







目录
参考链接
一、引言

聚类是一种数据挖掘技术,将相似的数据放入相关或同质的组中,而无需事先了解组的定义。具体而言,聚类是通过将与组内其他对象具有最大相似性、与其他组中的对象具有最小相似性的对象分组而形成的。这是一种有用的探索性数据分析方法,因为它通过客观地将数据组织成相似的组来识别未标记数据集中的结构。此外,聚类常被用于探索性数据分析以生成features,并作为其他数据挖掘任务的预处理步骤或作为复杂系统的一部分。
聚类中一种特殊类型的聚类是时间序列聚类。因为时序数据相对于常规的静态数据,具有时间上的依赖性。这种特性对于时序数据的聚类往往非常重要。
二、时间序列聚类的作用
1. 时间序列数据库包含可以通过模式发现获得的有价值的信息。聚类一种常见的解决方案,用于揭示时间序列数据集上的某些有规律的模式。
2. 时间序列数据往往非常庞大,人类无法很好地用直观的方式来理解,通过时间序列聚类,将不同的时序数据进行划分,然后分而分析之,在一定程度上,理解时序问题会变得更简单些。
3.时间序列聚类是最常用的一种探索技术,也常常是更复杂的数据挖掘算法(如规则发现、索引、分类和异常检测)的必备过程之一。
4. 将时间序列的簇结构表示为可视化图像(时间序列数据的可视化,通过gfk等方式将时序数据转化为图像)可以帮助用户快速理解数据集中的数据结构、簇、异常和其他规则。
三、时间序列数据的聚类问题正式定义
定义:时间序列聚类,给定一个时序数据集D={F1,F2......Fn},我们的目标是将其聚类为 C={C1,C2....Ck}个簇;
注意,这里的定义对于单序列和多序列问题同样适用:
对于单序列而言,F1~Fn表示的是不同的时间步,例如对于棉袄的销量数据而言,冬天和夏天的销量数据可能会被划分为两个簇群;
对于多序列而言,F1~Fn表示的是不同的时序对象,例如棉袄和鞋子的销量数据可能会被划分为两个簇群。
四、时序数据的聚类的挑战
1.时序数据往往很长,因此时序数据的数据量往往很大,如果再考虑多变量那真是大的离谱了,而聚类所需要的计算复杂度往往不低,导致大型时序数据的聚类速度非常慢,对于空间的占用需求也很高;
2.高维的时序数据使得许多常规的聚类算法不work了,因为维度越高,常规的闵氏距离度量越不work。
3.时序数据的相似度如何定义,例如对于北京的商品A的销量和上海的商品A的销量可能是相似的,而北京的商品A的销量和十八线小城市的商品A的销量可能是不相似的,但是如果排除数据的量级而言,单纯观察时序数据的趋势和周期等特性,商品A在各个城市的销量可能又是相似的,因此不能简单套用常规的表格数据中的聚类方法的相似度度量方法。
4.时序数据相对表格数据而言,更容易存在各类噪声,例如异常值(双十一销量非常高)和数据偏斜问题(今年的爆款明年热度下降)
5.多序列问题中,不同序列数据的长度不同
五、时间序列数据聚类有什么用
时间序列聚类的应用时间序列数据的聚类主要用于发现时间序列数据集中感兴趣的模式,该任务本身分为两类:
- 用于查找数据集中经常出现的模式。例如,股价变动相似的公司的发现,商店中特定产品的不同日常销售模式
- 发现数据集中发生的异常模式的方法。时间序列的聚类可以在不同的领域解决以下现实世界的问题:异常检测(anomaly detection)、新奇检测(novelty detection)或不和谐检测( discord detection)
六、时间序列聚类技术的分类
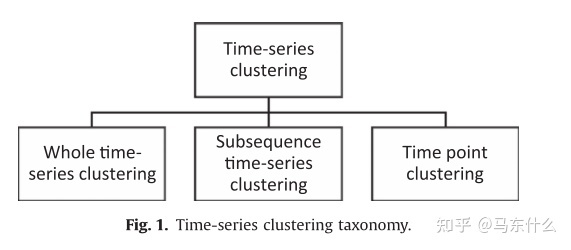
1.全时间序列聚类(whole time series clustering)是指对一组时间序列的相似性进行聚类,即对多个序列数据之间进行聚类。
2.子序列聚类(subsequence time series clustering)是指对单个时间序列的一组子序列进行聚类,通过滑动窗口提取子序列,即对单个长时间序列中的片段进行聚类。
3.时间点聚类(time point clustering)。它是基于时间点的接近度和对应值的相似性的时间点的聚类。这种方法类似于时间序列分割。但与分割不同的是,它不需要将所有的点都分配到聚类中,也就是说,会有一些时间点被认为是噪声点。
从本质上讲,子序列聚类是对单个时间序列进行的,Keogh和Lin[242]表示这种类型的聚类是没有意义的。时间点聚类也只适用于单个时间序列,类似于时间序列分割,时间点聚类的目标是找到时间点数据的聚类,而不是时间序列数据的聚类。
本研究的重点是“全时间序列聚类”
全时间序列的聚类通常有三种不同的方法,即基于形状、基于特征和基于模型。如下表

