







概述
本人使用的系统是Windows11,cuda版本11.7,cudnn版本8.5。
1. 安装环境
新建虚拟环境:
conda create -n yolov8 python=3.8(指定安装目录:conda create -p .\yolov8 python=3.8)
激活环境:
conda activate yolov8
安装torch:
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
安装ultralytics:
pip install ultralytics
除此之外,在这里总结一下常用的命令:
查看conda版本:conda --version
查看NVIDIA GPU 的各种信息:nvidia-smi(这里显示的cuda版本是本系统可安装的最高版本)
查看CUDA 版本:nvcc -V
查看cuDNN版本:
import torch
print(torch.backends.cudnn.version())
查看已安装的环境:conda env list
删除环境:conda remove -n your_env_name --all
退出环境:conda deactivate
2. 模型选择
目标检测算法可分为传统检测算法和基于深度学习的目标检测算法。传统目标检测算法通常依赖于手工设计的特征提取方法(如SIFT、HOG等),这些特征对施工现场复杂场景的泛化能力较差,难以适应目标的形状、纹理和光照的多样性。其次,传统方法依赖滑窗搜索等策略,难以准确定位目标,尤其是对于小目标或目标密集的场景。
基于深度学习的目标检测算法可分为一阶段目标检测算法(如 YOLO、SSD)和两阶段目标检测算法(如 Faster R-CNN)。两阶段算法在检测精度上通常更占优,但其速度、资源消耗方面使得它在某些场景下不如一阶段算法灵活实用。本人基于施工现场监控摄像头为研究方向,需要满足实时性需求,因此,这里选择一阶段目标检测算法。
YOLOv8 相较其他一阶段目标检测算法,具备更高的检测精度和推理速度,同时在小目标检测、多任务支持和部署灵活性方面表现优异。它通过改进网络结构、优化训练策略和易用工具链,大幅降低使用门槛,适合多场景应用。因此,本人选择YOLOv8算法进行安全帽识别。
