports
-
基于丢包的控制器 - 进行丢失率测量、RTT时间测量和(接收)REMB消息,并计算发送端的目标发送比特率。
-
基于延迟的控制器 - 可以部署在RTP接收端记录RTP报文的到达时间或部署在RTP发送端从接收端的反馈报文中获取数据包的到达时间,【就是为了获得到达时间,要么就从接收端里的RTP记录到达时间,接收端算,要么就从发送端收到的RR里面找一下,发送端算】计算最大比特率并传递给基于丢包的控制器。
2.1 question
- REMB是啥,有什么作用
- transport wide feedback packet是什么有什么作用
- RR报文和SR报文里面有什么有什么作用
3.Feedback and extensions
有两种方法来实现提出的算法,一种是两个控制器都在发送端运行,另一种是delay-based控制器在接收端运行,loss-based控制器在发送端运行。
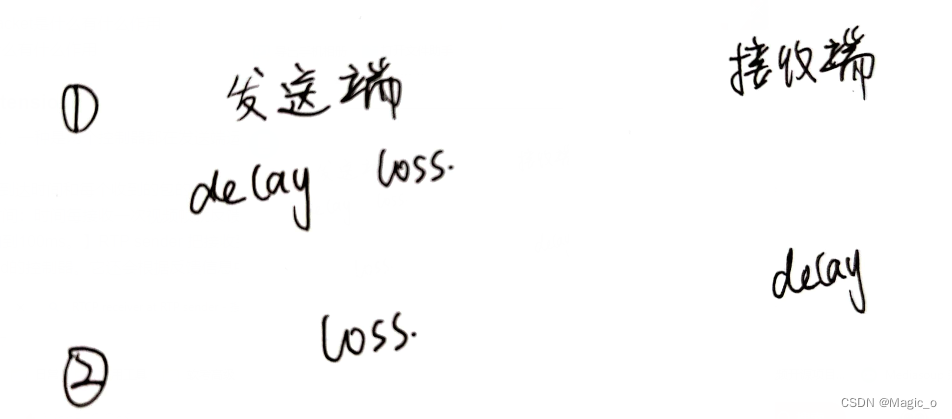
第一种:RTP receiver会记录到达时间和每个收到的包的传输层序列号(transport-wide sequence number,这些东西用transport-wide feedback message会定期发给发送端。【反馈的时间:时间每接收一次视频帧就反馈一次,如果只有音频或多流,至少每30毫秒一次反馈一次。如果反馈开销需要被限制,这个间隔可以增加到100ms。】发送方从反馈报文中获取RTP数据包的 {(传输层)序列号,到达时间} 信息,并与每个RTP数据包的发送时间建立映射(Map),再将这些时间戳提供给基于延迟的控制器。它还将根据反馈消息中的(传输层)序列号计算丢包率。
也就是接收端把RTP包到达时间和序列号记录一下,发给发送端。发送端根据发送时间和序列号对一下,抛给发送端的delay控制器,这样可以看出时延来,顺便算出丢包来。但是好像没有说loss控制器的什么事。
第二种:接收端的delay-based控制器,用来监控和处理到达时间和包的大小。发送方的abs-send-time RTP报头让接收者可以计算数据包组之间的延迟变化。从delay-based controller输出的是一个比特率,它将用REMB feedback message为载体,把这个比特率传给回发送方。RTCP-RR报文为载体把丢包率传给发送端。发送端 收到的REMB消息中的比特率和RR报文的丢包率被输入loss-based控制器,该控制器输出一个最终的目标比特率。当检测到拥塞时建议尽快发送REMB消息,或者至少每秒一次。
