






一.前情提要
1.本文理论为主,并且仅为个人理解,能力一般,不喜勿喷
2.本文理论知识较为成体系
3.如有需要,以下是原文,更为完备
二.正文
1.前言
①为什么用该技术:当模型很大,计算单元存储不下的时候,将其分散开来,需要的时候调用即可,该技术则是应用于此
②简介:ZeRO是一种用于大规模深度学习模型训练的优化技术,旨在解决在训练大型模型时遇到的内存限制和通信开销等问题(简单理解:加速transformer)
2.补充说明
①模型并行:
模型并行是一种用于训练大型神经网络的分布式计算策略,旨在将模型参数分割并分配到不同的设备上进行计算。这种方法有助于克服单个设备内存的限制,并提高训练大型模型的效率。
②通讯
GPU通信指的是在多个GPU之间进行数据传输和通信的过程。在深度学习中,通常会使用多个GPU来加速训练过程,这就需要在GPU之间有效地传输模型参数、梯度和其他相关数据。
③混合精度和半精度是深度学习中用于提高训练效率和性能的技术,通过减少模型参数和计算过程中的精度要求来降低计算成本。以下是对混合精度和半精度的解释:
1. 半精度
半精度是一种表示数值的方法,使用16位浮点数来存储数据。
2. 混合精度
混合精度是一种结合了不同精度的计算和存储方案。
3.ZeRO-dp优化的细节
(内存用在什么地方:①保存模型②保存梯度③保存优化器里的状态④中间值)
①核心算法是切开放在不同地方---->和参数服务器一样
②使用半精度来训练(fp16)但权重是fp32(避免一堆极小数字累加,可能仍然为0)再转化为fp16
③对于每个w状态只拷贝一份,避免重复-------->参与服务器的思想-------->内存使用下降
4.ZeRO-R优化的细节
①不同于计算来换空间,这里是带宽来换空间
②对于额外的临时缓存:设置固定大小
③对于内存碎片:不断的整理
5.具体实施(假定为两块卡,一个层)
①Pos(zero1)

②Pg(zero2)
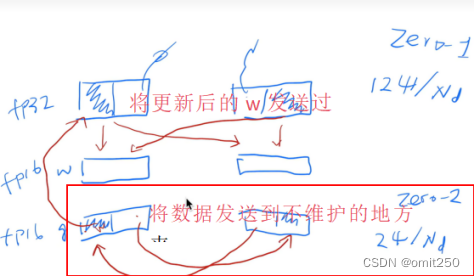
③Pp(zero3)

使用后呈现的结果:
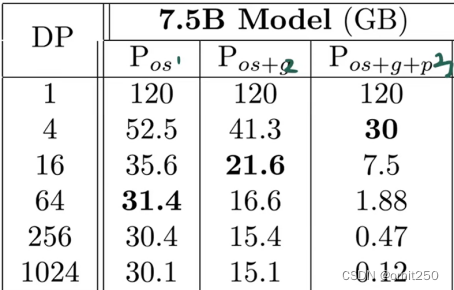
6.如何降低中间变量
①切分层(主要作用于模型并行)
PA:
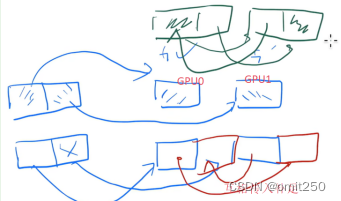
②buffer
类比:在发送数据上,等待足够多的再发送,就像把包裹塞满卡车
③内存整理
(上述都是使用在上层)
7.在megantron上
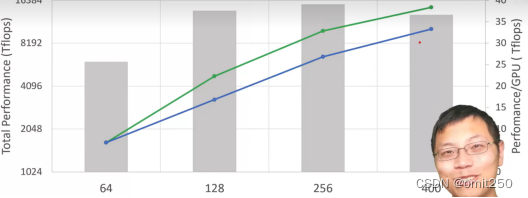
①实验主图

②超线性性能增长















 1845
1845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