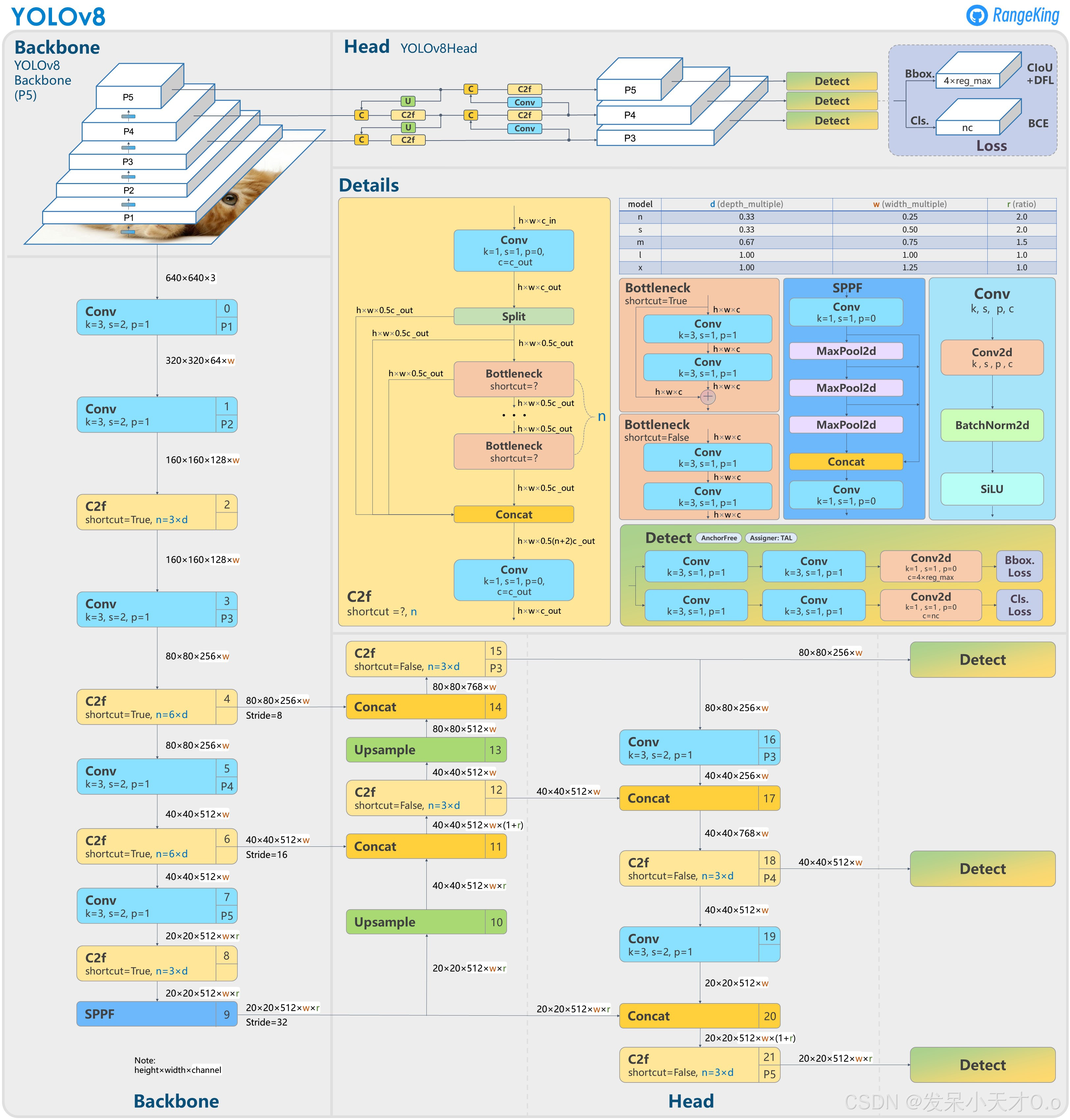
3. 模型介绍
YOLOv8由Ultralytics公司在2023年1月10日开源,支持全范围的视觉AI任务,包括分类、检测、分割、姿态估计和跟踪。YOLOv8在之前YOLO版本的基础上,在多个方面进行了改进和优化。以下是一些关键的改进点:
骨干和颈部改进: 相较于YOLOv5,YOLOv8采用了C2f模块替换YOLOv5的C3模块,该模块结合了丰富的梯度流信息,提高了特征提取能力。
检测头设计: YOLOv8采用了anchor-free + Decoupled-head的设计,使得模型能够更好地适应不同尺度和形状的物体,提高了检测的准确率。
损失函数优化: YOLOv8采用了分类BCE、回归CIOU + VFL的组合损失函数,通过引入VFL(Vision Transformer Loss)提高了模型对上下文信息的捕捉能力。在这里需要强调一点,训练时实际使用的回归损失函数是CIOU +分布焦点损失(DFL)。
检测框匹配策略: YOLOv8将检测框匹配策略从静态匹配改为Task-Aligned Assigner匹配方式,使得模型能够更准确地预测物体位置。
对于目标检测任务,YOLOv8提供了Nano (n)、Small (s)、Medium (m)、Large (l) 和 Extra Large (x) 五个变体,用户可以根据硬件条件和任务需求选择合适的版本,在速度、精度和资源消耗之间实现最佳平衡。考虑到施工现场监控摄像头的安全帽识别需要平衡实时性和精度需求,因此,本人选择YOLOv8s。
4. 数据集制作
4.1 数据标注
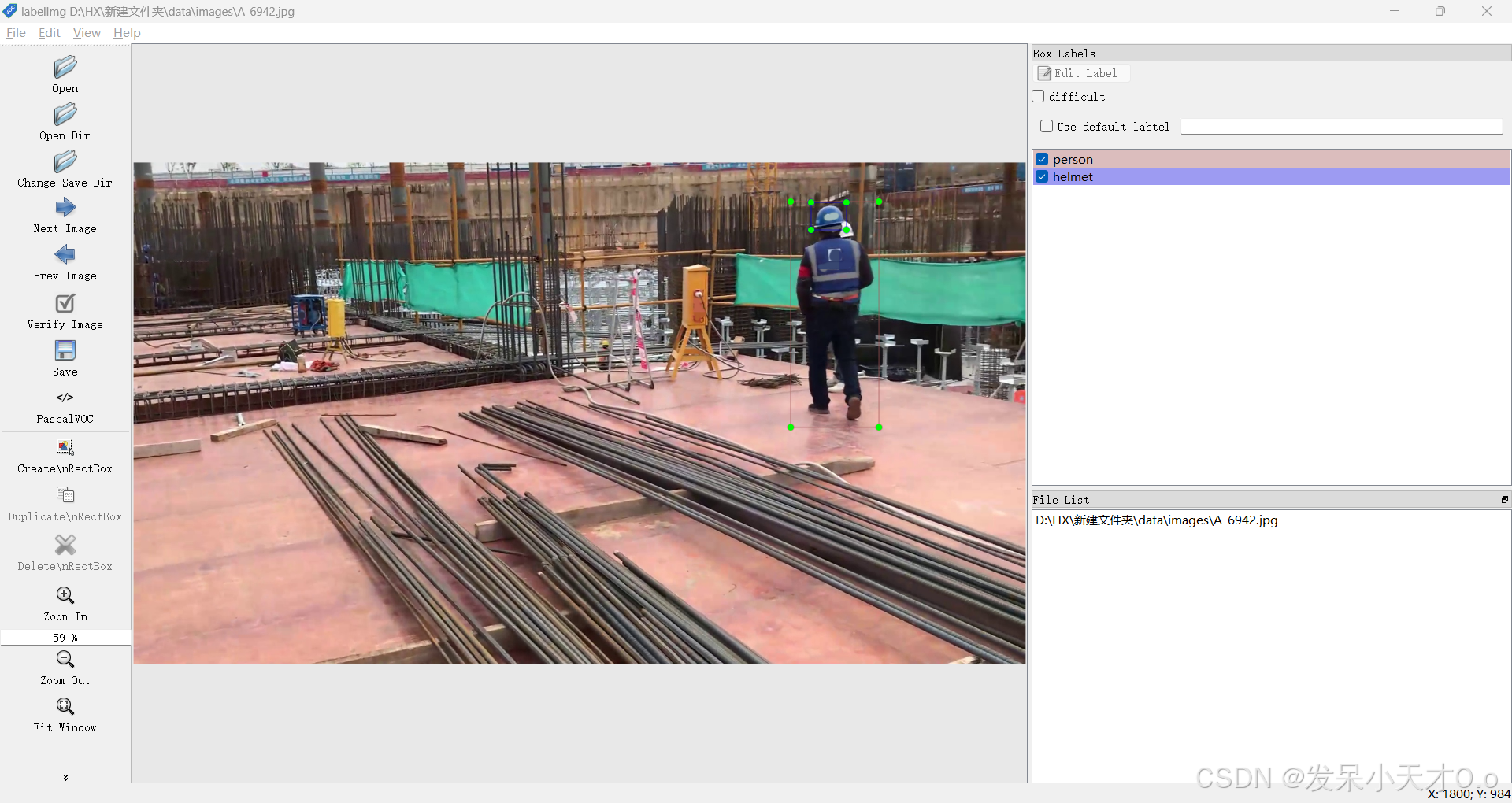
本人所采用的数据集是在开源数据集SHWD(Safety Helmet Wearing-Dataset)的基础上进行筛选和补充而得。由于SHWD数据集中存在大量非施工场景下的数据,因此额外收集了一部分施工现场的图片,使用labelimg对这些图像进行标注。
标注的目标分别是:
- ‘person’:行人
- ‘hat’:佩戴安全帽的头部
- ‘head’:未佩戴安全帽的头部
4.2 标签格式转换
标注完成后,得到的是VOC格式的XML标签。