也就是接收端把RTP包到达时间和包的大小和发送时间对一下,计算不同的两个包的延迟变化,把这个延迟变化抛给delay控制器,输出来一个初级比特率,初级比特率放在REMB中,丢包率放在RR中,一起传给发送端。发送端把收到这俩率抛给loss控制器,算出来了一个最终的目标比特率。
4. Delay-based control
基于延迟的控制算法可以进一步分解为三部分:到达时间过滤器(an arrival-time filter)、过度使用检测器(an over-use detector)和速率控制器(a rate controller)
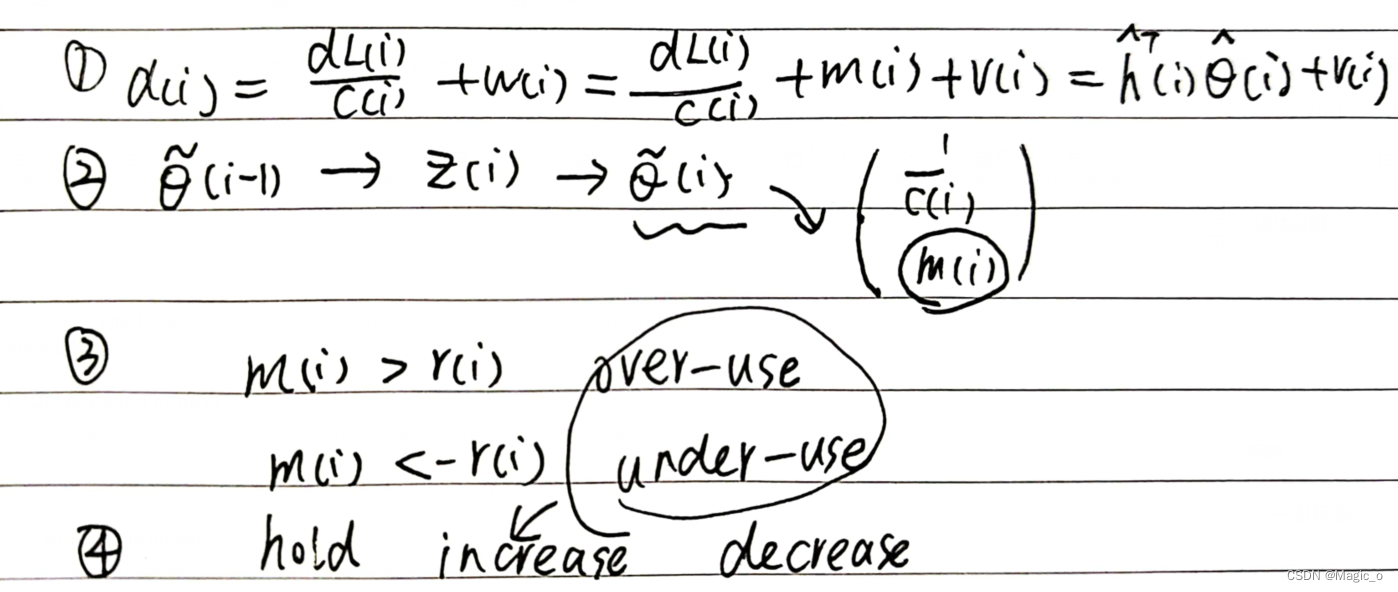
4.1 Arrival-time model
本节介绍了一个自适应滤波器(an adaptive filter),它根据接收数据包的时间,持续更新网络参数的估计值。
到达间隔时间inter-arrival time, t(i) - t(i-1):表示两个包或者两组包的到达时间不同. t(i)是对应于组中最后一个包被接收的时间。
出发间隔时间inter-departure time,T(i) - T(i-1):作为两个包或两组的出发时间的不同。其中T(i)是当前包组中最后一个包的出发时间戳
包组间延迟变化inter-group delay variation,d(i):d(i) = t(i) - t(i-1) - (T(i) - T(i-1))
在接收端,我们观察一组一组的传入数据包,其中一组包定义如下:
在burst_time间隔内发送的包序列组成一个小组。burst_time的建议值为5ms。此外,如果其inter-arrival time小于burst_time并且d(i)<0的数据包也被认为是当前组的一部分。 将这些数据包纳入组内的原因是为了更好地处理由"因与拥堵无关的原因,数据包排队"引起的延迟瞬变。任何无序接收的数据包都被Arrival-time model忽略。
t(i) - t(i-1) > T(i) - T(i-1) 网络有拥塞
由于在一条容量为C的路径上发送一组大小为L的数据包的时间ts大致为 ts = L/C
我们可以将包组之间的延迟变化建模为:

4.2. Arrival-time filter
根据卡尔曼滤波,根据之前的θ和延迟来估计现在的θ,从而判断网络的拥塞

4.3. Over-use detector
包组间延迟变化的估计值m(i)作为到达时间滤波器的输出

阈值gamma对算法的整体动态性和性能有显著影响。特别是,已经证明,如果gamma使用固定的阈值,则由该算法控制的流可以被并发TCP流(抢占而导致被)饿死。通过将阈值gamma增加到足够大的值,可以避免这种饿死。原因是,通过使用较大的gamma值,可以容忍较大的队列延迟,而在较小的gamma下,Over-use detector会对偏移估计值m(i)的微小增加迅速做出反应,产生一个over-use信号,减少基于延迟的可用带宽估计值A_hat,发的东西就少了,然后越来越小就会被饿死。【gamma很小,m很快就超过gamma,判断网络是过度使用的,可用带宽很小】因此,有必要动态地调整阈值gamma_1,以便在最常见的情况下获得良好的性能,例如在与基于损耗的流量竞争时。

通过这个设置,可以在并发TCP流的情况下增加阈值,防止饥饿以及强制协议内部公平。当m超过阈值的时候,就会over-use,A_hat会减小,如果gamma增大,m就不会超阈值了。当m小于阈值的时候,就会under-use,A_hat会增大,如果此时gamma减小,m就不会超阈值了。建议将gamma限制在[6, 600]范围内,因为太小的gamma会导致检测器变得过于敏感。
4.4. Rate control
速率控制分为两部分,一部分控制基于延迟的带宽估计,另一部分控制基于loss的带宽估计。这两种方法都旨在只要没有检测到拥塞,就要增加可用带宽A_hat的估计值,最终确保我们既能匹配信道的可用带宽也能对信道的过载状态进行检测。
一旦检测到over-use,基于delay-based控制器的可用带宽估计值就会减少。通过这种方法,我们得到了一个递归的和自适应的可用带宽估计。
如果没有检测到拥塞,A_hat一直增加。检测到拥塞,A_hat就会减少
在本文档中,我们假设速率控制子系统周期性地执行,并且这个周期是常数。
速率控制子系统有三种状态:增加、减少和保持。“增加”为未检测到拥塞时的状态;“减少”是检测到拥堵的状态,“保持”状态是为了在进入“增加”状态前耗尽已建立的(缓存)队列。
【信号触发】状态迁移规则表(空白表示“停留在【之前的】状态”):

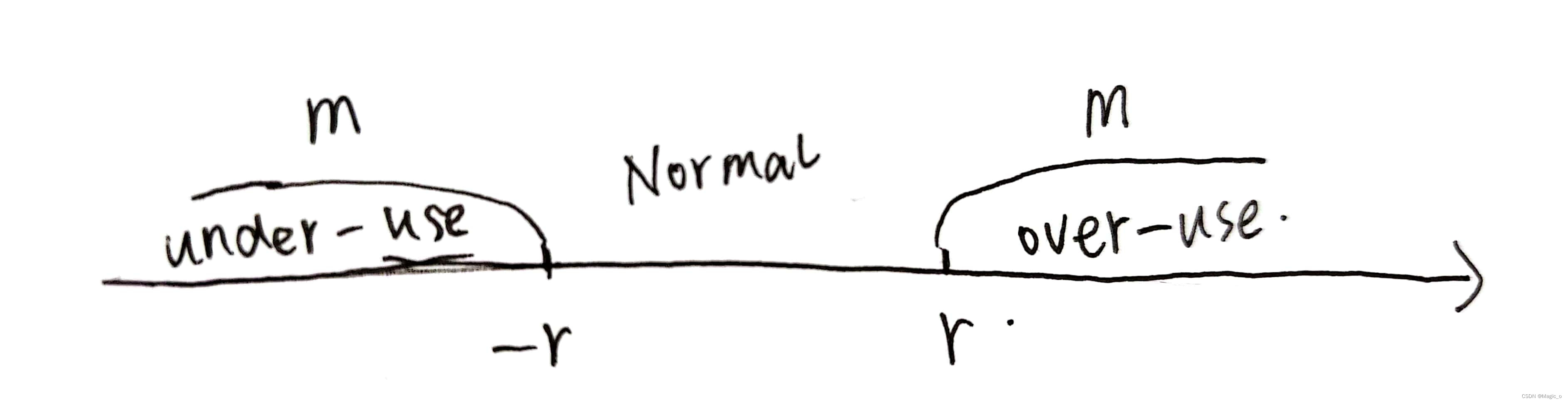
【我的想法】:这个地方感觉很奇怪,传统的理解,如果当前检测under-use的话,估计的带宽应该增加increase才对,但是这里并没有,而是一直hold 。我的理解是对under-use放宽要求了,因为m是两个包到达延迟的差,不可能m一直小,也就是发包越来越快,早晚会有一个静止不动的情况,早晚不会under-use,会回到normal的状态。但是如果是over-use的状态,会更over-use,不会回到hold的状态。
子系统启动时的初始状态是increase状态,直到探测器子系统检测到over-use或under-use为止。在每次更新时,基于延迟的可用带宽估计会根据当前状态采用乘法或加法的方式增加带宽估计值。
如果当前带宽估计远未收敛,则系统会使用乘法增加估计带宽,而如果更接近收敛,则系统会使用加法增加估计带宽。如果当前传入的比特率R_hat(i)接近之前处于下降状态时传入的比特率的平均值,则可以认为是接近收敛。
所谓“接近”,在这里被定义为距离该平均值在三个标准差之内。
我们建议使用0.95作为指数平滑系数来测量输入的 比特率 的平均值和标准差,因为我们认为它可以覆盖在 减少 状态下的多个场景。
当无法获得这些统计数据的有效估计值时,我们假设我们还没有接近收敛,因此仍处于乘法增长状态。如果R_hat(i)增加到平均最大比特率的三个标准偏差以上,我们认为当前拥塞等级已经改变,此时我们重置平均最大比特率并回到乘法增加状态。
R_hat(i)是基于delay-based的控制器在T秒窗口内测量的传入比特率:

在乘法增加过程中,估计值最多增加8%每秒。
在加法增加过程中,每过 response_time响应时间t2 的间隔时间,这个估计值 A_hat(i-1) 会增加大约半个数据包的大小。response_time间隔估计为往返时间加上100 ms作为over-use估计器和检测器反应时间的估计。

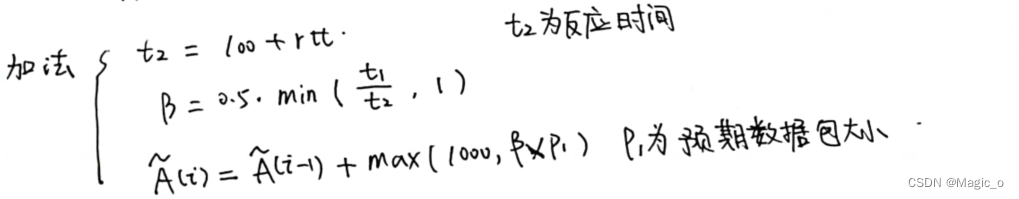
我们假设帧率是30的时候:
bits_per_frame = A_hat(i-1) / 30 每一帧的比特率
packets_per_frame = ceil(bits_per_frame / (1200 * 8)) (相当于bytes_per_frame/mtu)
avg_packet_size_bits = bits_per_frame / packets_per_frame
因为这个算法依赖 over-use 来判断当前的可用带宽估计值,我们必须确保我们的估计值不会远离发送端实际的发送码率。所以,如果发送端无法产生这个拥塞控制器要求的 bitrate,我们需要将可用带宽估计值限制到一个范围:A_hat(i) < 1.5 * R_hat(i)。
当探测到over-use,这个系统会转换为 Decrease 状态,可用带宽会降低到:A_hat(i) = alpha * R_hat(i)。alpha在范围[0.8 0.95]之间,建议为0.85。

