







使用 Transformers 模型做文本多分类任务,搭建好模型后,模型分类效果很差,训练时loss不断波动,有下降,但又会再变大,通过如下提示,比较训练和测试时loss变化趋势,发现属于第四种情况,因此调整了学习率和batch_size,获得了较好的多分类效果。
-
train loss 不断下降,test loss不断下降,说明网络仍在学习;
-
train loss 不断下降,test loss趋于不变,说明网络过拟合;
-
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
-
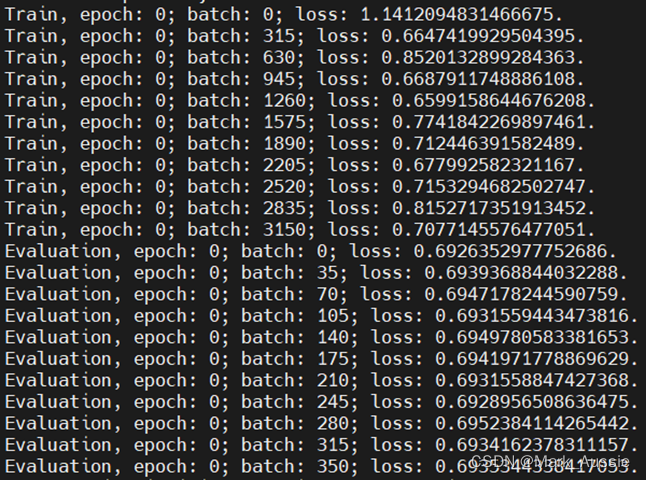
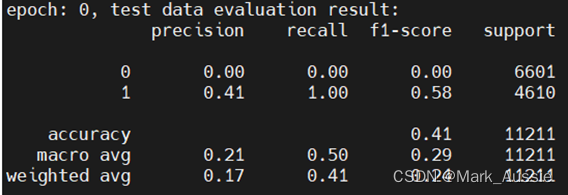
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;
-
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集清洗等问题。
实例
数据
新闻类别有两类:娱乐和体育,共22w条数据,抽取10w条做训练测试;
![]()
原参数
学习率:0.001;batch_size:32;sen_max_len:128;epoch:5
原效果
修改参数
学习率:1e-6;batch_size:16;sen_max_len:128;epoch:10
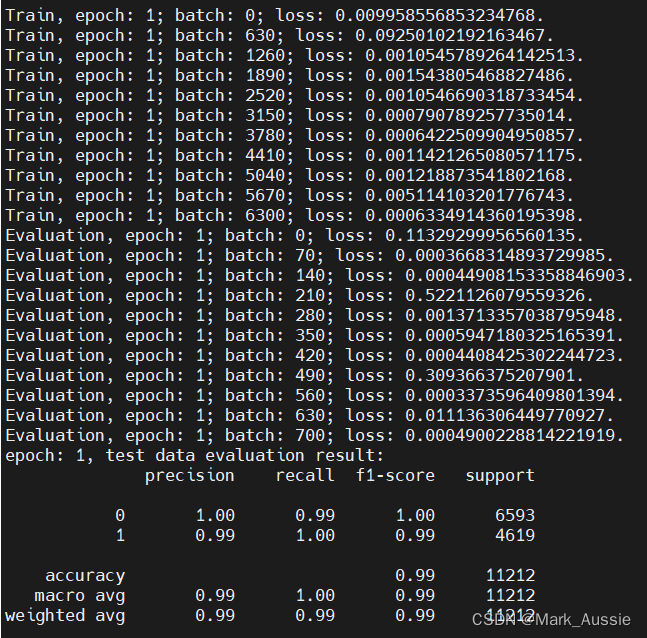
代码
import os
import pickle
import re
from pprint import pprint
import evaluate
import numpy as np
import pandas as pd
import torch
from sklearn.metrics import classification_report, precision_recall_fscore_support
from sklearn.utils import shuffle
from torch.optim import AdamW
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer, BertForSequenceClassification, get_scheduler, TrainingArguments, Trainer
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
def _train_eval(train_dl, test_dl, bert_model_path,
epoch_num: int = 5, class_num: int = 2,
target_names: list = None):
model = BertForSequenceClassification.from_pretrained(bert_model_path, num_labels=class_num)
optimizer = AdamW(model.parameters(), lr=1e-6)
model.to(device)
num_training_steps = epoch_num * len(train_dl)
lr_scheduler = get_scheduler(name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps)
train_batch_show_num = int(len(train_dl) / 10) if len(train_dl) / 10 > 10 else 10
test_batch_show_num = int(len(test_dl) / 10) if len(test_dl) / 10 > 10 else 10
for epoch in range(epoch_num):
model.train()
for i, bd in enumerate(train_dl):
segment_ids = bd['input_ids'].to(device)
attention_mask = bd['attention_mask'].to(device)
labels = bd['labels'].to(device)
outputs = model(segment_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
if i % train_batch_show_num == 0:
print(f'Train, epoch: {epoch}; batch: {i}; loss: {loss.item()}.')
