










URL
https://openreview.net/pdf?id=T1Qx6EC08o
TL;DR
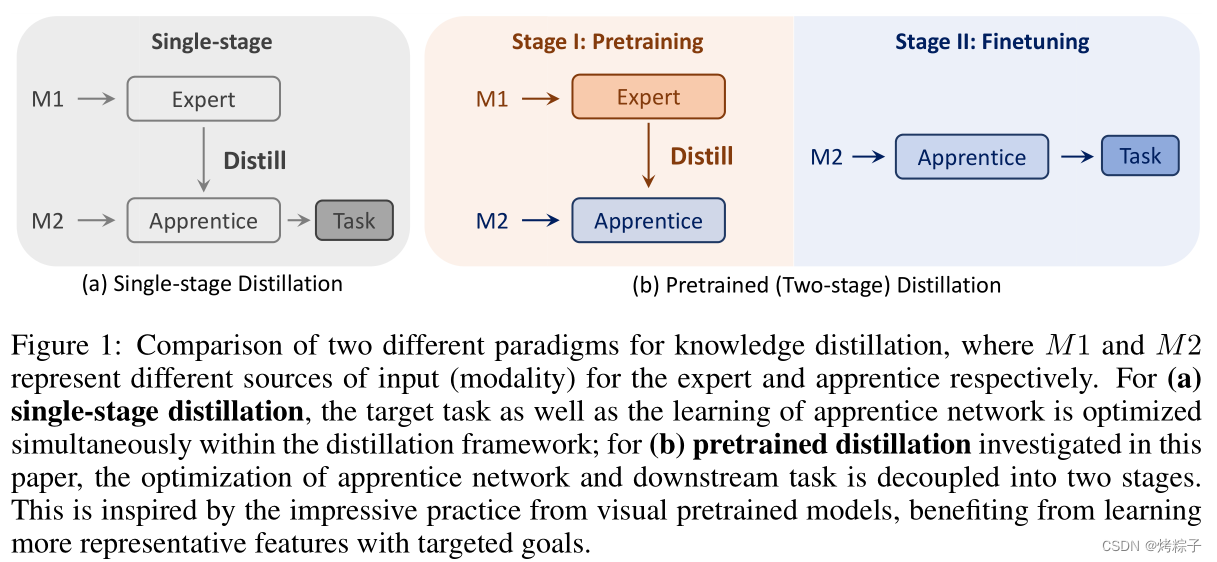
利用知识蒸馏来增强camera-based方法的特征学习。具体做法如下:
- 预训练一个高性能专家模型;
- 先从专家模型学习知识;
- 再在下游任务中进行微调;
Dataset/Algorithm/Model/Experiment Detail
模型结构
专家模型: lidar backbone 使用 TransFusion-L的backbone
为了对齐bev表征,师生使用相同的head。expert预先训练一个高性能模型。
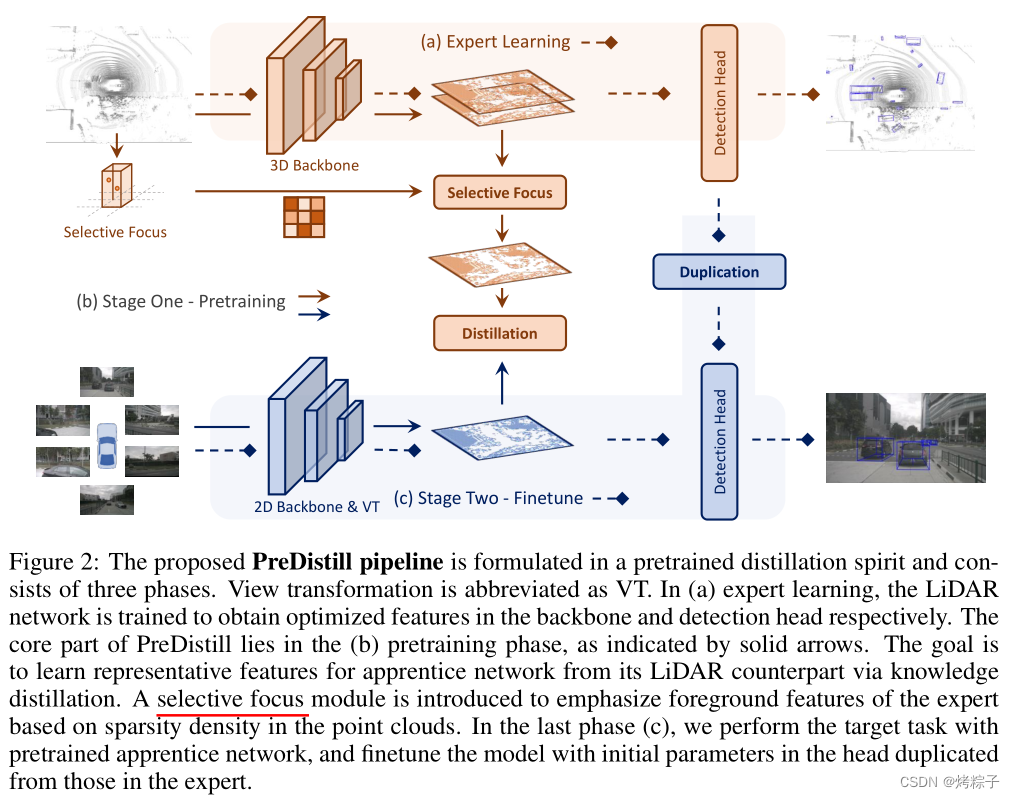
Predistill
pipline分为三部分:
- expert learning:先训练在一个3D检测任务,使用点云作为输入;