1.在基于模型的方法中,每个时间序列被转换为模型参数(这里说的是对时序数据做representation,比如基于lstm自编码器对原始时序数据做representation),然后选择合适的模型距离和聚类算法(通常是传统的聚类算法),并将其应用于提取的模型参数。然而,研究表明,通常基于模型的方法存在可伸缩性问题[78],当clusters彼此靠近时,其性能会降低(representation的过程中不可避免的会引入信息的缺失)。即先降维再聚类。
2.在基于特征的方法中,原始时间序列被转换成低维特征向量(例如基于滑动窗口做特征衍生,时间序列分解等,和基于模型的方法类似,只不过是通过人工的方式来主观的引入某些特征抽取的方法)。然后采用传统的聚类算法对提取的特征向量进行聚类。通常在这种方法中,先从每个时间序列中计算等长特征向量,然后进行欧氏距离测量。
3.在基于形状的方法中,两个时间序列的形状尽可能地匹配,通过非线性的时间轴的拉伸和收缩。这种方法也被称为基于原始数据的方法,因为它通常直接处理原始时间序列数据。基于形状的聚类算法通常采用传统的聚类方法,这种聚类方法与静态数据兼容,同时对其距离/相似度度量进行了修正(即不使用欧式距离而是使用dtw这种专门用于时序数据的相似度度量的方式),使之适用于时间序列。
4.multistep approach是shape based 和 features-based的方法的组合。
七、时间序列聚类的四步骤:
回顾已有的文献,可以发现时间序列聚类本质上由4个步骤组成:
1.特征抽取(人肉抽取or模型抽取(representation)都是一种特征抽取的方法);
2.距离度量:
3.prototype
4.结果评估。
时间序列聚类一般会适用上述的部分或全部步骤。
通常,数据通过特征抽取的方式(人肉or模型)把内存压力先降下来(简单的例子,1000天的数据通过300的时间窗口,中间间隔为100进行时间窗内的均值,方差计算,这样原始的数据就被特征抽取为维度很低的统计特征,显然,这类方式或多或少存在一些细节的信息的缺失)。
然后,利用距离测度对数据进行聚类。
在聚类过程中,通常需要一个prototypes来对时间序列进行总结。
最后,利用某些评估准则对聚类结果进行了评价。
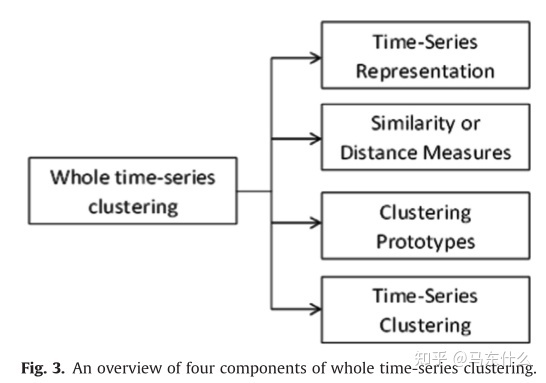
需要注意,这里作者把一个大的聚类算法拆解为两部分:
1.相似度度量;
2.prototype
例如对于dbscan而言,其prototype就是基于密度的聚类思想确定出来的某些簇心,而密度的度量则可以结合不同的相似度度量方法来定义。比如sklearn中的knn的距离定义可以由用户自由选择或自定义。
下面分别介绍这四个部分:
考虑到作者把人肉特征工程和模型的自动特征工程这类特征抽取的方法都称之为representation,因此下文也统一用represantation来表示这一过程。
1、时间序列的representation

这是文献[9,80 - 82]中提出的大多数全时间序列聚类方法的通用解决方案。之所以通用,是因为这种方法可以结合现有的许多成熟的聚类技术,在工程开发上压力也很低,简单来说,通过representation的方法我们只是对原始数据做特征抽取,然后将抽取的结果存储之后,剩下的事情和常规的聚类做的事情是一样的。除此之外,这么做的好处还有:
1.representation往往意味着维度降低,比如word2vec就大大降低了word onehot之后的维度;
2.一些距离测量对时序数据中的某些“扭曲”非常敏感,即时序数据中存在的噪声点要比常规的表格数据高的多,直接聚类的结果很容易产生“对噪声相似的时间序列进行聚类”,
这方面,如何选择representation的方式以及如何取得效率和质量的完美平衡是一个具有挑战性的任务。
定义:给定一个时间序列F={F1,F2....Ft},时间序列的representation就是将其转换为:Fnew={Fnew1,Fnew2...Fnewx},其中x<t,如果时间序列F和另一个时间序列M在原始的特征空间中相似,则representation之后的结果也要相似。
选择合适的representation方法是影响效率和精度的关键因素。大多数时间序列数据[6]具有高维数和噪声的特点,因此,在全时间序列聚类中通常采用降维方法来解决这些问题并提高性能。时间序列降维技术已经取得了长足的发展,在大规模时间序列数据集上得到了广泛的应用,每种技术都有自己的特点和缺点。
这里值得一提的是最近在表示方法方面的一个比较。H. Ding等[91]在38个数据集上对8种representation方法进行了综合比较。他们已经研究了这些representation方法的有效性,结果也有利于聚类目的,它们使用下界的紧性来比较representation方法的效果,结果表明,最近的representation方法之间的差异非常小。
representation of time series可以划分为:
自适应、非数据自适应、基于模型和数据指示的表示方法,如下图所示

