







论文介绍
题目:
Separable Self and Mixed Attention Transformers for Efficient Object Tracking
论文地址:
创新点
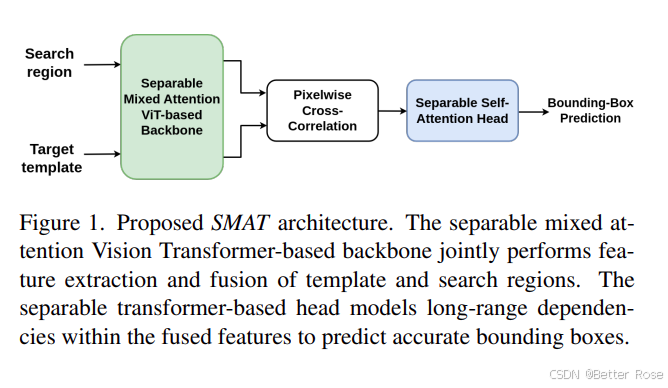
论文提出了一种名为SMAT的轻量级目标跟踪架构,它利用可分离的自注意力和混合注意力变换器来有效地融合模板和搜索区域的特征,以生成更优越的特征编码,并通过对编码特征进行全局上下文建模来实现鲁棒的目标状态估计。SMAT在多个基准数据集上超越了相关轻量级跟踪器的性能,同时在CPU上以37帧每秒、GPU上以158帧每秒的速度运行,并具有3.8M的参数量。
-
高效的自注意力和混合注意力变换器架构:文章提出了一种基于变换器的轻量级跟踪架构,该架构利用可分离的混合注意力变换器来融合模板和搜索区域,以生成更优的特征编码。
-
全局上下文建模:所提出的预测头通过利用高效的自注意力块对编码特征进行全局上下文建模,以实现鲁棒的目标状态估计。
-
轻量级跟踪器的首次部署:文章首次同时部署了基于变换器的轻量级跟踪器的主干网络和头部模块。
-
性能和参数效率:所提出的轻量级跟踪器SMAT(Separable Self and Mixed Attention-based Tracker)在多个基准测试中超过了相关轻量级跟踪器的性能,同时在CPU上以37 fps的速度运行,在GPU上以158 fps的速度运行,并且只有3.8M的参数。
-
混合注意力Vision Transformer主干网络:文章采用了级联的卷积神经网络(CNN)和Vision Transformer(ViT)块,这种混合设计结合了卷积(学习空间局部表示)和变换器(建模长期依赖性)的优点,并且参数更少。
-
可分离自注意力变换器预测头:预测头有效地对编码特征进行全局上下文建模,使用可分离的自注意力单元,与完全基于卷积的方法相比,提高了定位精度。
方法
模型总体架构
这篇文章提出的模型SMAT(Separable Self and Mixed Attention-based Tracker)总体架构包含两个主要部分:一个是基于Vision Transformer的可分离混合注意力主干网络和一个基于自注意力的预测头。主干网络利用级联的CNN和ViT块来提取特征,并在ViT块中通过混合注意力机制融合模板和搜索区域的信息,以生成更优越的特征编码。
注意力融合
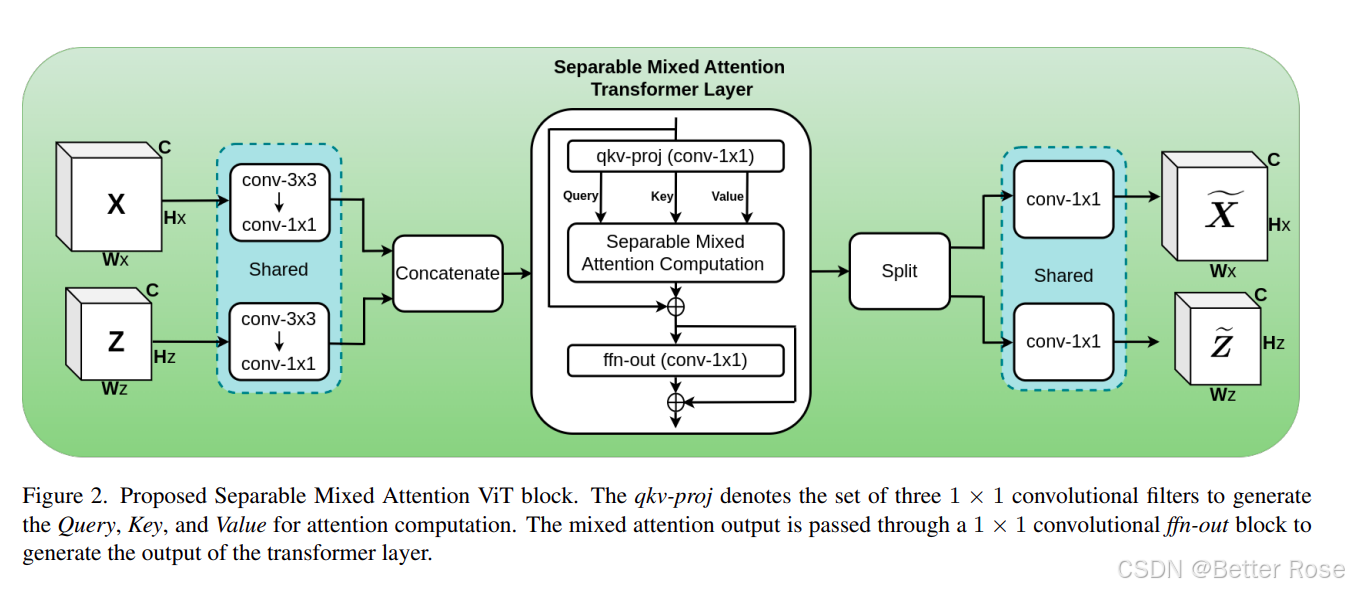
在文章提出的模型中,ViT(Vision Transformer)块通过混合注意力机制实现了模板和搜索区域信息的融合。这种方法的核心思想是在特征提取阶段就让模板和搜索区域进行信息交流,而不是像传统方法那样独立处理这两个区域。
具体来说,ViT块首先接收目标的模板图像和搜索区域图像作为输入。在ViT块内部,这两个输入会通过一系列卷积层处理,这些卷积层能够减少图像的空间维度并生成局部特征表示。接着,这些特征会被“标记化”,即转换成一系列的“tokens”,这些tokens代表了图像中的不同区域。
混合注意力机制的关键步骤是,它将模板和搜索区域的tokens合并在一起,然后在合并后的tokens上计算注意力。这种计算方式允许模型同时考虑来自模板和搜索区域的信息,捕捉它们之间的相互关系。通过这种方式,模型能够学习到如何在全局范围内整合两个区域的特征,从而更好地理解目标的外观和上下文。
在计算完注意力之后,ViT块会输出更新后的特征表示,这些特征表示已经融合了模板和搜索区域的信息。这些融合的特征随后会被送入模型的下一个阶段,即预测头,用于最终的目标定位。
总的来说,混合注意力机制通过在ViT块内部合并和处理模板和搜索区域的特征,实现了特征的融合,这有助于提高跟踪器在复杂场景下的性能和鲁棒性。


















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









