







一、引言
在人工智能的黄金时代,Transformer架构已经成为了自然语言处理(NLP)领域的革命性创新。自2017年Vaswani等人首次介绍了这一架构以来,Transformer已经演化出多种变体,各自针对不同的NLP任务提供了专门的优化。这些变体包括BERT(Bidirectional Encoder Representations from Transformers)等Encoder-Only模型,专注于文本理解任务;GPT(Generative Pretrained Transformer)等Decoder-Only模型,擅长生成连贯的文本序列;以及标准的Encoder-Decoder模型,如原始Transformer和T5(Text-to-Text Transfer Transformer),它们在需要平衡理解和生成能力的任务,如机器翻译,中表现出色。这些大模型的出现不仅极大地推动了NLP的研究边界,还在商业应用中展现了巨大的潜力,从自动摘要和聊天机器人,到复杂的问答系统和情感分析,Transformer架构的不同变体已成为当今解决语言问题的核心工具。随着模型复杂性的增加和应用场景的扩展,微调变得尤为关键,以便将预训练的模型精准地适配到特定领域的需求。
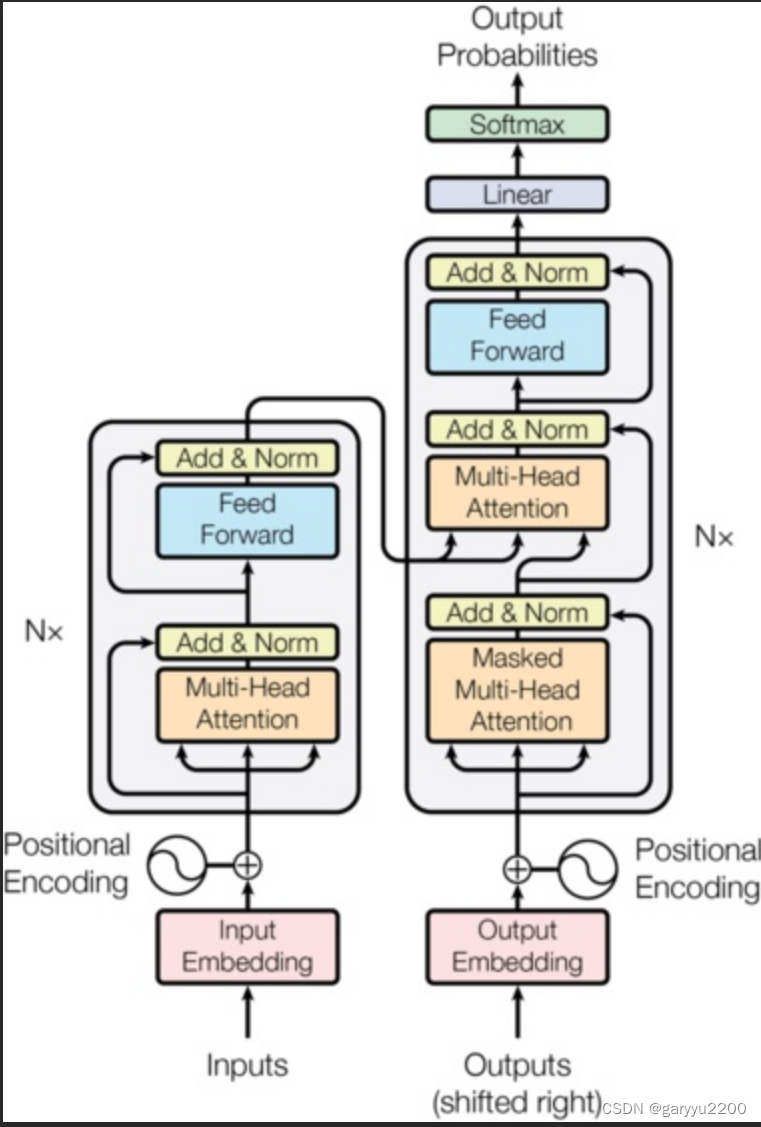
经典Tranformer架构
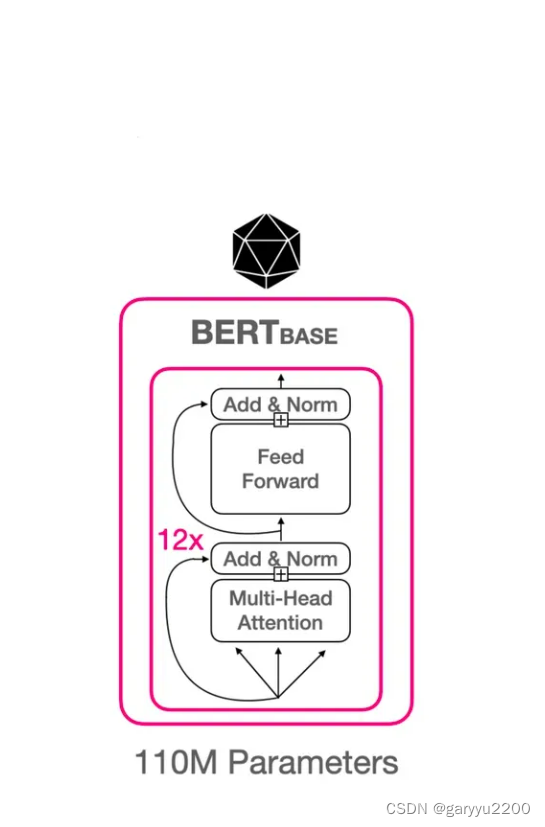
Bert(encoder-only)
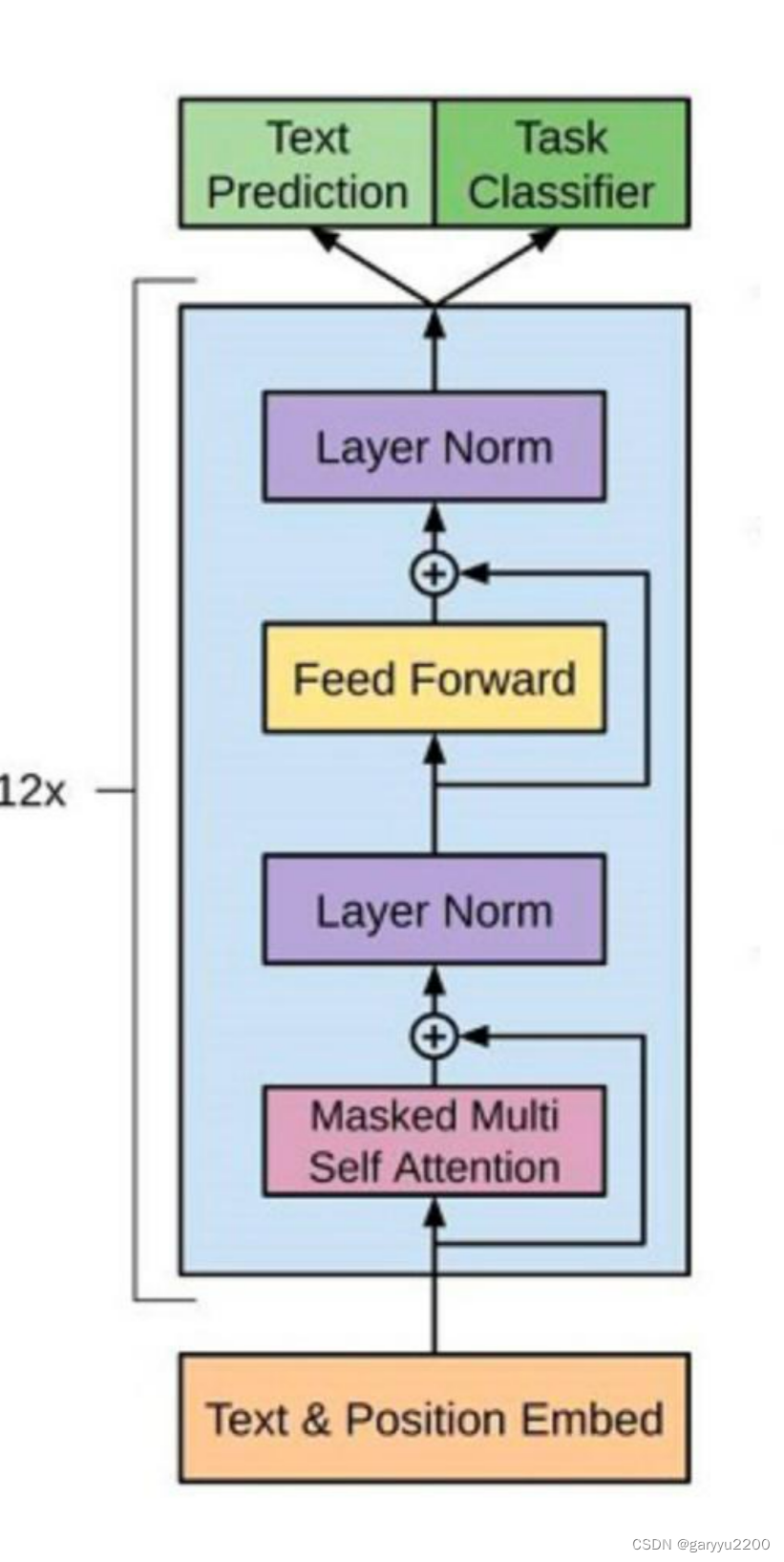
Decoder-only(GPT系列)
二、算法层面分析
1、Encoder的双向理解能力
Encoder的设计允许它同时考虑输入序列中的所有元素(例如单词),这种特性通常被称为双向理解能力或全局理解能力。在机器翻译任务中,这是非常重要的,因为源语言的每个单词的意义可能依赖于整个句子的上下文。
举例:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