1.数据自适应:数据自适应表示方法对数据集中的所有时间序列进行表示,并尝试使用任意长度(非等长)段最小化全局重构误差[94]。该技术已被应用于不同的方法,如分段多项式插值(PPI)[95],分段多项式回归(PPR)[96], 分段线性近似(PLA)、分段常数近似(PCA)、自适应分段常数近似(APCA)[87]、奇异值分解(SVD)[20,97]、自然语言(Natural Language)、符号自然语言(NLG)[98]、符号聚合近似(SAX)和iSAX[84]。数据自适应表示可以较好地逼近每个序列,但比较多变量的时间序列比较困难。
2. 非数据自适应方法是一种适用于固定大小(等长)分割时间序列的表示方法,多个时间序列的表示方法比较简单。这一组方法有小波变换,离散小波变换(DWT),谱Chebyshev多项式[99],spectral DFt[20],随机映射[100],分段聚合近似(PAA)[24]和可索引分段线性近似(IPLA)[101]
3. 基于模型的方法以一种随机的方式表示时间序列,如马尔可夫模型和隐马尔可夫模型(HMM)[102-104]、统计模型、时间序列位图[105]和自动回归移动平均(ARMA)[106107]。在数据自适应、非数据自适应和基于模型的方法中,用户可以根据手头的应用自己来定义压缩比。
4.相反,在数据指示方法中,压缩比是基于原始时间序列(如Clipped[83,92])自动定义的。
下表列出了文献中常用的几种表示方法:


小结:
在以往的研究中,研究人员对时间序列数据提出了许多不同的representation方法。这些方法大多侧重于加速计算,并且大多强调为实现这一目标而建立索引的过程,另一方面,其他一些方法考虑了representation的质量,如[83]中,作者关注表示方法的准确性,并提出了时间序列的水平近似。每个时间序列由一个位串表示,每个位值指定数据点的值是否高于时间序列的平均值。这种表示可以用来计算时间序列的近似聚类。这种表示也称为剪切representation,可以与原始时间序列进行比较,但在其他表示中,必须将数据集中的所有时间序列转换为相同的降维表示。然而,剪切序列在理论上和实验上已经足够用于基于变化相似度的聚类(基于模型的不相似度量),而不是基于形状的聚类。回顾文献表明,对于离散的时间序列的研究工作是有限的,而且值得注意的是,大多数研究工作是基于均匀抽样数据,而有限的工作是针对不均匀抽样数据。此外,在大多数研究工作中,数据误差没有被考虑在内。最后,在本文综述的所有论文中,没有一篇涉及处理每个变量长度不同的多元时间序列数据。
2、时序聚类中相似度的定义

时间序列聚类在很大程度上依赖于合理的相似度定义。有不同的方法可以用来测量时间序列之间的距离。
在传统的聚类中,静态对象之间的距离是完全匹配的,而在时间序列聚类中,距离是近似计算的。特别是,为了比较采样间隔和长度不规则的时间序列,充分确定时间序列的相似性具有重要意义。有不同的距离度量来指定时间序列之间的相似性。豪斯多夫距离、修改豪斯多夫(MODH) HMM-based距离,动态时间规整(DTW),欧几里得距离,和最长公共子序列(lcs)是最受欢迎的用于时间序列数据的距离测量方法。距离测量方法参考如下图所示。计算两个时间序列之间距离的最简单方法是将它们视为单变量时间序列,然后计算所有时间点之间的距离度量,但是这种方便无法用于多变量的时间序列数据问题。


定义:时间序列的距离/相似性
给定一个时间序列Fi={Fi1,Fi2,Fi3....Fit},则两个时间序列数据之间的距离定义为:

当然,如果对时序进行截断,重采样等,上述距离依然成立,只不过T发生变化而已。
我们前面提到过,

由于基于shape的聚类方法并不对原始的时序数据进行representation,因此,基于形状的时间序列的相似度的度量通常更容易遇到噪声、幅度缩放、偏移平移、纵向缩放、线性漂移、不连续和时间漂移等时间序列数据的共性问题所干扰,这些问题在文献中得到了广泛的研究[86]。
选择合适的距离方法取决于时间序列的特性、时间序列的长度、representation的方法,当然也在很大程度上取决于聚类时间序列的目标。如下图所示:
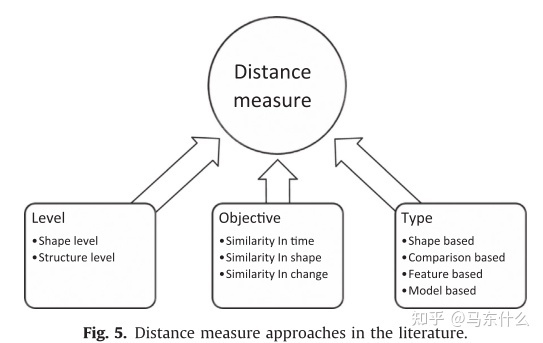
这里优先介绍objective层面的选择,毕竟这是和业务目标最为契合的相似度的选择方法:

1. similarity in time,这种方式所定义的时间序列自建的相似指的是两个时间序列数据在每一个时间步上都相似,例如欧式距离就很适合这样的目标。然而,因为这种相似度的计算方式对于长时间序列的计算往往是非常耗费时间的,因此,计算常常是在变换后的时间序列上进行的,例如傅里叶变换、小波变换或分段聚合近似(PAA)。 Keogh和Kasetty[6],对这个问题做了全面的回顾。一个典型的例子,将许多公司相关的股价的时间序列聚类,以发现哪些股票一起变化,以及它们如何相互关联)被归类为基于similairity in time。
2. similarity in shape: 在形状上寻找相似的时间序列模式并不care两个时间序列是否在相同的时间步上相似,即我们关心的是时序数据本身的形态,并不关心二者发生的时间,这也意味着similarity in shape的方法比similarity in time的方法要灵活的多,因为我们并不需要对不同的时间序列数据进行时间上的对齐(例如截断或补0等处理)。因此,这类similarity会采用弹性的相似度测量方法,例如Dynamic time Warping, DTW)进行相似度计算。利用这一定义,可以构建具有相似变化模式的时间序列的聚类,而不管时间点如何,
例如,将具有共同股票模式的不同公司的股价聚类,而不依赖于其在时间序列中的出现[1 12]。时间上的相似性是形状上的相似性的一种特殊情况,即在形态上的相似性问题中强制希望不同时间序列数据的时间点完全对齐的时候,similarity in shape 退化为 similarity in time。
3. similarity in change:
该方法通常利用隐马尔可夫模型(HMM)[1 16]或ARMA过程[107117]等建模方法,然后测量拟合模型参数与时间序列的相似性。即具有相似自相关结构的时间序列聚类,如次日股价下跌后有上升趋势的股票聚类[1 12]。这种方法适用于长时间序列,而不适用于有限或短时间序列[21]。关于这一点可能不是那么直观,结合下面的内容来理解。
然后我们这里讲一下shape level和structure level ,对于理解上述的三种方法有很好的帮助:
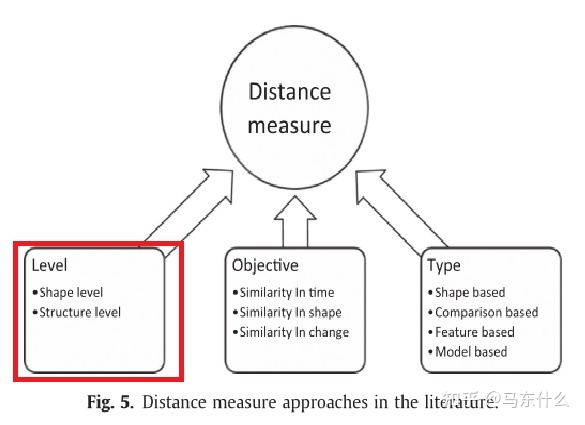
相似度的定义还可以根据时间序列的长度分为“shape level”和“structure level”两类。
“shape level”通常用来作为短时间序列聚类问题中相似度定义方法,比较的是局部模式上的相似性,而“sructure level”则是度量基于全局和高层结构的相似度。
针对短时间序列,本文采用了shape level 相似度的定义。根据时间序列的目标和长度,确定适当的距离度量类型。从本质上讲,文献中有四种距离测量方法。距离测量的类型请参考下图。