VOC XML 标签结构:
- <size>:图像大小
- <width>:宽度
- <height>:高度
- <depth>:通道数
- <object>:表示目标。
- <name>:目标的类别。
- <bndbox>:目标的边界框,包含:
- <xmin>:左上角x坐标。
- <ymin>:左上角y坐标。
- <xmax>:右下角x坐标。
- <ymax>:右下角y坐标。
将VOC格式的XML标签转换为YOLO算法的TXT格式,可以通过以下代码实现。
YOLO格式要求每一行代表一个目标,包括目标类别、目标中心点的归一化坐标 (x_center, y_center) 和目标宽高 (width, height),格式如下:
<class_id> <x_center> <y_center> <width> <height>
xml2txt代码实现:
import os
import xml.etree.ElementTree as ET
def voc_to_yolo(xml_dir, txt_dir, classes, img_size=None):
"""
将VOC格式的XML文件转换为YOLO格式的TXT文件。
Args:
xml_dir (str): XML文件所在的目录路径。
txt_dir (str): 输出的TXT文件目录路径。
classes (list): 固定的类别列表,如 ["person", "car", "dog"]。
img_size (tuple): 图像的宽高 (width, height)。如果为 None,则从 XML 文件中读取。
"""
# 创建输出目录
os.makedirs(txt_dir, exist_ok=True)
# 遍历XML文件
for xml_file in os.listdir(xml_dir):
if not xml_file.endswith('.xml'):
continue
# 解析XML文件
tree = ET.parse(os.path.join(xml_dir, xml_file))
root = tree.getroot()
# 获取图像尺寸
if img_size is None:
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
else:
width, height = img_size
# 转换目标信息
yolo_annotations = []
for obj in root.findall('object'):
# 获取类别名和边界框
class_name = obj.find('name').text
bndbox = obj.find('bndbox')
xmin = float(bndbox.find('xmin').text)
ymin = float(bndbox.find('ymin').text)
xmax = float(bndbox.find('xmax').text)
ymax = float(bndbox.find('ymax').text)
# 转换为YOLO格式
if class_name in classes:
class_id = classes.index(class_name)
x_center = (xmin + xmax) / 2 / width
y_center = (ymin + ymax) / 2 / height
obj_width = (xmax - xmin) / width
obj_height = (ymax - ymin) / height
yolo_annotations.append(f"{class_id} {x_center:.6f} {y_center:.6f} {obj_width:.6f} {obj_height:.6f}")
else:
print(f"Warning: Class '{class_name}' not in predefined classes, skipping.")
# 保存到TXT文件
txt_filename = os.path.splitext(xml_file)[0] + '.txt'
with open(os.path.join(txt_dir, txt_filename), 'w') as txt_file:
txt_file.write('\n'.join(yolo_annotations))
print(f"Conversion completed! YOLO files saved in {txt_dir}.")