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
torch.save(model.state_dict(), f"./model/bert_{epoch}_m.pth")
# 每个 epoch 验证训练结果
# model.load_state_dict(torch.load(f"./model/bert_{epoch}_m.pth"))
model.eval()
prediction_r = np.array([], dtype=int)
true_labels = np.array([], dtype=int)
with torch.no_grad():
for j, bd in enumerate(test_dl):
segment_ids = bd['input_ids'].to(device)
attention_mask = bd['attention_mask'].to(device)
labels = bd['labels'].to(device)
outputs = model(segment_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
if j % test_batch_show_num == 0:
print(f'Evaluation, epoch: {epoch}; batch: {j}; loss: {loss.item()}.')
probabilities = outputs.logits
bpr = torch.argmax(probabilities, dim=-1)
prediction_r = np.append(prediction_r, bpr.cpu().numpy())
labels = bd['labels'].cpu().numpy()
true_labels = np.append(true_labels, labels)
precision, recall, f1, support = precision_recall_fscore_support(true_labels, prediction_r,
average='macro', zero_division=0)
# pprint({'accuracy': (prediction_r == true_labels).mean(), 'precision': precision, 'recall': recall, 'f1': f1})
print(f'epoch: {epoch}, test data evaluation result:\n'
f'{classification_report(true_labels, prediction_r, target_names=target_names)}')
def train_eval_news(bert_model_path: str = 'bert-base-chinese/'):
# with open("D:\\GitProject\\bert_base_ch_demo\\bert_fine_tune_classify\\data/text_label.pkl", "rb") as f:
news_df = pd.read_csv("./output/news.csv")
news_df = news_df.sample(frac=0.5).reset_index(drop=True)
dr = sample_data_by_label(news_df, test_ratio=0.1, shuffle_flag=True)
train_df = dr["train_df"][['news', 'label']]
test_df = dr["test_df"][['news', 'label']]
pprint(f'train data:{train_df["label"].value_counts()}')
pprint(f'test data:{test_df["label"].value_counts()}')
tokenizer = BertTokenizer.from_pretrained(bert_model_path)
sen_max_len = 128
X_train = tokenizer(train_df['news'].tolist(), truncation=True, padding=True, max_length=sen_max_len)
Y_train = train_df['label'].tolist()
X_test = tokenizer(test_df['news'].tolist(), truncation=True, padding=True, max_length=sen_max_len)
Y_test = test_df['label'].tolist()
batch_size = 16
train_data_set = MyDataSet(X_train, Y_train)
train_dl = DataLoader(dataset=train_data_set, batch_size=batch_size, shuffle=False, num_workers=2)
test_data_set = MyDataSet(X_test, Y_test)
test_dl = DataLoader(dataset=test_data_set, batch_size=batch_size, shuffle=False, num_workers=2)
epoch_num = 6
class_num = 2
target_names = None
_train_eval(train_dl, test_dl, bert_model_path, epoch_num, class_num, target_names)
参考:















 1160
1160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