看了半天,分这种多种方法,给我搞懵了,关键名儿还差不多。。裂开,下面阐述第三种划分方式:、

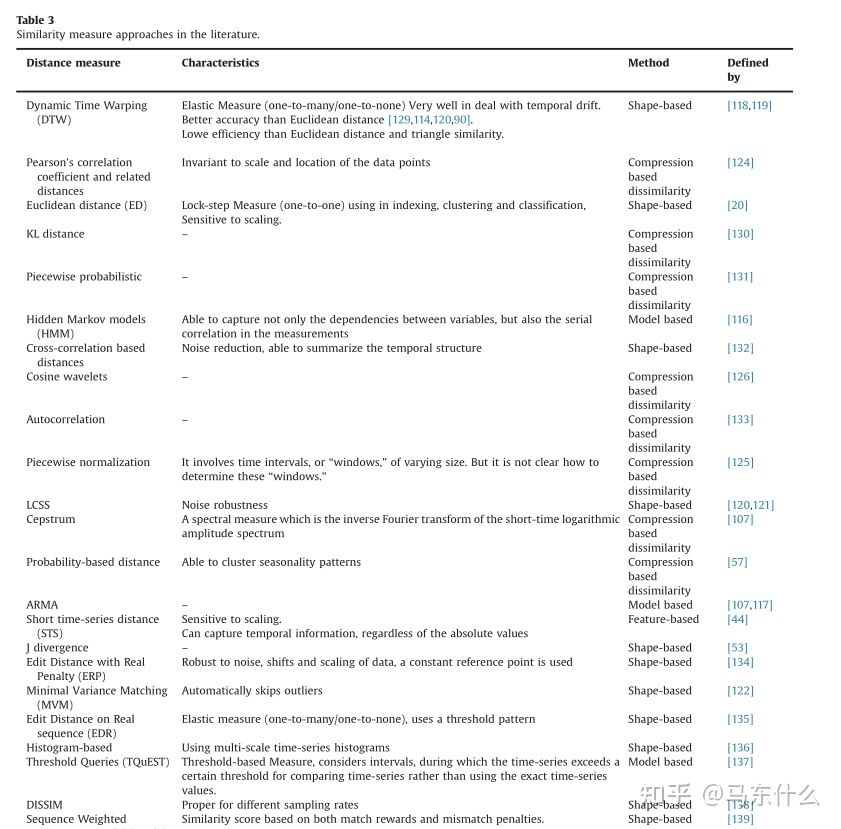
- shape based的相似性度量是在时间和形状上寻找相似的时间序列,如Euclidean, DTW[1 18,119], LCSS[120,121], MVM[122]。这是一组适用于短时间序列的方法。
- comparison based的相似度 适用于短时间序列和长时间序列,如CDM[123], Autocorrelation, Short time-series distance[44], Pearson’s correlation coefficient and related distances[124], Cepstrum[107], Piecewise normalization[125]and Cosine wavelets[126]。
- feature based的相似性度量适合于长时间序列,如Statistics, Coefficients,
- model-based的相似度度量 适合于长时间序列,如HMM[1 16]和ARMA[107,117]。
Last和Kandel对各种有效检索相似时间序列的方法进行了研究[127]。在[16]中,作者还提出了各种测量方法的公式。然后,Zhang等[128]对上述距离测量进行了全面的调查,并在不同的应用中进行了比较。在上图的table3中,从复杂性和特征方面比较了不同的度量方法。
关于距离度量的一些思考和讨论
在时间序列聚类领域,选择一个足够精确的距离度量是一个有争议的问题。研究人员提出了许多距离度量方法,并在上一节的table3中进行了比较和讨论。然而,我们可以从文献中得出以下结论:
1) 通过研究上述的相似性/不相似性度量方法,可以发现最有效和准确的方法是基于动态规划(DP)的方法,这种方法的时间复杂度很高(因为比较两个时间序列的时间复杂度为O(n^2),n为序列的长度)[143]。尽管通常会对这些距离/相似性度量采取一些约束来降低复杂性[1 19,144],但它需要仔细地调整参数以提高效率和有效性。因此,在选择相似性度量时时,应该在精度和效率之间找到平衡。另一种观点是,有必要理解距离测量在大尺度时间序列数据集中的有效性。这个问题不是从文献中得到的,因为大多数被考虑的论文都是基于相当小的数据集
2) 在相似性度量的研究中,距离度量面临着各种挑战。一个很大的挑战是距离度量与representation方法的不兼容问题。例如,用于时间序列分析的常用方法之一是将时序数据从时域转换到频域上,而在使用频域空间时,很难找到序列之间的相似性以产生基于值的差异用于聚类。
3) 欧氏距离和DTW是时间序列聚类中最常用的相似性度量方法。有研究表明,在时间序列分类精度方面,欧氏距离具有惊人的竞争力[145],而DTW在相似性度量方面也有其不可削弱的优势。
八、时间聚类的算法选择
在时间序列聚类方法中,寻找聚类的prototype算法或聚类的representation是一个必不可少的子程序。
解决时间序列聚类质量不高问题的方法之一是纠正聚类原型不准确的问题,聚类的质量高度依赖于prototype的质量。给定一个簇中的时间序列,可以清楚地看到簇中的所有时间序列与其prototype之间的距离最小。使Ci最小的时间序列,Rj 被称为steiner sequence[148]。公式如下

但是,通常可以看到定义prototype的三种方法:
1. The medoid sequence of the set. 集合中的medoid sequence
2. The average sequence of the set. 集合中的average sequence
3. The local search prototype. 局部搜索的prototype
下面将对这三种方法进行解释和讨论。
1. The medoid sequence of the set. 集合中的medoid sequence
在时间序列聚类中,最常用的接近最优Steiner序列的方法是使用聚类簇的medoid sequence作为prototype[150]。在这种方法中,集群的中心被定义为一个序列,该序列最小化到集群内其他对象的距离的平方和。给定聚类中的时间序列,聚类中所有时间序列对的距离使用某种距离度量例如欧几里得或DTW来计算。然后,将聚类中平方和误差较小的一个时间序列定义为聚类的medoid sequence [151]。
此外,如果距离是一种非弹性的方法,如欧几里得距离,则可以计算出cluster的质心,并且认为 medoid是最接近质心的时间序列。聚类medoid sequence是在时间序列聚类相关的研究中非常常见的方法,并已在许多论文中使用,如[77,150,152,153]。
2. The average sequence of the set. 集合中的average sequence
如果时间序列都是等长的,聚类过程中的距离度量是一个非弹性距离度量(如欧氏距离),则平均方法是一种简单的平均技术,即时间序列在每个点上的平均值。此时的做法其实等同于在做常规的静态数据的聚类,只不过每个时间步的序列值对应着每个特征。
然而,如果不同的时间序列长度各不相同,或我们定义的是similarity in shape,则上述的方式不合适,此时,使用DTW或LCSS的距离度量是比较合适的。
3.局部搜索的prototype
该方法首先计算聚类的medoid sequence prototype,然后使用平均法(第4.2节),基于wraping path计算平均prototype。然后,根据average prototype 计算出新的wraping path。Hautamaki等[77]提出了一种通过局部搜索获得的原型,而不是medoid,以克服欧氏空间中时间序列聚类质量较差的问题。他们在k-Medoids上应用medoid、average和局部搜索、随机交换(RS)以及层次聚类来评估他们的工作。他们发现,局部搜索提供了最好的聚类精度,也比k-Medoids更好。然而,与S. Aghabozorgi等人/ Information Systems 53(2015)的研究相比,尚不清楚它有多少改进,例如另一种常用的prototyp是medoid平均方法。
小结:
导致聚类精度低的问题之一是时间序列聚类过程中prototype的定义或更新方法较差,特别是在划分方法上。许多聚类算法存在表示方法准确率低的问题[77,149]。而且,不准确的原型会影响聚类算法的收敛,导致得到的聚类质量较低[149]。在第4节中讨论了定义prototype的不同方法。在本研究中,由于使用的距离度量是一个非弹性距离度量(ED),因此使用平均方法来寻找子簇的prototype。虽然为了合并的目的,可以使用任意方法,如果它兼容弹性方法,如[158],但是对于不同的方案,简单的“medoid”作为原型,以兼容距离度量DTW的弹性,使用k-Medoids算法,并为现有方法对所提模型的评价提供公平的条件。
1、时间序列中的聚类算法
一般聚类可大致分为六类:分区聚类、分层聚类、基于网格聚类、基于模型聚类、基于密度聚类和多步聚类算法。
AI研习社 - 研习AI产学研新知,助力AI学术开发者成长。god.yanxishe.com/columnDetail/27227