当检测器向速率控制子系统发出under use 的信号时,我们知道网络路径中的队列正在被清空,我们的可用带宽估计值A_hat低于实际可用带宽。根据该信号,速率控制子系统将进入hold状态,接收方可用带宽估计值将保持不变,同时等待队列稳定在较低级别,这是一种控制低延迟的方法。延迟的减小可能是由于在over-use后带宽估计值减小,也有可能由于一些交叉网络的连接减少了。建议每个response_time 间隔都要更新一个 A_hat(i)
4.5 参数设定
+------------+-------------------------------------+----------------+
| Parameter | Description | RECOMMENDED |
| | | Value |
+------------+-------------------------------------+----------------+
| burst_time | Time limit in milliseconds between | 5 ms |
| | packet bursts which identifies a | |
| | group | |
| Q | State noise covariance matrix | diag(Q(i)) = |
| | | [10^-13 |
| | | 10^-3]^T |
| E(0) | Initial value of the system error | diag(E(0)) = |
| | covariance | [100 0.1]^T |
| chi | Coefficient used for the measured | [0.1, 0.001] |
| | noise variance | |
| gamma_1(0) | Initial value for the adaptive | 12.5 ms |
| | threshold | |
| gamma_2 | Time required to trigger an overuse | 10 ms |
| | signal | |
| K_u | Coefficient for the adaptive | 0.01 |
| | threshold | |
| K_d | Coefficient for the adaptive | 0.00018 |
| | threshold | |
| T | Time window for measuring the | [0.5, 1] s |
| | received bitrate | |
| alpha | Decrease rate factor | 0.85 |
+------------+-------------------------------------+----------------+
5. Loss-based control
在发送端
拥塞控制器的第二部分基于从基于延迟的控制器接收到的往返时间、数据包丢失和可用带宽估计A_hat做出决策。
基于延迟的控制器产生的可用带宽估计值A_hat只有在路径上的队列足够大时才可靠。如果队列长度很短,则 over-use 状态只能通过丢包得知,这样 delay-based controller 便不可用了。
丢包率控制器应该在收到每个反馈信息(收到 rtcp)的时候运行一次。
- 如果丢包率控制在 2-10%,则 As_hat(i) 保持不变。
- 如果丢包率超过 10%,则我们计算 As_hat(i) = As_hat(i-1)(1-0.5p)。其中p是丢包率。
- 如果丢包率小于 2%,则 As_hat(i) 应该增加,As_hat(i) = 1.05*As_hat(i-1)。
这个新的带宽预测值的下界是 TFRC,这是一种 TCP 友好的速率控制公式(这个公式产生的带宽相对与 TCP 来说相当公平,且速率较为平稳)。上界是A_hat(i)。上界和下界的公式如下:
8*s
As_hat(i) >= ---------------------------------------------------------
R*sqrt(2*b*p/3) + (t_RTO*(3*sqrt(3*b*p/8)*p*(1+32*p^2)))
As_hat(i) <= A_hat(i)
公式中的 b 表示单个 tcp 的确认的包的数量。t_RTO 是TCP的重传超时时间,单位是秒,我们在这里设它为 4*R。s 是 平均每个包的字节数。R 是 rtt 时间,单位是秒。(我们将上述公式的分子乘8,用于将字节数转换为比特数)
简而言之:loss-based 的估计值不会大于 delay-based 估计值,也不会小于 TFRC 计算公式。(除非 delay-based 的估计值小于 TFRC)
一开始当传输通道 over-use,它应该只有很小的丢包率,这时我们由于发现丢包率没有达到 10%,所以并不会降低发送码率。于是,信道由于不断堆积,很快就会超过10%的丢包率(由于前面的数据包已经将队列填满,后续的数据包到来的速度又大于队列消耗的速度)。如果这个丢包率的产生和拥塞无关(那么它将上升到10%的丢包率),那么我们不应该对它进行处理。
如果传输通道由于over-use而有少量的丢包,如果发送方不调整他的比特率,这个丢包量很快就会增加来激励丢包阈值。因此,很快就会达到10%以上的阈值,我们应该调整As_hat(i)。但是,如果丢包率没有增加,那么这些丢包可能与自己造成的拥塞无关,因此我们不应该对它们做出处理。
6.Interoperability Considerations
如果发送方实现了这些算法,而接收方实现,建议发送方关注接收方的RTCP报告,并使用丢包率和rtt作为基于损失的控制器的输入。基于延迟的控制器就禁止使用了。
7. 跟同事交流
基于loss的和基于delay的都是通过控制发送的编码每次传几个包,来控制发送的带宽,然后控制拥塞。超过的包就直接丢掉了,发了也没有用,接收端会直接丢掉。
8. 一些想法
感觉读这种文献很好,可以从本质帮忙理清思路,而不是学一些很浅的东西。但是有一个问题,翻译太耗费时间了,因此下一次再学习相关的东西的时候就需要先搜索一下市面上的有没有已经翻译好的版本,两个结合来看。














 1727
1727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