- pretraining:multi-view image作为输入,文章提出了一个 selective focus module模块,提供weighted mask, 来描述点云的密度信息;
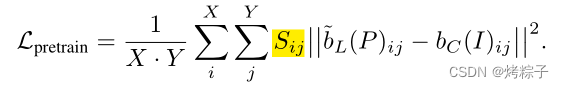
- finetuning: 学徒网络在3D检测任务上训练;同时,camera head使用和点云一样的head;因为BEV特征已经对齐,所以直接复制了点云的head,能更快收敛。 inference过程不变。
Refinements
**Selective Focus in Pretraining: ** 噪声主要来自于不准确的depth. 在BEV空间,点云数据提供更 attentive 的特征表达。由于激光雷达数据中点数量较少的区域不太可能提供高可信度的有用特征,提取这些区域的知识可能使网络偏离正确的优化目标。所以文章利用来自点云数据密度的统计提示来限制蒸馏区域。每个bev 特征points对应的pillars内包含的点云points;
本质是提出了一种特征蒸馏选区域的新的见解。
Duplication in Finetuning
BEV表示对齐后,camera学习到的特征表示分布应该遵循lidar的分布;所以camera直接复制了lidar的head和权重。
EXPERIMENTS
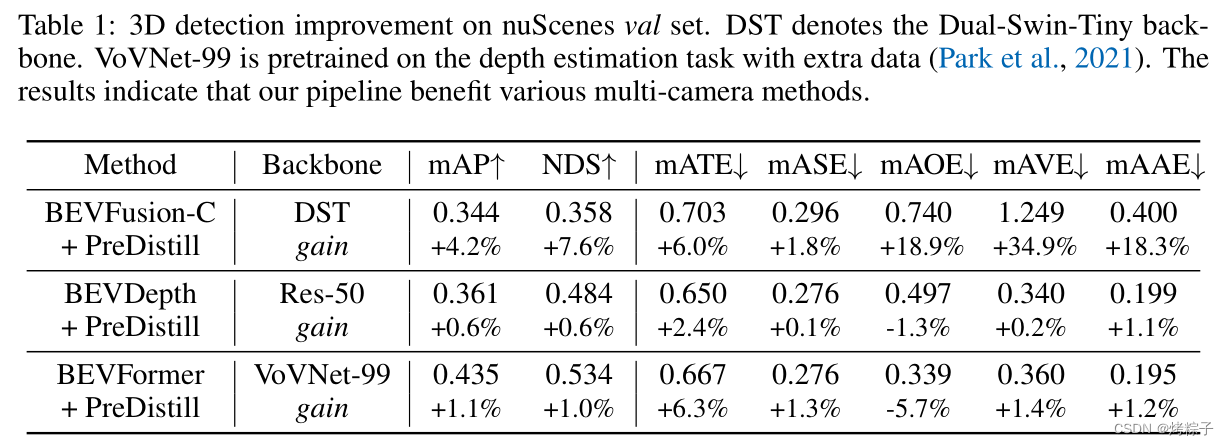
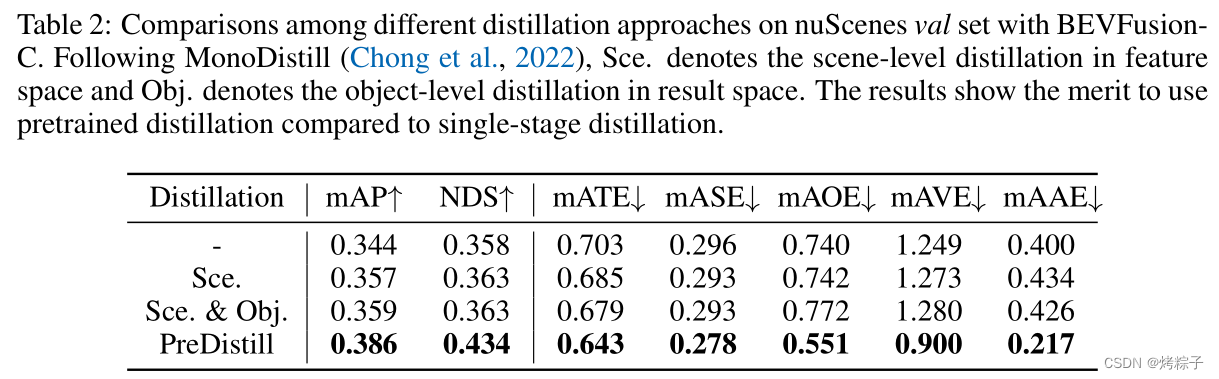
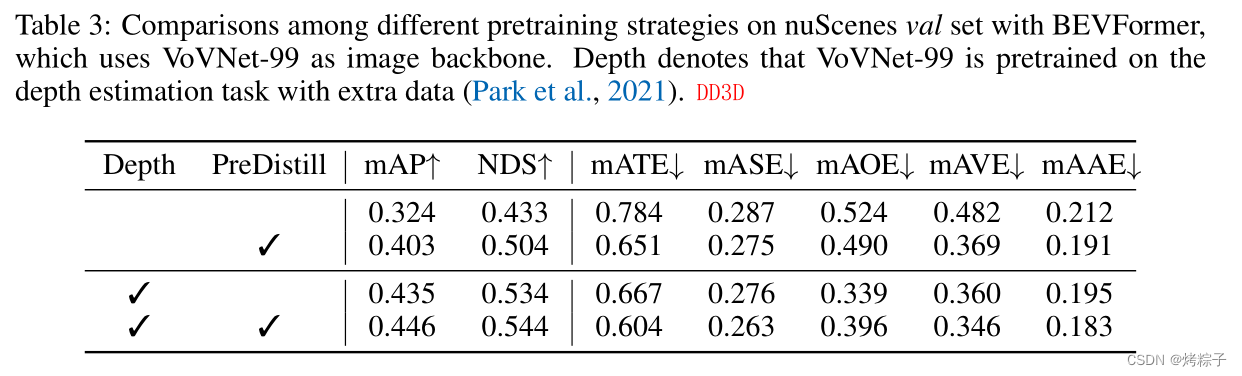
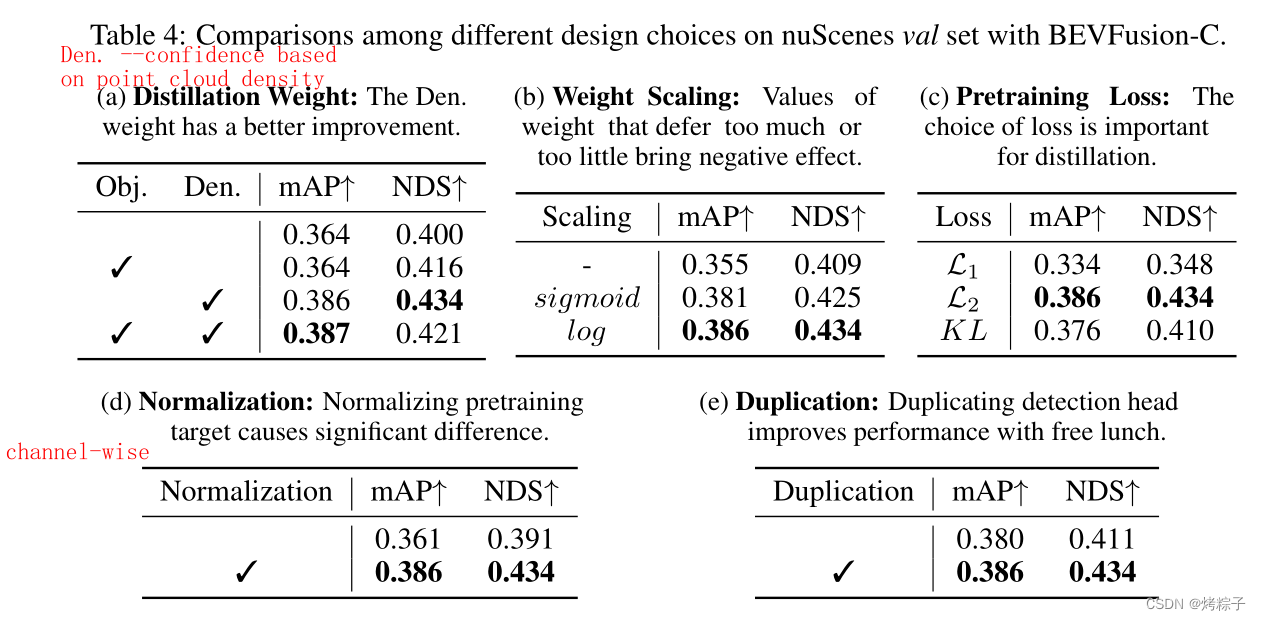
加了channel-wise normalization
Thoughts
一个亮点是,有别于之前利用object选取,本文提出利用点云密度来帮助选取,效果不错,证明了前背景信息都很重要。
本文重点在pretraining阶段,为了对齐特征表示,从老师那里学习知识,用了选区蒸馏,channel-wise等。















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