相对之前写的部分,多了一个multi step clustering的方法。
下面详细讨论了不同的聚类算法在时间序列聚类中的应用。
1. 层次聚类是一种聚类分析方法,利用凝聚或分裂的方式将样本划分成不同层次的聚类簇。凝聚式的层次聚类初始将每个样本视为一个聚类簇,然后逐步合并聚类(自底向上)。相比之下,分裂算法则完全相反。一般来说,分层算法的质量较差,因为在分裂法中,分簇后无法调整聚类,在凝聚法中,合并后也无法调整聚类。因此,通常将分层聚类算法与另一种聚类算法相结合,形成一种混合聚类方法来解决问题。层次聚类在时间序列聚类中具有很强的可视化能力[86166],这使得它在很大程度上成为时间序列聚类的一种方法。由于二次计算的复杂性,分层聚类本质上不能有效地处理大时间序列[21],因此可扩展性差,限制在小数据集。
2.分区聚类方法从未标记的对象中生成组,每个组至少包含一个对象。划分聚类最常用的算法之一是k-Means,其中每个聚类都有一个prototype,该prototype是其对象的均值。k-Means聚类背后的主要思想是最小化一个聚类中所有对象与它们的聚类中心(原型)之间的总距离(通常是欧氏距离)。


k-Means过程中的原型定义为聚类对象的均值向量。然而,当涉及到时间序列聚类时,这是一个具有挑战性的问题,kmeans需要确定簇的数量这一点比较烦人,但是与层次聚类相比,k-Means和k-Medoids的聚类速度非常快[169,172],这使得它们非常适合于时间序列聚类,并在许多工作中被使用[18,60,77,112,173]。k-Means和k-Medoids算法以“hard”或“soft”的方式构建聚类,这意味着一个对象要么是一个聚类的成员,要么不是。另一方面,FCM(Fuzzy c-Means)算法[174,175]和Fuzzy c-Medoids算法[176]构建“软”聚类。在模糊聚类中,对象在每个聚类中都有隶属度[177]。模糊划分算法已被用于某些领域的时间序列聚类。
3.基于模型的聚类试图从一组数据中恢复原始模型。这种方法为每个集群假定一个模型,并找出最适合该模型的数据。详细地说,它假设有一些随机选择的质心,然后一些噪声以正态分布添加到它们。从生成数据中恢复的模型定义了cluster。比较为人所知的是GMM,SOM和HMM,一般来说,基于模型的聚类有两个缺点:首先,需要设置参数而且它是基于用户的假设(例如GMM假设原始数据服从混合高斯分布),而用户的假设可能是错误的,因此聚类结果将是不准确的。其次,在大数据集上处理时间较慢(尤其是SOM)[186]。
4.在基于密度的聚类中,聚类是密集对象的子空间,这些子空间被低密度对象的子空间分隔开。其中一个著名的基于密度概念的算法是DBSCAN[187],在该算法中,如果一个集群的邻居密度较大,则该集群将被扩展。OPTICS[188]是另一种基于密度的算法,它解决了在不同密度的数据中检测有意义的簇的问题。Chandrakala和Chandra[189]提出的模型是少数案例之一,作者提出了一种基于密度的核特征空间聚类方法,用于聚类变长度的多元时间序列数据。此外,他们还提出了一种启发式的方法来寻找他们提出的算法中所使用的参数的初值。然而,回顾文献可以发现,基于密度的聚类方法由于其较高的复杂性,尚未被广泛应用于时间序列数据聚类。
5.基于网格的聚类方法将空间量化为有限数量的网格单元,然后在网格单元上执行聚类。STING[190]和Wave Cluster[191]是基于网格概念的聚类算法的两个典型例子。据我们所知,引用的文献中没有应用基于网格的方法来聚类时间序列的工作。
在表4a中,根据所采用的表示方法、距离度量、聚类算法以及适用时的原型定义,对相关工作进行了总结。考虑到大量的工作,我们了解到,在大多数模型中,作者使用时间序列数据作为原始静态数据或进行representation之后,使用标准的传统聚类算法。很明显,这种使用没有任何优化的蛮力方法来分析时间序列的方法是科学理论的正确解决方案,而不是现实世界的问题,因为它们在大型数据库中自然非常缓慢或不准确。因此,在许多研究中,研究者的注意力被吸引到使用更定制的算法对时间序列数据聚类作为最终的解决方案。在接下来的章节中,我们将讨论具体的方法,并着重讨论如何解决聚类过程中由于上述问题而导致的时间序列聚类质量较低的问题。
2、时间序列聚类评价方法
一般来说,在没有数据标签的情况下,对抽取的cluster进行评估是不容易的,这仍然是一个悬而未决的问题。cluster的定义取决于用户和领域,而且是主观的。例如,聚类的数量、聚类的大小、离群值的定义、问题中时间序列之间相似性的定义,都是依赖于手头任务的概念,应该主观地声明。这些都使得时间序列聚类成为数据挖掘领域的一大挑战。但是,由于分类数据标记为人工判断或它们的生成器(在合成数据集中),结果可以通过一些措施来评价。
在聚类原始数据方面,人类判断的标签并不完美,但在实践中,它抓住了算法的优缺点作为基本事实。为了评估MTC,数据集来自于它们的标签已知的不同领域。下图展示了在时间序列聚类中评价新模型的过程。
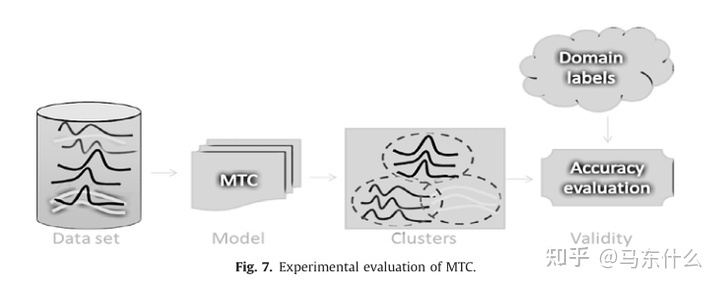
这种方法适用于存在少量标签无力构建有监督但又希望利用少量标签信息的场景。
常见的时间序列聚类的评估指标如下(对于常规的聚类大部分也适用)