# Example usage
xml_dir = "E:/data/xml_label" # VOC XML 文件目录
txt_dir = "E:/data/txt_label" # YOLO TXT 输出目录
classes = ["person", "head", "helmet"] # 直接定义类别
voc_to_yolo(xml_dir, txt_dir, classes)
可以查看以下代码是否转换正确:
import cv2
import os
labels = ['0', '1', '0', '3', '4'] # 根据你的类别进行修改
# Color palette, 你可以为每个类别添加新的颜色
colormap = [(255, 255, 255), (56, 56, 255), (151, 157, 255), (31, 112, 255), (29, 178, 255)]
def draw_box_in_single_image(image_path, txt_path, output_folder):
image = cv2.imread(image_path)
# 读取 txt 文件中的内容
def read_list(txt_path):
pos = []
with open(txt_path, 'r') as file_to_read:
while True:
lines = file_to_read.readline() # 读取整行
if not lines:
break
p_tmp = [float(i) for i in lines.split(' ')]
pos.append(p_tmp)
return pos
# 将归一化坐标转换为实际的框坐标
def convert(size, box):
xmin = (box[1] - box[3] / 2.) * size[1]
xmax = (box[1] + box[3] / 2.) * size[1]
ymin = (box[2] - box[4] / 2.) * size[0]
ymax = (box[2] + box[4] / 2.) * size[0]
box = (int(xmin), int(ymin), int(xmax), int(ymax))
return box
pos = read_list(txt_path)
for i in range(len(pos)):
label = str(int(pos[i][0]))
box = convert(image.shape, pos[i])
image = cv2.rectangle(image, (box[0], box[1]), (box[2], box[3]), (0, 0, 255), 2)
cv2.putText(image, label, (box[0], box[1] - 2), 0, 1, [0, 0, 255], thickness=2, lineType=cv2.LINE_AA)
# 保存标注后的图像
if pos:
output_path = os.path.join(output_folder, os.path.basename(image_path))
cv2.imwrite(output_path, image)
else:
print(f"No objects detected in {txt_path}")
def batch_process_images(image_folder, txt_folder, output_folder):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
image_files = [f for f in os.listdir(image_folder) if f.endswith('.jpg')]
for image_file in image_files:
image_path = os.path.join(image_folder, image_file)
txt_path = os.path.join(txt_folder, image_file.replace('.jpg', '.txt'))
if os.path.exists(txt_path):
draw_box_in_single_image(image_path, txt_path, output_folder)
else:
print(f"Label file not found for {image_file}, skipping.")
# 设置文件夹路径
image_folder = "E:/data/images"
txt_folder = "E:/data/txt_label"
output_folder = "E:/data/output"
# 批量处理图像
batch_process_images(image_folder, txt_folder, output_folder)
4.3 划分数据集
本文将数据集按照8:1:1的比例划分为训练集、验证集和测试集。
import os
import shutil
import random
from tqdm import tqdm
def split_img(img_path, label_path, split_list):
try:
# 数据存储根目录
Data = "E:/data/dataset"
# 定义训练集、验证集和测试集的图像和标签存储路径
train_img_dir = os.path.join(Data, 'images', 'train')
val_img_dir = os.path.join(Data, 'images', 'val')
test_img_dir = os.path.join(Data, 'images', 'test')
train_label_dir = os.path.join(Data, 'labels', 'train')
val_label_dir = os.path.join(Data, 'labels', 'val')
test_label_dir = os.path.join(Data, 'labels', 'test')
# 创建存储路径,如果目录已存在则不报错
os.makedirs(train_img_dir, exist_ok=True)
os.makedirs(train_label_dir, exist_ok=True)
os.makedirs(val_img_dir, exist_ok=True)
os.makedirs(val_label_dir, exist_ok=True)
os.makedirs(test_img_dir, exist_ok=True)
os.makedirs(test_label_dir, exist_ok=True)
except Exception as e:
print(f"Error creating directories: {e}")
# 获取数据划分比例:训练集、验证集、测试集的比例
train, val, test = split_list
# 获取所有图像文件路径
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# 随机划分训练集
train_img = random.sample(all_img_path, int(train * len(all_img_path))) # 从所有图像中随机选择训练集图像
train_img_copy = [os.path.join(train_img_dir, os.path.basename(img)) for img in train_img] # 训练集图像目标路径
train_label = [toLabelPath(img, label_path) for img in train_img] # 对应的标签路径
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
_copy(train_img[i], train_img_dir) # 复制图像到目标文件夹
_copy(train_label[i], train_label_dir) # 复制标签到目标文件夹
all_img_path.remove(train_img[i]) # 从剩余图像中移除已处理图像
# 随机划分验证集
val_img = random.sample(all_img_path, int(val / (val + test) * len(all_img_path))) # 从剩余图像中选择验证集
val_label = [toLabelPath(img, label_path) for img in val_img] # 对应的标签路径
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
_copy(val_img[i], val_img_dir) # 复制图像到目标文件夹
_copy(val_label[i], val_label_dir) # 复制标签到目标文件夹
all_img_path.remove(val_img[i]) # 从剩余图像中移除已处理图像
# 剩余的图像为测试集
test_img = all_img_path
test_label = [toLabelPath(img, label_path) for img in test_img] # 对应的标签路径
for i in tqdm(range(len(test_img)), desc='test ', ncols=80, unit='img'):