采用Rand指数、adjusted Rand指数、熵、纯度、Jacard、F-measure、FM、CSM和MNI对MTC进行评价。这些聚类评价标准的取值范围都在0到1之间,其中1对应的是ground truth和finding clusters相同的情况(除了Entropy,它被反过来称为cEntropy)。
因此,在这里,更大的标准值是首选的。所提到的每一种评价标准都有其优点,在数据挖掘领域中,对于哪一种标准更好还没有达成共识。对于时间序列聚类算法,本节将讨论不同方法的评价措施。
可视化和标量测量是评价聚类质量的主要技术,在一些文章中也被称为聚类有效性[214]。评估任何新提出的模型的技术将在下面的章节中解释。
在标量精度测量中,生成一个实数来表示不同聚类方法的精度。用于判断聚类效度各个方面的数值测度分为两类:
- 外部指标(External Index):该指标用于衡量形成的聚类与外部提供的类标签或ground truth的相似性,是目前最常用的聚类评价方法[215]。在文献中,该指标又被称为外部标准、外部验证、外部方法和监督方法,因为ground truth是可用的。
- 内部指标:该指标用于衡量一个聚类结构的优度,而不考虑外部信息。在文献中,该指标也被称为内部标准、内部验证、内部方法和无监督方法。本节的其余部分将讨论这些评估技术。
剩下的没啥可看的了,这些聚类指标也就是常规的一些无监督聚类的评估方法,解释就不看了。
3、总结
时序聚类的作用:
揭示规律,探索数据手段,理解时序数据 ,用于查找数据集中经常出现的模式。例如,股价变动相似的公司的发现,商店中特定产品的不同日常销售模式;发现数据集中发生的异常模式的方法。时间序列的聚类可以在不同的领域解决以下现实世界的问题:异常检测(anomaly detection)、新奇检测(novelty detection)或不和谐检测( discord detection)
时序聚类的挑战:时序数据长,数据量大,工程压力大;高维时序数据下,很多常规聚类算法不work;时序数据的相似度定义复杂;时序数据很容易存在噪声;时序数据长度常常不同;
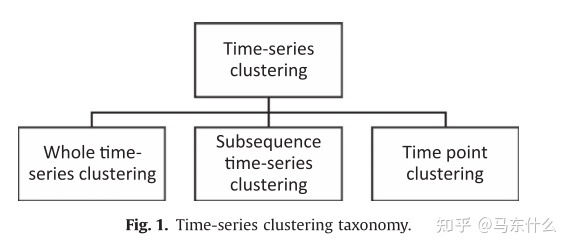
时序聚类的三个应用方向:
1.全时序数据聚类;
2.子序列聚类;
3.时间点聚类
其中,全时序数据聚类针对更常见的多序列聚类问题,例如对于不同公司的股票的价格数据进行聚类,而子序列聚类和时间点聚类则是针对单序列问题的,子序列聚类是对一个时间序列的不同时间周期下的子序列进行聚类,本质上也可以转化为全时序数据聚类,而针对单个时间序列数据的点聚类,它是基于时间点的接近度和对应值的相似性的时间点的聚类。这种方法类似于时间序列分割。但与分割不同的是,它不需要将所有的点都分配到聚类中,也就是说,会有一些时间点被认为是噪声点。
这篇文章的主题内容主要是在讲全时序数据聚类,当然,子序列聚类通过将原始的单个时间序列拆分为多个子序列从而也适用于适用全时序聚类的方法。而关于时间点聚类,文中并没有太多的描述。
怎么着手做一个时序聚类的问题:

四个方面,是否需要对原始的时序数据进行表征从而实现降维的同时保留原始数据的信息,如果需要,怎么去表征;怎么定义时序数据的相似性;使用什么样的聚类算法;聚类算法的prototypes(prototype的大体含义,在我们定义了相似性度量之后,怎么使用这种相似性度量去迭代模型,像kmeans一样使用均值?还是k-mediods一样使用中位数?还是像dbscan一样使用密度?指的是这个)
至于这四个问题有哪些解决的思路,可见原文部分这里就不赘述了,太多了也。。。
其它文章可以参考张戎大佬的:
张戎:时间序列的聚类282 赞同 · 21 评论文章正在上传…重新上传取消
张戎:时间序列的表示与信息提取450 赞同 · 25 评论文章正在上传…重新上传取消
张戎:两篇关于时间序列的论文426 赞同 · 16 评论文章正在上传…重新上传取消
时间序列数据的聚类有什么好方法?1431 关注 · 25 回答问题正在上传…重新上传取消
时间序列分类mp.weixin.qq.com/s/EF2r1GHB6JUJYLlU4idxYA正在上传…重新上传取消
深度学习+时间序列这块儿没啥综述,其实大体的方法也包含在上文中了,看了一些相关的文章,大体上主要是从representation的层面出发做一些时序数据的表征的工作,这块儿需要结合similairty measure来做,也有少数是直接将聚类作为cluster layer并入整个网络结构中,共同训练。

第二篇是2012年的,大体看了下,东西不全,相对于第一篇不详细,这里就截几张清楚的图好了


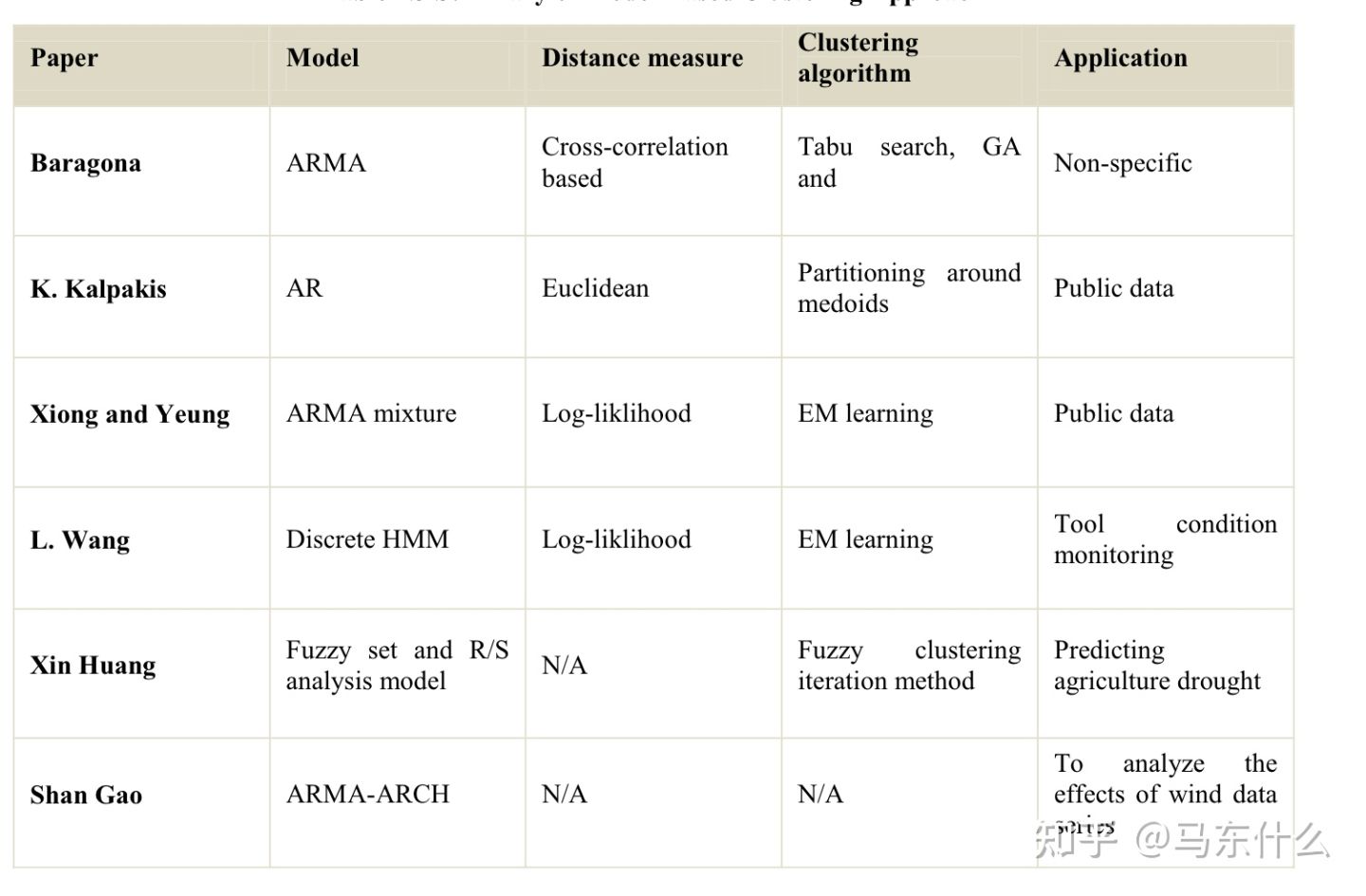














 594
594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