_copy(test_img[i], test_img_dir) # 复制图像到目标文件夹
_copy(test_label[i], test_label_dir) # 复制标签到目标文件夹
# 复制文件的辅助函数
def _copy(from_path, to_path):
shutil.copy(from_path, to_path) # 使用shutil.copy复制文件
# 根据图像路径生成对应的标签路径
def toLabelPath(img_path, label_path):
img = os.path.basename(img_path) # 获取图像文件名
label = img.split('.jpg')[0] + '.txt' # 假设标签文件名与图像名相同,只是后缀为.txt
return os.path.join(label_path, label) # 返回标签文件的完整路径
def main():
img_path = "E:/data/images" # 图像文件夹路径
label_path = "E:/data/txt_label" # 标签文件夹路径
split_list = [0.8, 0.1, 0.1] # 数据集划分比例:[训练集:验证集:测试集]
split_img(img_path, label_path, split_list) # 调用split_img函数进行数据划分
# 执行主函数
if __name__ == '__main__':
main()
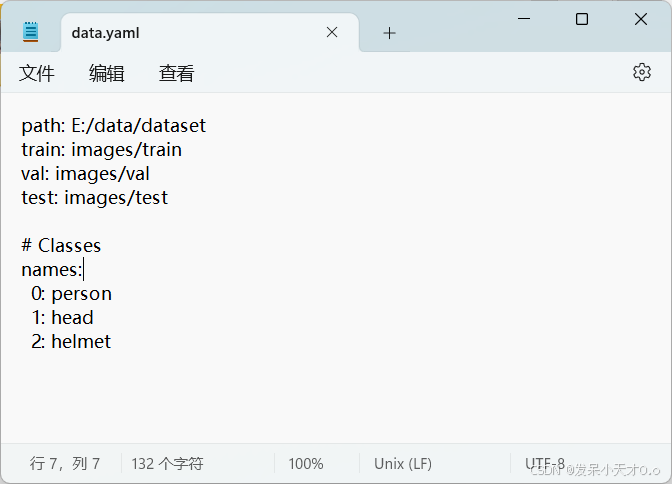
4.4 配置文件
在dataset文件夹下新建一个data.yaml文件(可以自定义命名),用来存放训练集和验证集的路径以及目标类别。
data.yaml内容如下:
至此,自定义数据集已创建完毕,接下来就是训练模型了。
5. 模型训练
5.1 模型下载
在YOLOv8的GitHub开源网址上下载源代码以及对应版本的模型。
也可以通过终端输入一下命令下载代码
git clone https://github.com/ultralytics/ultralytics.git
5.2 模型训练
一种方式是使用命令进行训练:
# 从YAML构建一个新模型,从头开始训练
yolo detect train data=E:/data/dataset/data.yaml model=./yolov8s.yaml batch=32 epochs=150 imgsz=640 workers=12 device=0 pretrained=False
# 从预训练的*.pt模型开始训练
yolo detect train data=E:/data/dataset/data.yaml model=./yolov8s.pt batch=32 epochs=150 imgsz=640 workers=12 device=0
# 从YAML中构建一个新模型,将预训练的权重转移到它并开始训练
yolo detect train data=E:/data/dataset/data.yaml model=./mymodel.yaml batch=32 epochs=150 imgsz=640 workers=12 device=0 pretrained=yolov8s.pt
另一种方式Python实现:
import os
import torch
from ultralytics import YOLO
def main():
# 检查是否有可用的GPU,如果有则使用GPU进行训练,否则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 模型加载部分(三选一的情况,这里选择加载预训练模型进行微调,可按需修改)
model = YOLO('yolov8s.pt') # 加载预训练模型
# model = YOLO('yolov8s.yaml') # pretrained=False,创建未预训练模型,自行从头训练
# model = YOLO('yolov8s.yaml').load('yolov8s.pt') # 构建YAML并转移权重
# 训练参数设置
data_path = 'E:/data/dataset/data.yaml'
epochs = 150
imgsz = 640
batch = 32
workers = 12
model.train(data=data_path, epochs=epochs, imgsz=imgsz, batch=batch, workers=workers, device=device)
if __name__ == "__main__":
main()
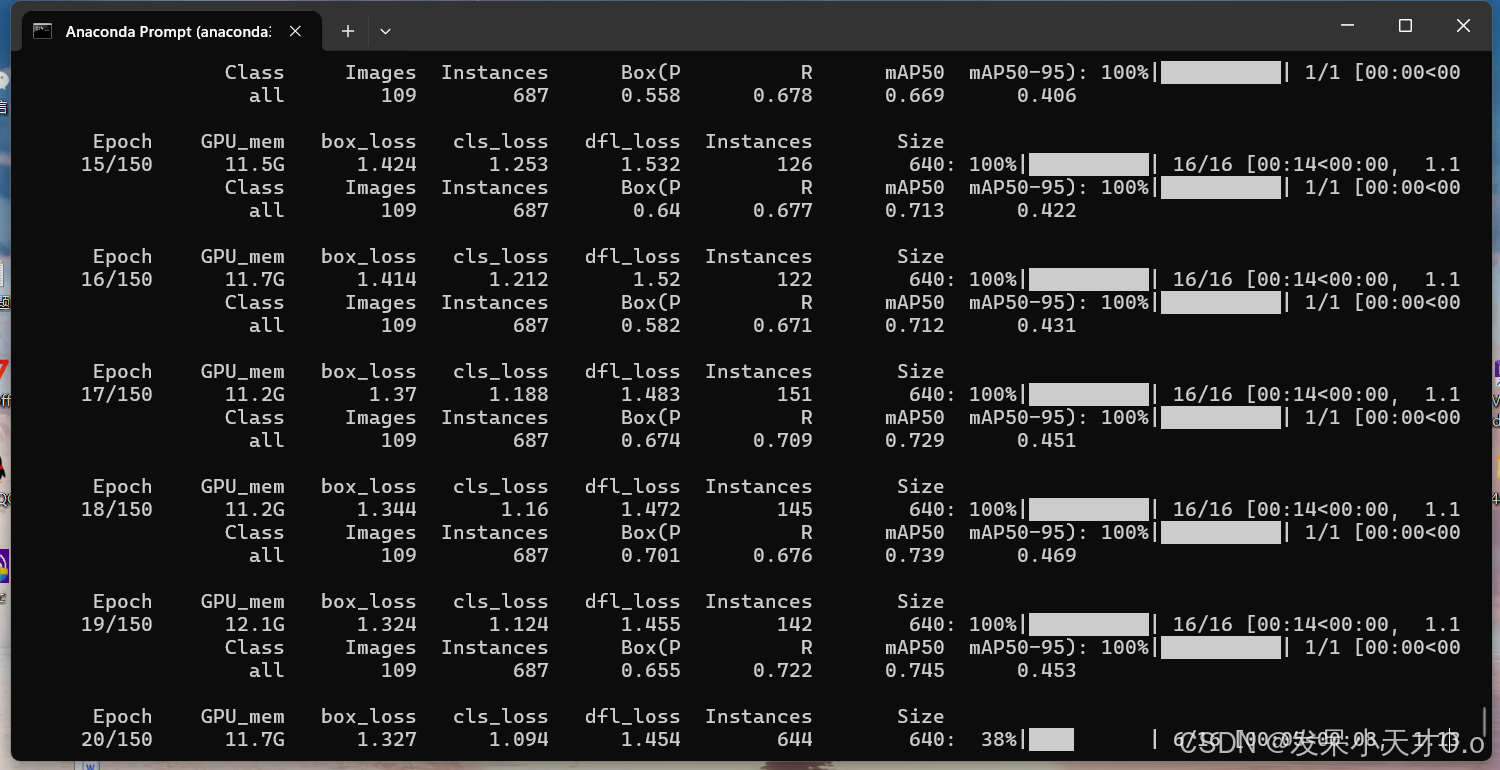
6. 模型验证
对验证集或测试集进行验证,命令如下:
# 验证集
yolo task=detect mode=val split=val model=./runs/detect/train/weights/best.pt data=E:/data/dataset/data.yaml batch=1 workers=0 imgsz=640 device=0
# 测试集
yolo task=detect mode=val split=test model=./runs/detect/train/weights/best.pt data=E:/data/dataset/data.yaml batch=1 workers=0 imgsz=640 device=0
或
from ultralytics import YOLO
model_path = r'.\runs\detect\train\weights\best.pt'
data_path = r'E:\data\dataset\data.yaml'
# 加载模型
model = YOLO(model_path)
# 对应命令行中的'mode=val'(这里调用val方法就是执行验证模式)、'split=test'(在数据配置中指定测试集相关信息来使用测试集进行验证)、
results = model.val(data=data_path, split='test', batch=1, workers=0, imgsz=640, device='0')
# results对象包含了如mAP(平均精度)、召回率等多种评估指标信息
print(results)
# 例如,提取并打印平均精度(mAP50),你可以根据实际需求查看其他指标
mAP50 = results.results_dict['metrics/mAP50']
print(f"mAP@50: {mAP50}")

7. 模型预测
yolo task=detect mode=predict model=./runs/detect/train/weights/best.pt source=E:/data/1.jpg save=True device=0
或
from ultralytics import YOLO
import os
model_path = r'.\runs\detect\train\weights\best.pt'
image_path = r'E:\data\1.jpg'# 可以是图像文件夹、视频
# 确保设备选择合理,如果有GPU且想使用GPU加速预测(这里设置使用GPU的第0块显卡),对应命令行中的 'device' 参数
# 若电脑没有GPU或者想使用CPU运行预测,则设置 device = ""
device = '0'
# 加载模型
model = YOLO(model_path)
# 使用模型对图像进行预测,设置参数
results = model.predict(source=image_path, save=True, device=device)
# 查看预测结果(可选操作,方便了解详细情况)
# results是一个包含预测信息的列表,对于单张图像预测,列表中只有一个元素
for r in results:
# 打印预测的类别、边界框坐标等信息(示例,可按需查看更多)
print(f"类别: {r.boxes.cls}")
print(f"边界框坐标: {r.boxes.xyxy}")
# 获取保存后的图像路径(默认会在当前目录下的 'runs/detect/predict' 文件夹中,按照一定命名规则保存结果图像)
save_dir = os.path.join('runs', 'detect', 'predict')
save_path = os.path.join(save_dir, os.path.basename(image_path))
print(f"带有预测标注的图像已保存至: {save_path}")

8. 模型导出
yolo task=detect mode=export model=./runs/detect/train/weights/best.pt format=onnx
或
from ultralytics import YOLO
# Load a model
model = YOLO('./runs/detect/train/weights/best.pt') # load a custom trained
# Export the model
model.export(format='onnx')


















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









